文章目录
初识分布式系统和redis
本篇文章的主要任务分为以下两点:
- 对分布式系统有初步认识
- 了解redis的特性和作用
在这篇文章:
我们将能初步理解到系统架构的推演,以及redis的作用及使用原因!
redis背景
首先需要了解:
- redis是什么?
- 为什么要使用redis?
- redis能解决什么问题?
我们来看官方对于redis的说明:
The open Source, in-memory data store used by millions of developers as a database, cache, streaming engines, and message broker.
在最初:redis就是希望能够作为一个"消息中间件「消息队列」",这是分布式系统(后续详细了解)
消息队列是分布式系统下常用的一个「生产者消费者模型」
除此之外:redis还常常被用作数据库,缓存,流式处理引擎等...
当然,redis最出名的是:
在分布式系统中,使用内存充当数据库,这是它被最为广泛使用的场景,这与它的初心是"违背"的。
但是我们也知道:我们常用的数据库像是mysql,功能已经非常强大了,为什么还要使用redis呢?
首先:我们需要明白,二者的使用方式是不太一样的
mysql是典型的关系型数据库,它的数据存储的位置是磁盘等外设中
redis的存储的数据主要是在内存中,主要是通过键值对存储的方式存储,是非关系型的
这就一定导致 👉 redis的访问速度比mysql快得多,但是存储的空间却是有限的
mysql的优点是:生态完善,功能齐全,但是访问速度可能比较慢,存储量大
redis的优点是:存储于内存中,读取速度快
所以,在比较大型的产品中,为了保证性能和空间的都能兼顾,常常将mysql和redis联用:
这是符合计算机的二八定律的:即「20%的热点数据能够满足80%的访问需求」
这里还需要特别说明的是:
redis常在分布式系统下进行使用,如果只是一个单机程序,那么使用redis还不如直接在本地操变量,这样效率远远高于在单机程序上引入redis
redis在分布式系统中:
可以通过「网络」作为载体,将自己内存中的变量交给其他网络进程,甚至让别的主机直接使用
这一点是在多主机通信下非常强劲的功能,这一点我们先了解即可
系统架构的推演过程
首先先表明分布式系统的本质是:
当单机性能 、容量 、可用性 无法满足业务需求时,将系统拆分为多个独立进程 / 服务 ,部署在多台物理 / 虚拟主机 上,通过网络 协同工作,对外表现为一个整体系统
一句话总结就是:分布式系统 = 多机协同 + 网络通信 + 解决单机瓶颈
单机架构
一般来说,使用单机架构就足够做一个小型的服务器了:
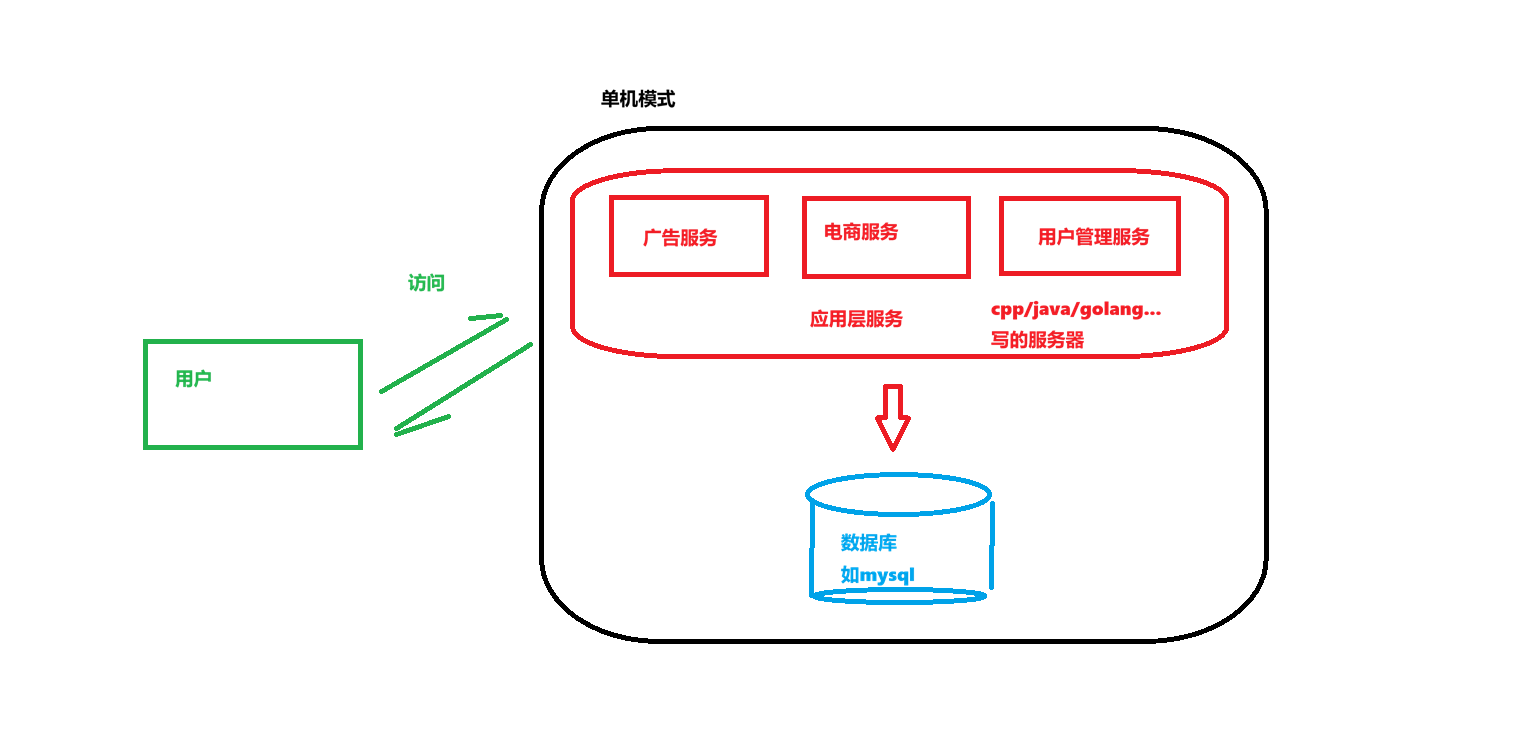
由上面可以看出,这一台单体架构的服务器:
既要负责客户端的连接处理,还得负责业务处理,还要操作数据库
当然,对于访问量不高的情况下,这样做是绝对可以的,也推荐这么做。
因为这种使用量不高,开发和维护的人员肯定不多,所以就怎么简单怎么来。
但是,一台主机的资源是有限的:
这里的资源特指:
CPU、内存、硬盘、网络、使用权等...
当访问量越来越多的时候,一台主机做全部事情肯定是不现实的。
在数以万计的访问量下肯定是处理不过来的,所以此时就得考虑一些办法去进行处理。
对于性能的提升方法,一般就是两种:「开源」&& 「节流」
开源:就是直接暴力的堆叠硬件资源:比如增加内存,增加硬盘,显卡
节流:在软件上优化,通过性能测试,对症下药,这种要求是比较高的
但是,一台主机的资源扩展能力也是有限的,所以在极端情况下,仅仅开源节流肯定是不够
所以,这就引出了「分布式系统」的概念了,即引入多台主机,合理涉及架构!
BUT:
并不是一昧的引入分布式就好的,引入分布式是迫不得已做的事情
因为分布式架构需要设计到多台主机间的通信、协作、业务处理的配合等...
那么环节一多,主机数量大,那么引发bug的概率也是蛮大的,所以并不是说分布式系统一定好的!
应用服务和数据存储分离
所以,我们可以考虑:
既然数据库的读取操作是比较慢的,比较耗时,那么可以考虑把这一项任务"外包"出去
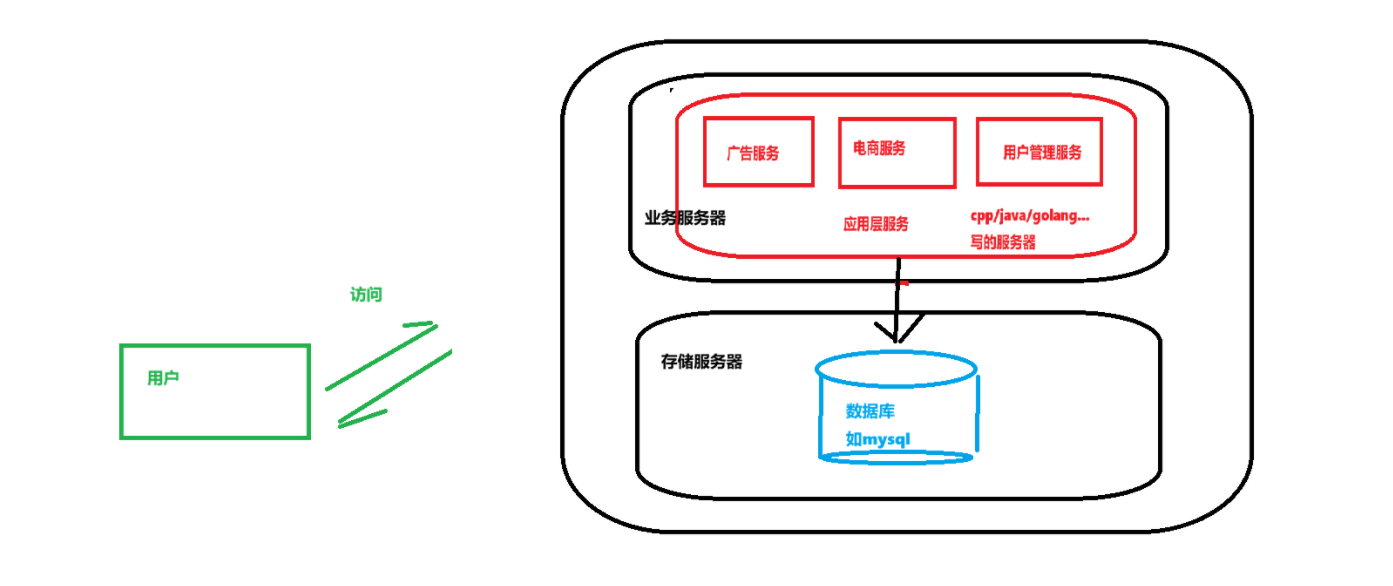
此时,在外部看来,访问的依旧是服务器这个整体
但是在内部,其实整个系统是由两台主机构成的:一台专门做业务处理,一个做存储处理
两者相互配合,共同对外进行服务
这样的系统效率还是比较高的:
因为业务服务器比较吃CPU和内存的资源
而数据存储吃硬盘/磁盘的资源SSD可以提供极大存储量
二者相互配合,可以使得访问数据的速度加快的同时,加快业务处理的速度
多台主机负载均衡
在面对极高并发量的时候,上述的架构肯定是顶不住的
因为一台主机能够处理的连接是有限的,短时间内能够处理的业务也是有限的!
所以,此时为了能够提高并发量,需要再次升级架构:
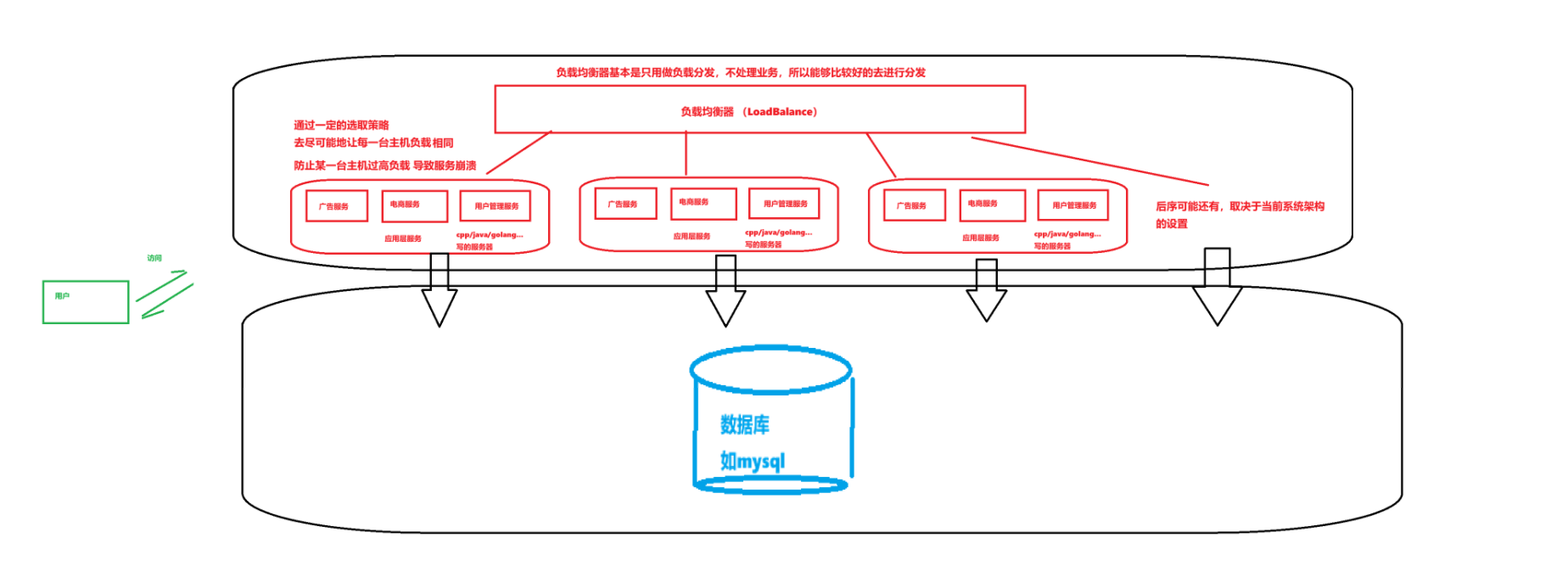
可以考虑把处理服务的主机进行分布排放,然后等待一个主代理器,进行服务的分发
然后这多台主机等待分发到的资源/连接/指令进行操作
这就有点像是「多线程」的操作,所以必须要保证每个主机处理业务时的并发数据安全
否则业务处理的逻辑会混乱,导致整个服务系统运行不稳定,甚至是服务崩溃!
而负载均衡器因为不会真正处理业务,只做分发负载的操作,所以承受的量肯定是更大的
如果还是撑不住,那就多引入一层负载均衡器,让一级负载均衡分发到二级,二级再分发给主机
读写分离
负载均衡模式下,对于处理业务的效率已经是很高的了,很难再从这个位置下手了
现在阻挡着整个系统运行效率的就是:对于数据的读取和写入太慢了!
一方面是要各个主机之间互斥,一方面是在处理大量数据的情况下,数据库的访问也会慢
所以,这么多主机就这么同时操作一个数据库,肯定是会出问题的!
而在实际的应用场景下,读取数据是要比写数据频率高的
所以我们可以考虑把数据库的读操作和写操作进行分离,数据库之间定时做同步操作即可:
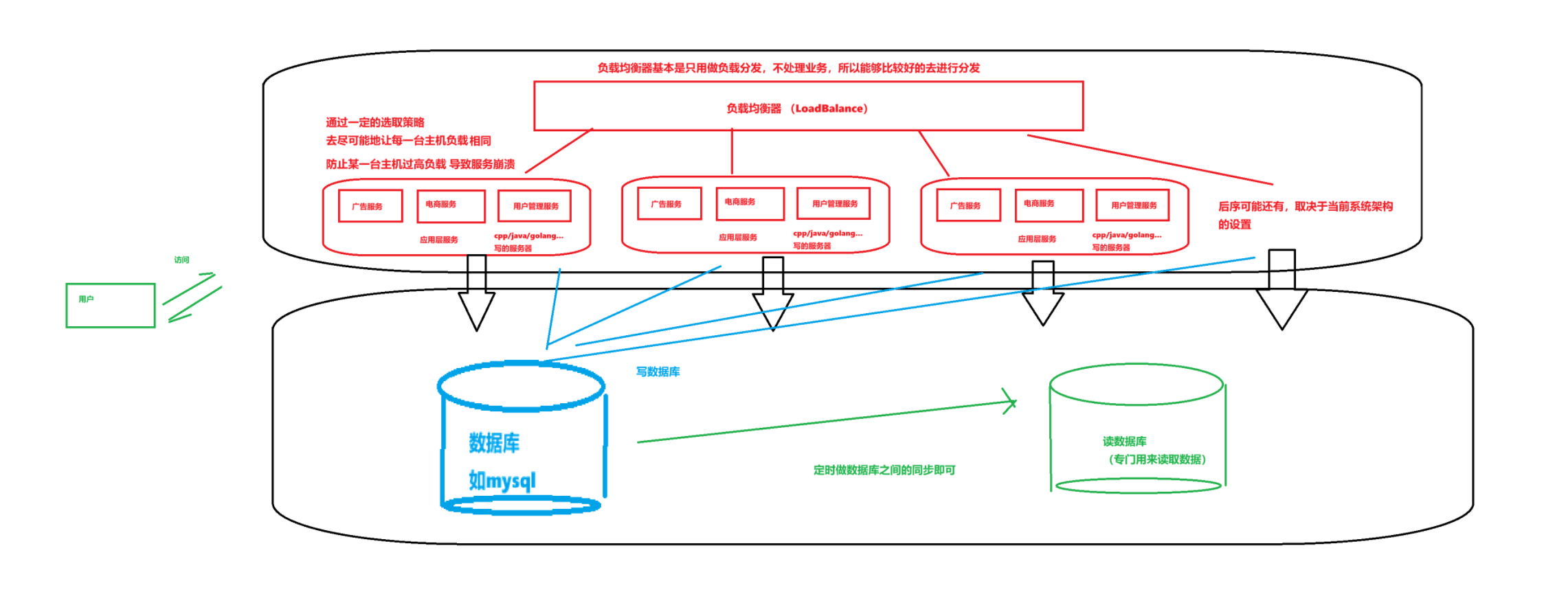
只不过是需要注意:
因为同步数据路和读取必然存在时间差,所以得规定一下二者的顺序:
比如是否支持读的同时看得到对方的修改,这一点参考MySQL的MVCC机制
数据冷热处理
数据库这一块其实还可以进行提升,有一些数据是经常被访问到的:
所以可以考虑把经常读取的数据存放在一个缓存中!方便进行快速筛查:
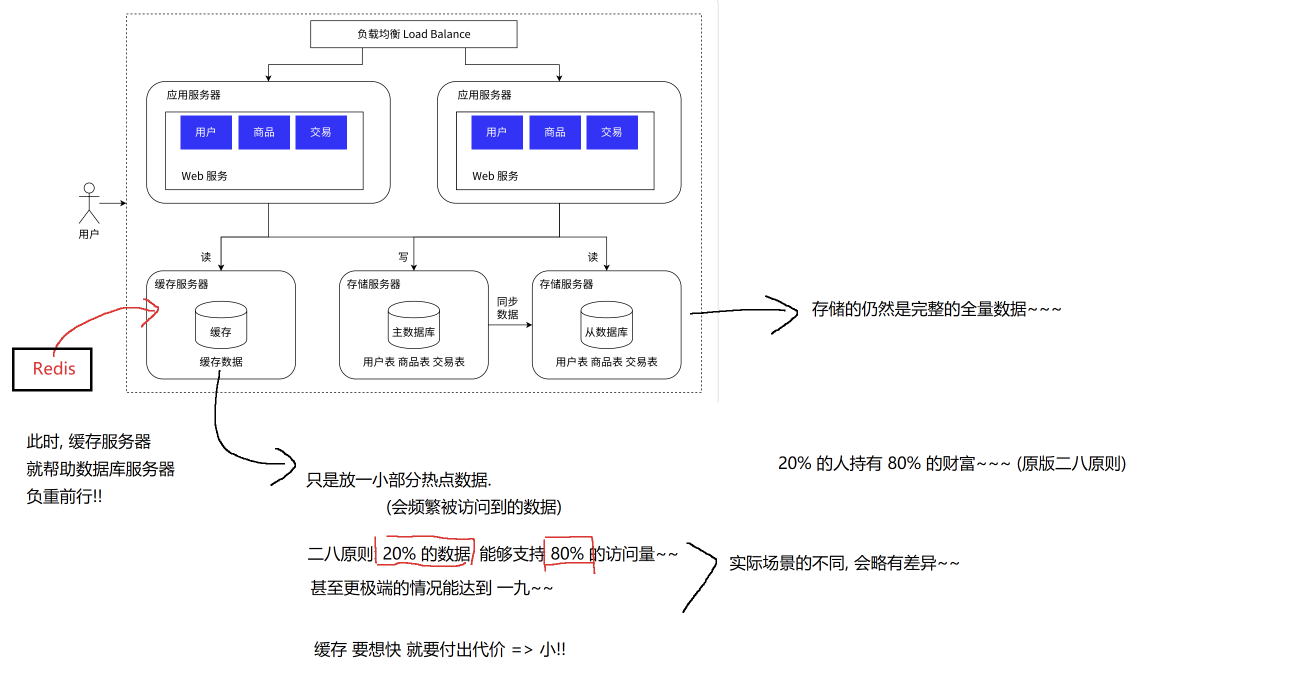
而缓存,我们一般会选择使用Redis,所以这就是为什么Redis常常在分布式系统下使用的原因了!
数据集群
上述都是针对于一台主机内的数据库,但是一台主机的数据库也会有撑不住的时候:
特别是上亿DAU的一些服务,一台主机的存储量必然是不够的
所以,和主机承担负载量的操作一样
可以对数据的存储进行主机上的分离,即数据存储在不同的集群:
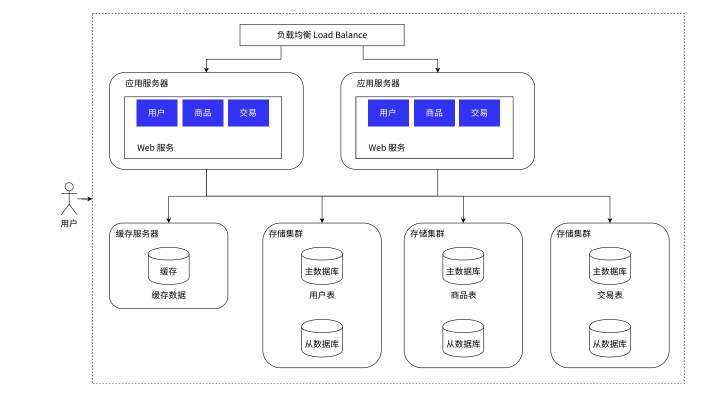
每个集群内存储不同类型的数据,使用主从模式,进行读写的分离
同时配备缓存,支持数据的快速查找读取
这样子,整个系统的架构就很完善了:
上至主机负载均衡,下至数据存储,都采用了合理的架构,以应对高并发量的情况
微服务
上述的架构其实已经是很完善的了,但是还是存在一些问题:
就是一台主机要做的业务太多了:比如商品交易,权限校验,用户管理,超时释放...
因为业务过多,服务复杂,这对于代码的维护是不利的:
所以,这里可以考虑把一个个服务从主机中拆除来,每个主机只做一种服务
每个主机之间通过特定的方式进行通信,这样子一台主机下只需要维护一种业务的代码即可!
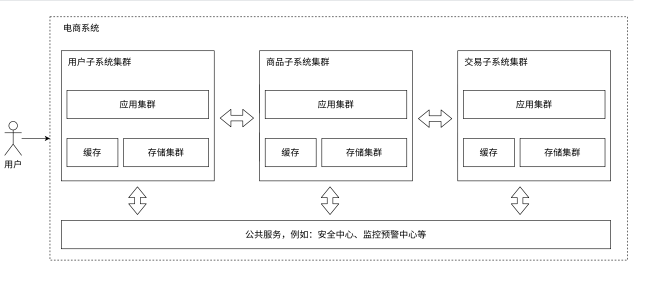
每个子系统都是某种服务器,对应着一种服务,有自己的缓存,自己的存储集群
这就是微服务的概念
1.微服务好处是什么,解决了什么?
① 微服务让代码的维护更加简单,业务逻辑更加明确
② 微服务解决了 "人" 的问题,能够提高人之间合作的效率
③ 微服务能够做到某种服务的复用,支持可拔插设计,可以针对不同的服务进行合适的部署
2.微服务的缺点呢?
① 性能会下降,因为服务器增多,系统架构变复杂,一个环节出错都会引发很多错误
② 多台主机之间通常使用网络进行通信,这非常考验网络的稳定性不差钱的公司可以上万兆网卡
③ 成本提高,这样繁杂的架构势必需要更多硬件资源和维护人员,一般是大公司才考虑
所以,不能盲目相信「分布式和微服务」的魔法,因为这也是有代价的
从来都没有十全十美的技术,只有最合适,最符合当前情况的技术!这是需要开发人员做出取舍的
相关概念
下面我们一起来看一下,分布式系统下的一些相关概念:
| 概念 | 概念解释 |
|---|---|
| 应用(Application)/ 系统(System) | 一个应用,就是一个「程序/服务程序」 |
| 模块(Module)/ 组件(Component) | 一个应用里,拥有多个功能,每个独立的功能,就可以称为一个模块/组件 |
| 分布式(Distributed) | 引入多个「主机/服务」,协同配合完成一系列的工作 → 物理上的多个主机 |
| 集群(Cluster) | 引入多个「主机/服务」,协同配合完成一系列的工作 → 逻辑上的多个主机 |
| 主(Master)/ 从(Slave) | 分布式系统中一种比较典型的结构:多个服务节点中,其中一个是主,另外的是从,从节点的数据要从主节点这里同步过来 |
| 中间件(Middleware) | 和业务无关的服务(功能更通用的服务),例如:数据库、缓存、消息队列等 |
| 可用性(Availability) | 系统整体可用的时间 / 总时间 → 一个系统的第一要务;常用 360/365 衡量,14个9对应99.99%可用性,5个9对应99.999% |
| 响应时长(Response Time RT) | 衡量服务好坏的性能指标(越小越好),和具体服务需要的业务密切相关 |
| 吞吐(Throughput)vs 并发(Concurrent) | 衡量系统处理请求的能力,是衡量性能的一种方式 |
redis特性
在前面,我们了解了redis是做什么的, 也了解了主要的使用场景
接下来,我们将更聚焦于redis的一些特性,这一定程度上决定了它被使用广泛
我们将从官方的解释进行谈论!
redis的优缺点
- In-memory data structures「内存中存储数据」
第一点就是redis存储数据是在内存中进行的,是以key-value这样的键值对方式存储的
相比于mysql,它肯定是更快的因为在内存中
而且可以通过某个key快速索引不同类型的数据,如整形,浮点,字符等...
2.Programmability「可编程性」
指系统、工具或平台 "支持通过编写代码 / 脚本来自定义功能、扩展能力" 的特性
比如redis支持 Lua 脚本、Redis Functions 等方式,让用户能自定义数据处理逻辑
| 操作方式 | 逻辑执行位置 | 原子性(关键!) | 核心特点 |
|---|---|---|---|
| 客户端调用命令(C++/Java连接) | 客户端代码里 | 多步操作可能被打断(非原子) | 发单个命令,Redis被动执行,逻辑在客户端实现 |
| Redis执行脚本(可编程性) | Redis服务端内部 | 脚本内操作是原子的 | 传自定义脚本,Redis主动执行,逻辑在服务端实现 |
- Extensibility「可扩展性」
相当于我们可以对redis这个服务自定义扩展,以便实现针对性的服务
比如让redis支持更多的数据结构,或者更多的操作
本质可以理解为一个动态库,运行的时候动态加载即可
- Persistence「可持久化」
redis虽然在内存上进行操作【内存的数据易丢失】,但是redis会在硬盘中保存一份备份
内存为主,硬盘为辅
这样子如果有丢失的情况,也不用担心,redis可以通过备份来进行恢复,这就是可持久化
5.Clustering「支持集群」
redis是一个常用于分布式系统的中间件,那么很可能在每个服务下都需要使用到redis
所以,redis能够支持集群是非常重要的,能解决分布式系统下的很多问题
所以,多个主机下都可以部署redis节点【一台主机内存有限】,节点之间能够互相通信和同步
这样整个系统能在数据完整保存的情况下,还能进行高效运行
5.High availability「高可用性」
redis支持集群,能够做同步,也就意味着可以redis支持主从架构
当主节点挂了,能够立马顶上一个新的节点,这就是高可用,支持冗余备份!
硬要说:redis的缺点就是:能够存储的数据量少!
因为redis是部署在内存中进行服务的。没办法进行大量存储数据!
redis为什么快
- redis存储的数据在内存中,CPU读取内存是非常快的
- redis核心功能就是操作简单的数据结构,功能不复杂操作自然快
- redis底层采用epoll多路复用,一次性管理一批就绪事件
- redis采用单线程模式,redis更多的是对内存中的数据进行操作,主要吃内存资源,而不是CPU资源。所以开过多线程反而增加了切换、销毁等成本