B+ 树是多路平衡搜索树 ,专为磁盘 / 页式存储 设计,是 MySQL InnoDB、Oracle、PostgreSQL 等数据库索引的事实标准。
一、B+ 树长什么样
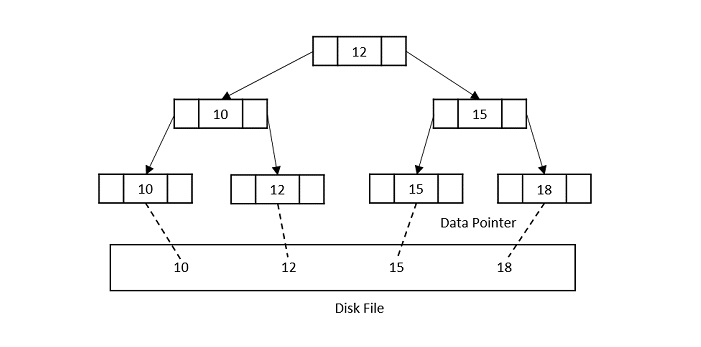
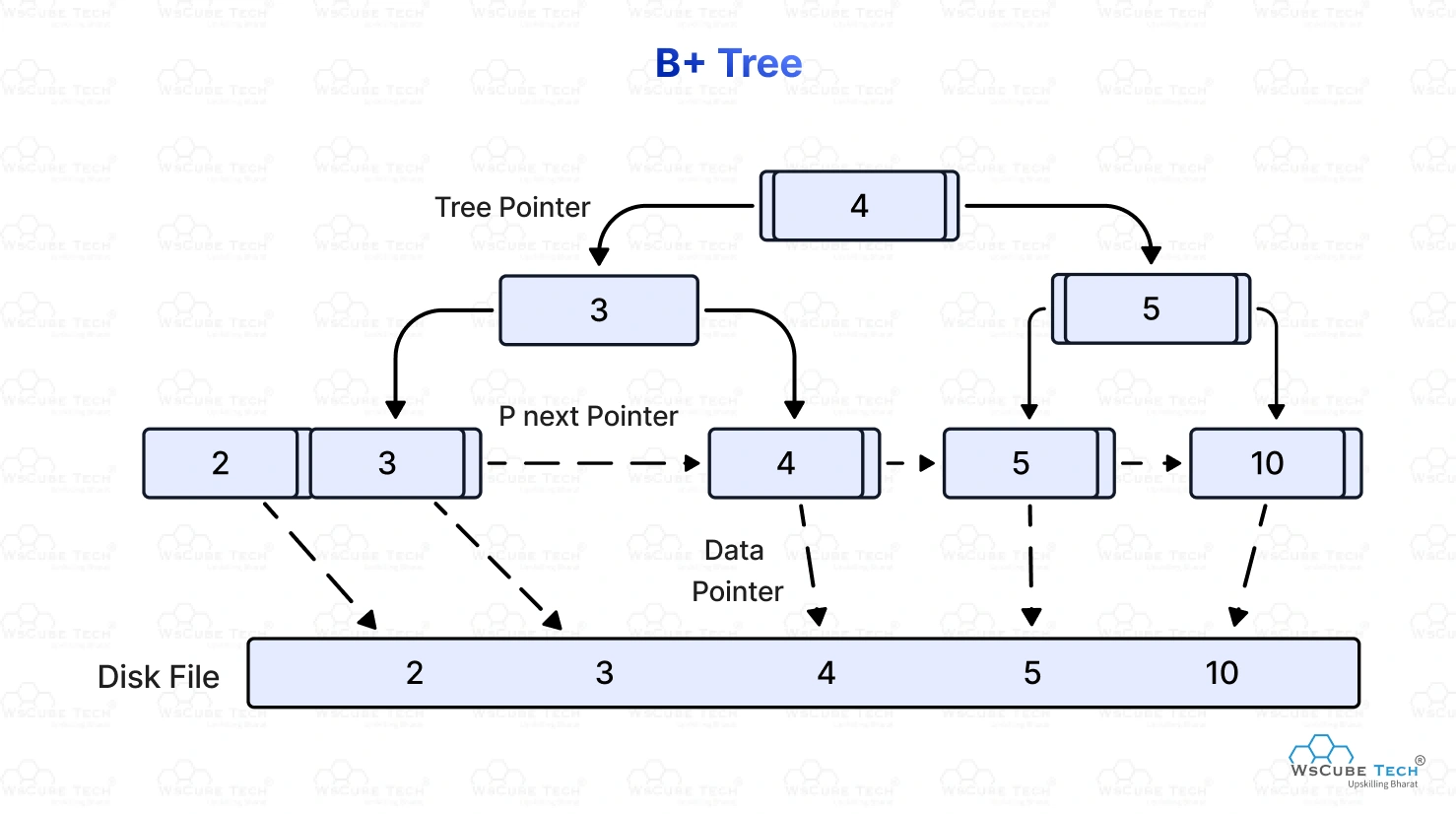
核心结构特征
- 多叉:一个节点可包含多个 key(降低树高)
- 所有数据只在叶子节点
- 叶子节点有序 + 双向链表
- 非叶子节点只存 key + 指针(不存数据)
二、B+ 树 vs 二叉搜索树(为什么不用 BST)
| 对比项 | 二叉搜索树 | B+ 树 |
|---|---|---|
| 分支数 | 2 | 多路 |
| 树高 | 高 | 很低 |
| 磁盘 IO | 多 | 极少 |
| 范围查询 | 差 | 极强 |
数据库瓶颈在磁盘 IO,而不是 CPU
B+ 树通过**"矮胖结构"**,将一次查询控制在 2~4 次磁盘 IO。
三、B+ 树 vs B 树(高频面试点)
| 对比 | B 树 | B+ 树 |
|---|---|---|
| 数据存储 | 所有节点 | 仅叶子节点 |
| 叶子节点 | 无链表 | 双向链表 |
| 范围查询 | 低效 | 极高效 |
| 磁盘利用率 | 一般 | 更高 |
✅ 数据库选择 B+ 树的根本原因:范围查询 + 顺序 IO
四、B+ 树为什么特别适合索引
1. 磁盘友好(页模型)
- 一个节点 ≈ 一个数据页(16KB)
- 一次 IO 读一整个节点
- 分支因子极大(几百)
百万级数据,树高通常 ≤ 3
2. 范围查询性能极佳
sql
WHERE id BETWEEN 100 AND 200- 定位到第一个叶子节点
- 沿着叶子链表顺序扫描
- 无回溯、顺序 IO
3. 排序天然有序
sql
ORDER BY id- 直接按叶子节点顺序读取
- 避免
filesort
五、B+ 树的基本操作流程
查找
- 从根节点开始
- 二分查找 key 区间
- 一路向下
- 命中叶子节点
插入
- 插入到叶子节点
- 节点满 → 分裂
- 中间 key 上推
- 可能级联到根
始终保持平衡
删除
- 删除 key
- 节点过少 → 向兄弟借
- 借不到 → 合并
- 可能向上调整
六、B+ 树在 MySQL InnoDB 中的真实形态
1. 聚簇索引(主键)
- 叶子节点 = 整行数据
- 数据物理顺序 ≈ 主键顺序
2. 二级索引
- 叶子节点 = 索引列 + 主键值
- 查询需要 回表
七、为什么不用 Hash / 跳表 / 红黑树
| 结构 | 问题 |
|---|---|
| Hash | ❌ 不支持范围查询 |
| 红黑树 | ❌ 树高太高 |
| 跳表 | ❌ 磁盘局部性差 |
| B+ 树 | ✅ 全面适合 |
八、一句话面试总结(背这个)
B+ 树是一种多路平衡搜索树,所有数据存储在叶子节点,叶子节点通过链表相连,极大降低树高和磁盘 IO 次数,特别适合范围查询和排序,因此成为数据库索引的标准实现。