目录
[二、Sklearn 决策树 API 全解析](#二、Sklearn 决策树 API 全解析)
[2.1 核心参数详解](#2.1 核心参数详解)
[2.2 常用方法](#2.2 常用方法)
[3.1 数据准备与模型构建](#3.1 数据准备与模型构建)
[3.2 模型评估](#3.2 模型评估)
[3.3 决策树可视化](#3.3 决策树可视化)
[3.4 结果分析](#3.4 结果分析)
决策树是机器学习中最经典、最易解释的算法之一,它既可以处理分类任务,也能解决回归问题。本文将结合 Sklearn 库的 API 详解与实战代码,带你全面掌握决策树的参数调优、模型构建与结果分析,从理论到实践吃透决策树算法。
一、决策树核心概念
决策树本质是一种递归分割特征空间的贪心算法,通过一系列 "if-then" 规则将数据划分成不同子集,最终形成树状结构:
- 根节点:包含全部样本的起始节点
- 内部节点:特征判断条件(分裂点)
- 叶子节点:最终预测结果(分类标签 / 回归数值)
- 剪枝:限制树的复杂度,避免过拟合(核心调优手段)
二、Sklearn 决策树 API 全解析
Sklearn 为决策树提供了两个核心类:DecisionTreeClassifier(分类树)和DecisionTreeRegressor(回归树),两者参数高度相似,仅核心评判指标不同。
2.1 核心参数详解
| 参数 | 分类树(DecisionTreeClassifier) | 回归树(DecisionTreeRegressor) | 实用调参建议 |
|---|---|---|---|
criterion |
分裂依据:gini(基尼系数,默认)/entropy(信息熵) |
分裂依据:mse(均方误差,默认)/mae(平均绝对误差) |
分类优先用gini(计算高效);回归优先用mse(对误差更敏感) |
splitter |
best(最优分裂点,默认)/random(随机分裂点) |
同分类树 | 优先用best;random多用于随机森林等集成模型 |
max_depth |
树的最大深度 | 同分类树 | 样本 / 特征多时常设 3-10;无限制易过拟合 |
min_samples_split |
内部节点分裂最小样本数(默认 2) | 同分类树 | 样本量极大时调大(如 5/10),避免过度分裂 |
min_samples_leaf |
叶子节点最少样本数(默认 1) | 同分类树 | 设为≥5 可避免单个样本的叶子节点,提升泛化能力 |
max_leaf_nodes |
最大叶子节点数(默认 None) | 同分类树 | 控制过拟合的高效手段,设值后max_depth失效 |
max_features |
分裂时考虑的最大特征数(默认 None = 全部) | 同分类树 | 特征数 < 50 时用默认值;特征多可设sqrt/log2 |
class_weight |
类别权重(处理样本不平衡) | 无此参数 | 样本不均衡时设balanced自动调整权重 |
random_state |
随机种子(保证结果可复现) | 同分类树 | 必设参数,建议固定为 42/0 等数值 |
2.2 常用方法
| 方法 | 功能 |
|---|---|
fit(X, y) |
训练模型 |
predict(X) |
预测结果(分类标签 / 回归数值) |
score(X, y) |
分类返回准确率;回归返回 R² 得分 |
get_depth() |
获取树的实际深度 |
get_n_leaves() |
获取叶子节点总数 |
apply(X) |
返回每个样本所属的叶子节点索引 |
plot_tree() |
可视化决策树结构 |
三、实战:电信客户流失预测(分类树)
以电信客户流失预测为例,完整演示分类决策树的构建、评估与可视化流程。
3.1 数据准备与模型构建
python
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn import metrics
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix
# 混淆矩阵可视化函数
def cm_plot(y, yp):
cm = confusion_matrix(y, yp)
plt.matshow(cm, cmap=plt.cm.Blues)
plt.colorbar()
# 标注混淆矩阵数值
for x in range(len(cm)):
for y_idx in range(len(cm)):
plt.annotate(cm[x, y_idx], xy=(y_idx, x),
horizontalalignment='center',
verticalalignment='center')
plt.ylabel('True label')
plt.xlabel('Predicted label')
return plt
# 1. 加载数据
datas = pd.read_excel("电信客户流失数据.xlsx")
data = datas.iloc[:, :-1] # 特征
target = datas.iloc[:, -1] # 目标变量(是否流失)
# 2. 划分训练集/测试集
data_train, data_test, target_train, target_test = train_test_split(
data, target, test_size=0.2, random_state=42
)
# 3. 初始化并训练决策树
dtr = DecisionTreeClassifier(
criterion='gini', # 基尼系数作为分裂依据
max_depth=8, # 限制树深度,避免过拟合
random_state=42 # 固定随机种子
)
dtr.fit(data_train, target_train)3.2 模型评估
python
# 4. 训练集预测与评估
train_pred = dtr.predict(data_train)
print("===== 训练集评估结果 =====")
print(metrics.classification_report(target_train, train_pred))
cm_plot(target_train, train_pred).show()
# 5. 测试集预测与评估
test_pred = dtr.predict(data_test)
print("\n===== 测试集评估结果 =====")
print(metrics.classification_report(target_test, test_pred))
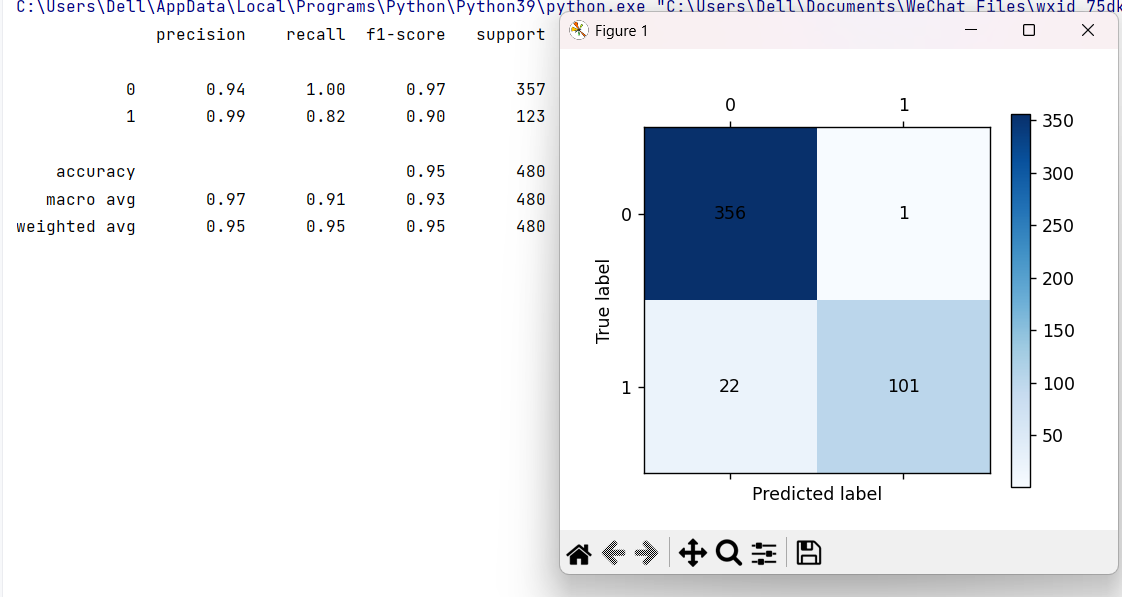
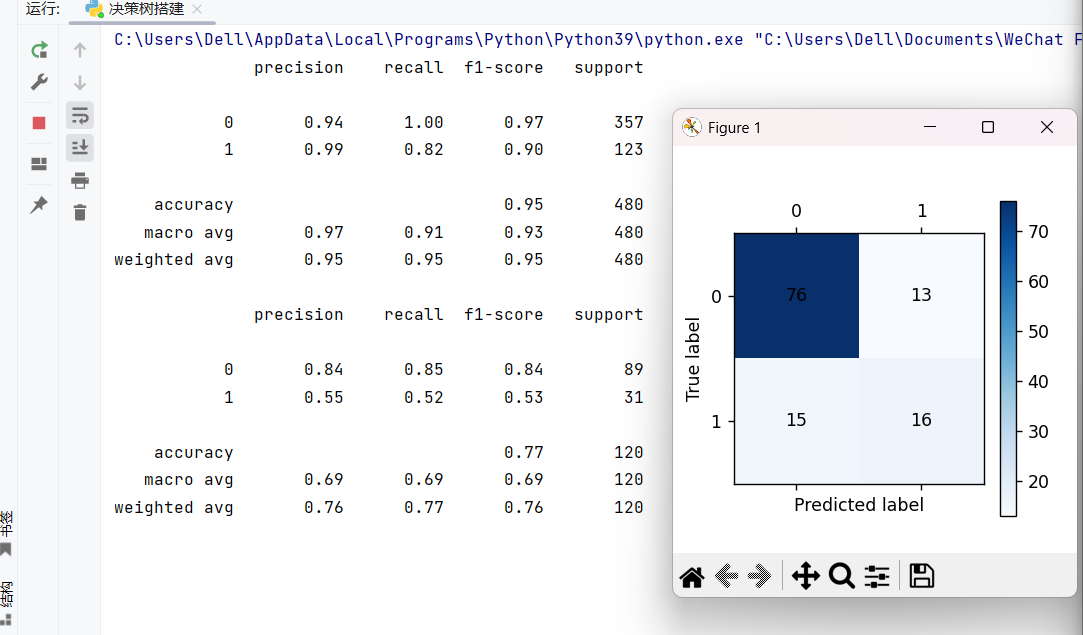
cm_plot(target_test, test_pred).show()运行结果:
3.3 决策树可视化
python
# 6. 可视化决策树结构
fig, ax = plt.subplots(figsize=(32, 32)) # 设置画布大小
plot_tree(dtr, filled=True, ax=ax, feature_names=data.columns)
plt.show()运行结果: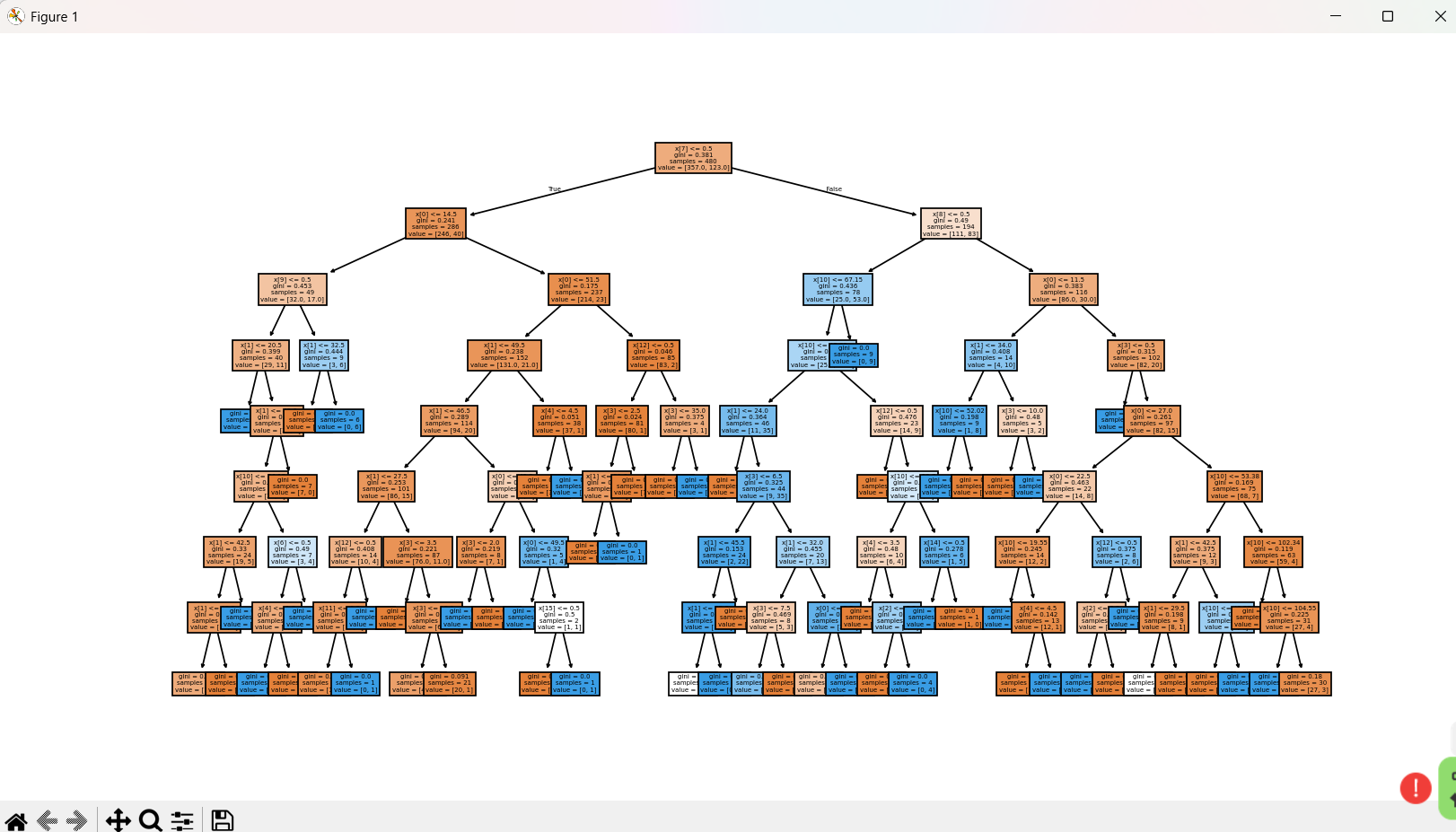
3.4 结果分析
- 分类报告 :重点关注
precision(精确率)、recall(召回率)、f1-score(综合得分),测试集得分若远低于训练集,说明模型过拟合; - 混淆矩阵:直观展示真实标签与预测标签的匹配情况,可清晰看到模型在 "流失 / 未流失" 类别上的误判数量;
- 树可视化:通过图形化展示决策规则,可分析哪些特征是客户流失的关键影响因素。
四、回归树实战要点
回归树与分类树的使用流程几乎一致,核心差异在于:
- 目标变量为连续值(如房价、销量);
- 评估指标用 MSE(均方误差)、MAE(平均绝对误差)或 R²(
score方法返回); - 核心参数调优逻辑与分类树一致,优先通过
max_depth/max_leaf_nodes控制过拟合。
python
# 回归树极简示例(糖尿病指标预测)
from sklearn.tree import DecisionTreeRegressor
from sklearn.datasets import load_diabetes
from sklearn.metrics import mean_squared_error
# 加载数据
data = load_diabetes()
X, y = data.data, data.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 训练回归树
reg_tree = DecisionTreeRegressor(
criterion='mse',
max_depth=5,
min_samples_leaf=3,
random_state=42
)
reg_tree.fit(X_train, y_train)
# 评估
y_pred = reg_tree.predict(X_test)
print(f"回归树MSE:{mean_squared_error(y_test, y_pred):.2f}")
print(f"回归树R²得分:{reg_tree.score(X_test, y_test):.2f}")五、决策树调优核心技巧
- 防止过拟合 :优先调小
max_depth、调大min_samples_leaf、设置max_leaf_nodes; - 样本不平衡 :分类树使用
class_weight='balanced'平衡类别权重; - 特征选择:先做特征筛选(如相关性分析),减少冗余特征,提升树的解释性;
- 交叉验证 :用
GridSearchCV自动调参,示例:
python
from sklearn.model_selection import GridSearchCV
# 定义参数网格
param_grid = {
'max_depth': [3, 5, 8],
'min_samples_leaf': [1, 3, 5],
'criterion': ['gini', 'entropy']
}
# 网格搜索
grid = GridSearchCV(DecisionTreeClassifier(random_state=42),
param_grid, cv=5)
grid.fit(data_train, target_train)
print(f"最优参数:{grid.best_params_}")
print(f"最优得分:{grid.best_score_:.2f}")六、总结
- 决策树的核心优势是解释性强 、无需特征归一化,适合业务规则挖掘;
- 分类树与回归树的参数高度通用,核心调参方向是限制树的复杂度以避免过拟合;
- 实战中需结合混淆矩阵(分类)/MSE(回归)、分类报告等指标综合评估模型;
- 单棵决策树性能有限,通常结合集成学习(随机森林、XGBoost)提升效果。