算力即权力:透视AI时代的核心生产力
2026年,人工智能发展显著地已脱离"大模型军备竞赛"的初始蛮荒阶段,进而步入了精细化落地与产业化深度融合的关键区域,在这场堪称深刻的技术变革进程里,有一个词汇被不断反复提及,其重要程度与日俱增,这个词汇便是------AI算力,它不再单纯只是技术极客以及大型科技公司所关注的特定专利范畴,而是正逐渐演变为如同电力、网络那般,能够决定数字经济发展进程快慢的基础性资源,本文会从客观、专业的视角方向,深度剖析解析AI算力的构成状况、当前现状、具体应用模式以及未来发展趋势。
一、 AI算力的核心构成:不止于GPU
谈论AI算力之际,极其轻易就会把它单纯地等同于图形处理器也就是GPU的数量,可是呢,现代AI计算属于一个复杂的系统工程,它是由多元异构的硬件资源构成的,主要涵盖的有:。
- GPU(图形处理器): 因有着强大的并行运算能力,GPU现今仍是AI训练以及推理的绝对主要力量。它那数千个核心能够在同一时间处理好多简单运算,很好地符合了神经网络海量矩阵运算的需要。像的H100、A100还有消费级的RTX 4090等作为代表,它们形成了算力市场的关键力量。
其二,有关其他专用芯片,伴随技术不断发展,NPU也就是神经网络处理单元、TPU即张量处理单元以及FPGA也就是现场可编程门阵列等这类专用芯片,于特定场景里开始崭露头角。NPU在能效比方面具备显著优势,极为契合移动端和边缘侧的推理任务,TPU乃是专门用来加速等框架下的深度学习任务的标点符号。
- **CPU跟存储网络:**强劲的算力要有相匹配的基础设施。性能卓越的CPU承担着指令调度以及数据预处置的工作,然而PB级别的大容量存储还有Tbps级别的弹性带宽,保证了海量的训练数据能够被迅速读取并且传输,防止出现I/O瓶颈。
因此,有一个成熟的AI算力平台,其本质是这样的,它是一个综合系统,这个系统会把GPU、NPU、CPU等多元算力资源进行池化,还会对这些资源进行管理,并且会实施智能调度。
二、 算力服务的演进:从重资产到水电模式
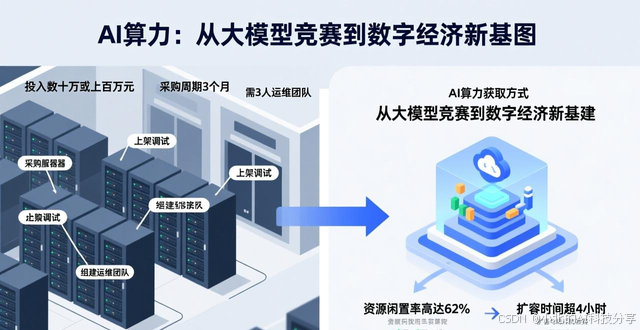
早前的时候,企业以及研究机构获取AI算力的唯一一种方式在于自行建立数据中心,这就表明在前期的时候需要投入数十万甚至是上百万元去采购服务器,要历经长达3个月的采购、上架以及调试周期,并且要组建至少3人的专业运维团队。在这样的模式之下,硬件的折旧、电力的消耗以及人力方面的成本一直处于很高的状态。更为关键的是,面对突然出现的业务高峰,手动进行扩容所需时间要超过4小时,而日常的资源闲置率依据监控数据统计能够高达62%,从而造成了极大的浪费。
这样一种"有着重资产特性、缺乏弹性特点"的模式,正被具备更灵活特质以及更高效效能的算力服务模式给替代。当下主流的算力交付模式主要存在以下三种情况:
对于 GPU 容器实例(按需计费)而言,它达成了"开箱即用"的情况,用户不用去操心底层硬件之事,短短只需 5 分钟就能够开通投入使用,平台还预先集成了主流的 AI 框架,并且支持一键部署像 、 等这样的大模型,它的计费模式可是相当灵活的,就拿一张 RTX 4090 来说,每卡每小时仅仅需要 2.3 元之多,对于日均推理任务来讲,月成本预估能够控制在 1600 元左右,如此这般极大地降低了中小企业以及开发者的入门门槛。
-
弹性即时算力(): 这是朝着资源利用率的极致方向去追求的。架构具备支持秒级自动伸缩的特性,它可以极为出色地应对AI推理服务里出现的突发流量状况。在业务处于低谷时期,资源会自动进行释放,达成"零闲置成本"标准;处于高峰期时则会 扩展,以此保障服务的稳定性。它的计费精确到秒这一程度,还进一步把算力进行了颗粒化处理,使得用户仅仅是为实际所使用的计算资源以及流量去付费。
-
裸金属租赁(物理机独占): 在存在强安全隔离需求的场景下,在需要极致低延迟之情形中,在进行大规模仿真训练的状况里,裸金属租赁给出了最佳的选择,用户独家享有一整台全部是物理的服务器,没有任何虚拟化所产生的开销,得到百分百的原本的算力。拿一台配备了RTX 4090的服务器来当作例子,一个月的租赁所需要的成本大概是7200元,远远比自己建造的综合成本要低,而且还支持在一天之内迅速交付。
这三种模式出现了,于是这样一来,算力切实开始如同水电那般,按照需求去取用,依据用量来付费。
三、 边缘算力:决定体验的最后一公里
于AI应用里,算力这一要素,它不仅仅是与"算得快"存在关联,而且更是和"响应快"有着密切关系。在实时翻译、自动驾驶、工业视觉等这些对于时延极为敏感的场景当中,把数据传回到千里之外的云端中心去进行处理,这是不符合实际情况的。
应运而生的是边缘算力,大量边缘节点被部署在靠近用户的地区从而构建起一张全球毫秒级的算力输送网络,这些节点通常分布于东南亚、中东、欧美等主要市场,当用户发起推理请求时,智能调度引擎会根据网络状况以及节点负载自动选择最优的边缘节点进行"就近推理"。
经实践验证,借助这种智能路由以及边缘计算,端到端的网络延时能够降低超过80%,而且能够稳定地控制在20毫秒以内。这对于提升AIGC应用的用户体验而言,对于实现工业现场的实时控制来说,都是至关重要的。与此同时,边缘节点还能够开展数据预处理以及脱敏操作,这既减轻了中心节点所承受的压力,又满足了数据本地化处理的合规要求。

四、 合规与全球化布局:出海企业的必答题
随着中国企业走向全球的数量越来越多,算力基础设施的合规性变成了一项无法避开的挑战,不同国家和地区针对数据主权、隐私保护存有严格的法律法规。
成熟的算力平台,不但会提供资源,而且还会提供合规的"通行证"。比如说,在国内的话,核心城市节点有着等保2.0三级认证;西部像贵阳、庆阳等国家算力枢纽节点,会提供电价优惠以及政策支持。在海外,新加坡、雅加达等东南亚节点一般具备GDPR合规认证,能够满足出海企业对于数据本地化存储和处理的严格要求。对于更广泛的区域而言,具备全球化服务能力的平台能够提供按需定制的本地化合规支持,以此帮助企业规避潜在的法律风险。
五、 展望:AI算力的未来趋势
AI算力将朝着以下几个方向发展:
于芯片制程而言,其会持续朝着物理极限不断靠近,在此期间,借助Like (芯粒)这般的先进封装技术去整合具备不同工艺的芯片,并且还要发展更为高效的散热技术这一情况呢,将会成为提升算力密度以及能效比的关键所在。
算网深度融合,意味着,算力跟网络不会再处于割裂状态。在未来,算力网络可以像对计算资源进行调度那样,以动态、实时的方式,去调度网络带宽以及路径,进而为用户给予一体化的服务体验。
在服务方面展现出更为精细的特性:算力服务商所处角色发生转变,不再仅仅停留于单纯的资源提供方的身份上 ,而是朝着全流程的技术伙伴这一方向迈进。涵盖从模型优化开始 ,历经部署调优这一环节 ,直至提供7x24小时不间断的专家运维支持 ,如此这般构建而成的专业服务体系 ,会成为用于衡量平台价值的关键重要标准。
AI算力如今可不再是单纯的技术拼凑,它已然成为了一个复杂性生态系统,这个系统集合了多元硬件、智能调度、灵活计费以及全球化合规等多方面要素。对于所有AI创新者而言,在未来竞争里要想占据先机,关键就在于理解并且善于运用这一核心生产力。不管是大型企业去构建自身的护城河,还是初创团队快速验证创意,其前行的速度与边界,都将由选择合适的算力获取方式来决定。