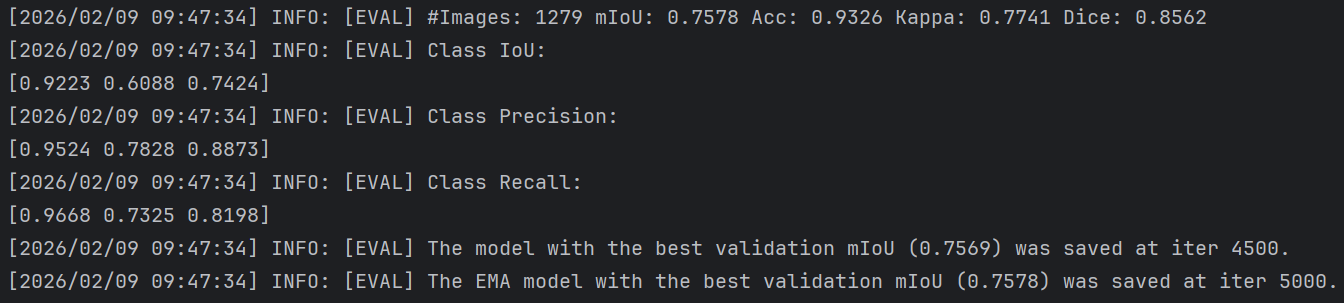
先前博主将PaddleSeg的语义分割模型转换为ONNX后,其结果发生了明显下降,经过分析,发现可能是其预处理过程中的mean和std值不太合理:
python
def preprocess(image, size):
h, w = image.shape[:2]
resized = cv2.resize(image, size, interpolation=cv2.INTER_LINEAR)
# 确保用 float32 计算
resized = resized.astype(np.float32)
mean = np.array([0.485, 0.456, 0.406], dtype=np.float32)
std = np.array([0.229, 0.224, 0.225], dtype=np.float32)
normalized = (resized / 255.0 - mean) / std
input_tensor = normalized.transpose(2, 0, 1)[np.newaxis, ...].astype(np.float32)
return input_tensor, (h, w)其中:
python
mean = np.array([0.485, 0.456, 0.406], dtype=np.float32)
std = np.array([0.229, 0.224, 0.225], dtype=np.float32) 是取自ImageNet数据集的值,相较于遥感数据集,其存在差异:
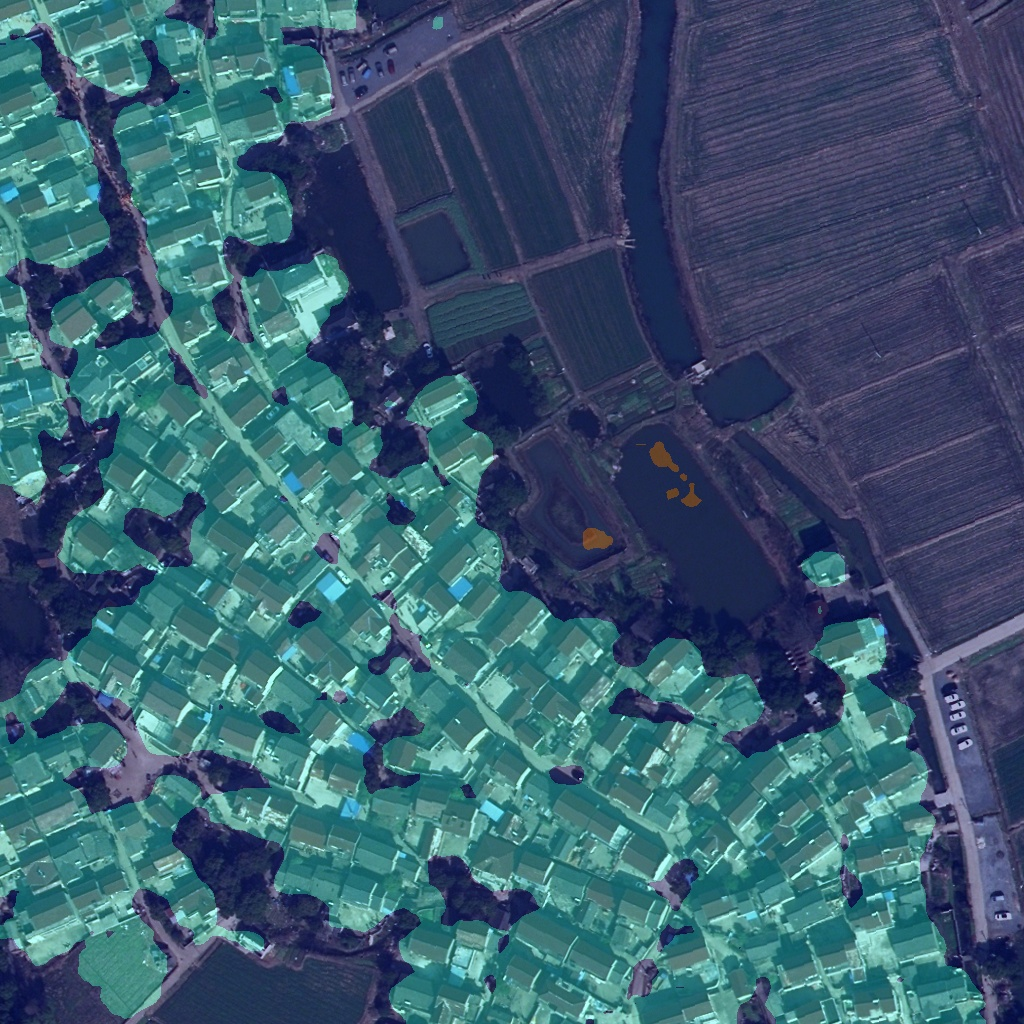
这里博主将其改为
python
mean = np.array([0.5, 0.5, 0.5], dtype=np.float32)
std = np.array([0.5, 0.5, 0.5], dtype=np.float32)其结果如下图所示,其结果好了很多:
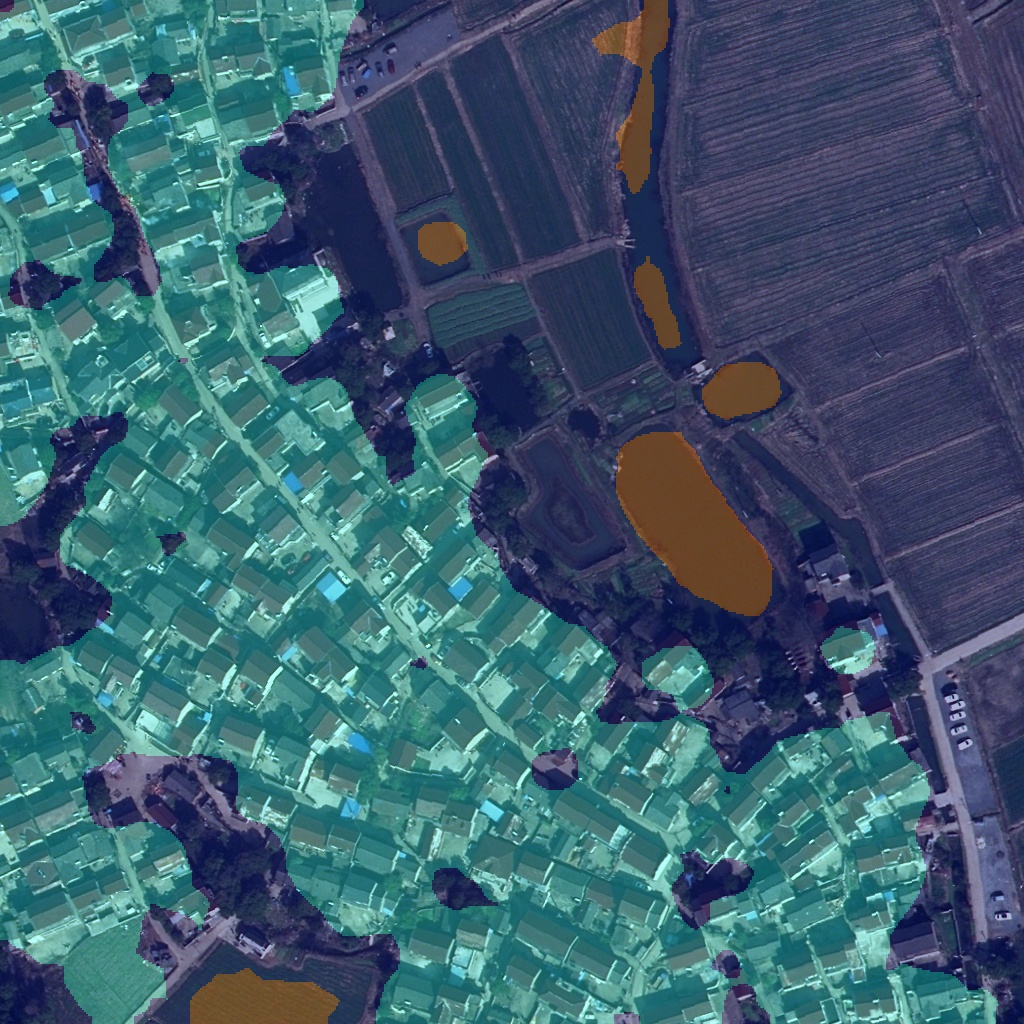
但这个方法也并不完美,最好是我们在训练时便指定好mean与std,如下:
python
- type: Normalize
mean: [0.5, 0.5, 0.5] # ← 显式写明
std: [0.5, 0.5, 0.5] # ← 显式写明完整配置文件如下:
python
batch_size: 8
iters: 10000
train_dataset:
type: Dataset
dataset_root: D:/BaiduNetdiskDownload/yaogan/output
train_path: D:/BaiduNetdiskDownload/yaogan/output/train.txt
num_classes: 4
mode: train
transforms:
- type: ResizeStepScaling
min_scale_factor: 0.5
max_scale_factor: 2.0
scale_step_size: 0.25
- type: RandomPaddingCrop
crop_size: [512, 512]
- type: RandomHorizontalFlip
- type: RandomDistort
brightness_range: 0.5
contrast_range: 0.5
saturation_range: 0.5
- type: Normalize
mean: [ 0.5, 0.5, 0.5 ]
std: [ 0.5, 0.5, 0.5 ]
val_dataset:
type: Dataset
dataset_root: D:/BaiduNetdiskDownload/yaogan/output
val_path: D:/BaiduNetdiskDownload/yaogan/output/val.txt
num_classes: 4
mode: val
transforms:
- type: Normalize
mean: [ 0.5, 0.5, 0.5 ]
std: [ 0.5, 0.5, 0.5 ]
optimizer:
type: SGD
momentum: 0.9
weight_decay: 4.0e-5
lr_scheduler:
type: PolynomialDecay
learning_rate: 0.01
end_lr: 0
power: 0.9
loss:
types:
- type: CrossEntropyLoss
coef: [1, 1, 1]
model:
type: PPLiteSeg
backbone:
type: STDC2
pretrained: https://bj.bcebos.com/paddleseg/dygraph/PP_STDCNet2.tar.gz这样,我们重新训练后,其结果就好很多了。
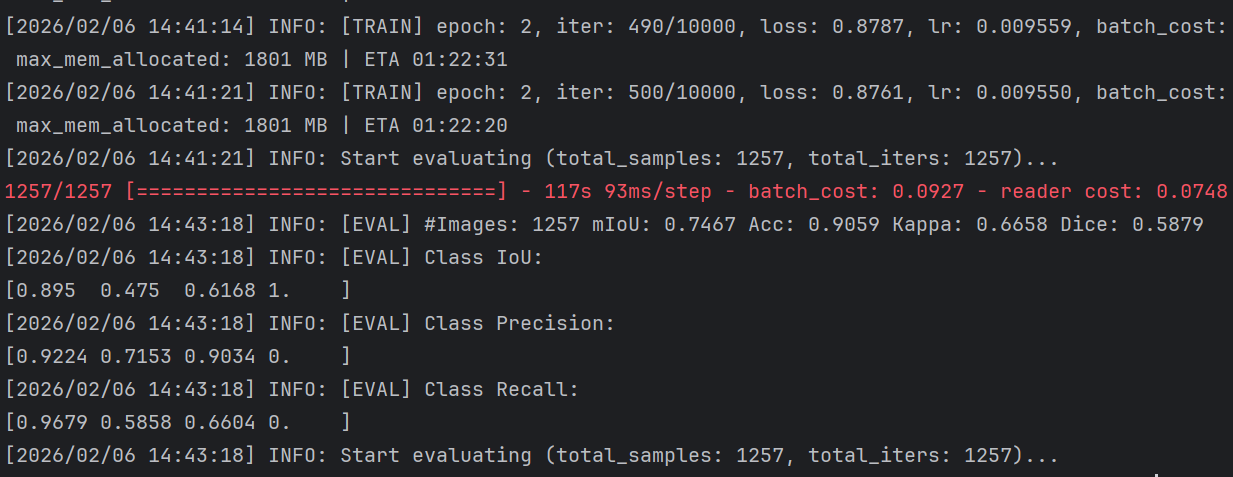
最终效果如下: