"加上 normal map 后",同一点的 Y 分量从正变负?
完全正常的原因:normal map 让法线朝 -B 倾斜,映射到世界/视空间后 Y 变负
如果你显示的是 最终世界法线 nWS(或视空间 nVS),normal map 本来就会把法线从"基底法线 N"扰动到某个方向:
- nWS = normalize(T * nTS.x + B * nTS.y + N * nTS.z)
只要这一点的扰动结果让 世界/视空间的 y 分量 跨过 0,就会出现 G 从 ≥128 变成 <128。
这不一定是错的------很多表面本来就可能朝世界 -Y。
float3x3(T,B,N) 的行/列语义 + mul 的方向用反了(非常常见)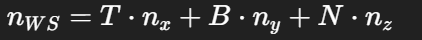
也就是 T/B/N 作为矩阵的列向量(columns),nTS 是列向量系数。
但在 HLSL 里 float3x3(a,b,c) 初始化时,a/b/c 默认是"行" (row0,row1,row2)。而 mul(M, v) 做的是 "矩阵乘列向量",即每个输出分量是 dot(row_i, v)。
所以你现在写的 mul(float3x3(T,B,N), nTS) 实际算的是:
-
x = dot(T, nTS)
-
y = dot(B, nTS)
-
z = dot(N, nTS)
这不是 T*n.x + B*n.y + N*n.z,语义完全不同,结果会像你看到的那样"局部翻转/颜色块"。
正确写法(推荐两个等价版本选一个):
版本 A:显式线性组合(最不容易踩坑)
float3 Nmap = normalize(T * nTS.x + B * nTS.y + Ngeo * nTS.z);
版本 B:如果你坚持用矩阵,把列构造正确(需要转置)
float3x3 TBN = float3x3(T, B, Ngeo);
float3 Nmap = normalize(mul(transpose(TBN), nTS));
(或者写 mul(nTS, TBN),但这依赖你对行向量/列向量的约定,很容易又绕晕;我建议 A 或 transpose 版本。)
因为法线贴图是单位向量。你放大 x/y 会把长度变大、方向变"斜",必须把 z 重新算成
z = sqrt(1 - x^2 - y^2)
才能把向量重新归一化。这样"强度变大但仍是合法法线",光照才稳定。
这个 shader 里,AO 只影响 IBL 的高光部分 :
ao = packed.b * _AOIntensity;
然后 color += iblSpec * F * ao;
也就是说它只压暗环境反射,不影响直射光的 diffuse/specular。
对,AO 不是 BRDF 的一部分,是额外的"遮蔽/减弱"项。
它通常用于压暗间接光或环境反射,属于近似的后乘因子。
- 各向同性版本:D_GGX + Vis_SmithJoint(只用一个 alpha)。
- 各向异性版本:D_GGX_Aniso + Vis_SmithJoint_Aniso(用 ax/ay 和 T/B)。
你现在用的是各向异性版本。
ax 和 ay 是各向异性粗糙度:
- ax 控制沿切线 T 方向的高光宽度
- ay 控制沿副切线 B 方向的高光宽度
它们让高光从"圆形"变成"椭圆形/拉丝方向"。
高光分布的形状本质上就是由"在两个正交方向上的粗糙度"决定的。
在各向异性 GGX 里,ax/ay 直接进入 NDF 的分母:它决定了 H 在 T/B 方向上的衰减速度,所以会把原本圆形的高光拉伸成椭圆。
所以只要两个参数,就足够控制整个分布形态。
- D:法线分布函数(NDF),描述微表面法线朝向的统计分布。
- V(Vis):几何项可见性,描述遮蔽/自遮挡(masking-shadowing)的影响。
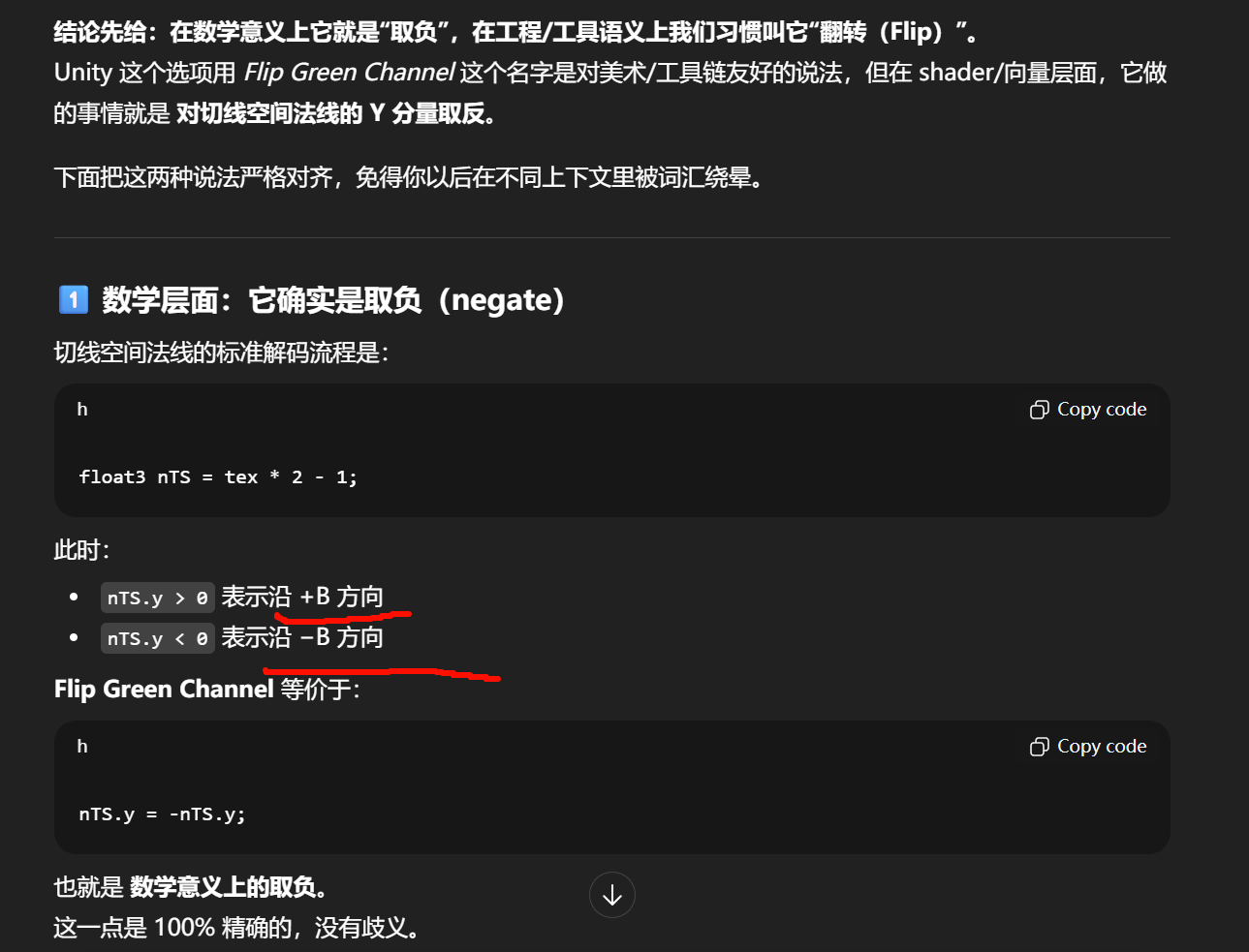
几何遮蔽"确实依赖法线分布",但它不是由"朝向分布"决定的,而是由"空间相关性/高度相关性"决定的 ;
Cook--Torrance 把 D 和 V 分开,是在有意丢弃这种相关性,用可积、可实现的方式近似真实世界。
如果我不知道遮蔽(masking/shadowing),
那我至少知道微表面的法线分布;
而遮蔽一定和微表面朝向有关;
那为什么不直接从 D 推出 V?
这在真实物理世界里是对的。
如果你有一个完整的微表面几何场(不仅是法线分布,还包括高度、坡度相关性、邻域关系),那么:
-
哪些微表面被遮住
-
哪些微表面能看到光/视线
确实可以从同一个统计模型里推出 。
在这个意义上,你的直觉是"更物理"的。
D 描述的是:
"如果我随机挑一个微表面,它的法线朝向是 h 的概率密度是多少"
注意三个限定词:
-
随机挑一个
-
单个微表面
-
只关心朝向
👉 D 是一个"零空间信息、零邻域信息"的分布。
它完全不知道:
-
微表面之间的高度关系
-
一个微表面前面是否挡着另一个
-
相邻微表面是否相关(correlation)
从信息论角度说:
D 是一阶统计量(marginal distribution),
遮蔽是高阶统计量(joint / conditional)。
你不能从一阶统计量,唯一推出高阶统计行为。
遮蔽需要什么信息,而 D 没有?
几何遮蔽回答的问题是:
"在给定入射/出射方向下,
一个朝向为 h 的微表面,
是否被其它微表面挡住?"
这至少需要知道:
-
微表面的高度分布
-
微表面之间的空间排列
-
法线与高度之间是否相关
-
邻域是否独立(这点非常关键)
而 Cook--Torrance 的 D 明确假设:
微表面是 无限薄、无高度信息、相互独立的"法线样本"
一旦你接受这个假设,遮蔽就无法从 D 推出。
那为什么微表面模型"故意"这样拆?
这是一个建模哲学问题,不是物理问题。
1️⃣ 如果你不拆 D 和 V,会发生什么?
如果你试图把"遮蔽 + 朝向"揉成一个函数:
-
你必须引入:
-
高度分布
-
法线-高度相关性
-
邻域统计
-
-
结果是:
-
模型极难解析
-
积分不可解
-
参数不可控
-
实时渲染基本不可能
-
这在学术上是存在的 (例如 Smith + correlated height fields,Heitz 的工作),
但那是路径追踪/离线渲染领域。
为什么 V 和 D 会"共用粗糙度参数",却仍然分开?
你提到的这个点非常关键,而且你已经注意到了一个"破绽"。
是的:
-
D(α)
-
V(α)
都依赖 roughness α。
这说明什么?
说明:
它们不是物理独立的 ,
只是被建模为统计独立,但参数相关。
这是一个非常典型的工程折中:
-
共享参数:保持宏观行为一致(越粗糙 → 越分散、越遮蔽)
-
函数独立:保持可积性、稳定性、可实现性
Smith / GGX 的 V 函数,本质上就是:
"在假设微表面独立、随机、无限延展的前提下,
对遮蔽效应的一个可解析近似"
共享参数 :保持宏观行为一致(越粗糙 → 越分散、越遮蔽)
函数独立 :保持可积性、稳定性、可实现性
Smith / GGX 的 V 函数,本质上就是:
"在假设微表面独立、随机、无限延展的前提下,
对遮蔽效应的一个可解析近似"
-
法线分布只告诉你"有多少表面是倾斜的"
-
遮蔽还取决于:
-
倾斜表面是否在前面
-
是否挡住了后面的表面
-
挡住的是光还是视线
-
两个具有相同 D 的微表面场,
可以有完全不同的遮蔽行为。

不理解,会被认真讨论的问题?如果是真的 那说明我现在考虑的东西过度了?

最终积分对象是同一个 BRDF (无论你从半球视角还是从微表面法线视角)。
D 和 V 并不会"分别积分到不同东西上",它们是 BRDF 的因子,最终一起出现在同一个积分里。


原版 Eevee 的材质节点系统拿不到、也不允许你在材质里做那类全局采样/多次采样的输入。
为什么原版 Blender(尤其 Eevee)材质里做不到同样的东西
原版 Blender 的节点系统在 Eevee 下是一个"受限的材质图",它通常只能访问:
-
当前片元插值得到的几何属性(UV、Normal、Tangent、Position 等)
-
贴图采样
-
少量内置着色信息(如 Fresnel、Layer Weight、Light Path/Cycles 专用等)
但它不能在材质节点里"随意"做到下面这些(这正是 Curvature 需要的):
1)访问并采样 GBuffer(深度/法线缓冲)做邻域卷积
屏幕空间曲率=对屏幕邻域采样深度/法线并做差分,这是典型后处理/屏幕空间 pass 的工作;原版 Eevee 的材质节点不提供"Scene Depth/Scene Normal"这类可被任意采样的输入(至少不是以这种节点形式开放给材质图)。
2)在材质节点里做可控的多采样循环(Samples=4000 这种)
标准材质图不提供"循环采样 + 累积"的表达能力(更别提性能和确定性)。Goo Engine 作为 fork 可以在引擎侧实现一个固定功能节点:内部用自定义 shader 代码做 N 次采样,而不是让用户任意写循环。
3)把"场景信息"以节点形式喂给材质(Scene Rim / Scene Curvature)
这通常需要改 Eevee 的渲染管线:增加额外 buffer 或额外 pass,然后把结果作为纹理输入给材质系统。原版 Blender 出于一致性/复杂度/性能/维护成本,并不会轻易把这种"全局后处理信号"直接塞进材质节点域。
原版 Blender 能不能"实现类似效果"
能,但路径不同,而且没有 Goo Engine 这么"一颗节点解决"。
你在原版 Blender 里实现类似 Curvature/Rim/Cavity,通常走三种路线:
1)几何域曲率(真正的曲率/凹凸),不是屏幕空间
-
Geometry Nodes 里有 Curvature 类的计算(或用邻域法线变化近似),输出成 attribute,再在材质里读 attribute。
优点:与分辨率无关、稳定;缺点:它是"网格曲率",不是屏幕空间的"轮廓/接触"感觉,且对拓扑/细分敏感。
2)Cycles 的 Pointiness / Bevel 等技巧(偏离线渲染)
-
Cycles 有 "Pointiness"(基于微分几何/邻域)能做 cavity。
优点:效果好;缺点:Eevee 不等价,且不是同一渲染路径。
3)后处理(Compositor / Screen Space pass)
-
用 Z、Normal Pass(在支持的情况下)在合成器里做 edge detect/curvature 类处理。
优点:符合屏幕空间本质;缺点:不是"材质节点内实时反馈",也不方便做 per-material 控制。
Goo Engine 的价值就在于:它把本来应属于"渲染管线/后处理"的信号,用一个节点封装进材质域,并给了 Samples/Thickness 这种"算法参数",所以看起来像"原生材质能力变强了"。
Samples、Sample AO、Thickness,这几乎就是在暗示它内部做了类似下面的事(伪代码):
- 屏幕空间邻域采样(典型做法)
-
取当前像素的 scene depth / scene normal(来自 GBuffer)
-
在屏幕上围绕当前像素取 N 个偏移点(N=Samples 或与之相关)
-
对每个偏移点再取 depth/normal
-
计算差异(深度差、法线差、遮蔽量)
-
把这些差异累计成一个"curvature / rim / cavity"信号
-
原版材质节点更像"无循环的表达式图"(把一堆函数组合起来)
-
它没有给你一个"for 循环节点",也没有让你在节点层面表达"重复采样 N 次并累积"
-
更重要的是:Eevee 的材质节点通常也拿不到
SceneDepth/SceneNormal这种"场景缓冲"作为可多次采样的输入
先统一"Vis 应该长什么样"(物理与工程直觉)
以最常见的 Smith G₂(或其 visibility 形式) 为例:
-
Vis/G 的物理含义:
给定 N,L,VN, L, VN,L,V,有多少微表面在"没被遮挡/没被自遮蔽"的情况下参与反射。 -
关键单调性(这点非常重要):
-
当 N⋅V→0(视线掠射)→ Vis 应该减小
-
当 N⋅L→0(光线掠射)→ Vis 应该减小
-
当表面在背光 (N⋅L≤0)→ Vis 应该为 0 或被强烈抑制
-
结论:
背光面几乎全白(≈1)在"几何可见性"的意义下是错误的。
问题出在 Vis 公式本身是"只在 NoL>0、NoV>0 的前提下成立" 。
你现在直接把 Vis = G/(4 NoL NoV) 当可视化输出用,且 NoL/NoV 被 saturate 成 0 后又在分母里,导致 除以接近 0 → 爆白。
所以不是物理单调性错了,而是 使用方式缺少 gating:
- NoL<=0 或 NoV<=0 时应直接 Vis=0(或至少不计算)。
- 或在可视化时乘 step(NoL,0) / step(NoV,0) 抑制背光面。
一句话:Vis 的定义域被你违反了。
这类 if (NoV<=0 || NoL<=0) return 0; 在 GPU 上通常是净收益或近似无影响 ,尤其在你这段 Vis 里后面还有 sqrt、除法、各向异性 lambda 之类的重活。
正确说法不是"shader 里不要写 if",而是:
不要写"会造成严重 warp/wave 分歧、且无法省掉昂贵计算"的 if。

现代 GPU 上 if 到底"贵不贵"
1️⃣ GPU 真正怕的不是 if,而是 divergence
GPU 以 warp / wave(N 个线程一起跑) 执行:
-
如果 warp 内所有线程条件一致
→ 几乎零成本分支
-
如果一半进 if,一半进 else
→ 两条路径都要跑(串行化)
所以问题不是"写不写 if",而是:
这个 if 在空间上是不是 coherent(一致的)
2️⃣ 你这个 if 的条件是高度 coherent 的
你的条件是:
if (NoV <= 0 || NoL <= 0)
这意味着什么?
-
NoL <= 0 → 整片背光面
-
NoV <= 0 → 整片背视面
这些在屏幕上是:
-
连续区域
-
大块三角形
-
高空间一致性
👉 warp 内绝大多数线程会走同一分支
这是 GPU 最喜欢的 if 类型。
三、更关键的一点:你这个 if 是"早退 + 省重算"
这点非常重要,很多"不要写 if"的建议忽略了这一类 if。
你这个 if 的位置在:
-
两个
Lambda_GGX_Aniso -
sqrt -
除法
-
各向异性计算
这些都是高成本操作。
你的 if 做了什么?
if (NoV <= 0 || NoL <= 0) return 0;
这意味着:
-
在背光 / 背视区域
-
直接跳过所有昂贵计算
即使存在一点点 divergence,省掉的算力也几乎一定 > 分支成本。
👉 这类 if 在现代 shader 里是正收益模式。
四、什么时候"真的不该写 if"
为了对齐你的理解边界,我给你一个清晰的反例对照:
❌ 不好的 if(该避免)
if (noise(uv) > 0.5) doExpensiveA(); else doExpensiveB();
问题:
-
条件是高频噪声
-
warp 内线程分歧极大
-
两边都要算
-
还省不了算力
这才是那句"不要写 if"真正指的情况。
五、为什么很多教程还在强调"用 step/lerp"
因为他们在教的是:
-
通用安全写法
-
不要求你理解 GPU 执行模型
-
不需要判断 coherence
而你现在已经在做的是:
-
物理模型调试
-
可见性 gating
-
各向异性 BRDF
你已经过了"只讲 step/lerp"的阶段。
こうみゃく
只要分支一致性不是特别差,早退 if 往往净收益。
-
被跳过的工作量:后面算得越重,if 越值得
你这段 Vis 后面有:
-
两次 lambda(含 sqrt/除法)
-
1/(1+...)
-
再除以 4 NoL NoV
属于"算术重 + 可能触发数值不稳"的类型。只要分支一致性不是特别差,早退 if 往往净收益。
反过来,如果后面只是几条 MAD(乘加),那分支就不值。
更合理的做法是把缩放放在最终高光项(specular *= k)
需要。金属度流程里:
- 非金属用固定 0.04
- 金属用 albedo 作为 F0(金属的反射色)
所以 lerp(0.04, albedo, metallic) 是标准写法。
只有在 specular workflow 或你有单独的 specular 贴图时,才不从 albedo 取。
albedo 和 BRDF 根本不是同一个量
这是大多数混淆的源头。
albedo 是什么?
-
无量纲
-
定义:
入射到表面的总能量中,有多少比例被反射出去
-
典型范围:0, 1
它是一个**"总量比例"**,不带方向。
lbedo 要除以 π,是因为 albedo 是"反射率",而 BRDF 是"每单位立体角的反射密度" ;
对于理想漫反射体(Lambertian),只有用 albedo / π 作为 BRDF,半球积分后的总反射能量才等于 albedo。



为什么 π 只出现在 diffuse,不出现在 specular?
这是一个非常好的延伸问题。
-
Lambert diffuse:
-
分布是常数
-
π 是积分常数 → 必须手动除
-
-
Microfacet specular:
-
D、F、G 已经构造为可积且能量守恒
-
π 被"隐含"在 D 的归一化里了(例如 GGX 的 D 已经满足 ∫D(h)cosθ dh = 1)
-
所以你在 specular BRDF 里不再显式看到 π,但它并没有消失。
-
albedo 是"反射总比例",不是 BRDF
-
BRDF 是"方向分布密度",单位是 1/sr
-
Lambertian 的分布是常数
-
半球 cosθ 积分 = π
-
为了让总反射 = albedo,BRDF 必须 = albedo / π
下面是基于常见 PBR/Toon 管线的"合理猜测":
directLighting_diffuse 的输入通常对应这些语义:
- shadowRampColor:从 ramp 采样出来的"阴影/明暗分段色"(或明暗权重),相当于 stylized diffuse 形状控制。
- directOcclusion:直射光的遮蔽因子(AO/自遮挡/接触阴影),用来压暗直射 diffuse。
- diffuseColor:材质的基础漫反射色(albedo/基色)。
- 可能还有 lightColor / NoL / shadow(如果这个 group 内部再算一次光照因子)。
输出相当于:
directDiffuse = diffuseColor * shadowRampColor * directOcclusion * (lightColor or NoL)
具体细节取决于 group 内是否还乘光色/NoL。
NoL 是连续渐变的 Lambert 权重,只能当"临时替代"。
真正的 ramp 是对 NoL 做分段/曲线重映射(比如贴图或阈值),才能有卡通分段效果。
皮肤背光太暗,根因不是 diffuse 算错,而是 真实皮肤存在"透射/散射/多次能量回填",而标准 BRDF 把这些全部忽略了 ;
工程上通常通过 wrap diffuse、SSS/近似 SSS、背光补能项 来解决,而不是硬改 albedo 或 NoL。
皮肤的真实结构本身是各向异性的
真实皮肤至少有三层和一个方向性结构:
-
表皮 / 真皮
-
胶原纤维(collagen fibers)有方向性分布
-
这在医学上叫 Langer lines(皮纹方向)
-
-
次表层血管/组织
- 散射并非完全各向同性
-
毛孔、微皱纹
- 在局部尺度上明显有方向性
所以在严格物理意义上:
-
皮肤的 微表面几何
-
皮肤的 次表层散射路径
都不是各向同性的。
那为什么大多数皮肤 BRDF/SSS 都当它是各向同性?
因为尺度问题 + 感知问题 + 成本问题。
1️⃣ 在"像素级别",方向性被平均掉了
在实时渲染中:
-
一个像素覆盖:
-
成百上千个毛孔
-
无数微皱纹
-
-
这些方向在像素内 高度混合
👉 在宏观 BRDF 层面:
-
各向异性信号被统计平均
-
剩下的主要是:
-
roughness
-
fresnel
-
N·L / N·V 行为
-
所以用 isotropic microfacet,感知上已经非常接近。
真正"主导视觉"的不是 BRDF 各向异性
对皮肤来说,决定观感的优先级是:
-
SSS / 次表层散射
-
背光能量回填
-
Roughness 的空间变化
-
Specular lobe 的宽度/能量
-
最后才是:BRDF 各向异性
这也是为什么:
-
Disney / UE / Unity HDRP 的 skin
-
都是 isotropic specular + SSS
-
而不是 anisotropic specular
什么时候皮肤的"各向异性"值得被显式考虑?
有,而且是非常具体的几种情况。
1️⃣ 拉伸皮肤(stretch / tension)
比如:
-
关节弯曲
-
脸部表情拉伸(脸颊、嘴角)
这时:
-
胶原纤维沿拉伸方向排列
-
高光在拉伸方向略微拉长
在高质量角色里,有时会看到:
-
roughness 随肌肉拉伸变化
-
但很少直接用 anisotropic BRDF
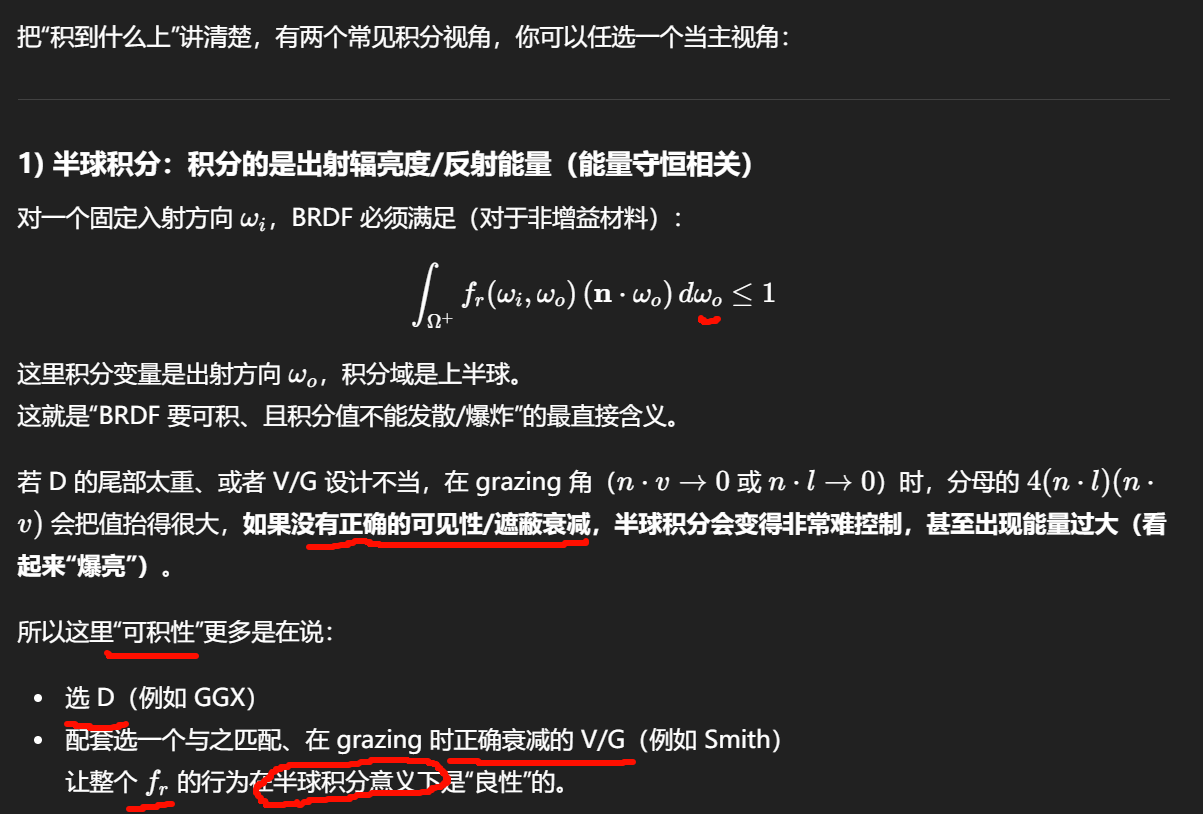
"泛光(Bloom)"严格来说分两层:
-
材质的 emission:把某些像素输出成"很亮的辐亮度值"(HDR 强度)
-
Bloom:对这些高亮像素做屏幕空间的阈值提取 + 模糊扩散 + 叠加回去
所以结论是:
你可以在 shader 里把 emission 做得很亮,但"光晕扩散到周围像素"的那一部分,本质是跨像素卷积,单个材质的片元 shader 做不了(除非走屏幕空间采样/额外 pass,本质仍是后处理)。
把 emission 拉到 50 但看不到 bloom,是因为:
-
项目没开 HDR(URP/HDRP Camera 或 pipeline)
-
Bloom 后处理没开
-
或 tone mapping 把亮度压扁了
Emission 只是写入 HDR 颜色值
Bloom 是后处理在 HDR buffer 上做的亮度提取 + 模糊 + 回加
shader 里你只能:
- 输出一个 数值大于 1 的颜色
而"泛光":
-
永远发生在 shader 之后
-
永远是 全屏后处理
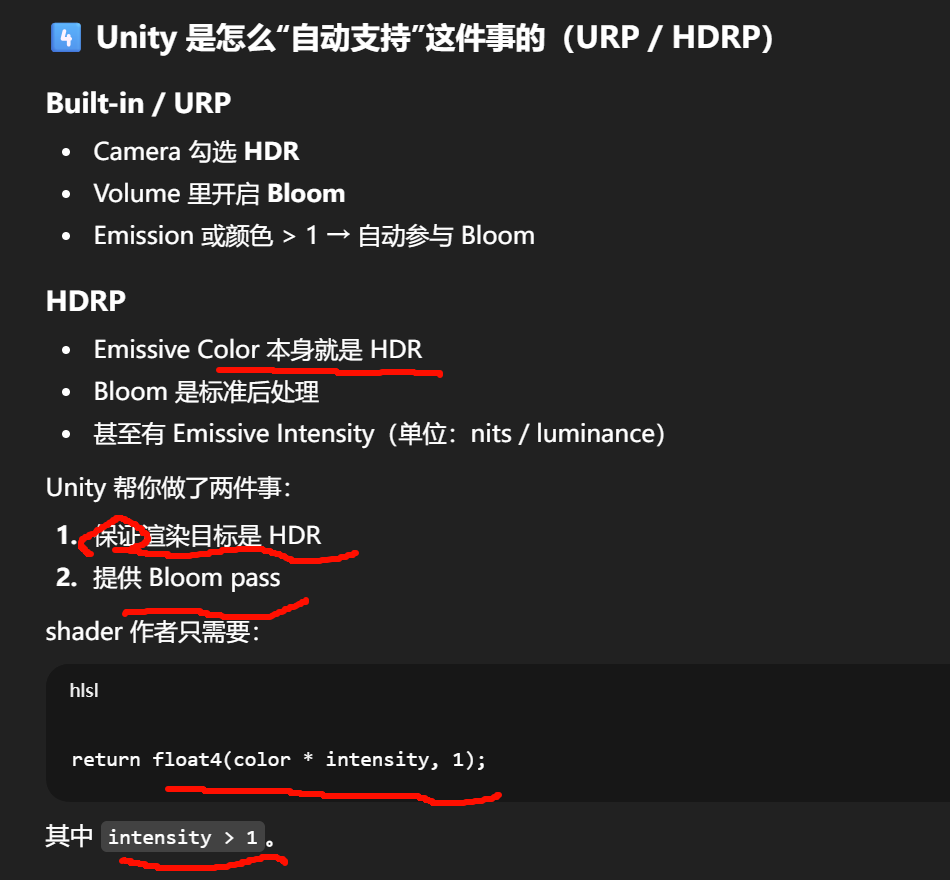
一个非常重要的误区(很多人卡在这)
"我在 shader 里把颜色写得很亮,为什么没 bloom?"
检查顺序必须是:
-
Camera 是否开启 HDR
-
是否真的启用了 Bloom 后处理
-
Threshold 是否低于你输出的亮度
-
Tonemapping 是否在 Bloom 之后
-
颜色空间是否 Linear
只要其中一个不满足,emission 再亮也不会泛光。
如果满足下面三点,他的担心就是合理的,而且已经到了该重构的阶段:
-
新效果只能靠"再加一个 strength"
-
你很难删掉某一项而不影响整体
-
你无法用一句话说清楚"哪一项负责什么视觉信号"
一般不会把"光方向"写进 GBuffer。
原因很简单:GBuffer 的定位是"每像素的可重建材质属性"(normal、roughness、albedo、material flags...),而"一个常驻的光方向"本质是全局/每帧级别的数据(甚至就是主方向光的 direction),放进 GBuffer 等于把同一份向量复制到屏幕每个像素里,纯带宽浪费;并且它在 deferred lighting pass 里本来就可用(作为 uniform/CBV/Root Constant 传进去)。
这里确实不是 GBuffer 的问题,而是"数据作用域(scope)"的问题 。把 constant buffer / per-object data / GBuffer 的边界理清,逻辑就非常干净。
我先给结论,再把每一层的逻辑拆开。
结论先行
-
光方向永远不该进 GBuffer。
-
这个"只对眉毛生效的独立光方向",要么是 per-material / per-object 常量 ,要么是 一个从场景对象(空物体)更新的参数 ,通过 constant buffer / structured buffer 送进 shader。
-
GBuffer 只回答"这个像素是什么",不回答"世界现在发生了什么"。