一、引言
智能语音交互 与本地知识库作为人工智能领域两大关键技术,正分别重塑着人机交互模式与企业知识管理方式。
| 技术领域 | 核心目标 | 关键技术组成 | 关键特征 | 典型应用场景 |
|---|---|---|---|---|
| 智能语音交互 | 实现人与机器之间高效、自然的语音交流 | 语音识别 (ASR)、自然语言处理 (NLP)、语音合成 (TTS) | 以语音为主要载体,实现从指令识别到复杂对话的交互 | 智能家居、车载系统、智能手机助手、智能客服 |
| 本地知识库 | 为特定领域或企业提供精准、可靠、安全的知识支持 | 检索增强生成 (RAG)、大语言模型 (LLM)、向量数据库 | 数据存储在本地,响应速度快,支持个性化定制,隐私安全性高 | 企业智能客服、研发知识管理、合规审计支持、内部知识问答系统 |
二、技术汇总简述
关键技术分类说明表如下所示:
| 技术/组件名称 | 类别 | 核心功能 | 主要特点 | 应用场景 |
|---|---|---|---|---|
| Picovoice Porcupine | 语音唤醒引擎 | 离线语音关键词检测 | 1. 低功耗、低延迟 2. 支持自定义唤醒词 3. 跨平台支持(嵌入式/移动/桌面) 4. 无需网络连接 | 智能音箱、车载系统、物联网设备、移动应用 |
| Ollama | 本地AI模型部署工具 | 在本地运行和管理大型语言模型 | 1. 简化模型部署流程 2. 支持多种开源模型 3. 本地化运行,保障隐私 4. 提供REST API接口 | 私有知识库、本地AI助手、离线对话系统、研发测试 |
| Cherry Studio | AI应用开发平台 | 集成多模型对话与知识库管理 | 1. 图形化操作界面 2. 支持连接多种模型源 3. 内置知识库管理功能 4. 支持AI编程助手 | AI应用快速开发、团队协作、知识管理、教育培训 |
| MCP(Model Context Protocol) | AI模型交互协议 | 标准化大型语言模型(LLM)与外部数据源和工具之间的通信接口 | 1. 标准化与解耦:提供统一的"USB-C"式接口,实现AI应用与工具的"即插即用",降低集成复杂度 2. 双向通信:支持实时双向交互,LLM既可查询数据也能触发操作 3. 安全性:内置身份验证、权限控制和资源隔离机制,保障安全 4. 生态开放:基于JSON-RPC 2.0的开放标准,促进工具生态发展 | 1. 智能代码助手:在IDE中让LLM访问代码库、执行Git命令 2. 企业智能客服:连接CRM、知识库,提供个性化支持 3. 电商AI助手:通过自然语言完成商品推荐、下单、售后等全流程 |
| MFCC | 语音信号处理技术 | 梅尔频率倒谱系数特征提取 | 1. 模拟人耳听觉特性 2. 降低数据维度 3. 提升语音识别鲁棒性 4. 广泛应用的经典特征 | 语音识别、说话人识别、语音情感分析、音频分类 |
| WebRTC/FastRTC + Whisper | 实时音频处理方案 | 实时音频采集传输与语音识别 | 1. 低延迟音频传输 2. 高质量语音识别 3. 多语言支持 4. 开源可定制 | 实时字幕系统、视频会议、语音笔记、直播转录 |
| Xiaomi MiMo | 轻量化大语言模型 | 端侧设备上的高效推理 | 1. 模型轻量化优化 2. 快速推理响应 3. 端侧部署能力 4. 多模态支持潜力 | 手机AI助手、智能汽车、边缘计算设备、移动应用 |
三、 关键技术介绍
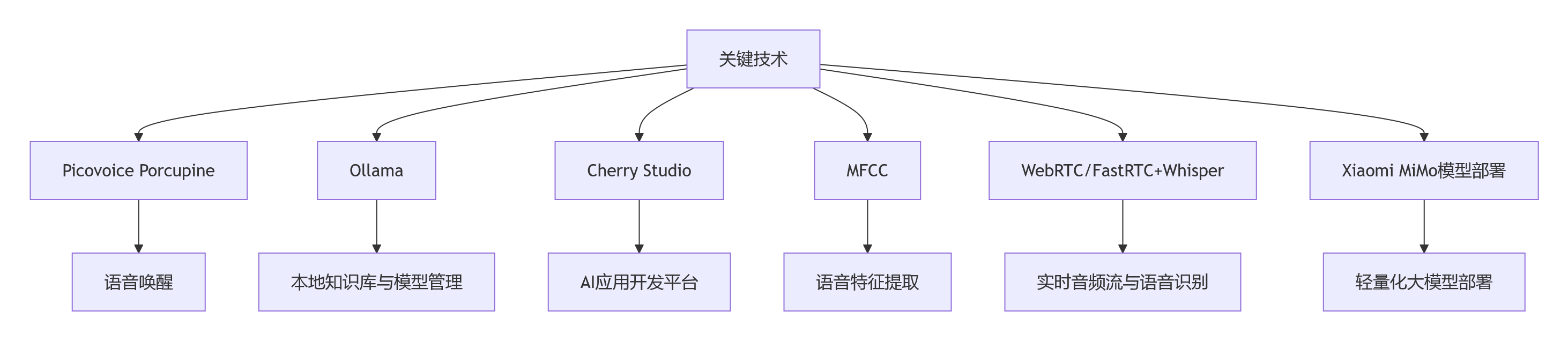
3.1 Picovoice Porcupine 语音关键字识别技术
技术特性 :Picovoice Porcupine是一款轻量级、高精度的离线语音唤醒引擎,支持多平台部署(Linux、Windows、macOS、Android、iOS、Raspberry
Pi等)。采用深度神经网络技术,模型大小仅数MB,支持自定义唤醒词训练,无需云端依赖,完全本地化运行。
核心特性:
-
离线唤醒:无需网络连接,保护用户隐私
-
低功耗运行:CPU占用率低,适合嵌入式设备
-
多唤醒词支持:可同时识别多个自定义唤醒词
-
抗噪能力强:在嘈杂环境下仍能保持高识别率
-
跨平台兼容:提供多种编程语言SDK
-
技术概述:轻量级离线语音唤醒解决方案,专为边缘计算设计。
应用场景:
-
智能音箱、智能家居设备的语音唤醒
-
车载语音助手、智能后视镜
-
工业设备语音控制
-
隐私敏感的语音应用场景
性能指标:
-
唤醒响应延迟:<200ms
-
误唤醒率:<1次/24小时
-
CPU占用:<5%(单核)
-
内存占用:<20MB
-
支持唤醒词数量:最多16个
3.2 Ollama +Cherry Studio 本地知识库搭建
技术特性 :Ollama提供本地大语言模型管理框架,支持多种开源模型(llama2、千问qwen、mistral等)的本地部署和推理。Cherry Studio是一款聚合主流大语言模型(LLM)服务的桌面工具。它通过直观的可视化界面和远程API接口,实现了跨平台调用各类模型,提供模型管理、知识库构建、对话界面等功能。
核心特性:
-
本地模型管理:一键下载、更新、切换不同模型
-
知识库构建:支持多种文档格式(PDF、Word、TXT、网页等)的自动解析和向量化
-
RAG增强:结合向量检索提升回答准确性和时效性
-
图形化界面:无需代码即可管理模型和知识库
-
API接口:提供RESTful API,便于集成到其他系统
应用场景:
-
企业内部知识问答系统
-
文档智能检索和总结
-
客服机器人、智能助手
-
教育培训领域的个性化学习助手
-
代码助手、技术文档查询
性能指标依赖环境:
-
模型加载时间:<30秒(7B模型)
-
知识库检索响应:<500ms(百万级文档)
-
单次推理延迟:<2秒(7B模型,CPU推理)
-
支持文档格式:PDF、DOCX、TXT、HTML、Markdown等
-
最大知识库规模:支持千万级文档向量化
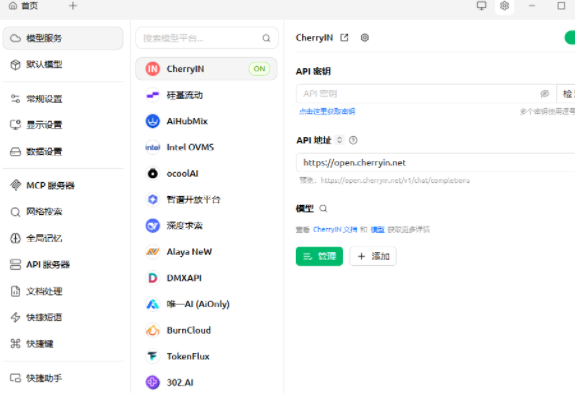
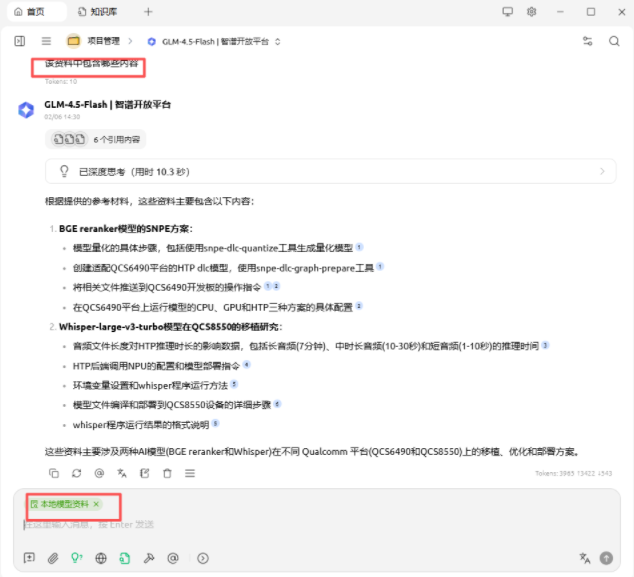
下述图为将本地相关文档传入,可以通过模型,对文档中的内容进行查找和总结:
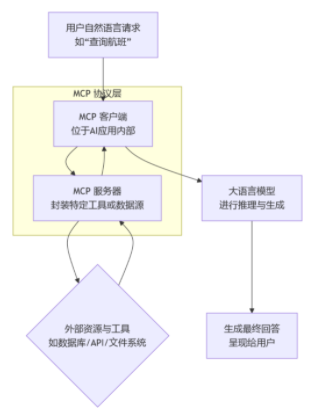
3.3 MCP(Model Control Protocol)
技术特性 :MCP是一种轻量级的AI模型交互协议,支持HTTP/HTTPS和WebSocket两种传输方式。协议设计简洁高效,支持同步和异步调用模式,具备良好的跨平台兼容性,可在不同编程语言和框架中快速集成。
核心特性:
-
统一接口规范:标准化模型调用、参数传递和结果返回格式
-
多模型支持:支持大语言模型、语音识别、图像处理等多种AI模型
-
资源管理:支持模型版本管理、负载均衡、熔断降级
-
监控统计:提供调用统计、性能监控、错误追踪
-
安全机制 :支持身份认证、访问控制、数据加密
应用场景:
-
AI中台服务化架构
-
多模型统一调度平台
-
微服务架构中的AI能力集成
-
边缘计算场景的模型服务治理
性能指标:
-
协议开销:<1ms(单次调用)
-
并发支持:>1000 QPS(单节点)
-
传输延迟:<5ms(局域网)
-
错误率:<0.1%
-
支持语言:Python、Java、Go、Node.js、C++等
3.4 MFCC 语音唤醒技术
技术特性 :MFCC(Mel-Frequency Cepstral Coefficients)是一种基于人耳听觉特性的语音特征提取方法,将语音信号转换为梅尔频率倒谱系数,用于语音识别和唤醒。技术成熟稳定,计算复杂度低,适合资源受限设备。
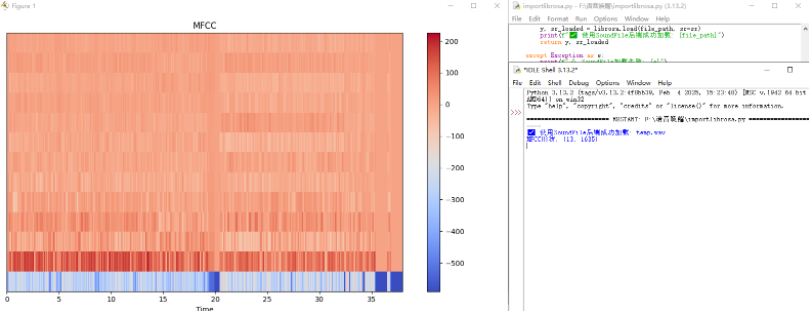
下图为使用python中的 librosa库来读取一个名为本地 temp.wav的音频文件,并从中提取一种在语音和音频分析中非常常用的特征------MFCC (梅尔频率倒谱系数),最后将结果可视化。
核心特性:
-
听觉特性建模:模拟人耳对频率的感知特性
-
降维处理:将高维语音信号压缩为低维特征向量
-
抗噪性能:对背景噪声有一定鲁棒性
-
计算高效:适合嵌入式设备实时处理
-
标准化特征:广泛应用于语音识别领域
应用场景:
-
语音唤醒词检测
-
语音命令识别
-
说话人识别
-
语音情感分析
-
语音活动检测
性能指标:
-
特征提取延迟:<10ms(10ms帧长)
-
特征维度:13-39维
-
采样率支持:8kHz、16kHz
-
帧长:10-25ms
-
帧移:5-10ms
3.5 WebRTC/FastRTC + Whisper 音频字幕技术
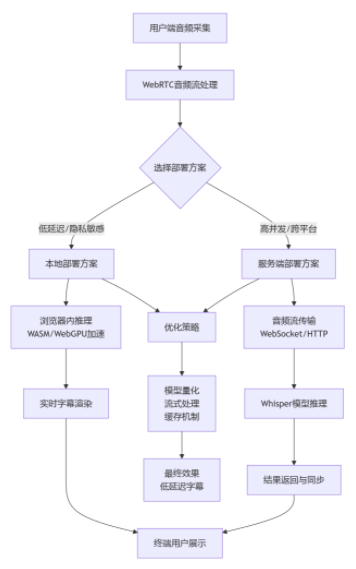
技术特性 :WebRTC提供浏览器端实时音视频通信能力,支持P2P传输和媒体流处理。FastRTC是WebRTC的优化版本,提供更低的延迟和更好的性能。Whisper是OpenAI开源的语音识别模型,支持多语言语音转文本,准确率高。技术框架如下图:
核心特性:
-
实时传输:端到端延迟<200ms
-
自适应码率:根据网络状况动态调整
-
多语言支持:Whisper支持99种语言
-
离线识别:Whisper可本地部署
-
字幕生成:实时语音转文字,生成字幕
应用场景:
-
在线会议实时字幕
-
直播平台实时字幕
-
视频会议转录
-
语音笔记自动生成
-
多语言实时翻译
性能指标:
-
端到端延迟:<200ms
-
识别准确率:>90%(中文)
-
支持语言:99种
-
模型大小:1.5GB(large模型)
-
推理速度:<实时(GPU加速)
3.6 Xiaomi MiMo 模型部署
技术特性:Xiaomi MiMo是小米自研的轻量化大模型部署框架,针对移动端和边缘设备优化,支持模型压缩、量化、剪枝等技术,在保持模型性能的同时大幅降低计算和存储开销。

下图为使用Xiaomi MiMo相关api询问今日西安天气的回复:
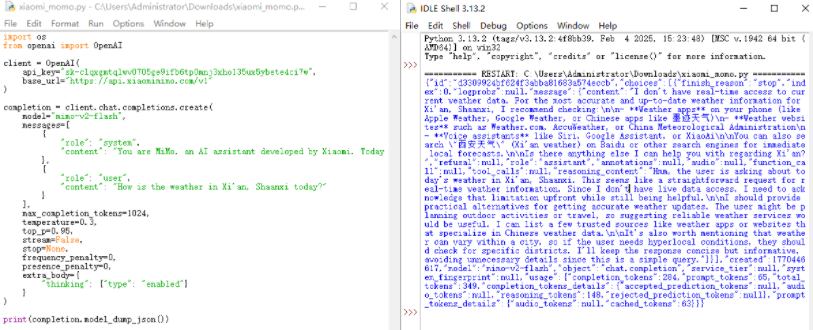
核心特性:
-
模型压缩:支持量化、剪枝、蒸馏等压缩技术
-
硬件加速:充分利用NPU、GPU等硬件加速器
-
动态加载:支持按需加载模型组件
-
多模型协同:支持多个小模型协同工作
-
功耗优化:针对移动端功耗深度优化
应用场景:
-
手机端AI应用(拍照增强、语音助手)
-
智能家居设备端AI
-
车载AI系统
-
IoT设备智能分析
-
边缘计算AI推理
性能指标:
-
模型压缩比:4-8倍
-
推理速度提升:2-4倍
-
内存占用降低:50-70%
-
功耗降低:30-50%
-
精度损失:<2%
四、 技术整合方案
4.1 智能语音交互技术整合方案
构建基于端到端语音处理的技术栈,实现高效、低延迟的语音交互体验:
前端语音采集层
-
采用Picovoice Porcupine实现离线语音唤醒,确保隐私安全
-
通过WebRTC/FastRTC进行实时音频采集和传输
-
集成MFCC特征提取技术,提升语音识别鲁棒性
核心处理引擎
-
部署Whisper语音识别模型,支持多语言实时转文本
-
结合MCP协议实现模型间的标准化通信
-
利用Xiaomi MiMo进行端侧轻量化推理优化
4.2 本地知识库技术整合方案
构建安全、高效的本地化知识管理和总结系统:
数据管理层
-
使用Ollama框架部署本地大语言模型
-
构建向量数据库,实现文档高效检索
-
支持多种格式文档的自动解析和向量化
知识处理引擎
- 通过Cherry Studio集成多个大模型,并提供图形化知识库管理界面
4.3 技术优势对比分析
| 技术领域 | 核心技术优势 | 适用场景 | 性能指标 |
|---|---|---|---|
| 智能语音交互 | 1. 离线运行保障隐私安全 2. 低延迟实时响应 3. 多平台兼容性 4. 抗噪声能力强 | 1. 智能家居控制 2. 车载语音系统 3. 移动设备助手 4. 工业语音控制 | 1. 唤醒延迟<200ms 2. 识别准确率>90% 3. CPU占用<5% 4. 内存占用<20MB |
| 本地知识库 | 1. 数据本地化保障安全 2. 响应速度快 3. 支持个性化定制 4. 无需网络依赖 | 1. 企业知识管理 2. 内部问答系统 3. 合规审计支持 4. 研发知识库 | 1. 检索响应<500ms 2. 支持千万级文档 3. 多格式文档支持 4. 7B模型加载<30s |