如今人工智能、大数据分析以及科学计算等领域处于高速发展态势,在此情形下,算力已然成为驱动创新的核心引擎。算力平台,它作为提供大规模计算资源以及服务的基础设施,正从传统的集中式数据中心朝着分布式、异构化还有智能化的形态而演进,其重要性正日益凸显出来。对于企业、研究机构乃至个人开发者来讲,理解算力平台的运作机制以及选型逻辑,是能够有效利用计算资源、加速业务创新的前提条件。
在了解架构以及服务模式的状况之下,当下的算力平台主要能够划分出来几种类型。首先存在的是传统的自行建造数据中心,用户需要依靠自己去采购服务器,开展网络以及冷却系统的部署工作,并且组织专业的团队来实施运维工作。这样的模式在前期的时候资本投入是非常巨大的,一台具备高性能的GPU服务器,其采购成本有可能从数十万元开始起步,而且部署的周期常常是长达数个月的。依据行业的统计数据,自行建造的数据中心在非峰值这段时间里的平均资源闲置率,有可能高达60%以上,从而导致明显的资源浪费以及成本沉没。
次之是拿虚拟机以及容器当作代表的云计算服务。使用者无需去管理物理硬件,能够按照需求去租用虚拟化的计算资源、存储资源以及网络资源,并且一般是依据使用的时长来计费。这样的模式极大地削减了初始门槛,资源开通的时间能够缩短到分钟级别。然而虚拟化层会产生一定的性能开销,对于那些追求极致计算性能的应用而言可能存在着限制。
其中的第三种,是近些年来开始兴起的异构算力平台以及边缘计算平台,这一类平台,不但整合了CPU、GPU,而且还纳入了NPU、TPU等好些专用计算芯片,进而形成统一的资源池,更为关键的是,它们依靠广泛的边缘节点网络,把算力布置在更靠近数据产生源头或者用户终端的物理位置,比如说,有些平台在全球范围之内建造了超过1000个边缘节点,能够把端到端的网络传输延迟降低80%以上,这对于实时视频渲染、在线交互式AI推理等情形而言至关重要。
在挑选算力平台之际,要对多个维度的因素予以综合衡量。性能绝对是关键核心,这涵盖单卡算力、集群互联带宽、存储IO速度等硬性指标。比如说,针对大规模语言模型训练,显存高达80GB的A100或者H100芯片因具备高速互联能力而成为主流之选。成本结构会直接影响项目的经济可行性,除了硬件租赁的显性开支,还得留意电力的消耗、网络讯息流量的费用、运维方面的人力等隐性成本。反应业务波动时效的灵敏程度取决于弹性伸缩这一能力,符合期望的平台应当依据负载达成秒钟级别的自动扩展收缩,于业务处于高峰阶段时毫无缝隙地进行扩展,在空闲之际自行将资源予以释放从而把成本降低。
同样不能被忽视的是安全性、合规性与易用性,数据敏感型应用要求平台给出严格的物理隔离或者加密保障,跨国业务需要保证算力节点所在之处契合当地的数据主权法规,平台有没有提供预集成的AI框架、一键式模型部署工具以及完善的监控告警系统,这也直接关联到开发与运维的效率。
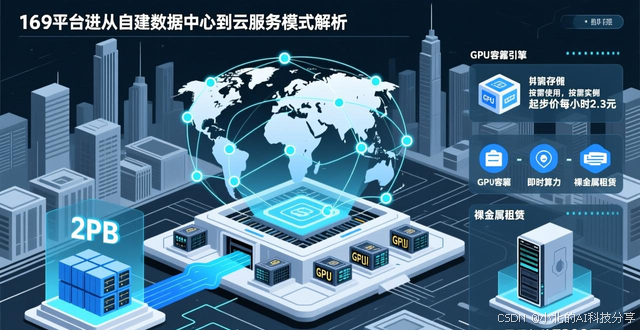
在市场选择呈现多样化的情形下,各异的服务商依据自身所拥有的资源以及技术方面的积淀,塑造出了带有各自独特风格的解决方案。就拿白山智算来说,其所搭建的分布式算力平台,整合了数量超过的异构算力资源,还配备了容量为2PB的并行存储系统。此平台借助智能调度引擎,把算力任务以动态方式分配到全球分布的各个节点,目的在于达成资源利用率的最大化。在服务模式这个层面上,它给出了从GPU容器实例、即时算力再到裸金属租赁的多种选择。其GPU容器实例,支持等型号,按需使用时,起步价约为每小时2.3元;裸金属租赁模式,为需要物理隔离或极致性能的任务,提供整机租用,一台配置的服务器,月租起价约为7200元。平台强调,通过动态路由和就近推理,来优化网络延迟,且配有专业的技术支撑团队。
整体来说,算力平台的发展正朝着更为高效、更为灵活、更为普惠的方向前行,未来的趋势不但不会局限于给予基础的计算能力,而且会深度融入到AI工作流的各个环节当中,涵盖着数据的预处理,模型的自动化训练与优化,推理服务的部署还要进行监控等,构建出一站式的智算解决方案。聚焦于用户一端来说,重中之重是清晰界定自身业务所需、性能期望以及成本规划,基于此,谨慎衡量不同平台于核心技术指标、服务可靠程度以及长期生态支撑方面的呈现状况,借此做出最契合自身发展轨迹的算力基础设施挑选抉择。于这个算力等同于生产力的时代而言,理性的选型行为与高效的利用举措,毫无疑问是获取竞争优势的关键基石要素。