传统的检索增强生成(Retrieval-Augmented Generation,RAG)方法由于依赖固定数量的检索文档 而受到限制,往往会引入不完整或噪声较大的信息 ,从而削弱整体任务性能。尽管近期提出的一些自适应方法 在一定程度上缓解了这些问题,但其在复杂且真实世界的多模态任务中的应用仍然较为有限。
为此,我们提出了一种新的方法------自适应多模态检索增强生成(Self-adaptive Multimodal Retrieval-Augmented Generation,SAM-RAG) ,专门针对多模态场景进行设计。SAM-RAG 不仅能够根据输入查询动态筛选相关文档 (在需要时还会引入图像描述信息),还能够对检索到的文档质量以及最终生成结果进行验证。
大量实验结果表明,SAM-RAG 在检索准确率和回答生成质量 方面均优于现有的最新方法。通过进一步的消融实验与有效性分析,我们发现,SAM-RAG 在多模态 RAG 任务中,在保持高召回率的同时显著提升了整体任务性能 。相关代码已开源,地址为:
https://github.com/SAM-RAG/SAM_RAG
引言(Introduction)
近年来,大型语言模型(Large Language Models,LLMs)的快速发展显著推动了多项自然语言处理任务的性能提升(Manikandan et al., 2023;OpenAI et al., 2024;Ouyang et al., 2022;Touvron et al., 2023;Anil et al., 2023),其中包括问答任务(Tan et al., 2023)。此外,LLMs 也开始突破模态边界,在视觉理解(Pan et al., 2022)、代码生成(Wang et al., 2024)等多模态任务中展现出潜力。
然而,当前 LLM 仍面临诸多挑战,例如生成虚假信息(幻觉) (Li et al., 2022)以及知识更新困难 (Zhang et al., 2023),这些问题限制了其在更广泛实际场景中的应用。为应对上述挑战,检索增强生成(Retrieval-Augmented Generation,RAG) 方法被提出(Lewis et al., 2020)。RAG 的核心假设是:在语义空间中与查询相似的文档更有可能包含回答该查询所需的信息。通过利用 LLM 的上下文学习能力,RAG 能够基于语义相关文档生成更准确的回答,同时有效减少幻觉现象,并促进知识获取(Li et al., 2024)。
随着 RAG 技术的发展,其应用逐渐扩展至多模态领域,并在文本(Wu et al., 2024)、图像(Pan et al., 2022)等任务中取得进展。图 1 给出了一个多模态 RAG 任务示例,其中部分问题依赖视觉信息,仅使用文本检索无法完成回答,需要对视觉上下文进行检索与推理。
尽管 RAG 具有显著优势,但其仍面临重要挑战,尤其体现在适应性不足 方面(Zhao et al., 2024)。RAG 通常依赖于固定数量的检索文档 ,这容易导致关键信息遗漏或引入过多噪声,从而对性能产生负面影响。此外,RAG 缺乏对生成结果进行有效验证 的机制。为解决这些问题,研究者提出了自适应 RAG 框架 ,能够根据具体任务需求动态调整检索策略,在多项任务中显著提升 RAG 性能。然而,针对多模态场景的自适应 RAG 研究仍然较为有限。
为此,我们提出了 Self-Adaptive Multimodal Retrieval-Augmented Generation(SAM-RAG) ,这是首个具备主动选择相关数据并能够自我评估生成结果的自适应多模态 RAG 框架。通过将先进模型的知识蒸馏至一个更小规模的多模态 LLM,我们在保证效率的同时实现了卓越的多模态任务性能。
SAM-RAG 定义了三个核心判别标准:相关性(relevance) 、可用性(usefulness) 和 支持性(support)。在处理查询的过程中,SAM-RAG 会对每一组检索结果进行独立评估,在检索之后识别与查询相关的数据;随后基于这些相关上下文生成初步回答,并评估各上下文对回答生成的贡献;最终,框架会对查询、上下文和生成的回答进行全面验证。该流程确保生成的答案能够被所提供的上下文充分支撑,从而显著降低幻觉发生的概率。
我们设计了一系列实验并引入多种基线方法来评估所提出的框架。实验结果表明,SAM-RAG 在多模态 RAG 任务中显著优于包括 MuRAG (Chen et al., 2022)在内的现有最先进方法以及其他基线模型,充分展示了其在多模态检索与生成方面的强大能力。消融实验验证了三种验证机制的合理性与有效性,而检索效果分析进一步强调了动态检索在性能提升中的关键作用。此外,案例分析通过具体示例展示了各验证机制如何单独及协同提升检索准确率和回答生成质量。
SAM-RAG 框架将动态检索、相关性验证以及多阶段答案验证有机结合,以优化多模态任务性能,在最小化幻觉的同时确保生成答案的准确性与可支撑性。整体流程涵盖模态对齐、文档检索,以及针对相关性、可用性和支持性的迭代验证,从而同时提升输出质量与模型鲁棒性。
2 相关工作(Related Works)
2.1 检索增强生成(Retrieval-Augmented Generation)
检索增强生成(RAG)通过向语言模型引入外部知识,显著提升了生成结果的相关性与准确性。早期研究主要集中于文本模态 。例如,Re2G(Glass et al., 2022)结合了 BM25 与深度学习检索方法;UPRISE(Cheng et al., 2023)引入了提示检索器(prompt retriever),以增强大语言模型的零样本能力;QOQA(Koo et al., 2024)则通过**查询重写(query regeneration)**来提升检索性能。
然而,这些方法普遍依赖于固定数量的检索结果 ,从而限制了其对具体任务的适应性。SAM-RAG 通过采用自适应检索机制克服了这一局限性,能够对召回文档进行动态评估,从而提升回答生成质量。
2.2 多模态检索增强生成(Multimodal Retrieval-Augmented Generation)
RAG 研究中的一个重要方向是多模态场景,即融合文本(Wu et al., 2024)、图像(Pan et al., 2022)、表格(Dong et al., 2024)以及音频(Xu et al., 2019)等多种数据形式,其中**视觉问答(VQA)**是一个核心研究任务(Ishmam et al., 2024)。
多模态 RAG 与纯文本 RAG 的主要区别在于:前者需要将不同模态统一到同一表示空间 中,这一过程通常被称为模态对齐(modality alignment)。当前的大语言模型由于利用了大规模互联网语料进行训练,在推理、分析与生成能力方面表现尤为突出,且在这些任务上往往优于视觉等其他模态(Jin et al., 2024)。因此,多模态 RAG 中的一种常见做法是通过**模态转换器(modality converter)**将非文本模态转化为文本表示,从而充分发挥 LLM 在文本处理方面的优势(Zhao et al., 2023)。
例如,RA-VQA(Lin and Byrne, 2022)利用目标检测从图像中生成多种文本描述,并将其用于标准 RAG 流程;而 MMHQA-ICL(Liu et al., 2023)和 UniMMQA(Luo et al., 2023)则融合文本、表格和视觉信息,使其能够适配基于文本的 RAG 技术。本文主要关注文本与图像两种模态,并在此基础上融合上述方法,以高效提取图像中的关键信息。
2.3 自适应检索增强生成(Adaptive Retrieval-Augmented Generation)
检索质量对 RAG 的整体性能具有决定性影响,因为无关或错误的文档 往往会导致模型产生"幻觉"(Huang et al., 2023b)。传统 RAG 框架依赖固定数量的检索文档,这不仅可能遗漏关键信息,也容易引入无关内容。此外,传统 RAG 还缺乏对生成答案的验证机制。
为此,自适应 RAG 框架被提出。例如,Self-Improve(Huang et al., 2023a)和 Self-Refine(Madaan et al., 2023)通过反馈循环机制 对模型错误进行修正;Self-Correction(Welleck et al., 2023)与 Self-Reasoning(Xia et al., 2024)进一步通过推理过程来提升检索质量;Self-RAG(Asai et al., 2024)则引入按需检索(on-demand retrieval)与反思机制(reflection),显著增强了模型的适应性。
SAM-RAG 在上述研究基础上进一步拓展,将主动筛选(active screening)与反思机制 引入到多模态领域中,构建了更加动态的检索流程,从而推动了多模态 RAG 方法的发展。
3.1 任务定义(Task Definition)
形式化地,RAG 任务首先使用检索器 RRR 从文档集合
D={d1,d2,...,dn}D = \{d_1, d_2, \ldots, d_n\}D={d1,d2,...,dn}
构建检索数据库。对于查询集合
Q={q1,q2,...,qm},Q = \{q_1, q_2, \ldots, q_m\},Q={q1,q2,...,qm},
检索器 RRR 会为每个查询 qqq 识别一个相关文档子集
Drel={d1,d2,...,dk},D_{\text{rel}} = \{d_1, d_2, \ldots, d_k\},Drel={d1,d2,...,dk},
并基于该文档集合生成一个由 sss 个 token 组成的答案序列
A=a1,...,as。A = a_1, \\ldots, a_s。A=a1,...,as。
其中,k(k<n)k (k < n)k(k<n) 通常是一个预先设定的检索数量。
在多模态 RAG 任务 中,整体流程通常包括以下步骤:
首先,模态转换器 PPP 将其他模态的信息转换为语言模型 LLL 可理解的格式,并与文本数据进行融合以便检索;
其次,对于每个查询 qqq,检索器 RRR 识别相关信息集合 DrelD_{\text{rel}}Drel;
最后,语言模型 LLL 基于检索到的信息生成一个由 sss 个 token 组成的回答 a1,...,asa_1, \\ldots, a_sa1,...,as。
在实际系统中,模块 PPP 与 LLL 往往被整合为一个统一模块 MMM,以简化整体流程。
3.2 嵌入模型(Embedding Model)
在 RAG 框架中,检索结果的质量对整体性能至关重要(Salemi and Zamani, 2024)。为了提升检索器 RRR 的召回能力,我们通过**对比学习(contrastive learning)**来优化其表示能力。
对于给定查询 qqq,能够支持标准答案的文档构成正样本集合 DposD_{\text{pos}}Dpos,从而形成正样本查询--文档对 (Q,Dpos)(Q, D_{\text{pos}})(Q,Dpos)。其余文档则构成负样本集合 DnegD_{\text{neg}}Dneg。
我们采用 Dense Passage Retrieval(DPR) (Karpukhin et al., 2020)对负样本集合 DnegD_{\text{neg}}Dneg 进行排序,并从排名前 50 的文档中随机选取 10 个作为负样本,构建负样本查询--文档对 (Q,Dneg)(Q, D_{\text{neg}})(Q,Dneg)。最终,我们构建了一个约 24 万条样本的数据集,其中每个查询对应一个正样本文档 dposd_{\text{pos}}dpos 和一个负样本文档 dnegd_{\text{neg}}dneg,用于对检索器 RRR 进行微调。
我们使用 InfoNCE 损失函数(He et al., 2020)来优化检索器性能,其形式如公式(1)所示。其中,DposD_{\text{pos}}Dpos 表示支持答案的文档集合,τ\tauτ 为温度超参数。目标是最小化正负样本之间的损失 ℓ\ellℓ。
ℓ=−logexp(Q⋅Dpos/τ)∑exp(Q⋅D/τ)(1)\ell = -\log \frac{\exp(Q \cdot D_{\text{pos}} / \tau)}{\sum \exp(Q \cdot D / \tau)} \tag{1}ℓ=−log∑exp(Q⋅D/τ)exp(Q⋅Dpos/τ)(1)
3.3 多模态知识蒸馏(Multimodal Knowledge Distillation)
知识蒸馏是一种将高性能模型(教师模型)的知识迁移到结构更简单模型(学生模型)中的方法,能够在降低模型复杂度的同时提升其性能(Yang et al., 2024)。在大语言模型中,该技术已被证明可以有效地将大模型的能力迁移至小模型(Jin et al., 2024;Gu et al., 2024;Li et al., 2023)。
在本研究中,我们使用 GPT(记为 GGG) 生成指令微调数据,以提升本地多模态模型 MMM 的性能(Peng et al., 2023),并增强其推理与生成能力。通过引入思维链推理(Chain-of-Thought, CoT)(Wei et al., 2022),我们保留了模型 GGG 的完整推理过程,用于高效的模型蒸馏。
模型蒸馏的数据构建流程如下:
首先,针对查询--图像对 {q,dpos}\{q, d_{\text{pos}}\}{q,dpos},由模型 GGG 生成与查询相关的图像描述 DscD_{\text{sc}}Dsc,并仅保留生成答案 AAA 与标准答案一致 的推理过程。
随后,基于查询--文档对 {q,d∣d∈Dsc,Dt}\{q, d \mid d \in D_{\text{sc}}, D_t\}{q,d∣d∈Dsc,Dt} 推断相关性标记 isRel ,并保留推断结果为 True 的推理过程。
为提升效率,负样本集合 DnegD_{\text{neg}}Dneg 先通过 DPR 进行排序,并从相似度最高的前 10 个文档中随机选取与正样本数量相同的文档进行推理;其中 isRel = False 的推理过程被保留。
接着,从筛选后的 DposD_{\text{pos}}Dpos 中生成粗粒度答案 AAA,并仅保留结论与标准答案一致的推理过程。随后,基于集合
{q,d,A∣d∈{Dsc,Dt}}\{q, d, A \mid d \in \{D_{\text{sc}}, D_t\}\}{q,d,A∣d∈{Dsc,Dt}}
推断 isUse = ?(是否有用)。与 isRel 相同,保留推断结果一致的正负样本推理过程。
最后,推断 isSup = ? (是否支持)。对于负样本,保留 isSup = False 的推理过程;而对于正样本,则保留推断结果为 True 或 Partial 的推理过程。
3.4 SAM-RAG 框架
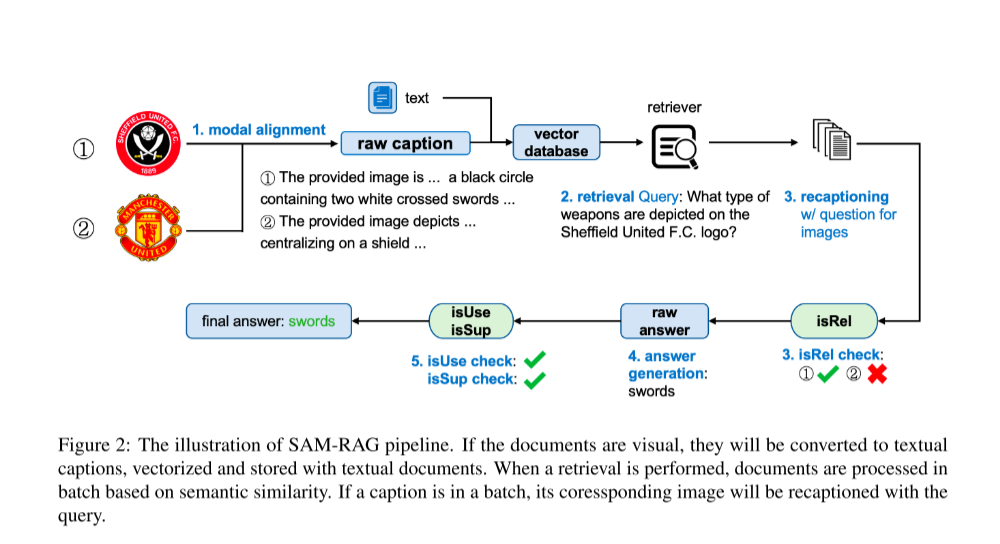
如图 2 所示,下面对 SAM-RAG 框架的各个组成部分进行说明。多模态 RAG 任务的整体执行流程被划分为 五个阶段 :
1)模态对齐(Modality Alignment) ,
2)文档检索(Document Retrieval) ,
3)相关性验证(Relevance Verification) ,
4)答案生成(Answer Generation) ,以及
5)答案验证(Answer Verification)。
首先,将整个文档语料库中的图像信息对齐到文本模态 。在接收到查询之后,系统执行文档检索操作。随后,对检索到的结果按照相似度进行排序,并逐条评估其与查询的相关性,仅保留与查询高度相关的结果。基于这些相关文档,框架生成答案 AAA。随后对生成答案的有效性进行验证;若验证通过,则返回该答案并结束检索流程。
该方法的核心创新点 在于引入了 三种关键的验证机制,其具体定义见表 1。所使用的提示词(prompts)列于附录 B。
3.4.1 模态对齐(Modality Alignment)
首先,使用 GPT(记为 GGG)为图像生成原始描述(raw captions) drcd_{rc}drc。这些描述不针对具体查询进行定制,而是在图像标题等约束条件下生成。
由于原始描述并非面向特定查询,drcd_{rc}drc 可能会遗漏与查询高度相关的关键信息。因此,drcd_{rc}drc 仅用于索引构建和相似度计算,而不直接用于答案生成。
随后,将生成的图像描述集合 DrcD_{rc}Drc 与原始文本文档集合 DtD_tDt 一并输入嵌入模型 RRR 进行向量化表示,为后续的查询检索阶段做准备。
3.4.2 文档检索(Document Retrieval)
对于给定查询 qqq,使用 Dense Passage Retrieval(DPR) (Karpukhin et al., 2020)对文档语料库 DDD 进行打分,并根据相似度得分从高到低排序,以供下一阶段处理。

3.4.3 相关性验证(Relevance Verification)
为跟踪检索状态,首先将标志位 FFF 初始化为 False ,并创建一个存储空间 CCC 用于保存相关信息。检索到的文档以批次(batch)形式进行处理:对于每一篇检索到的文本文档 dtd_tdt,直接通过相关性验证模块 isRel 来判断其与查询的相关性(参见图 2 与表 1 第一行)。
若检索到的是图像 did_idi,则根据查询生成一个查询相关的图像描述 dscd_{sc}dsc,并据此评估其相关性。当 isRel = True 时,将对应的相关信息存入 CCC,并将标志位 FFF 更新为 True。
在处理完一个批次后,若 isRel = False,则继续处理下一个批次;否则,暂停检索流程并进入下一阶段。
3.4.4 答案生成(Answer Generation)
在上一阶段生成的上下文集合 CCC 与查询 qqq 一并输入模型 MMM,通过自回归生成方式 产生一个初步答案(coarse answer) AAA。随后,对生成的答案 AAA 进行验证,以评估其相关性与支撑性。
3.4.5 答案验证(Answer Verification)
在该阶段,引入 isUse 验证过程(参见图 2 与表 1 第二行),用于判断生成的答案 AAA 是否有效地回应了查询 。若 isUse = True ,则进一步使用 isSup(参见图 2 与表 1 第三行)评估答案 AAA 是否得到了上下文 CCC 的充分支撑;否则,将基于 CCC 重新生成答案 AAA。
isSup 的目标是确认答案 AAA 是否由 CCC 中的证据充分支持,从而避免答案缺乏来自 DrelD_{rel}Drel 的依据。
-
若 isSup = True,说明 AAA 满足任务要求,直接返回 AAA,并结束检索流程;
-
若 isSup = False,表示 AAA 未得到 CCC 的支持,此时将 CCC 与 FFF 同时重置,并返回到第一阶段重新进行检索;
-
若 isSup = Partial,则说明支撑信息不完整,系统会保留 CCC,但重置 FFF,并返回第一阶段继续检索。
该阶段的核心目标是确保最终输出符合任务需求 ,并最大限度降低潜在幻觉(hallucination)的风险。
通过上述设计,SAM-RAG 在保证高效检索的同时,有效降低了生成误导性答案的风险,从而确保最终输出结果的质量。为进一步提升模型的稳定性与结果的可靠性,我们在每一个验证过程以及答案生成阶段 均引入了 思维链(Chain-of-Thought)方法 (Wei et al., 2022)。此外,还可以结合 自一致性策略(self-consistency)(Wang et al., 2023)以进一步增强系统的鲁棒性。
4 实验(Experiments)
4.1 数据集(Dataset)
在本研究中,我们采用 MultimodalQA 数据集 (Talmor et al.)作为基准,用于评估 SAM-RAG 框架 的性能。该数据集包含多模态问答样本,涵盖文本、图像以及表格等多种模态信息。
为确保与当前主流多模态 RAG 模型 MuRAG (Chen et al., 2022)之间的公平比较,实验中仅使用 MultimodalQA 数据集中的 TextQ 与 ImageQ 两类问题,以避免不同问题类型带来的干扰。
4.2 评价指标(Metrics)
我们采用 F1 分数 和 Exact Match(EM) 指标(Rajpurkar et al., 2016)来评估生成答案的质量。此外,为了评估检索阶段的性能,还引入了以下两种检索指标:
-
Recall@N(定义见公式 2):用于衡量在前 NNN 个检索结果中是否覆盖了正确的相关文档;
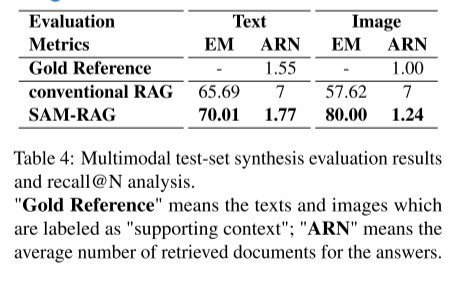
-
平均检索数量(Average Retrieval Number, ARN) :这是本文提出的一项新指标,用于衡量在生成最终答案过程中,系统平均检索的文档数量。
ARN 能够更细粒度地反映 SAM-RAG 在检索效率方面的表现,从而对其动态检索能力进行更加全面的评估。
4.3 实验设置(Experimental Settings)
实验设置包括对嵌入模型 RRR 与 视觉语言模型 MMM 的微调,以及在生成与推理阶段使用 MMM 或 GGG 进行推理。所有微调实验均在一张 NVIDIA A100 80GB GPU 上完成,服务器操作系统为 Ubuntu Server 20.04 LTS。
对于嵌入模型,我们采用 bge-base-en-v1.5 (Xiao et al., 2024),并基于 FlagEmbedding 框架 (Xiao et al., 2023)进行微调。主要超参数设置如下:学习率为 1e−5 ,训练 5 个 epoch ,批大小为 64。
视觉语言模型 MMM 选用 LLaVA-v1.5-7B (Liu et al., 2024),并通过 LLaMA-Factory 框架 (Zheng et al., 2024)结合 LoRA (Hu et al., 2022)进行参数高效微调。其训练配置包括:学习率 1e−4 ,训练 5 个 epoch ,批大小为 1 ,梯度累积步数为 8 ,优化器采用 AdamW(Loshchilov, 2017)。
在数据生成与推理阶段,使用模型 GGG (GPT-4o-2024-05-13),并将温度参数设为 1.2 以增强生成结果的多样性。该模型同时用于微调 MMM 以及执行推理任务。
相关资源链接如下:
-
bge-base-en-v1.5:https://huggingface.co/BAAI/bge-base-en-v1.5
-
FlagEmbedding:https://github.com/FlagOpen/FlagEmbedding
-
LLaVA-v1.5-7B:https://huggingface.co/llava-hf/llava-1.5-7b-hf
-
LLaMA-Factory:https://github.com/hiyouga/LLaMA-Factory
4.4 主要实验结果(Main Results)
实验结果汇总于表 2。结果表明,SAM-RAG 在所有评测任务中均取得了最优性能 ,显著优于包括当前最先进方法 MuRAG 在内的各类基线模型。下面对主要结果进行详细分析。
1. 整体性能分析
在文本任务与图像任务中,SAM-RAG 在 F1 与 EM 指标上均明显优于所有基线方法 。这一结果验证了其动态检索与生成机制 的有效性。SAM-RAG 中的关键组件 isRel、isUse 与 isSup 的作用将在消融实验(4.5 节)中进一步分析,并通过案例研究(4.7 节,图 4)进行直观展示,更多案例见附录 A。
2. 与基线方法的性能对比
表 2(上半部分)显示,对检索模型 RRR 或视觉语言模型 MMM 进行微调均可提升多模态 RAG 的性能,但微调 MMM 所带来的性能提升更为显著。这表明,基线检索模型 RRR 本身已较为充分优化,因此其微调带来的增益相对有限;相比之下,对 MMM 的优化能够直接增强模型对多模态信息的理解与处理能力。
值得注意的是,尽管在训练数据规模上存在差异,微调后的传统 RAG(R\*+M\*R^\* + M^\*R\*+M\*)性能仍略低于 MuRAG,进一步凸显了 SAM-RAG 结构性设计的优势。
3. SAM-RAG 与传统 RAG 的对比
如表 2(中部)所示,SAM-RAG 在所有设置下均稳定优于传统 RAG 方法。通过动态检索直到找到相关信息,SAM-RAG 有效规避了固定检索数量策略所带来的局限。
微调检索模型 RRR 虽然能够加快文档检索速度,但对整体性能提升影响有限;SAM-RAG 的核心优势主要来源于对微调后的 MMM 的有效利用。实验结果表明,在 SAM-RAG 框架中,微调 MMM 能带来最显著的性能提升,尤其是在多模态任务场景下。
4. GPT 集成效果分析
表 2(下半部分)展示了在 SAM-RAG 与传统 RAG 框架中引入 GGG 后带来的显著性能提升。集成 GGG 的模型在所有配置下均优于未集成的模型,凸显了 GGG 在推理能力与语义理解方面的优势。
其中,SAM-RAG 与 GGG 结合的配置取得了最为显著的性能提升,尤其是在视觉任务中,其表现甚至超过了文本任务。这表明,当与 GGG 结合时,SAM-RAG 能够比其他方法更深入地理解和利用视觉信息。
4.5 Ablation Study
4.5 消融实验
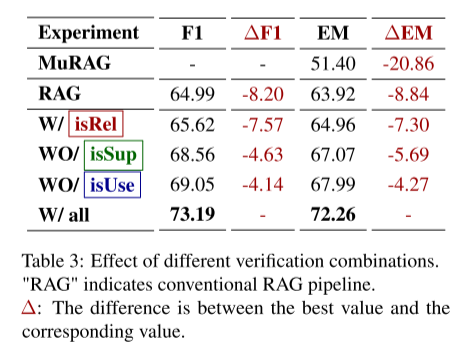
为验证 SAM-RAG 各个组件的有效性 ,作者进行了系统性的消融实验,逐一移除框架中的不同组件,并评估其性能变化,实验结果如 表 3 所示。
结果表明,与传统 RAG 相比,引入不同类型的验证机制 ,尤其是 isRel 和 isSup ,在 F1 和 EM 两个指标上都带来了显著提升。具体而言:
-
仅引入 isRel(相关性验证) 时,性能提升较为有限;
-
随着 isUse(可用性验证) 和 isSup(支持性验证) 的进一步引入,性能提升幅度明显增大;
-
当 三种验证机制全部启用(标记为 "with all") 时,EM 分数达到最高值 ,相比 MuRAG 的性能提升 超过 20%。
这一结果表明,同时考虑:
-
相关性(isRel)
-
支持性(isSup)
-
可用性(isUse)
可以帮助模型在生成答案前 有效筛选最有价值的信息,从而显著提升生成结果的质量。
此外,即使 仅引入单一验证机制 ,模型的 EM 分数也会有所提升 ,说明每一种验证标准都在优化过程中发挥了独立且互补的作用 。然而,实验结果清楚地显示,当多种验证机制联合使用时,性能提升最为显著。
这进一步说明,将多种验证机制进行集成,能够对 信息检索与生成过程进行更全面的优化,有效降低无关或低质量信息对最终答案的负面影响。
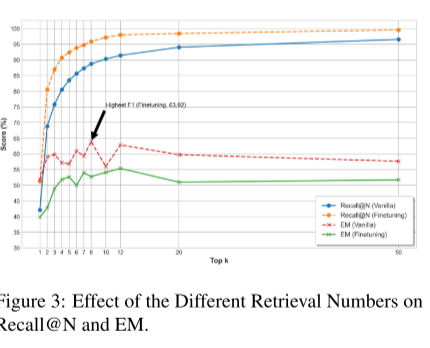
4.6检索有效性分析(Retrieval Effectiveness)
为评估检索效果,我们分析了性能最优的 SAM-RAG 与传统 RAG 模型,结果如图 3 和表 4 所示。实验结果表明,在所有 top-k 取值下,微调后的检索模型 R∗ 在 Recall@N 指标上始终优于未微调的 R ,说明对嵌入模型进行微调能够提升相关上下文的检索能力。表 2 进一步显示,使用 R∗ 时的 EM 分数整体高于使用 R 的情况。
值得注意的是,在 top-k = 8 时,R∗ 的 EM 分数比 R 的所有结果高出近 20% ,这表明微调后的检索模型在中等数量的检索结果下收益最大,而过多的检索可能会引入噪声。与传统 RAG 不同,后者往往检索到超出实际需求数量的文档,从而引入无关内容;SAM-RAG 的检索数量与 "Gold Reference" 更加接近,并且在文本和图像检索任务中都获得了更高的 EM 分数。
这些结果表明,SAM-RAG 能够在有效检索相关信息的同时减少噪声,从而生成更加准确、高质量的输出结果。