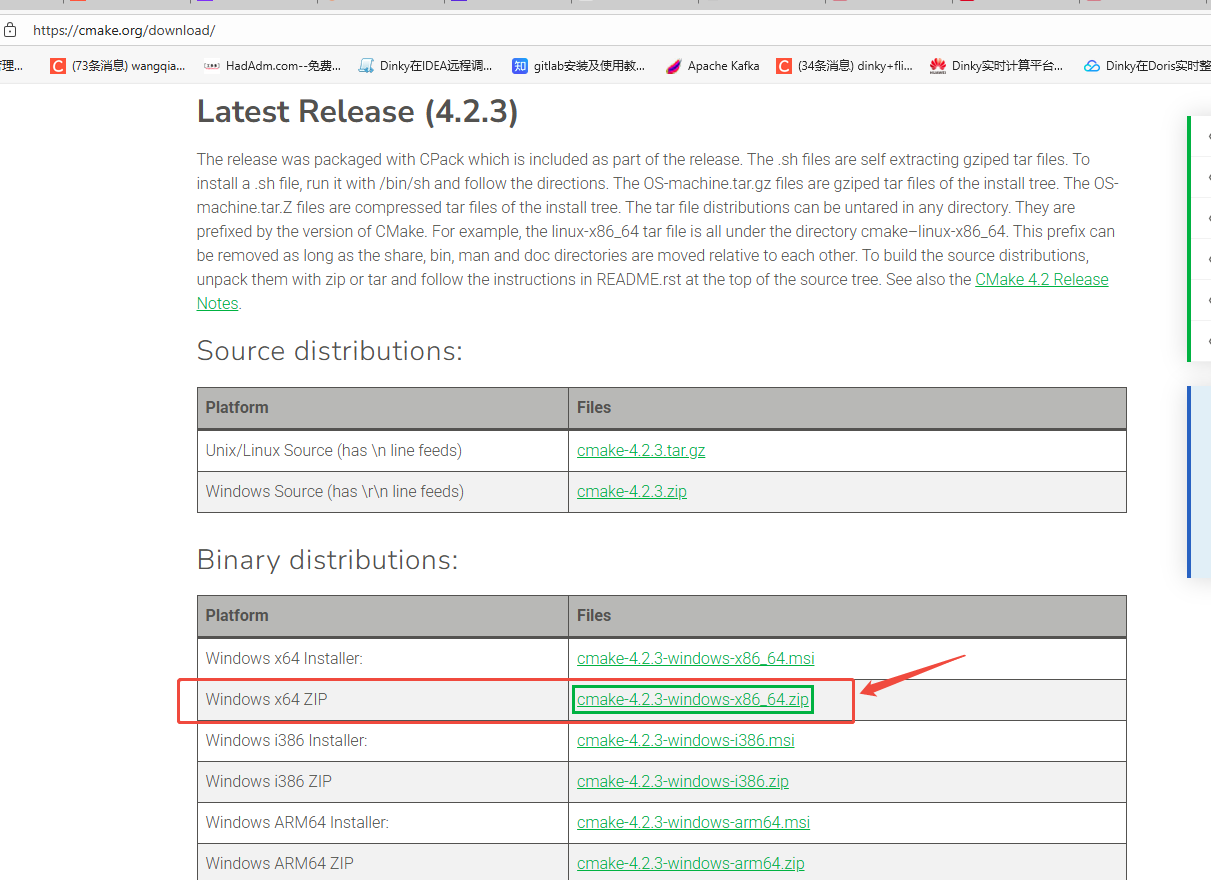
1 、 Download CMake
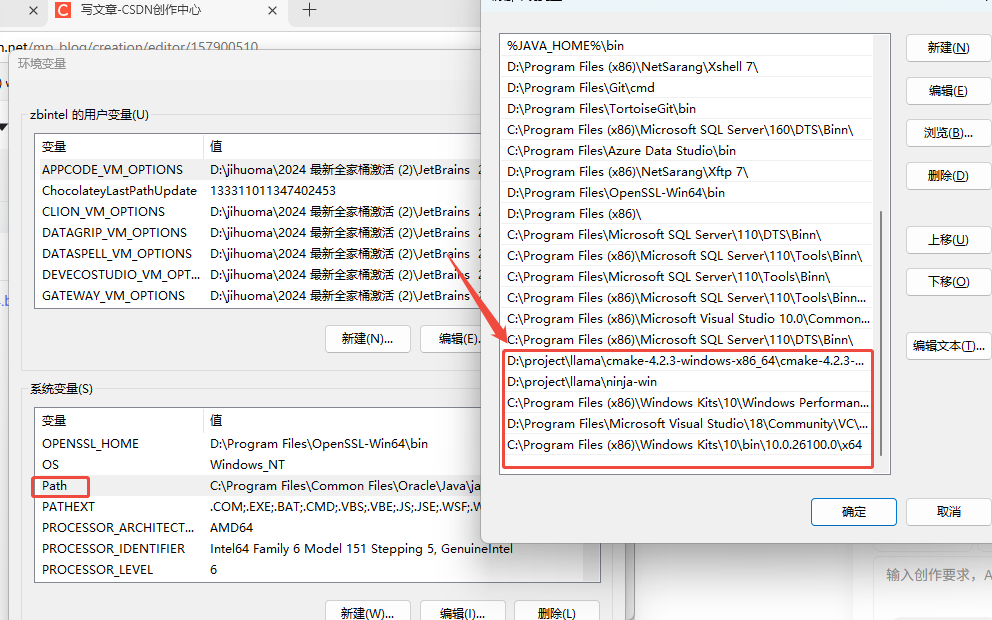
解压后,编辑环境变量 Path 中 增加
D:\project\llama\cmake-4.2.3-windows-x86_64\cmake-4.2.3-windows-x86_64\bin

1、步骤 1:在构建机编译(带 VS2022)
llama.cpp 是 C/C++ 项目,Windows 上默认使用 MSVC(Microsoft Visual C++) 编译器:
build.bat脚本依赖cl.exe(MSVC 编译器)- 需要 Windows SDK 和 C++ 运行时库头文件
适用于 Windows、Mac 和 Linux 的 Visual Studio 和 VS Code 下载
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
下载 ninja
加到环境变量 Path中,
在 CMD 中运行 vcvars64.bat,再启动 PowerShell
🔧 操作步骤如下:
- 关闭当前 PowerShell
- 按下
Win + R,输入cmd,回车 → 打开 命令提示符(CMD) - 在 CMD 中运行以下命令:
call "D:\Program Files\Microsoft Visual Studio\18\Community\VC\Auxiliary\Build\vcvars64.bat"
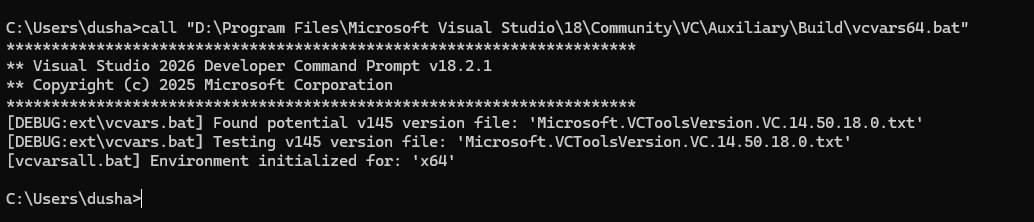
-
在同一 CMD 窗口中,启动 PowerShell:
1. 检查 cl.exe
cl /?
2. 检查 rc.exe
rc /?
3. 检查 LIB 路径是否包含 Windows SDK
$env:LIB -split ';' | Select-String -Pattern "Windows Kits.*x64"
4. 测试编译一个小程序
echo 'int main(){return 0;}' > test.c
cl test.c
dir test.exe # 应该存在!
如果 test.exe 成功生成,说明 编译器、链接器、SDK 全部正常!
# 进入项目目录
cd D:\project\llama\llama.cpp
# 清理旧构建
Remove-Item build-ninja -Recurse -Force
# 创建新构建目录
mkdir build-ninja
cd build-ninja
# 配置 CMake
cmake .. -G Ninja -DCMAKE_BUILD_TYPE=Release -DLLAMA_CURL=OFF
# 编译
cmake --build .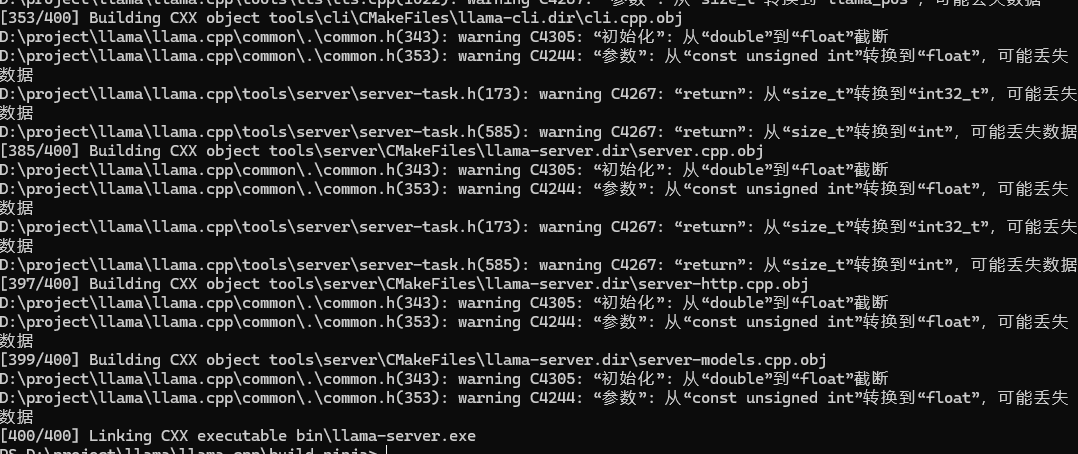
参考:Windows 环境下 llama.cpp 编译 + Qwen 模型本地部署全指南-CSDN博客
下载 qwen2.5-7b-instruct-1m-q4_k_m.gguf
启动服务:
:: 1. 打开 CMD
:: 2. 运行以下命令
cd /d D:\project\llama\llama.cpp\build-ninja\bin
chcp 65001
llama-server.exe -m D:\models\qwen2.5-7b-instruct-1m-q4_k_m.gguf --port 11433 -c 8192 --threads 6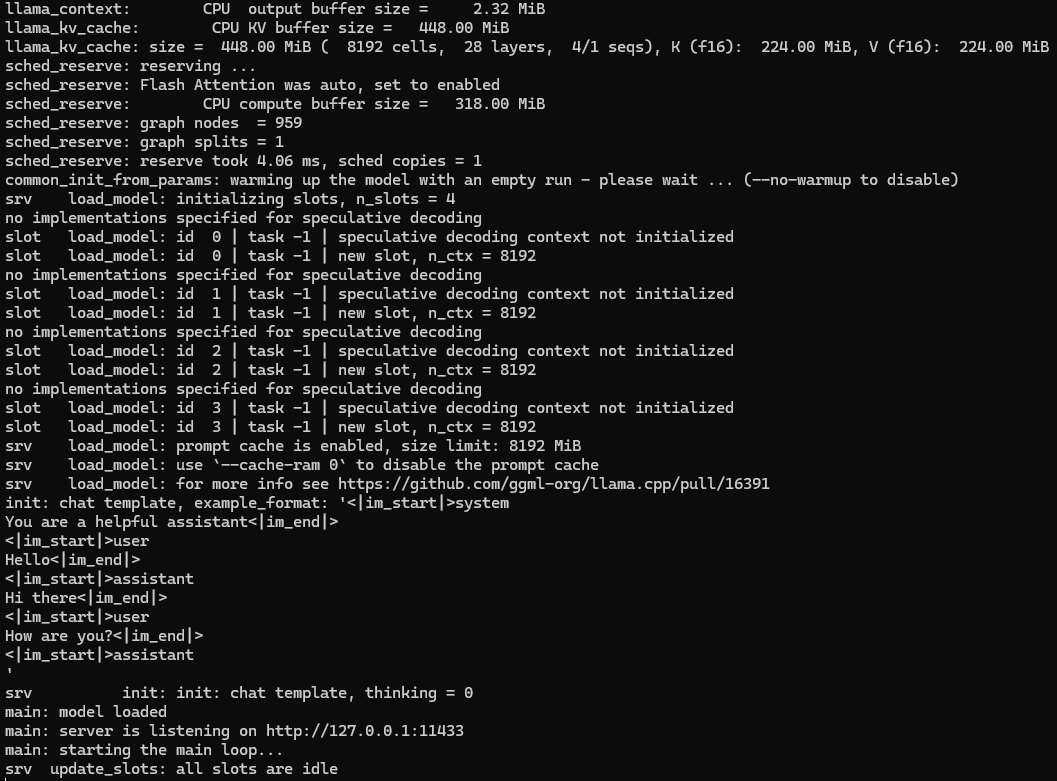
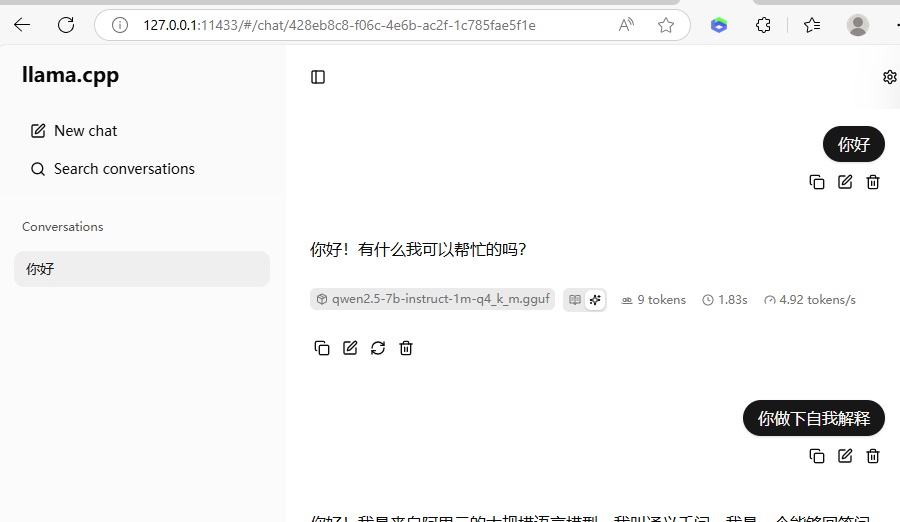
在浏览器中打开:
后台运行的命令如下 在cmd中打开:
cd /d D:\project\llama\llama.cpp\build-ninja\bin && chcp 65001 >nul && start /min cmd /c "llama-server.exe -m D:\models\qwen2.5-7b-instruct-1m-q4_k_m.gguf --host 0.0.0.0 --port 11433 -c 4096 --threads 6 >> D:\llama.log 2>&1"