 本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
文章目录
- 引言
- [Primary Index](#Primary Index)
- Projections
- [Data skipping indexes](#Data skipping indexes)
- Bloomfilter
- 结束语
引言
Clickhouse中存在以下用于加速的结构,从时序数据的角度讲,没有耳目一新的结构,但是该有的都有,要说真缺,也就是一个真.倒排索引了(Projections并不是)。
| 类别 | 结构/机制 | 加速原理(核心点) | 典型适用查询 | 代价/注意事项 | 资料 |
|---|---|---|---|---|---|
| 有序性/主索引 | Primary index(由 ORDER BY/PRIMARY KEY 产生的稀疏主索引) | 以 granule 为单位做范围跳读/数据裁剪 | 高选择性的范围过滤、按排序键前缀过滤、部分 TopN 模式 | 排序键选错会导致"几乎无法跳读";写入/合并成本与排序键相关 | 官方博客ClickHouse |
| 数据裁剪 | Partition pruning(PARTITION BY 分区裁剪) | 先剪掉大量分区/parts,减少参与扫描的数据范围 | 时间序列按天/月、租户隔离、区域隔离等 | 分区过细会带来 parts 数膨胀与合并压力;过粗则裁剪弱 | |
| 有序性/额外结构 | Projections(投影) | 为同一张表维护"另一套物理布局/排序或列子集",允许part级别于granule级别过滤,允许不存储排序键外的其他数据减少存储量(会增加IO数) | 与原表排序不一致的常见查询模式;多维过滤/聚合的加速路径 | 会增加存储与写入/合并成本;需要观察 EXPLAIN 是否命中 |
投影文档([ClickHouse](https://clickhouse.com/docs/data-modeling/projections?utm_source=chatgpt.com "Projections |
| 额外结构过滤 | Data skipping indexes(跳数索引):minmax / set / bloom_filter / tokenbf_v1 / ngrambf_v1 等 | 给每个 granule 维护额外摘要(min/max、集合、布隆等),命中时跳过整块数据 | 非排序键上的过滤;存在性判断;子串/分词过滤(Bloom 系) | 选择性不高时收益小;索引会占存储并增加写入/合并成本;新增后可需要 materialize/等 merge 才覆盖旧数据 | 跳数索引总览(ClickHouse);索引类型示例表([ClickHouse](https://clickhouse.com/docs/optimize/skipping-indexes/examples?utm_source=chatgpt.com "Data Skipping Index Examples |
| TopN 优化(与裁剪相关) | Top-N granule 级跳读(利用 min/max 元数据) | 对 TopN 模式(如 ORDER BY x LIMIT N)利用块级元数据提前跳过大量 granules |
大表 TopN、排行榜、最近/最大/最小值类查询 | 依赖数据分布与可用元数据;需要观察读量变化 | TopN 跳读官方博客(2026-01-19)(ClickHouse) |
| 全文检索 | Text Index(倒排索引 / Inverted index) | token → posting list(行号列表),对文本检索从扫描变成索引检索 | 日志检索、关键词搜索、短语/分词检索 | 建索引与存储开销;要选好 tokenizer/配置;仍需看命中与召回 | 文档:Text indexes(inverted indexes)(ClickHouse);官方博客(ClickHouse) |
| 向量检索 | Vector similarity index(ANN,如 HNSW) | 近似最近邻索引,把高维距离计算从全扫变为 ANN 搜索 | embedding 检索、语义相似、推荐召回 TopK | ANN 有召回/精度权衡;索引参数和 LIMIT 约束;需要与查询距离函数匹配 | ANN 文档(ClickHouse);示例数据集建索引(ClickHouse) |
| 预计算 | Materialized Views(物化视图) | 写入时增量计算/路由,把查询时的聚合/过滤前置 | 实时看板、按天/小时聚合、宽表加工 | 增加写入成本;回填历史要额外策略;要防止重复/延迟写入导致的口径问题 | MV 官方博客(ClickHouse);rollup 示例(ClickHouse) |
| 预聚合存储 | AggregatingMergeTree(/Summing 等)配合聚合型 MV | 合并阶段把同 key 的聚合 state 进一步合并,减少行数与聚合成本 | 指标类聚合查询、维度汇总层 | 需要用 AggregateFunction/SimpleAggregateFunction;查询要用 ...Merge 系函数 |
AggregatingMergeTree 文档([ClickHouse](https://clickhouse.com/docs/engines/table-engines/mergetree-family/aggregatingmergetree?utm_source=chatgpt.com "AggregatingMergeTree table engine |
| 生命周期+降采样 | TTL + GROUP BY Rollup(TTL 汇总/降采样) | TTL merge 时按规则把明细"滚动汇总"为更粗粒度并保留 | 近细远粗、历史降采样、成本控制下保留趋势 | 依赖 TTL merge;GROUP BY 需要符合主键/排序键前缀等约束(实践上要验证) | TTL 指南(含 rollup)(ClickHouse);(补充实践注意)(Altinity® Knowledge Base for ClickHouse®) |
| 维表/映射加速 | Dictionaries(字典)+ dictGet | 把维表变成内存 KV 结构,查询时 O(1) 查字典,常用来替代部分 JOIN | 用户属性映射、代码表、标签映射、在线富化 | 需要维护刷新策略;字典过大占内存;键设计要稳定 | Dictionary 文档([ClickHouse](https://clickhouse.com/docs/dictionary?utm_source=chatgpt.com "Dictionary |
| JOIN 结构化加速 | Join table engine(把右表预加载成 Join 结构) | 避免每次查询都构建右表哈希/结构;适合"右表固定且重复 JOIN" | 高频服务化查询、右表小且变化不频繁 | Join 表数据常驻内存(RAM);需要关注内存与更新流程 | Join 引擎文档([ClickHouse](https://clickhouse.com/docs/engines/table-engines/special/join?utm_source=chatgpt.com "Join table engine |
| 结果缓存 | Query cache(结果缓存) | 相同 SELECT 只算一次,后续直接返回结果,降低延迟与资源 | 报表/看板重复刷新、同查询多用户复用 | 一致性通常是"可接受的不严格一致";需要设置启用与有效期策略 | Query cache 文档([ClickHouse](https://clickhouse.com/docs/operations/query-cache?utm_source=chatgpt.com "Query cache |
| 读路径缓存 | mark_cache / uncompressed_cache 等 | 缓存 marks 与(可选)解压数据,减少随机 IO 与重复解压 | 热点表/热点范围反复查询 | 内存分配要平衡;uncompressed_cache 在一些场景未必收益明显 |
Cache types 文档([ClickHouse](https://clickhouse.com/docs/operations/caches?utm_source=chatgpt.com "Cache types |
| 多级预计算 | Cascading Materialized Views(级联 MV) | 把加工/聚合拆成多层,逐层降低查询时计算量 | 多层指标体系、明细→中间层→服务层 | 链路更复杂;需要监控延迟与重算策略 | 级联 MV 文档([ClickHouse](https://clickhouse.com/docs/guides/developer/cascading-materialized-views?utm_source=chatgpt.com "Cascading Materialized Views |
本文主要解析以下三个结构的持久化格式:
- Primary Index
- Projections
- Data skipping indexes
Primary Index
sql
CREATE TABLE %s (
created_date Date DEFAULT today(),
created_at DateTime DEFAULT now(),
time String,
tags_id UInt32,
%s,
additional_tags String DEFAULT ''
) ENGINE = MergeTree()
PARTITION BY toYYYYMM(created_date)
ORDER BY (tags_id, created_at)
SETTINGS index_granularity = 8192使用tsbs导入clickhouse数据,一个part的磁盘结构如下:
这里存在一些公共文件
- checksums.txt 元数据 所有文件的 checksum,用于完整性校验
- columns.txt 元数据 列定义(名称、类型)
- columns_substreams.txt 元数据 每列的子流列表
- count.txt 元数据 投影 part 的总行数
- metadata_version.txt 元数据 元数据版本
- serialization.json 元数据 序列化信息
- default_compression_codec.txt 元数据 默认压缩编码
- primary.cidx 主键索引 压缩的主键稀疏索引,每个 granule 存该 granule 第一行的投影排序键
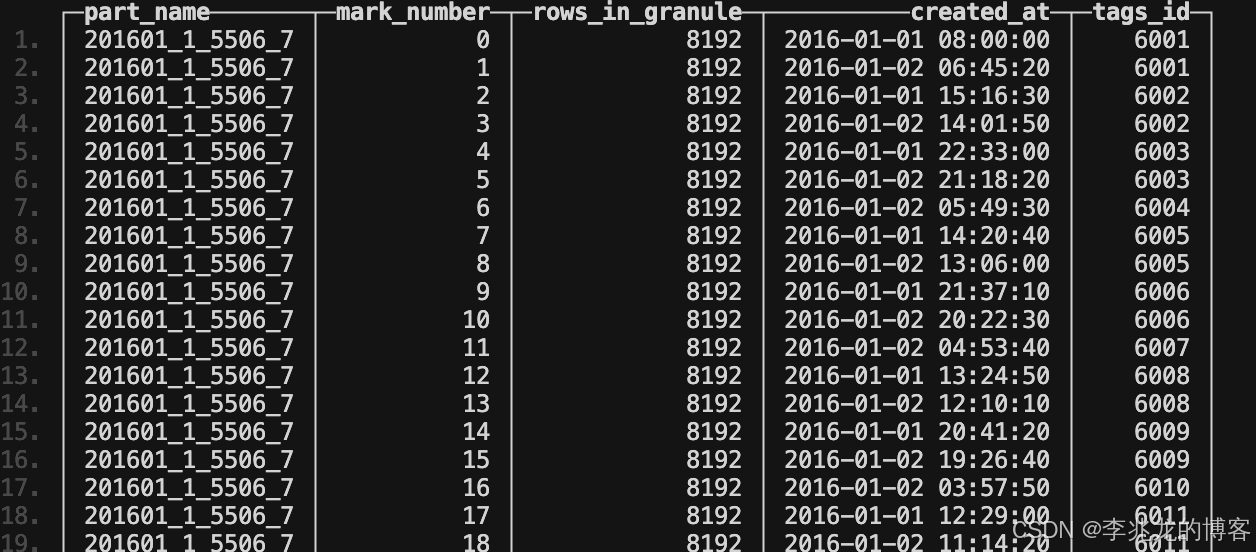
通过执行:
./clickhouse local --path /data1/exercise/ClickHouse/build/programs \ -q "SELECT part_name, mark_number, rows_in_granule, created_at, tags_id FROM mergeTreeIndex('benchmark', 'cpu', with_marks=0, with_minmax=0) ORDER BY part_name, mark_number LIMIT 50 FORMAT PrettyCompact"
可以获取主索引的值:
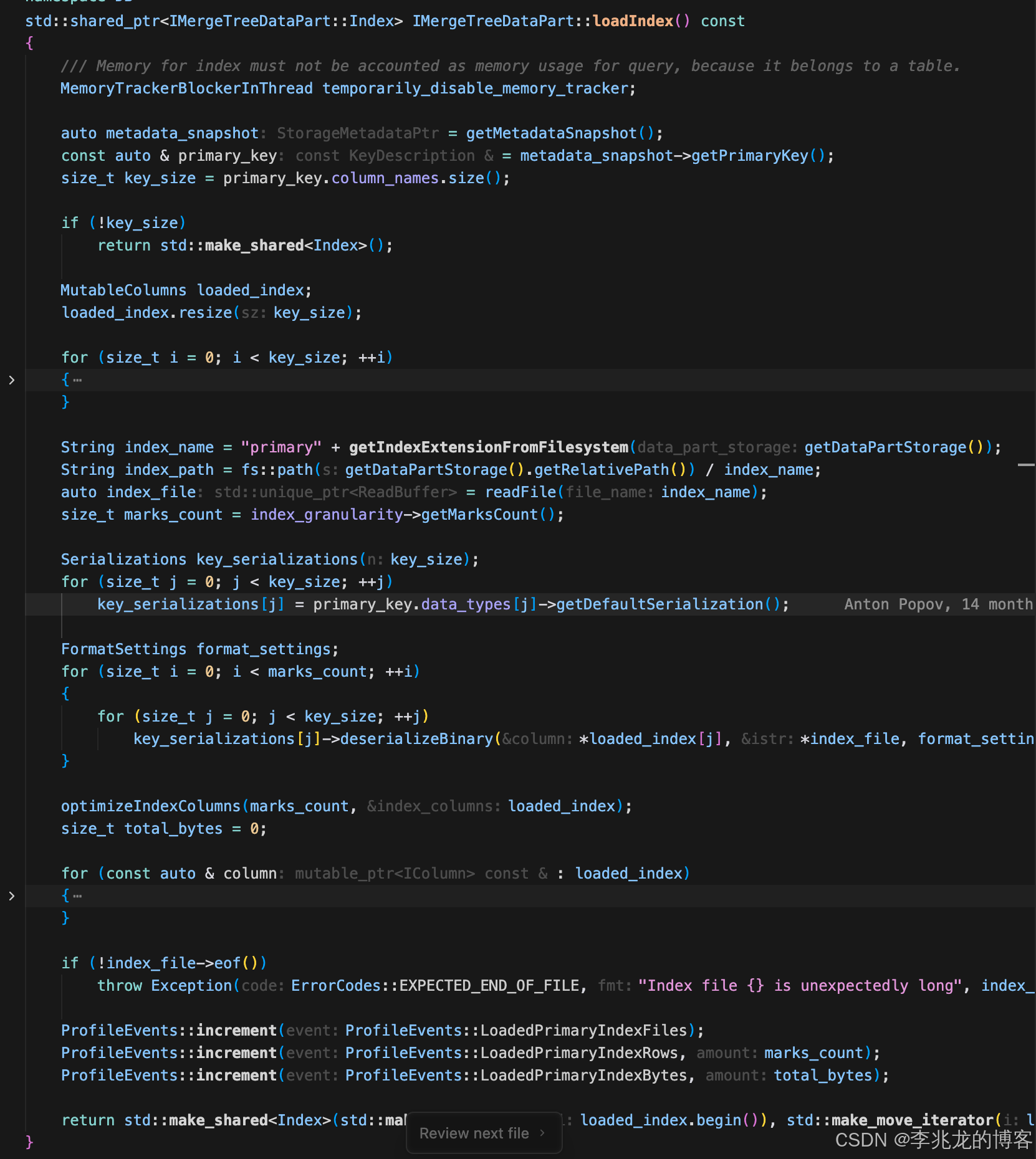
主索引载入过程如下:
Projections
sql
CREATE DATABASE IF NOT EXISTS uk;
CREATE OR REPLACE TABLE uk.uk_price_paid_with_proj
(
price UInt32,
date Date,
postcode1 LowCardinality(String),
postcode2 LowCardinality(String),
type Enum8(
'terraced' = 1, 'semi-detached' = 2, 'detached' = 3, 'flat' = 4, 'other' = 0),
is_new UInt8,
duration Enum8('freehold' = 1, 'leasehold' = 2, 'unknown' = 0),
addr1 String,
addr2 String,
street LowCardinality(String),
locality LowCardinality(String),
town LowCardinality(String),
district LowCardinality(String),
county LowCardinality(String),
PROJECTION by_time (
SELECT _part_offset ORDER BY date
),
PROJECTION by_town (
SELECT _part_offset ORDER BY town
)
)
ENGINE = MergeTree
ORDER BY (postcode1, postcode2, addr1, addr2);
sql
INSERT INTO uk.uk_price_paid_with_proj
(
price, date, postcode1, postcode2, type, is_new, duration,
addr1, addr2, street, locality, town, district, county
)
SELECT
-- price: 50k ~ 2.05m 之间波动
toUInt32(50000 + (cityHash64(number) % 2000000)) AS price,
-- date: 最近 10 年内的日期
toDate('2015-01-01') + toIntervalDay(toInt32(cityHash64(number) % 3650)) AS date,
-- postcode1: 类似 "SW1", "E2", "M1"
concat(
arrayElement(['SW','E','W','N','SE','NW','NE','S','WC','EC','M','B','LS','L'], toInt32(cityHash64(number) % 14) + 1),
toString(toInt32(cityHash64(number + 1) % 9) + 1)
) AS postcode1,
-- postcode2: 类似 "1AA", "2BB"
concat(
toString(toInt32(cityHash64(number + 2) % 9) + 1),
arrayElement(['AA','AB','AD','AE','AF','BA','BB','BD','BE','BF','DA','DB','DG','EA','EB'], toInt32(cityHash64(number + 3) % 15) + 1)
) AS postcode2,
-- type: Enum8 ('terraced','semi-detached','detached','flat','other')
arrayElement(['other','terraced','semi-detached','detached','flat'], toInt32(cityHash64(number + 4) % 5) + 1)
AS type,
-- is_new: 0/1
toUInt8(cityHash64(number + 5) % 2) AS is_new,
-- duration: Enum8 ('freehold','leasehold','unknown')
arrayElement(['unknown','freehold','leasehold'], toInt32(cityHash64(number + 6) % 3) + 1)
AS duration,
-- addr1/addr2: 高基数字符串
concat(toString(toInt32(cityHash64(number + 7) % 200) + 1), ' ', arrayElement(['Flat','Unit','Apt',''], toInt32(cityHash64(number + 8) % 4) + 1))
AS addr1,
concat('Building ', toString(toInt32(cityHash64(number + 9) % 5000) + 1)) AS addr2,
-- street/locality/town/district/county: 低基数维度
arrayElement(['High Street','Station Road','Main Street','Church Lane','Park Road','Victoria Road','Green Lane','Manor Road'], toInt32(cityHash64(number + 10) % 8) + 1)
AS street,
arrayElement(['Central','Riverside','Old Town','New Town','West End','East Side','North Quarter','South Bank'], toInt32(cityHash64(number + 11) % 8) + 1)
AS locality,
arrayElement(['LONDON','MANCHESTER','BIRMINGHAM','LEEDS','LIVERPOOL','BRISTOL','SHEFFIELD','NEWCASTLE'], toInt32(cityHash64(number + 12) % 8) + 1)
AS town,
arrayElement(['Camden','Westminster','Islington','Hackney','Salford','Leeds District','Bristol District','Sheffield District'], toInt32(cityHash64(number + 13) % 8) + 1)
AS district,
arrayElement(['Greater London','Greater Manchester','West Midlands','West Yorkshire','Merseyside','Bristol','South Yorkshire','Tyne and Wear'], toInt32(cityHash64(number + 14) % 8) + 1)
AS county
FROM numbers(10000000); -- 生成 1kw 行(你想要更多就改这里)通过如上结构创建Projections,持久化结构如下,每个Projections都有一个独立的目录
每个目录中如下,这里在创表时选择了_part_offset,每个Projections在_parent_part_offset.bin中存储主表的part行号,这样通过查date主索引,就可以找到其在主表中的行号,虽然看起来很美好,甚至于官方博客将其称之为替代二级索引。实际并不总是那么有效,如果目标tag没有在主表中的排序键内,大概率数据是离散分布的,和全表扫区别不大,还是物化视图通用一些,当然Projections也可以选择携带一部分field,这样的话就不需要回主表查询了,IO也更加聚合,就是存储量和写入IO增加了。

- primary.cidx 投影的主键稀疏索引(按 date 排序)。每个 granule 存第一行的 date,用于按 date 二分查找 granules
- date.bin 投影的 date 列数据(压缩)
- date.cmrk2 date 的 marks,每条 mark 指向该 granule 在 date.bin 中的位置
- _parent_part_offset.bin 投影每行对应的主表 part 行号
- _parent_part_offset.cmrk2 _parent_part_offset 的 marks
可以执行如下语句观察_parent_part_offset.bin内数据
sql
./clickhouse local --path /data1/exercise/ClickHouse/build/programs \
-q "SELECT _part, _parent_part_offset, town
FROM mergeTreeProjection('uk', 'uk_price_paid_with_proj', 'by_town')
WHERE _parent_part_offset >= 0
LIMIT 100;"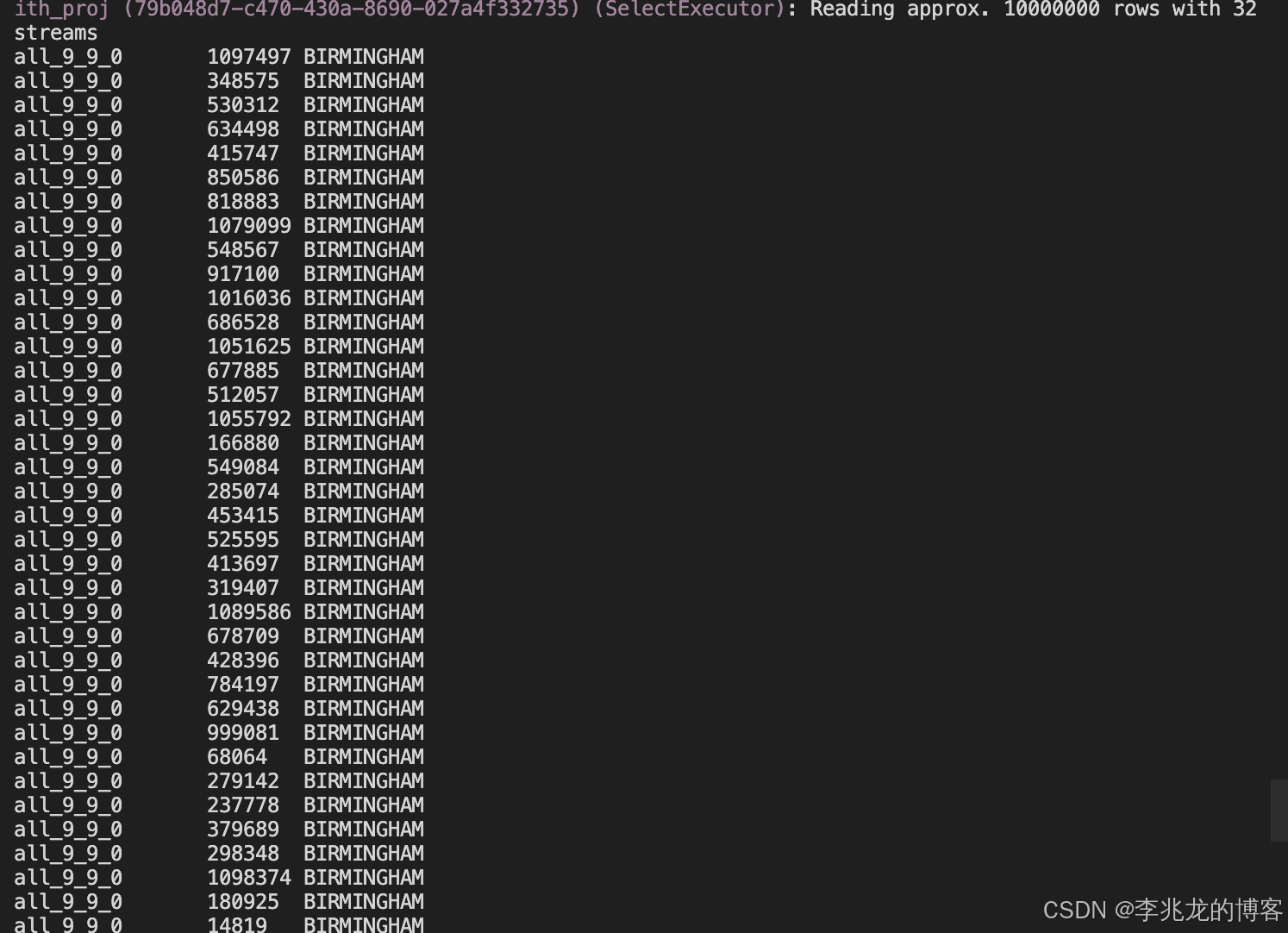
Data skipping indexes
sql
CREATE DATABASE IF NOT EXISTS demo;
CREATE TABLE demo.events
(
created_date Date DEFAULT today(),
created_at DateTime DEFAULT now(),
time String,
tags_id UInt32,
user_id UInt64,
event_type LowCardinality(String),
message String,
additional_tags String DEFAULT '',
-- 1) minmax:常用于时间/数值范围过滤
INDEX idx_created_at_minmax created_at TYPE minmax GRANULARITY 1,
-- 2) set:适合低基数 IN 查询(例如 event_type 或者某些枚举字段)
INDEX idx_event_type_set event_type TYPE set(1000) GRANULARITY 4,
-- 3) bloom_filter:适合等值/IN(高基数 id)
INDEX idx_user_id_bf user_id TYPE bloom_filter(0.01) GRANULARITY 4,
-- 4) ngrambf_v1:适合 message LIKE '%timeout%' 这种任意子串
INDEX idx_msg_ngram message TYPE ngrambf_v1(3, 10000, 3, 7) GRANULARITY 1,
-- 5) tokenbf_v1:适合 token/词级(常见做法是 lower(message))
INDEX idx_msg_token lower(message) TYPE tokenbf_v1(10000, 7, 7) GRANULARITY 1
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(created_date)
ORDER BY (tags_id, created_at)
SETTINGS index_granularity = 8192;
sql
INSERT INTO demo.events
(created_date, created_at, time, tags_id, user_id, event_type, message, additional_tags)
SELECT
today() - (number % 10) AS created_date,
now() - toIntervalSecond(number % 200000) AS created_at,
toString(now() - toIntervalSecond(number % 200000)) AS time,
toUInt32(number % 1000) AS tags_id,
toUInt64((number * 1103515245 + 12345) % 1000000) AS user_id,
multiIf(number % 5 = 0, 'login',
number % 5 = 1, 'logout',
number % 5 = 2, 'pay',
number % 5 = 3, 'timeout',
'other') AS event_type,
concat('user=', toString(user_id), ' msg=',
multiIf(number % 13 = 0, 'timeout while calling upstream',
number % 17 = 0, 'payment failed: insufficient funds',
number % 19 = 0, 'login ok',
'misc event')) AS message,
if(number % 7 = 0, 'a=b,c=d', '') AS additional_tags
FROM numbers(10000000); -- 1kw行持久化结构如下:
minmax
可以看到有两个minmax索引,一个是minmax_created_date.idx,一个是skp_idx_idx_created_at_minmax.idx2;
前者的作用是用作parttion的过滤,可以执行 od -An -t u2 minmax_created_date.idx 获取其内容;
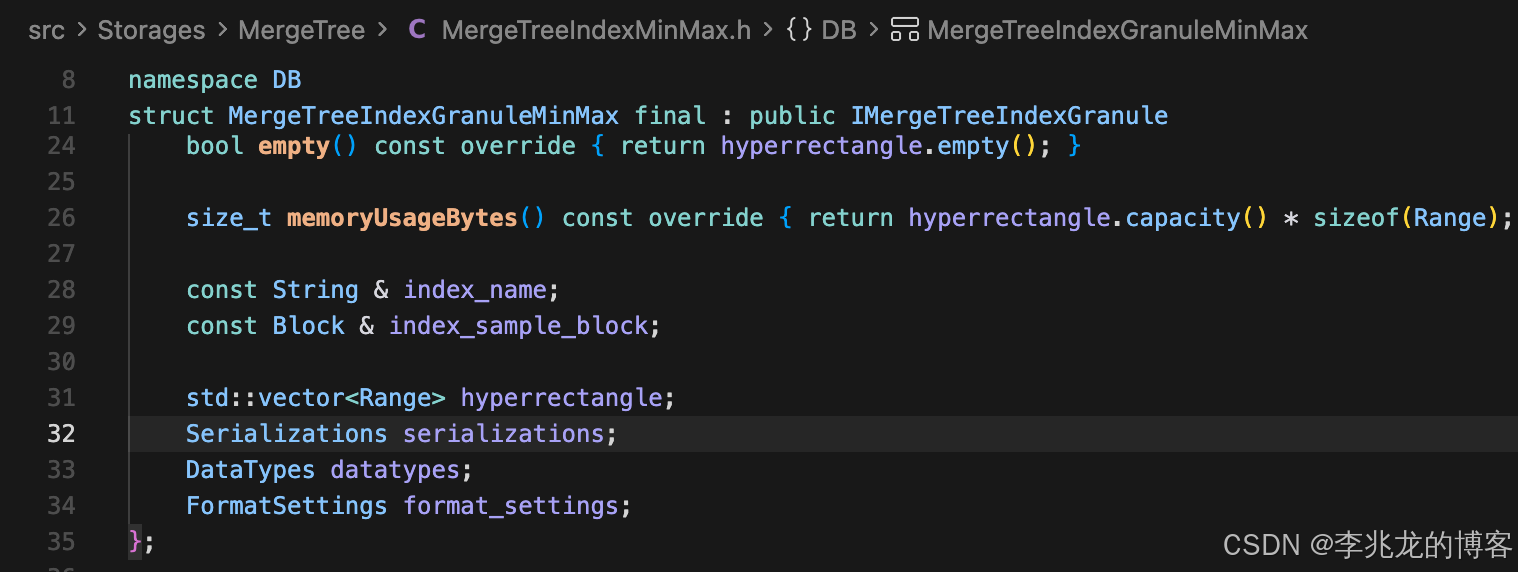
后者则为列级别的过滤,其基本单位为granule。结构体也很简单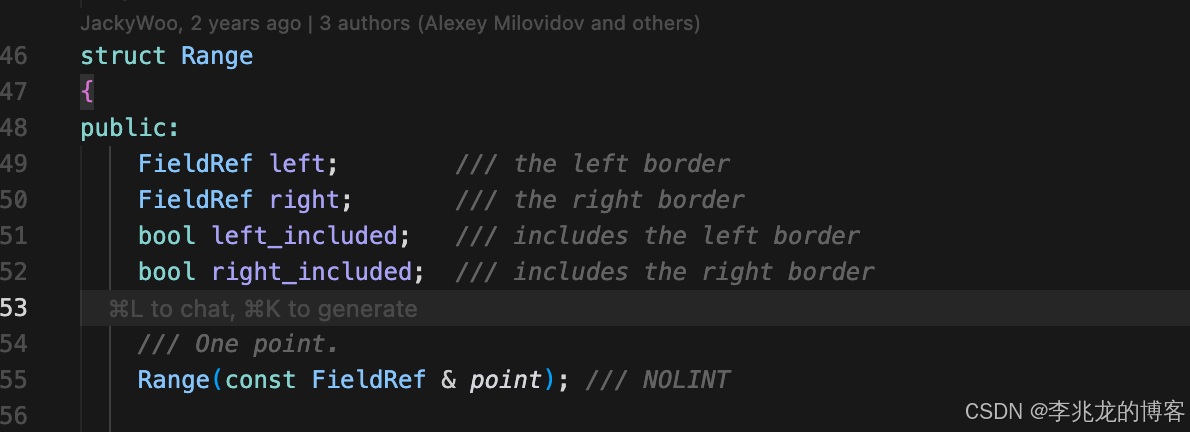
set
其基础结构为MergeTreeIndexAggregatorSet,在update时执行去重,并把数据写入block(for循环),在serializeBinary和deserializeBinary中是具体的序列化逻辑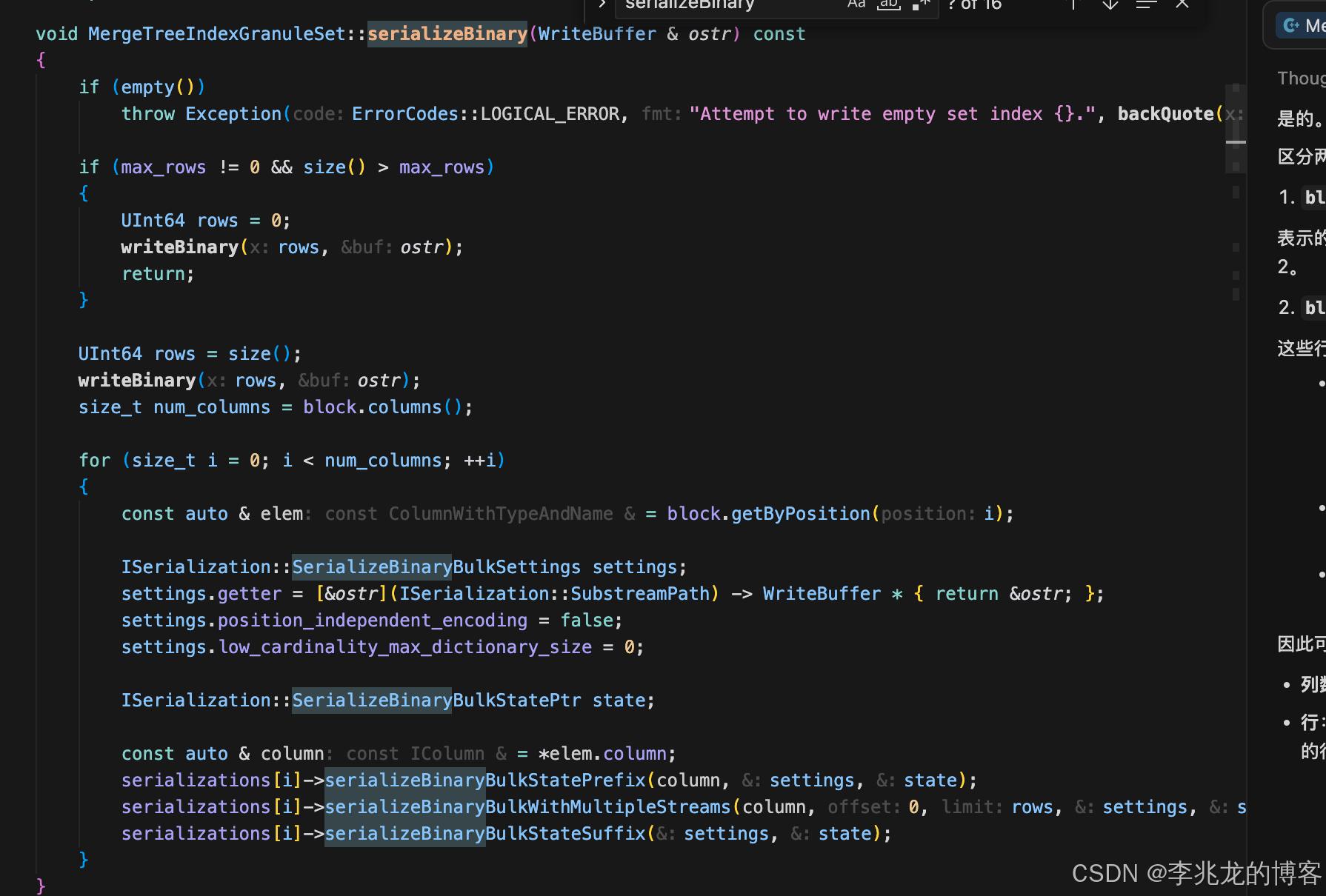
这其实就是我朝思暮想的DistinctCache。
Bloomfilter
bloom_filter使用MergeTreeIndexGranuleBloomFilter,典型实现
tokenbf_v和ngrambf_v1使用MergeTreeIndexGranuleBloomFilterText,仅分词方式不一致,
- ngrambf_v1使用NgramsTokenExtractor;
- tokenbf_v1使用SplitByNonAlphaTokenExtractor;
- sparse_grams使用SparseGramsTokenExtractor;
| 索引类型 | Bloom filter 里存的"元素" | 最适合的查询形态 | 典型 SQL(能触发) | 关键参数 / 调优点 | 主要限制 |
|---|---|---|---|---|---|
bloom_filter |
列值本身(或表达式结果) | 等值 / IN(needle-in-haystack) | col = x / col IN (...) |
bloom_filter([false_positive_rate])(默认 0.025)(ClickHouse) |
不支持 LIKE(官方函数支持表里 LIKE 对 bloom_filter 为 ✗)(ClickHouse);且 Bloom 类索引都无法优化"期望结果为 false"的条件(如 NOT LIKE、!= 等)(ClickHouse) |
tokenbf_v1 |
token(词元):按非字母数字分隔的序列 | 包含某个词(更像"词命中") | hasToken(col, 'error')(支持表中对 tokenbf_v1 为 ✔)(ClickHouse) |
tokenbf_v1(size_bytes, hash_functions, seed)(ClickHouse) |
对"任意子串"能力弱;大小写不敏感要对 lower(col) 建索引才有效(官方备注)(ClickHouse) |
ngrambf_v1 |
固定长度 n-grams(滑动切片) | 子串搜索 (尤其 LIKE '%...%') |
col LIKE '%timeout%'(支持表中为 ✔)(ClickHouse) |
ngrambf_v1(n, size_bytes, hash_functions, seed)(ClickHouse) |
若查询常量长度 < n,无法用该索引优化(官方说明)(ClickHouse);同样受 Bloom "假阳性"与"不能优化 false 结果条件"限制(ClickHouse) |
sparse_grams |
sparse grams tokens(稀疏 grams) :不是所有 n-gram,而是按 sparseGrams 算法选取的"更稀疏、可变长度"的 grams(减少常见片段带来的噪声/假阳性)(ClickHouse) | 更偏"搜索/子串"场景:在很多文本中比固定 n-gram 更"挑剔"(通常更少 token → 更少误命中) | 支持 LIKE、match、startsWith、endsWith(函数支持表中 sparse_grams 为 ✔,而 bloom_filter 对 LIKE/match 为 ✗)(ClickHouse) |
sparse_grams(min_ngram_length, max_ngram_length, min_cutoff_length, size_bytes, hash_functions, seed)(ClickHouse);其中 min_cutoff_length 会让返回的 grams 长度 ≥ cutoff(函数说明)([ClickHouse](https://clickhouse.com/docs/data-modeling/projections?utm_source=chatgpt.com "Projections |
ClickHouse Docs")) |
结束语
过去几年里,ClickHouse几乎已经成了日志与分布式追踪数据存储的默认选择,并通过收购 Langfuse,进一步把自身延伸为模型训练与部署阶段的数据底座:既承担观测数据的沉淀,也覆盖面向应用与模型的监控能力。
与此同时,ClickHouse在 2024-09-03 推出 TimeSeriesEngine,开始以更细粒度的时间线存储能力补齐 metrics 版图;但无论是它还是国内的 GreptimeDB,当前的主要市场叙事仍然围绕 Prometheus 展开。问题在于,metrics 并不等同于 Prometheus:在公司级中台、车联网、物联网等场景里,metrics 往往是更广义、更强约束、更强业务化的数据形态,但是越来越多的metric开始变的基数更高,不再适合于传统的索引结构,需要向ClickHouse这样的架构演进,这也是Clickhouse、InfluxDB IOX、GrepTimedb等都将自己视为可观测性解决方案平台,而并不是垂类领域的解决方案系统。
从现实出发,ClickHouse的计算与存储引擎、数据导入导出链路、协议与生态适配都已极其成熟。若在有限资源下试图在日志与分布式追踪数据领域正面追赶它,我长期并不乐观。
参考:
- The ultimate guide to Open Source Observability in 2026: From silos to stacks
- ClickHouse vs Prometheus A detailed comparison Compare ClickHouse and Prometheus for time series and OLAP workloads
- TimeSeries table engine
- ClickHouse 营收与市值
- 中国社会各阶级的分析
- Apache Paimon: Streaming Lakehouse is Coming
- Apache Paimon: the Streaming Lakehouse
- Why continuous profiling is the fourth pillar of observability
- A practical introduction to primary indexes in ClickHouse
- Time Series Engine