摘要
在非推理场景下,重复输入提示词能够提升主流模型(Gemini、GPT、Claude、Deepseek)的性能,且不会增加生成 token 的数量或推理延迟。
1 提示词重复
大语言模型(LLM)通常被训练为因果语言模型 ,即过去的token无法关注到未来的token。因此,用户查询中token的顺序会影响预测性能。例如,形式为"<上下文> <问题>"的查询,其表现往往与"<问题> <上下文>"的查询不同(见图1中的"选项优先"与"问题优先"对比)。
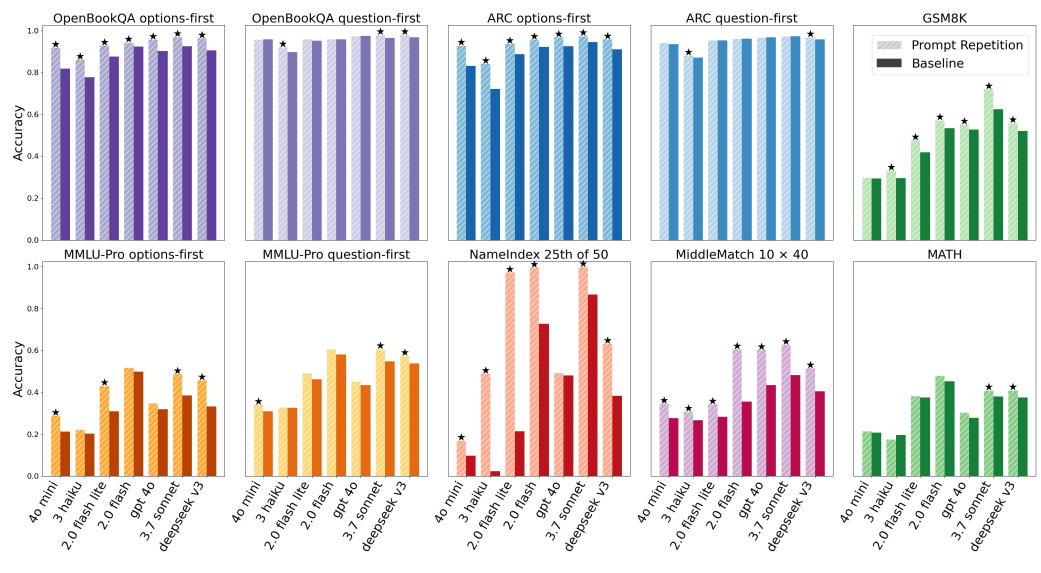
图 1:当要求模型不进行推理时,针对多个热门大语言模型及不同基准测试的提示词重复策略与基线准确率对比。
星号表示在统计学上显著优胜(根据 McNemar 检验 McNemar, 1947,p 值 < 0.1)。在 70 项测试中,提示词重复策略在 47 项中获胜,且未有败绩。
我们提出重复提示词 的方法,即将输入从"<查询>"转换为"<查询><查询>"。这使得每个提示词token都能关注到其他所有提示词token,从而解决上述问题。在非推理场景下,提示词重复能够提升LLM的性能(见图1),且不会增加生成输出的长度或推理延迟(见图2和图3)。
进一步的动机是,我们观察到通过强化学习(RL)训练的推理模型,往往会学习到重复用户请求(的部分内容)的行为。提示词重复是高效的,因为它将重复操作转移到了可并行化的预填充(prefill)阶段,且生成的token数量不会增加¹。此外,提示词重复不会改变生成输出的格式,使其与原始提示词的输出保持可互换性,从而可以在现有系统中直接"即插即用"部署,也便于终端用户直接使用。当启用推理时,提示词重复的效果是中性到略微正向的(见图4)。
核心总结
- 核心动机:因果语言模型的单向注意力限制,导致提示词中token的顺序会影响性能(如"上下文在前"与"问题在前"表现不同)。
- 核心方法 :将输入提示词重复一次(
QUERY → QUERY+QUERY),让每个提示词token都能关注到其他所有提示词token,打破单向注意力的限制。 - 核心优势 :
- 性能提升:在非推理场景下显著提升模型表现,在推理场景下中性或略有增益;
- 成本不变:不增加生成token数和推理延迟,重复操作在可并行的预填充阶段完成;
- 部署友好:不改变输出格式,可直接替换现有系统中的提示词,无需额外适配。
- 启发:强化学习训练的推理模型会自发学习"重复提示"的行为,而本文将其提炼为一种高效、可部署的工程技巧。
¹ 注:预填充阶段的token数会翻倍,但生成阶段的token数保持不变,因此整体延迟和成本的增加幅度远低于直接增加生成长度。
2 实验
我们在7款来自主流大语言模型厂商、不同规模的热门模型上测试了提示词重复(Prompt Repetition)的效果:Gemini 2.0 Flash、Gemini 2.0 Flash Lite Gemini Team Google, 2023、GPT-4o-mini、GPT-4o OpenAI, 2024、Claude 3 Haiku、Claude 3.7 Sonnet Anthropic, 2024,以及Deepseek V3 DeepSeek-AI, 2025。所有测试均在2025年2月至3月期间,通过各厂商的官方API完成。
我们在7个基准测试集上,以多种配置测试了每个模型:ARC (Challenge) Clark et al., 2018、OpenBookQA Mihaylov et al., 2018、GSM8K Cobbe et al., 2021、MMLU-Pro Wang et al., 2024、MATH Hendrycks et al., 2021,以及2个自定义基准:NameIndex和MiddleMatch(见附录A.3)。对于多项选择题基准(ARC、OpenBookQA、MMLU-Pro),我们同时报告两种设置下的结果:一种是"问题在前、选项在后",另一种是"选项在前、问题在后"------后者会让模型在处理选项时,上下文里看不到问题(除非使用提示词重复)。
准确率:在不启用推理的情况下,提示词重复提升了所有测试模型和基准的准确率(见图1)。我们采用McNemar检验(p值<0.1)来判断一种方法是否显著优于另一种,满足该条件则记为"获胜"。在此标准下,提示词重复在70个"基准-模型"组合中获胜47次,且0次落败。值得注意的是,所有测试模型的性能均得到提升。正如预期,在"问题优先"的多项选择题基准中,提升幅度较小;而在"选项优先"的设置下,提升幅度更大。在NameIndex和MiddleMatch这两个自定义任务上,所有模型通过提示词重复都获得了显著的性能增益(例如,Gemini 2.0 Flash-Lite在NameIndex任务上的准确率从21.33%提升至97.33%)。我们还在鼓励"逐步思考"的设置下,对一小部分基准进行了测试(见图4),结果为中性到略微正向(5胜、1负、22中性),这与预期一致(见附录A.2)。
消融实验与变体 :我们将提示词重复与另外两种变体进行了对比:详细版提示词重复(Prompt Repetition (Verbose))和三倍提示词重复(Prompt Repetition ×3)(见附录A.4)。我们发现,在大多数任务和模型上,它们的表现与基础版提示词重复相近(见图2和图3),有时甚至表现更优。值得注意的是,在NameIndex和MiddleMatch任务上,三倍提示词重复的表现往往大幅优于基础版提示词重复(而基础版本身已大幅优于基线)。因此,对这些变体进行进一步研究是有价值的。为了证明性能提升确实源于重复提示词,而非仅仅增加输入长度,我们还评估了填充(Padding)方法(见附录A.4):用句号(.)将输入填充到与提示词重复相同的长度,结果如预期所示,该方法并未提升性能。
效率:对于每个模型、提示词方法和数据集,我们测量了生成输出长度的平均值、中位数,以及实测延迟²。正如预期,在禁用推理时,所有数据集和测试模型的延迟都相近。启用推理后,所有延迟(以及生成输出的长度)都显著增加。无论在哪种情况下,提示词重复及其变体在所有场景下都不会增加生成输出的长度或实测延迟(见图2和图3),唯一的例外是Anthropic模型(Claude Haiku和Sonnet)在处理非常长的请求(来自NameIndex或MiddleMatch数据集,或三倍重复变体)时,延迟会有所增加(这很可能是由于预填充阶段耗时更长)。
核心总结
-
实验设置
- 模型覆盖:涵盖Google、OpenAI、Anthropic、DeepSeek的7款主流模型,从轻量到旗舰,验证方法普适性。
- 基准覆盖:包含5个公开基准(推理、知识、数学)和2个自定义任务(NameIndex、MiddleMatch),覆盖不同场景。
- 关键对比:在多项选择题中,专门测试了"问题优先"与"选项优先"两种顺序,凸显因果注意力的影响。
-
核心结论
- 准确率提升显著:在非推理场景下,提示词重复在70个组合中47胜0负,所有模型均受益;在"选项优先"的困难设置下提升更明显,在自定义任务上甚至能将准确率从21%提升至97%。
- 变体有潜力:三倍重复等变体在特定任务上表现更优,值得进一步探索;而单纯填充长度无增益,证明提升源于"重复语义"而非"增加token数"。
- 效率几乎无损:提示词重复不增加生成token数和延迟,仅在极长输入下,Anthropic模型因预填充耗时略有延迟上升。
-
工程启示
- 提示词重复是一种零成本(或近零成本)的性能提升手段,可直接在现有系统中部署,无需修改输出格式或推理流程。
- 对于因果注意力受限导致的"顺序敏感"问题,重复提示词是一种高效的工程化解决方案,尤其适合非推理场景。
² 注:延迟测量包含API调用的完整耗时,包括预填充和生成阶段。
3 相关工作
目前已有诸多针对大语言模型的提示词优化技术被提出,其中最具代表性的是思维链(Chain of Thought, CoT)提示Wei 等人, 2023(该方法需要为每个任务设计专属示例)与**"逐步思考"提示**Kojima 等人, 2023。这两种方法虽能带来显著的性能提升,但会增加模型生成输出的长度,进而导致推理延迟增加、计算资源需求上升(本文实验表明,该类技术可与提示词重复方法结合使用,整体效果基本为中性)。
近期也有一些独立研究探索了类似的输入优化思路:
- Shaier2024尝试仅重复提示词中的问题部分,发现该操作并未带来任何性能增益;
- Springer 等人2024的研究表明,将输入内容重复两次能得到质量更优的文本嵌入;
- Xu 等人2024则发现,通过提示让模型重新阅读问题,能够提升其推理能力。
核心总结
-
主流提示词技术的共性局限
思维链、逐步思考等经典优化方法,均以牺牲效率为代价换性能提升 ------生成token数、推理延迟、计算成本都会增加,而本文的提示词重复是非推理场景下无效率损耗的性能优化手段,形成鲜明对比。 -
与同期同类研究的核心差异与关联
研究成果 核心做法 研究方向/效果 与本文方法的关联 Shaier 2024 仅重复提示词中的问题部分 下游任务:无性能增益 证明完整重复提示词是性能提升的关键 Springer 等人2024 输入重复两次 文本嵌入:提升嵌入质量 佐证"输入重复"的有效性,本文将其拓展至下游任务性能优化 Xu 等人2024 提示模型重新阅读问题 推理任务:提升推理能力 同属缓解因果模型注意力限制的思路,本文是隐式优化(重复输入) ,该研究是显式优化(提示指令) -
本文方法的创新定位
并非首次提出"输入重复"的思路,而是在现有研究基础上,明确了完整重复提示词在非推理场景的普适价值,并通过大规模跨模型、跨基准实验,验证了其**"零成本提性能"**的独特优势,填补了大语言模型无效率损耗提示词优化的技术空白。
4 结论
本文研究表明,在非推理场景 下,对提示词进行重复操作,能在各类模型与基准测试中持续提升模型性能。此外,该操作不会影响推理延迟 ³------因其仅对可并行化的预填充(pre-fill)阶段产生影响⁴。提示词重复不会改变生成输出的长度与格式,在不启用推理的情况下,这一方法或可成为众多模型与任务的优质默认配置。
未来研究方向 :
(1) 基于重复提示词对模型进行微调;
(2) 结合提示词重复训练推理模型,以提升效率(模型或可学习避免自身重复提示词的行为);
(3) 在生成过程中周期性重复最后生成的token,并探索该方法在多轮对话场景中的适用性;
(4) 仅在键值缓存(KV-cache)中保留第二次重复的提示词内容(使生成阶段的性能完全不受影响);
(5) 仅重复提示词的部分内容(针对长提示词场景尤为适用);
(6) 替代全量重复的方式,借助小型模型对提示词进行重新排序;
(7) 探索该方法在非文本模态中的适用性(如图像);
(8) 进一步分析不同变体的效果,例如多次重复(超过2次)在哪些场景下更具优势;
(9) 深入分析重复操作带来的注意力模式变化(沿用Xu等人2024的研究思路);
(10) 将提示词重复与选择性注意力等技术结合使用Leviathan等人, 2024;
(11) 探索该方法与前缀语言模型(Prefix LM)等技术的交互效果Raffel等人, 2023;
(12) 研究提示词重复在何种场景下发挥作用,以及重复前后token表征的变化规律;
(13) 探索具有应用潜力的提示词重复变体(详见附录A.1)。
核心总结
1. 研究核心结论
本次研究的核心价值在于验证了提示词重复 作为非推理场景下LLM优化手段的普适性、高效性与易用性,三大核心亮点:
- 性能端:跨模型、跨基准实现持续的性能提升,无任何场景下的性能衰减;
- 效率端:仅影响可并行的预填充阶段,不增加推理延迟、不改变生成输出的长度/格式;
- 工程端:无需适配现有系统,可直接作为非推理任务的默认配置,落地成本极低。
2. 未来研究方向核心脉络
12个未来方向围绕性能优化、场景扩展、技术融合、机制探究四大维度展开,核心是让提示词重复的价值最大化,同时解决其潜在的适用边界问题:
- 性能与效率再优化:如KV-cache仅保留二次重复内容、结合微调/推理模型训练,彻底消除预填充阶段的微小影响;
- 场景适配拓展:如长提示词仅重复关键部分、多轮对话周期性重复token、向图像等非文本模态迁移;
- 跨技术融合:与选择性注意力、Prefix LM等现有LLM优化技术结合,探索组合增益;
- 底层机制探究:分析重复带来的注意力模式、token表征变化,明确其性能提升的核心原理,为后续优化提供理论支撑。
补充注释(贴合原文标注)
³ 仅Anthropic模型处理极长请求/三倍重复时,预填充阶段耗时略有增加,属于特殊例外;
⁴ 预填充阶段为LLM的并行计算阶段,该阶段的耗时变化对整体推理延迟的影响可忽略不计。