最近研究了一下 Libvio.link 的爬虫实现,踩了不少坑,也摸清楚了不少门道,和大家唠唠。
站点特性与反爬初印象
Libvio.link 作为影视资源聚合站点,页面渲染大量依赖前端 JS。第一次用 requests 直接请求页面,返回的 HTML 里几乎没有有效资源链接,全是需要二次渲染的占位节点。它的反爬门槛不算顶尖,但针对性很强:一是设置了动态 Cookie 校验,首次请求返回的 Cookie 有效期极短,必须带着 Cookie 发起二次请求才能拿到真实数据;二是做了简单的 UA 校验,使用默认 requests UA 大概率会被 403 拦截。
最近研究了一下 Libvio.link 的爬虫实现,踩了不少坑,也摸清楚了不少门道,和大家唠唠。
站点特性与反爬初印象
Libvio.link 作为影视资源聚合站点,页面渲染大量依赖前端 JS。第一次用 requests 直接请求页面,返回的 HTML 里几乎没有有效资源链接,全是需要二次渲染的占位节点。它的反爬门槛不算顶尖,但针对性很强:一是设置了动态 Cookie 校验,首次请求返回的 Cookie 有效期极短,必须带着 Cookie 发起二次请求才能拿到真实数据;二是做了简单的 UA 校验,使用默认 requests UA 大概率会被 403 拦截。
核心爬取流程拆解
我最终采用的是 Selenium 配合 undetected-chromedriver 的方案。首先通过无头浏览器模拟真实用户访问,等待页面完全加载后,执行自定义 JS 脚本提取加密的资源链接。这里需要注意,站点的资源链接被隐藏在data-src属性中,并且经过了 Base64 简单编码,需要解码后才能得到真实播放地址。
另外,站点的分页采用了滚动加载机制,传统的翻页按钮定位完全失效。我通过监听页面滚动事件,当滚动条接近底部时自动触发加载,配合显式等待确保新内容渲染完成后再进行数据提取,完美解决了分页爬取的问题。
避坑指南与优化思路
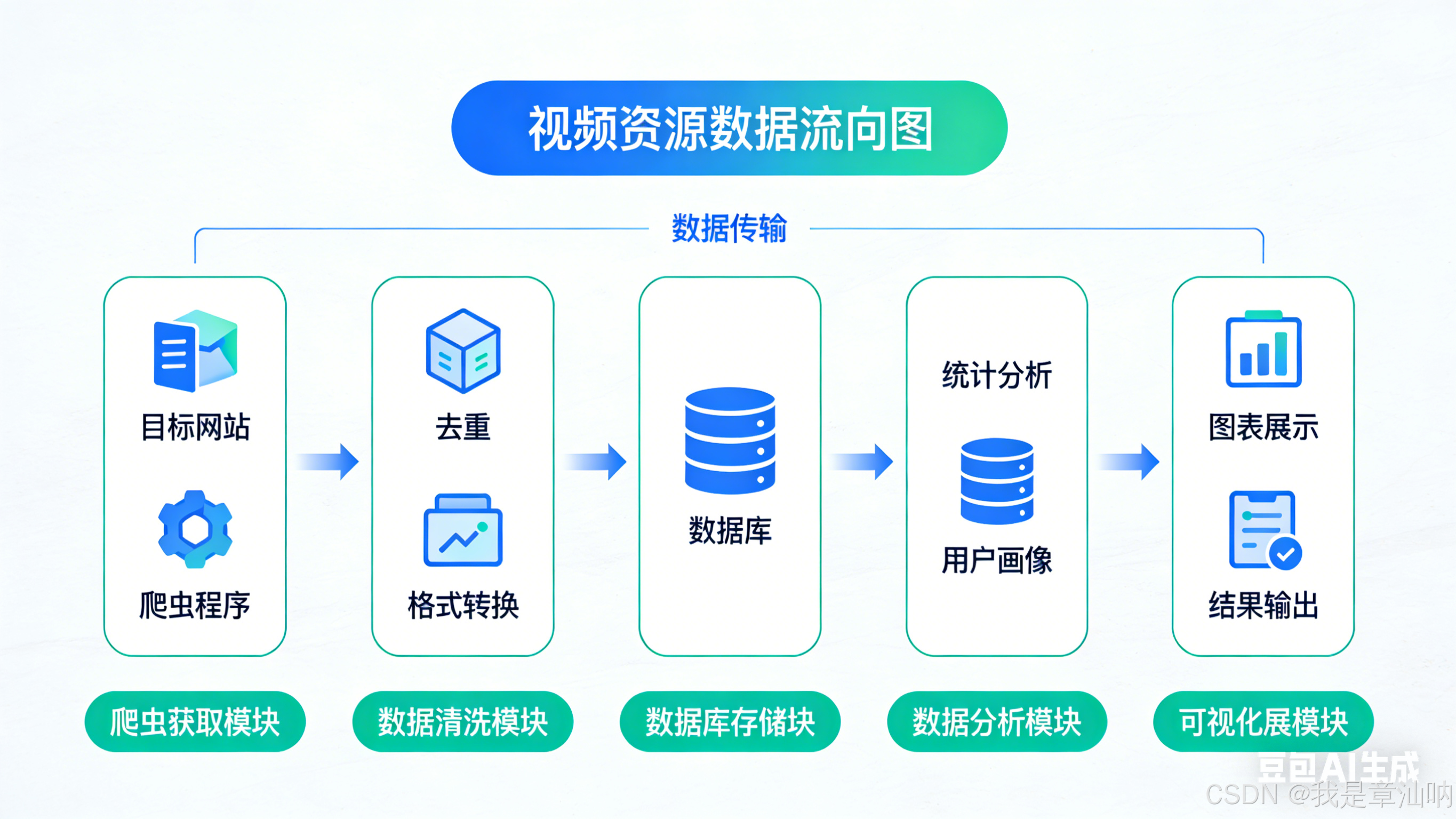
实战中遇到的最大问题是频繁访问导致的 IP 封禁。后来我改用了代理池配合随机请求头的方案,将请求间隔随机设置在 3-8 秒,同时每次请求都更换 UA 和代理 IP,成功绕过了 IP 限制。
数据存储方面,我将爬取到的影视标题、封面和播放地址存入 MongoDB,通过定时任务每天凌晨增量更新一次数据,既保证了数据时效性,又避免了对目标站点造成过大访问压力。
总的来说,Libvio.link 的反爬机制更偏向基础的前端混淆和访问频率限制,只要模拟好真实用户行为,配合针对性的解码逻辑,就能高效获取到想要的影视资源数据。
核心爬取流程拆解
我最终采用的是 Selenium 配合 undetected-chromedriver 的方案。首先通过无头浏览器模拟真实用户访问,等待页面完全加载后,执行自定义 JS 脚本提取加密的资源链接。这里需要注意,站点的资源链接被隐藏在data-src属性中,并且经过了 Base64 简单编码,需要解码后才能得到真实播放地址。
另外,站点的分页采用了滚动加载机制,传统的翻页按钮定位完全失效。我通过监听页面滚动事件,当滚动条接近底部时自动触发加载,配合显式等待确保新内容渲染完成后再进行数据提取,完美解决了分页爬取的问题。
避坑指南与优化思路
实战中遇到的最大问题是频繁访问导致的 IP 封禁。后来我改用了代理池配合随机请求头的方案,将请求间隔随机设置在 3-8 秒,同时每次请求都更换 UA 和代理 IP,成功绕过了 IP 限制。
数据存储方面,我将爬取到的影视标题、封面和播放地址存入 MongoDB,通过定时任务每天凌晨增量更新一次数据,既保证了数据时效性,又避免了对目标站点造成过大访问压力。
总的来说,Libvio.link 的反爬机制更偏向基础的前端混淆和访问频率限制,只要模拟好真实用户行为,配合针对性的解码逻辑,就能高效获取到想要的影视资源数据。