C 端场景下分布式 KV 存储(如 Redis、Tair)随着业务逻辑的日益复杂、对象体积不断膨胀,大 Value 问题成为系统顽疾之一,危害系统稳定性与接口性能。
-
大 Value 数据如果读写频率较高,容易导致网卡流量较高触发流控,还容易硬盘的负载太高甚至导致引擎处理不过来而阻塞正常的写入。
-
大 Value 网络传输和内存拷贝本身就慢,服务端的内置缓存引擎不容易缓存大 Value,涉及的大 Value 读写基本都是经过硬盘,而且大 Value 在存储引擎上容易有严重的写放大问题,所以大 Value 处理性能会明显较差。
为了解决这一痛点,同时不牺牲系统的吞吐能力,针对性地设计出了一套基于 Fory 序列化与 Zstd 压缩的组合方案。这套方案的核心逻辑在于:利用 Fory 的极致性能解决序列化带来的 CPU 和耗时问题,利用 Zstd 的高压缩比与解压速度解决 KV 存储的大 Value 问题。
为什么是 Fory 与 Zstd
在传统 Java 服务端开发中,序列化通常使用 JDK 自带方案或 Hessian,压缩习惯使用 Gzip。但在 QPS 极高的场景下该组合性能差、系统压力大。
Apache Fory™(淘宝开源)是一个基于动态代码生成和零拷贝技术的多语言序列化框架,实现了无需 IDL 编译的原生多语言编程范式,并提供最高 170 倍的性能和极致的易用性。大幅提升大规模数据传输、高并发 RPC、分布式系统、云原生中间件等场景的性能,显著降低多语言系统的研发成本。
Zstandard(Facebook 开源)是一个提供高压缩比的快速压缩算法,采用了有限状态熵(Finite State Entropy,缩写为 FSE)编码器。该编码器是基于 ANS 理论开发的一种新型熵编码器,提供了非常强大的压缩速度/压缩率的折中方案(事实上也的确做到了"鱼"和"熊掌"兼得)。Zstandard 达到了 Pareto frontier(资源分配最佳的理想状态),因为它解压缩速度快于任何其他当前可用的算法,但压缩比类似或更好。
选型对比
序列化算法对比
在序列化层面,我们主要关注序列化速度(影响接口耗时)、码流大小(影响网络与存储)以及易用性。
| 序列化框架 | 序列化/反序列化速度 | 码流大小 | 易用性与兼容性 | 适用场景 |
|---|---|---|---|---|
| Fory | 极快 (JIT 加速) | 小 (支持类注册) | 高 (兼容 JDK 序列化,无需 IDL) | 高性能 Java 应用,内部 RPC/KV |
| Hessian2 | 中等 | 中等 | 高 (兼容性好) | 传统 RPC,对性能要求不严苛 |
| Protobuf | 快 | 极小 | 低 (需编写.proto 文件) | 跨语言交互,Schema 稳定的场景 |
| JDK 原生 | 慢 | 大 | 高 (开箱即用) | 不推荐用于高并发生产环境 |
| Kryo | 极快 | 小 | 中 (需处理线程安全) | 大数据处理,Spark/Flink |
Fory 在保持了 Java 原生兼容性的前提下,提供了接近甚至超越 Protobuf 的性能,且不需要维护复杂的 IDL 文件。
压缩算法对比
在压缩层面,我们重点关注压缩率(节省空间)与解压速度(影响读取 RT)。
| 压缩算法 | 压缩率 | 压缩速度 | 解压速度 | 特点 |
|---|---|---|---|---|
| Zstd | 高 | 快 | 极快 | 综合性能最强,平衡了空间与时间 |
| Gzip | 高 | 慢 | 慢 | CPU 消耗大,高并发下易导致 RT 抖动 |
| LZ4 | 低 | 极快 | 极快 | 速度最快,但压缩率较低,大 Value 优化有限 |
| Snappy | 低 | 快 | 快 | Google 出品,性能介于 LZ4 与 Gzip 之间 |
Zstd 在压缩率上完胜 LZ4,在解压速度上完胜 Gzip,达到了 Pareto frontier。
最佳实践
整体流程
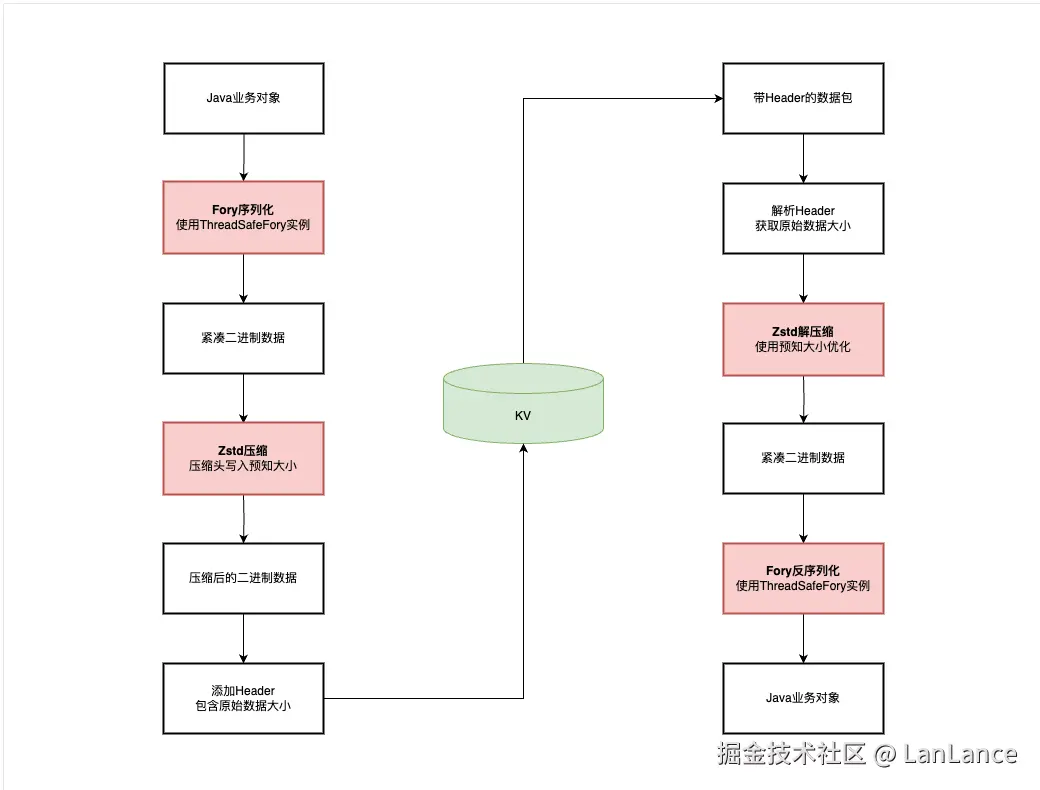
Fory 实例复用
创建 Fory 成本很高,始终复用实例,严禁在每次请求中通过 new Fory() 创建实例,应使用 ThreadSafeFory 或者 ThreadLocal 来复用实例。同时按 ID 注册类会有更好的性能和更小的空间开销。
java
private static final ThreadSafeFory FORY_INSTANCE;
private static final Map<Class<?>, Integer> REGISTERED_CLASSES_WITH_IDS = new LinkedHashMap<>();
static {
REGISTERED_CLASSES_WITH_IDS.put(LbsRecallCacheBO.class, 1);
REGISTERED_CLASSES_WITH_IDS.put(ActivityPoiDocument.class, 2);
REGISTERED_CLASSES_WITH_IDS.put(SkuSolrVo.class, 3);
REGISTERED_CLASSES_WITH_IDS.put(PoiScore.class, 4);
}Zstd 解压精确分配
Zstd 在解压时,如果能预先知道解压后的数据大小,就可以直接分配精确的内存空间,避免多次内存扩容或分配过大的缓冲区。最佳实践是在压缩后的字节数组头部手动写入原始数据的长度(或者使用 ZSTD_getFrameContentSize API)。
java
public static byte[] serializeAndCompress(Object object) {
try {
if (object == null) {
return new byte[0];
}
byte[] serializedData = FORY_INSTANCE.serializeJavaObject(object);
if (serializedData == null || serializedData.length == 0) {
LOGGER.warn("Serialized data is empty for object: {}", object.getClass().getName());
return new byte[0];
}
byte[] compressedData = Zstd.compress(serializedData, ZSTD_COMPRESSION_LEVEL);
ByteBuffer buffer = ByteBuffer.allocate(HEADER_SIZE + compressedData.length);
buffer.putInt(serializedData.length);
buffer.put(compressedData);
return buffer.array();
} catch (Exception e) {
LOGGER.error("Fory+Zstd serialization failed for object: {}", object.getClass().getName(), e);
throw new RuntimeException("Fory+Zstd serialization failed", e);
}
}优化效果
某核心营销页面(脱敏)正常召回 TP90 59.4ms,使用缓存召回 TP90 1.6ms,同时午高峰该页面缓存命中率 80% 左右。且在 10 万 QPS 的入口流量下 TP90 能够保证 2ms 以内,Value 大小均小于 100Kb。