Transformer底层原理---Decoder结构
本系列文章详细介绍Transformer架构,请参考往期文章:
Transformer原理------注意力机制Transformer原理------位置编码Transformer原理------Encoder结构Transformer原理------Dncoder结构(上)Transformer原理------Dncoder结构(下)
一、完整Transformer与Decoder-only结构的数据流
Decoder 结构是 Transformer 中至关重要的结构,这不仅仅是因为Decoder 是专门设计用来处理输出序列生成的结构,更是因为Decoder 的用法非常灵活并且复杂。在之前 Encoder 的课程中,我们讲解了数个 Encoder`-Only` 结构的使用场景,在` `Transformer 丰富的用法中,我们还可以选择使用按照完整的 Encoder`+`Decoder 结构、或者 Decoder-only 架构------
- 使用完整
Transformer结构的任务
完整的
Transformer结构包括编码器(Encoder)和解码器(Decoder)部分,通常用于需要将一个序列映射到另一个序列的任务,如:
- 机器翻译(Machine Translation):
- 将源语言的句子翻译成目标语言的句子。例如将英文句子翻译成中文句子。
- 文本摘要(text Summarization):
- 将长文本总结为简短的摘要,例如将新闻文章总结为简短的新闻标题。
- 图像字幕生成(Image Captioning):
- 为给定的图像生成描述性的文字(图生文)
- 文本到语音(text-to-Speech, TTS):
- 将文本转换为语音信号,比如将输入文本转换为自然的语音输出。
- 问答系统(Question Answering):
- 根据上下文回答用户的问题,或者给定一段文本,回答其中提到的具体问题。
- 只使用
Decoder结构的任务
只使用
Decoder结构(通常被称为自回归模型或生成模型)适用于需要从部分输入生成完整序列的任务,如:
大语言模型(Language Modeling):
- 任务描述:预测给定文本序列中的下一个词或字符,例如GPT系列模型用于生成连续的文本段落(当然,并不是所有的大语言模型都是
Decoder-only结构)。文本生成(text Generation):
- 任务描述:根据部分输入生成完整的文本,比如根据开头的一句话生成一篇文章或故事,根据部分诗句生成完整的诗歌。
代码补全(Code Completion):
- 任务描述:根据部分输入代码生成完整的代码段。
对话生成(Dialogue Generation):
- 任务描述:根据对话历史生成下一句回复。
问答系统(Question Answering):
- 根据上下文回答用户的问题,或者给定一段文本,回答其中提到的具体问题。
这些任务利用Transformer的强大表示能力,通过不同的结构来适应不同的应用场景。完整的Transformer结构适合需要从一个序列转换到另一个序列的任务 ,一般我们会在需要高度依赖原始数据信息、尤其是需要语义的转译 的时候使用这种结构,因为Encoder会有非常好的语义和数据信息解析功能,可以帮助架构更好地吸收原始数据的信息;而只使用Decoder结构的模型适合需要生成连续序列的任务 ,当我们更强调基于原有的信息基础上进行"创新、创造、续写",而对原有的数据的依赖程度不是那么高时,我们会选择Decoder-only结构。
当然了,一个任务对于原始信息的依赖程度是否高,这是可以讨论、甚至因人而异的判断。像机器翻译任务,最好能够原封不动将原始数据的语义表达出来,就会显然更适合完整的Transformer结构,但代码补全这样的、文本生成这样更强调续写的任务,就会更偏向于Decoder-only,然而对于像大语言模型、对话系统这样无法明确判断出"多大程度依赖于原始输入信息的"任务,就会依据算法创造者的不同选择有不同的状态。例如大语言模型,GPT、llama等等大模型就是``Decoder-only结构,BERT模型是Encoder-only 结构、T5(text-to-text Transfer Transformer)和BART(Bidirectional and Auto-Regressive Transformers)模型则是使用了完整的Transformer结构。
为什么在Decoder篇章一开始,我们就要讲解不同的任务呢?与Encoder不同的是,Decoder结构在不同的任务中承担不同的角色、存在不同的网络架构、不同的训练模式以及不同的数据流,因此我们需要理解不同的任务、才能知道Decoder结构究竟是什么样的。接下来,就让我来看看Transformer完整结构与Decoder-only结构下的具体情况。
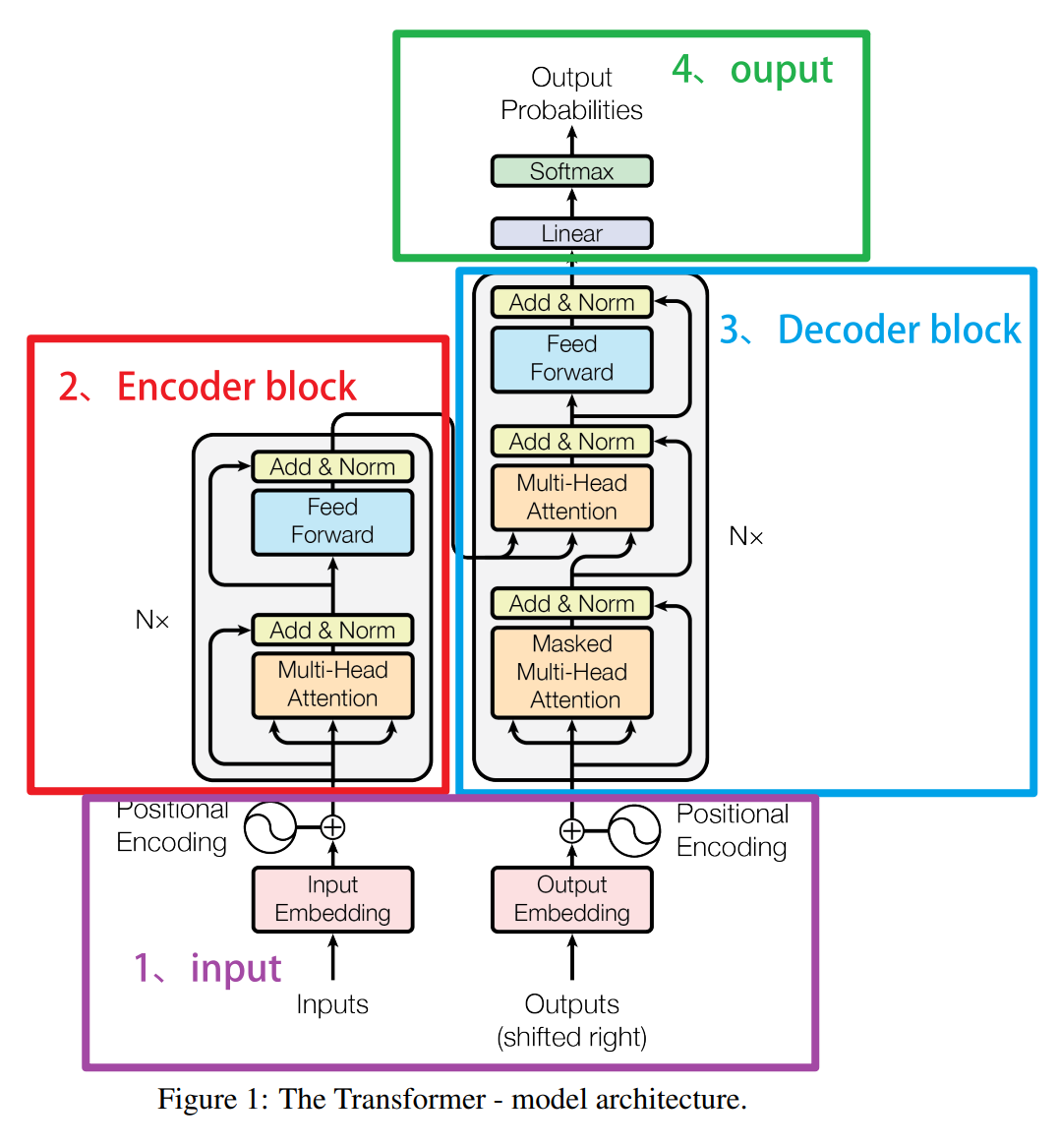
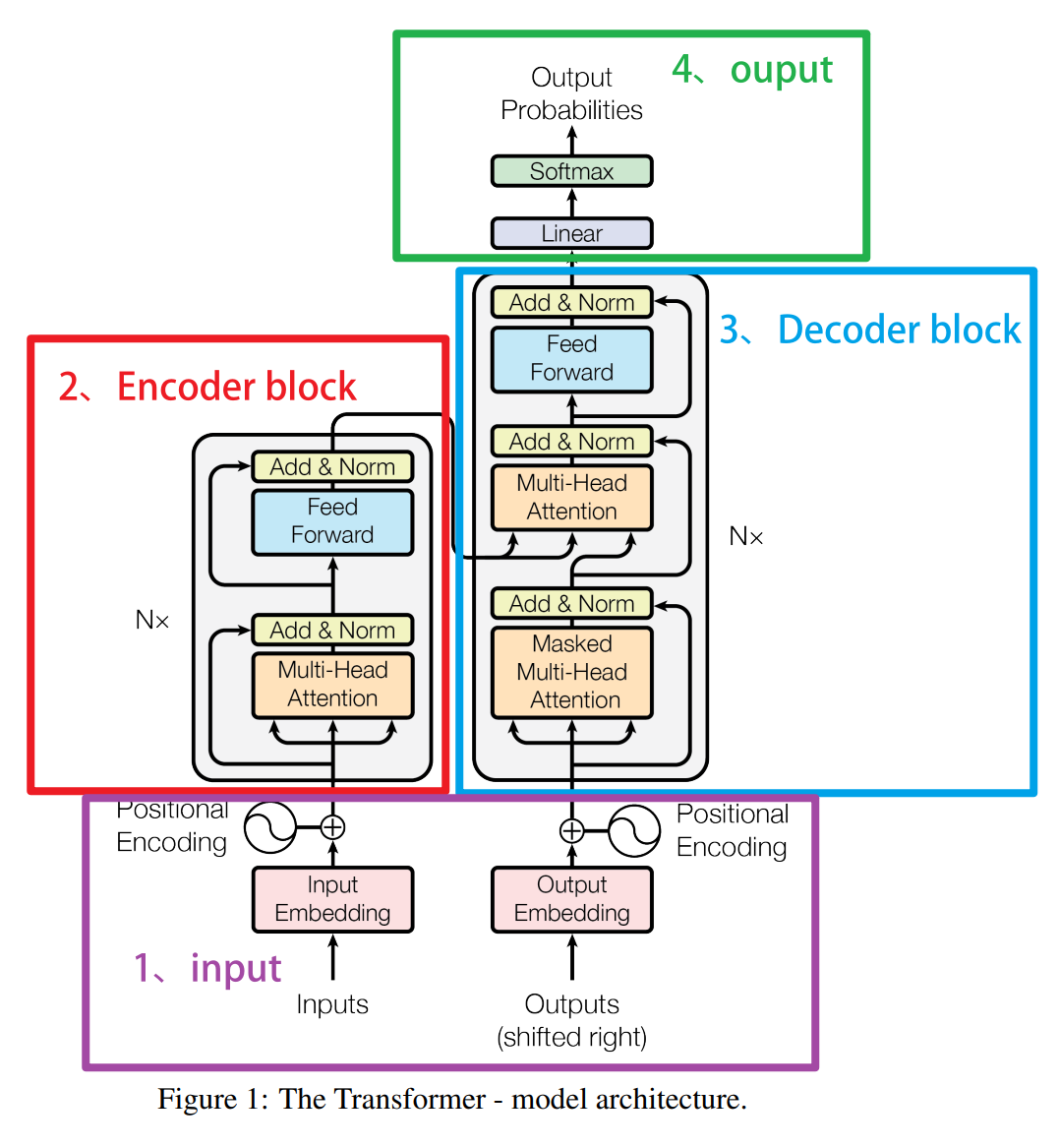
二、Encoder-Decoder结构中的Decoder
上图所示的就是Transformer完整结构下的Decoder block 的结构。之前在讲解Trans整体架构时我们就提到过,Decoder其实与Encoder非常类似,从图上来看,整个Decoder的结构包括如下核心内容:
-
输入与teacher forcing机制
Decoder的输入是滞后1个单位的标签矩阵 (shifted right outputs),我们要将真实标签输入给模型,并且让真实标签指导模型的学习与预测,这种让模型通过正确的标签来学习的流程在Transformer中被称之为是teacher forcing强制教学机制。 -
Embedding与位置编码
标签矩阵首先通过嵌入层(embedding)转换成固定大小的向量。就像
Encoder一样,Decoder也会对这些嵌入向量添加位置编码,以包含序列中的位置信息。但这里需要注意的是,输入到Decoder层中的sequence_length维度可以与输入到Encoder中的sequence_length维度不一致。
Encoder与Decoder架构中的Seq_len可以不一致,这其实非常好理解。假设是英文翻译成中文的机器翻译任务,为了表达相同的语义,英文句子长度与中文句子长度都应该不受限制,尽量精准地表达;不同语言、不用序列之间的规律本来就各不相同,有的语言比较高效、有的语言则追求尽量详尽,因此要求Encoder和Decoder的输入的数据长度相同是强人所难。
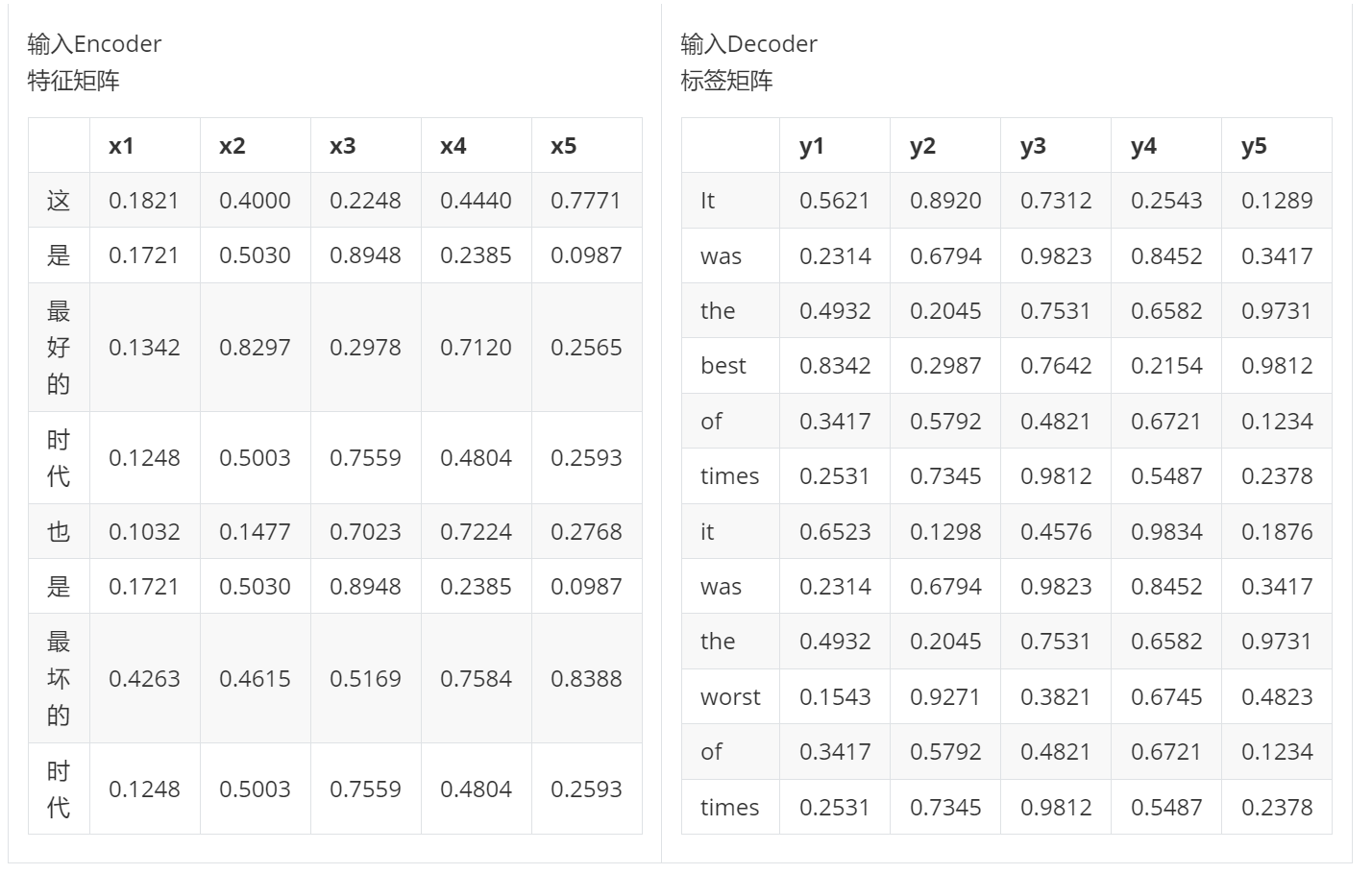
不过这里就会引发无穷的问题,比如结构不相同的矩阵如何在同一个注意力机制中运行?最终输出的矩阵结构是什么?
Decoder后续的结构会帮助我们解决这些问题。
-
带掩码的自注意力层 (
Masked Self-Attention)Decoder的自注意力层在功能上与Encoder的自注意力层类似,它允许Decoder关注到之前所有生成的词。然而,为了防止在生成当前词时使用未来的信息(即避免信息泄露),使用了所谓的"掩码"技术(Masking)。这种技术通过将未来位置的值设置为负无穷大(在 softmax 操作前),使得这些位置的影响力为零。 -
编码器-解码器注意力层(`Encoder-Decoder Attention)
这一层是
Decoder特有的注意力层,它就是位于图像上、Decoder结构中间的那个注意力机制层。它允许Decoder的每个位置关注Encoder的全部输出。具体来说,这一层的查询(Q)来自前一层Decoder的输出,而键(K)和值(V)则来自Encoder的输出。通过这种方式,Decoder能够利用输入序列中的相关信息来帮助生成正确的输出序列。 -
前馈神经网络网络、层归一化和残差链接
与
Encoder中的前馈网络、层归一化以及残差链接相同,每个Decoder层包含一个前馈网络,该网络对每个位置应用相同的全连接层。这个网络通常包含两个线性变换,并在中间加入了一个激活函数,如 ReLU 或 GELU。
在这些结构当中,我们较为陌生的三个结构是"Teacher Forcing"、"带掩码的自注意力层"以及"编码器-解码器注意力层" ,我们先来了解一下数据滞后操作以及 teacher forcing 制度。
2.1 输入与 teacher forcing
Decoder的输入是滞后1个单位的标签矩阵 (shifted right outputs),我们要将真实标签输入给模型,并且让真实标签指导模型的学习与预测,这种让模型通过正确的标签来学习的流程在Transformer中被称之为是teacher forcing强制教学机制。接下来让我们展开仔细讲讲。
shift right操作
首先,在序列到序列任务中,我们会将标签矩阵进行滞后操作(shift)。
python
import pandas as pd
# 创建DataFrame
df = pd.DataFrame({
"值": [0.1543, 0.2731, 0.3627, 0.4812, 0.5238]
})
print(df)
'''
值
0 0.1543
1 0.2731
2 0.3627
3 0.4812
4 0.5238
'''
# 对序列来说滞后是一种常见的操作👇是指将原有的序列向未来、向正向顺序的方向挪动位置,留出空值的行为:
df.shift(1) #挪动一个位置,被叫做滞后1
# df.shift(2) # 也可以挪动多个位置
'''
值
0 NaN
1 0.1543
2 0.2731
3 0.3627
4 0.4812
'''当表现为编码前的序列时,就是从 [y1, y2, y3, y4] 变成 [NaN, y1, y2, y3, y4],因此这个过程也被叫做"向右滞后"(shift right),其实代表的是在序列的最前方腾挪出位置,将已有的序列向后挤。在Transformer当中,我们一般会为解码器的输入标签添加起始标记"SOS"(start of sequence) ,并将这个起始标记作为标签序列的第一行,最终构成 ["sos", y1, y2, y3, y4] 这样的序列。当进行 embedding 编码后,会呈现为:
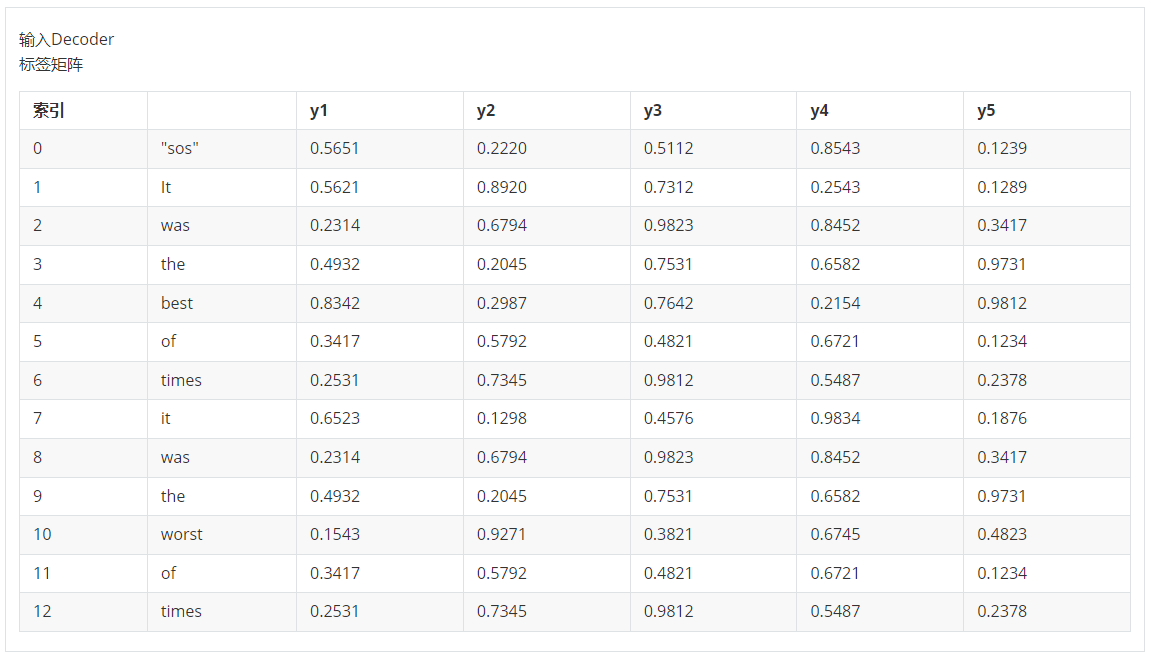
起始标记(Start of Sequence,SOS)和结束标记(End of Sequence,EOS)在序列到序列(Seq2Seq)任务中起着重要的作用,特别是在自然语言处理(NLP)和机器翻译等任务中。
- 起始标记(
SOS)的意义
- 标识序列的开始 :SOS标记用于指示解码器开始生成序列。这在训练和推理过程中都非常重要。
- 初始化解码器 :在解码阶段,解码器需要一个初始输入来开始生成输出序列。SOS标记作为解码器的第一个输入,帮助其启动生成过程。
- 模型一致性:通过在每个输出序列的开头添加SOS标记,模型在训练时可以学到序列生成的起点,从而在推理时保持一致的生成过程。
- 结束标记(
EOS)的意义
- 标识序列的结束 :EOS标记用于指示生成的序列在何处结束。这对于模型在推理阶段停止生成非常重要。
- 控制生成长度 :在没有固定长度的输出序列中,EOS标记告诉模型何时停止生成,而不需要生成固定数量的时间步。这使得模型可以处理变长序列。
- 训练终止条件:在训练过程中,模型学会在适当的时候生成EOS标记,从而正确地结束序列。
假设我们有一个输入序列和一个目标序列:
- 输入序列:
x = ["这", "是", "最", "好", "的", "时", "代"] - 目标序列:
y = ["it", "was", "the", "best", "of", "times"]
在 Seq2Seq 任务的训练过程中,由于Decoder结构会需要输入标签,因此我们必须要准备三种不同的数据,并进行如下的处理:
- 编码器输入 :
x不需要添加起始标记和结束标记。 - 解码器输入的标签:在目标序列前添加起始标记(SOS)。
- 解码器用来计算损失函数的标签:在目标序列末尾添加结束标记(EOS)。
处理后的序列就是:
- 编码器输入 :
["这", "是", "最", "好", "的", "时", "代"] - 解码器输入的标签 :
["SOS", "it", "was", "the", "best", "of", "times"] - 解码器用来计算损失函数的标签 :
["it", "was", "the", "best", "of", "times", "EOS"]
以下是一个简化的示例代码,展示如何使用PyTorch为序列添加起始标记和结束标记,并进行词嵌入:
python
import torch
import torch.nn as nn
# 假设词汇表大小(包括特殊标记如SOS和EOS)
vocab_size = 10
embedding_dim = 4
# 创建嵌入层
embedding_layer = nn.Embedding(vocab_size, embedding_dim)
# 假设索引0是SOS,索引1是EOS
SOS_token = 0
EOS_token = 1
# 目标序列的索引表示
target_sequence = [2, 3, 4, 5, 6] # 假设 "it", "was", "the", "best", "of"
# 添加起始标记和结束标记
Decoder_input = [SOS_token] + target_sequence
Decoder_output = target_sequence + [EOS_token]
# 转换为张量
`Decoder`_input_tensor = torch.tensor(`Decoder`_input)
`Decoder`_output_tensor = torch.tensor(`Decoder`_output)
# 嵌入
embedded_Decoder_input = embedding_layer(`Decoder`_input_tensor)
embedded_Decoder_output = embedding_layer(`Decoder`_output_tensor)
print("Decoder Input (with SOS):", `Decoder`_input_tensor)
print("Decoder Output (with EOS):", `Decoder`_output_tensor)
print("Embedded Decoder Input:", embedded_`Decoder`_input)
print("Embedded Decoder Output:", embedded_`Decoder`_output)
'''
Decoder Input (with SOS): tensor([0, 2, 3, 4, 5, 6])
Decoder Output (with EOS): tensor([2, 3, 4, 5, 6, 1])
Embedded Decoder Input: tensor([[-0.0425, 0.2930, -0.3895, -1.6590],
[-0.9277, -0.1985, 1.6883, 1.5838],
[-0.6614, 1.6603, 0.2338, 0.3172],
[-1.4791, -0.4578, -0.9611, 0.2102],
[ 0.9115, 0.9477, 0.6285, -1.0261],
[ 0.2483, 0.5679, -1.3950, 0.9890]], grad_fn=<EmbeddingBackward0>)
Embedded Decoder Output: tensor([[-0.9277, -0.1985, 1.6883, 1.5838],
[-0.6614, 1.6603, 0.2338, 0.3172],
[-1.4791, -0.4578, -0.9611, 0.2102],
[ 0.9115, 0.9477, 0.6285, -1.0261],
[ 0.2483, 0.5679, -1.3950, 0.9890],
[ 0.1113, -1.1856, 1.8317, -1.3278]], grad_fn=<EmbeddingBackward0>)
'''teacher force
如果你非常熟悉序列模型的预测(比如时间序列的预测),那你应该早就见过很多使用真实标签+特征一起来指导模型学习的操作;例如,时间序列中存在"带标签的滑窗"技术。"带标签的滑窗"是一种特征矩阵构建方法,它会将可以使用的那部分标签作为其中一个特征,和其他特征concat在一起构建特征矩阵。使用带标签的滑窗后,特征信息与标签信息会一起被输入给模型,模型将会结合特征和可使用的标签两部分信息来共同决策。
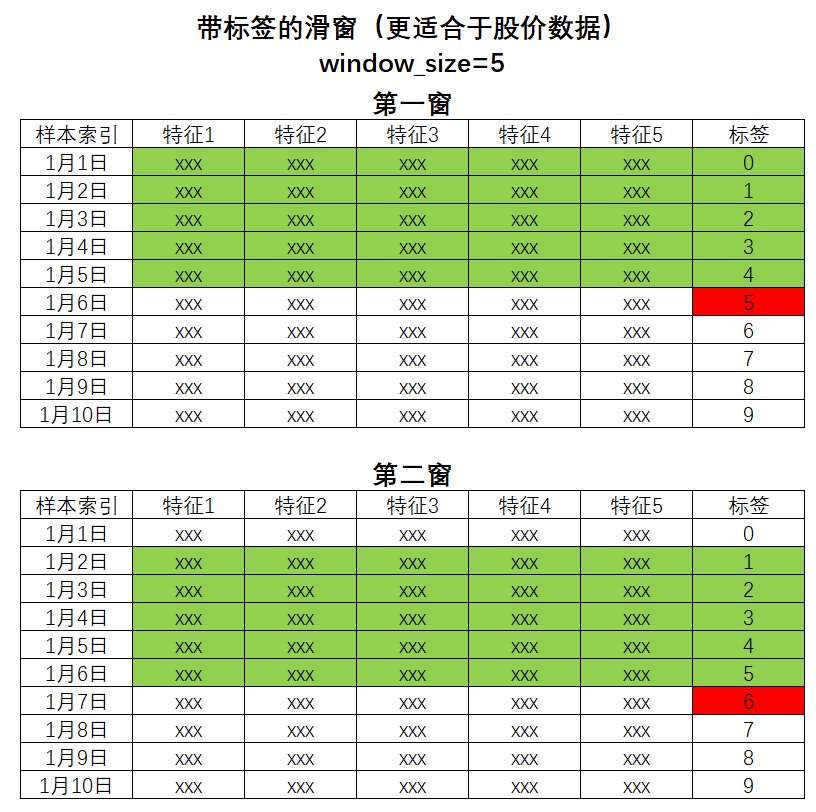
在Transformer中,这种对标签的使用从时间序列数据扩大到了任意序列数据(对时间数据而言,可使用的标签就是当前预测时间点之前所有的时间点,对其他序列数据而言,例如文字数据,可使用的标签就是当前预测的文字位置之前的所有文字),并且将这种技巧从时间序列预测拓展到了序列到序列任务(seq2seq)。
然而需要注意的是,时间序列任务是一种使用过去的信息来预测未来的任务,通常是利用一个序列的前半段数据来预测同一序列的后半段数据。这意味着时间序列预测更多地依赖于生成式模型,旨在根据已有数据生成未来的数据点。而Seq2Seq任务(序列到序列任务)并不总是遵循这种模式。例如,在机器翻译任务中,模型的目标是将一个语言的句子转换成另一种语言的句子,这并不是通过预测同一序列的未来部分来实现的。因此,时间序列预测更接近于生成式任务,而不是典型的序列到序列任务。
- 时间序列任务/生成式任务:同一张表、过去预测未来
| 时间点 | 值 |
|---|---|
| 1 | 0.1543 |
| 2 | 0.2731 |
| 3 | 0.3627 |
| 4 | 0.4812 |
| 5 | 0.5238 |
Encoder-Decoder下的seq2seq任务:两个序列大概率不是一张表,是用一张表去预测另一张表
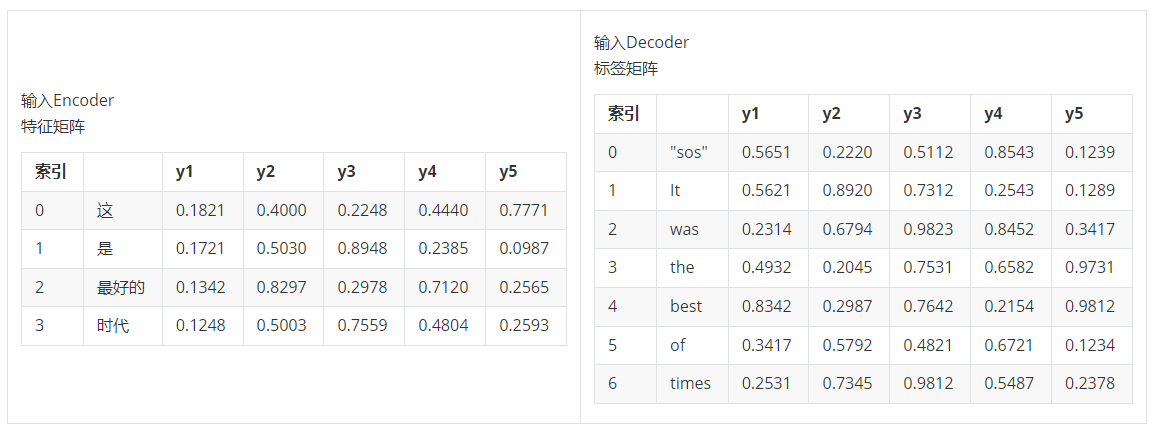
因此在 teacher force 所强调的使用标签是需要将特征矩阵和标签矩阵的信息融合后再进行训练。以上面两张表单为例,设------
原始序列y = "这","是","最","好","的","时","代"
真实标签y = "it", "was", "the", "best", "of", "times"
编码器输出的预测结果为yhat,添加过初始词/结束词、经过
embedding的矩阵为ebd_X和ebd_y
那我们实际走的训练流程是:
- 第一步,输入ebd_X & ebd_y0 >> 输出yhat0,对应真实标签y0
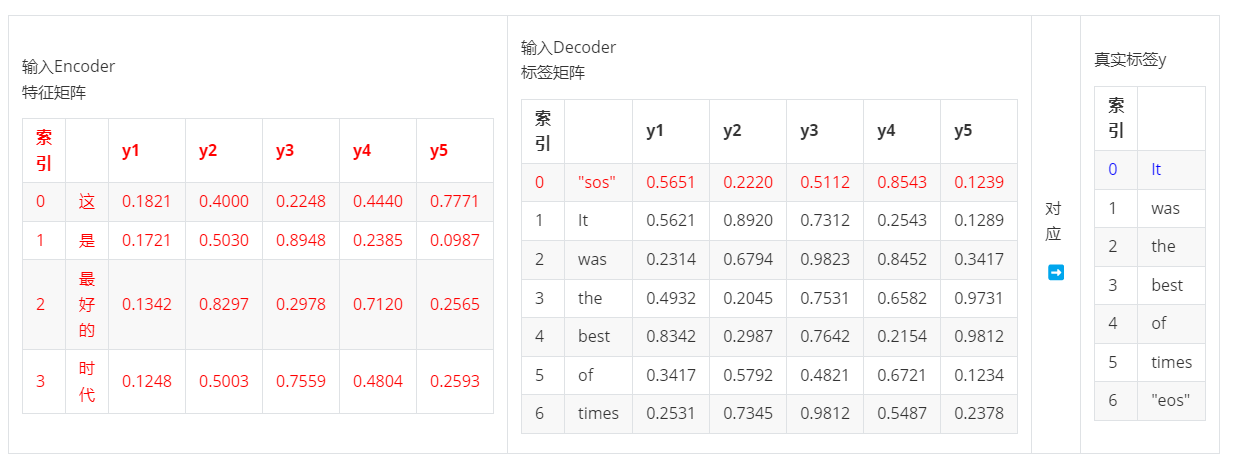
- 第二步,输入ebd_X & ebd_y:1 >> 输出yhat1,对应真实标签y1
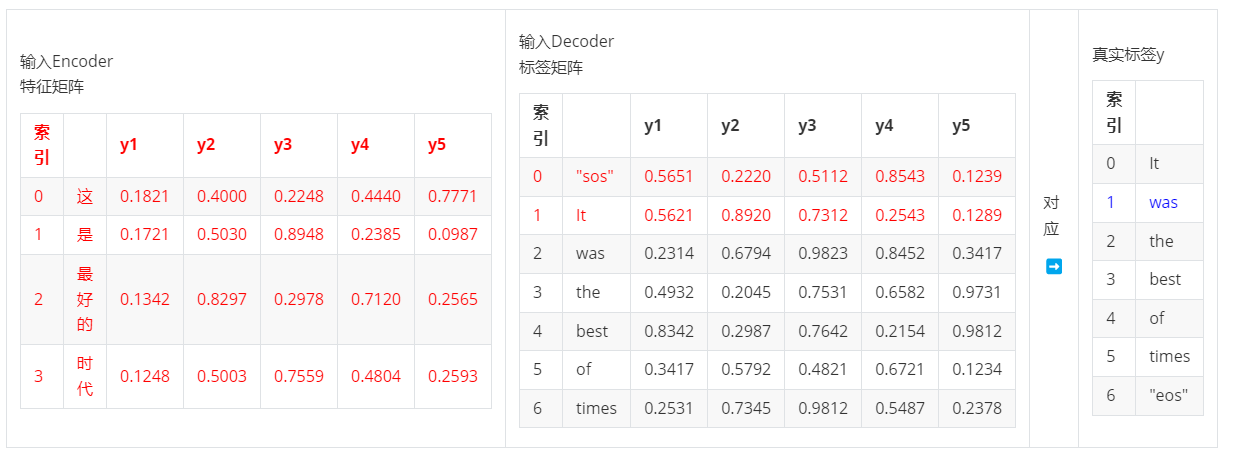
- 第三步,输入ebd_X & ebd_y:2 >> 输出yhat2,对应真实标签y2
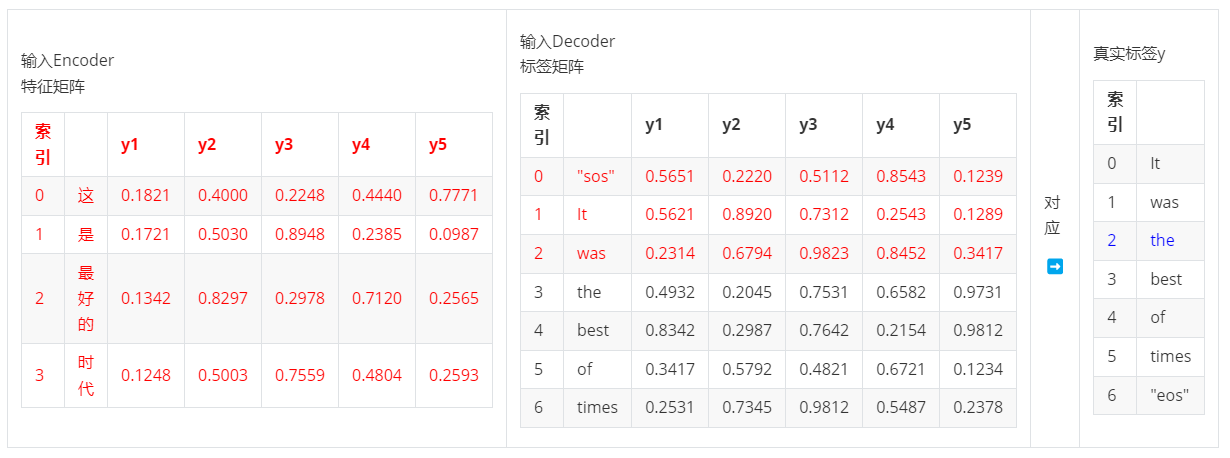
......以此类推下去。不难发现,在这个流程中我们实现了【利用序列A + 序列B的前半段预测序列B的后半段】,这样的方式既没有泄露真实的标签,又能够为预测下一个词提供最大程度的准确的信息,这就是teacher forcing的本质。在训练过程中,这个流程通过掩码自注意力机制+编码器-解码器注意力层合作的方式实现了并行,所以Seq2Seq任务在训练时实际上并不是按照时间步顺序来运行,反而呈现为一次性输入特征矩阵+标签矩阵后,一次性获得整个预测的序列。
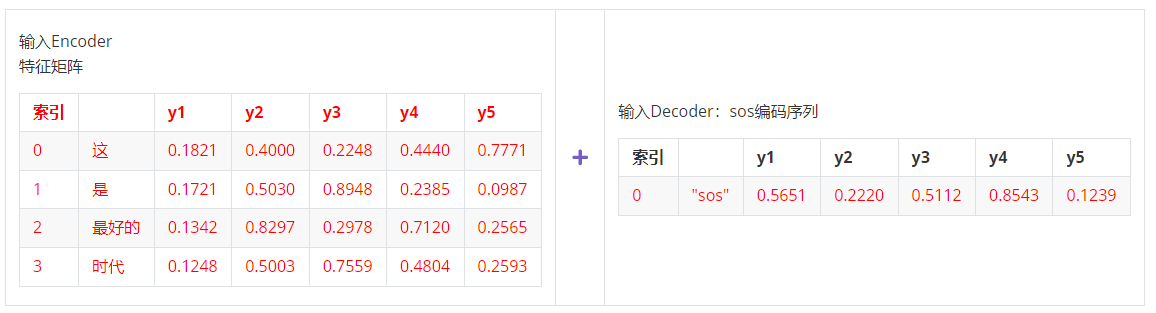
然而在测试和推理过程中可就不一样。在测试和推理的过程中,我们并没有真实的标签矩阵,因此需要将上一个时间步预测的结果作为Decoder需要的输入 。具体来看,在测试流程中:
- 第一步,输入 ebd_X & sos >> 输出时间步1的预测标签,对应真实标签y0
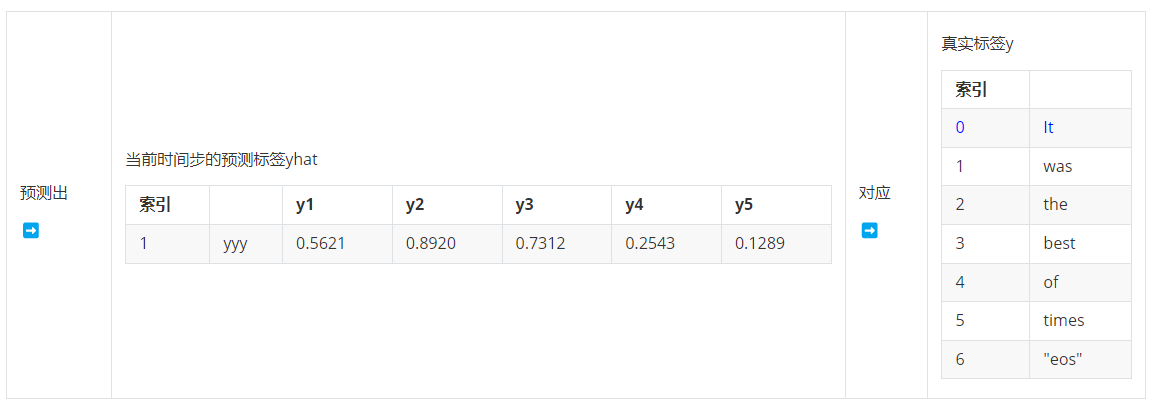
- 第二步,输入ebd_X & yhat:1 >> 输出时间步2的标签,对应真实标签y1
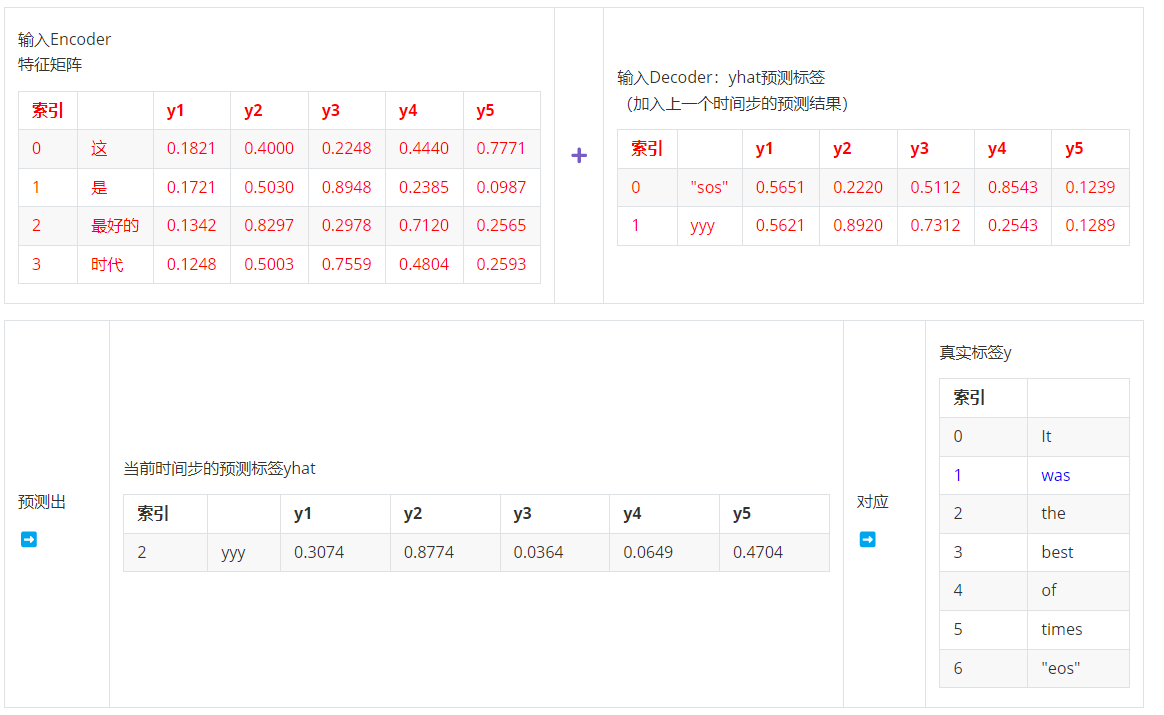
- 第三步,输入ebd_X & yhat:2 >> 输出索引为3的标签,对应真实标签y1
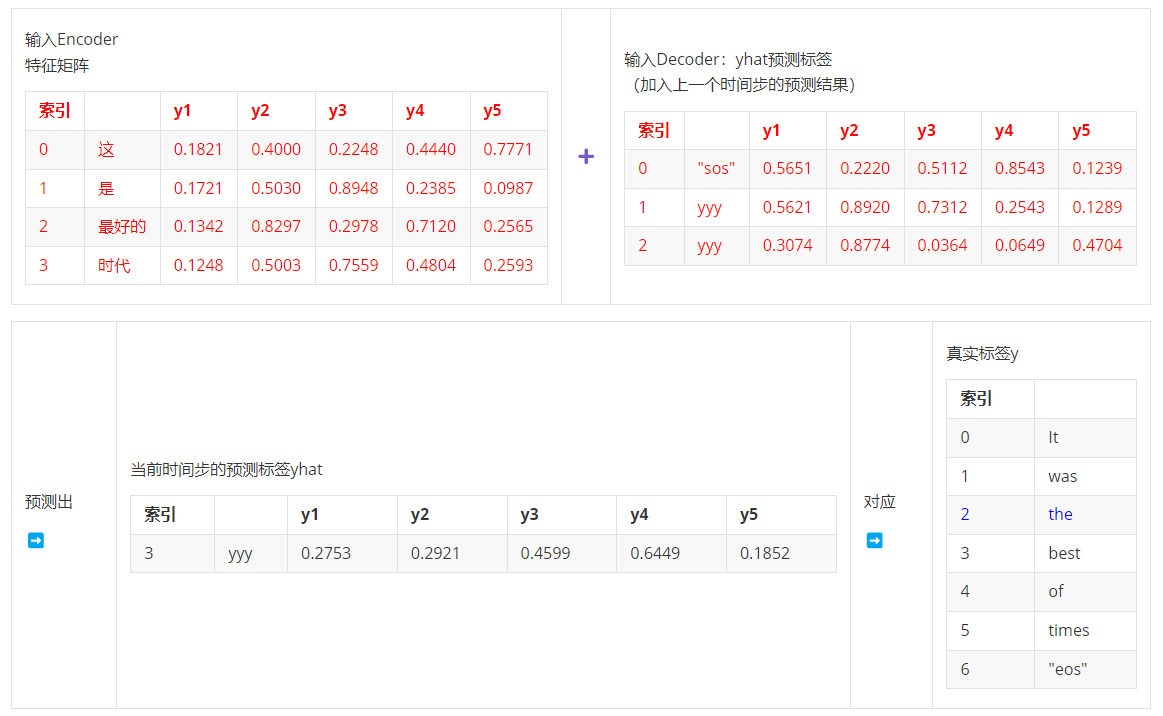
很显然,这是一个自回归的流程。在实际代码实现时,这个过程是线性的、必须按照一个字、一个字的方式来预测,但Transformer本身并不提供像RNN和LSTM那样逐步处理样本的结构,因此推理流程中,我们需要写循环代码来完成推理的过程。每一步生成一个新词,并将其作为输入添加到序列中,直到生成结束标记 "EOS" 或达到最大长度为止。这个流程会极大地限制生成类算法的预测速度,因此现在也有越来越多的技术来帮助我们改进这个环节,但是使用最多的依然是最经典的自回归策略。
现在你已经知道在seq2seq任务中Transformer处理训练数据的流程了------
原始序列y = "这","是","最","好","的","时","代"
真实标签y = "it", "was", "the", "best", "of", "times"
编码器输出的预测结果为yhat,添加过初始词/结束词、经过embedding的矩阵为ebd_y和ebd_y
那我们实际走的训练流程是:
第一步,输入ebd_X & ebd_y0 >> 输出yhat0,对应真实标签y0
第二步,输入ebd_X & ebd_y:1 >> 输出yhat1,对应真实标签y1
第三步,输入ebd_X & ebd_y:2 >> 输出yhat2,对应真实标签y2
以此类推......
在讲解这个过程时我们曾经提到,在训练过程中,这个流程通过掩码自注意力机制+编码器-解码器注意力层合作的方式实现了并行,所以Seq2Seq任务在训练时实际上并不是按照时间步顺序来运行,反而呈现为一次性输入特征矩阵+标签矩阵后,一次性获得整个预测的序列。
实际流程中是并行,就意味着我们需要将完整的yhat输入给Transformer,在这里就会存在两个问题:
- 并行是如何实现的?
- 将完整的yhat输入给
Transformer,是如何避免标签泄漏的?
整个Decoder结构中、掩码注意力机制、编码器解码器注意力层共同解决了这两个问题。接下来让我们一起来看看带掩码的注意力机制。
2.2 掩码注意力机制
在Transformer的Decoder中,掩码自注意力(Masked Self-Attention)确保在生成当前时间步的输出时,模型不能查看未来的输入。这是通过在注意力机制计算过程中应用一个掩码实现的,该掩码有效地将未来位置的注意力得分设置为非常低的值(通常是负无穷),这样模型就无法在预测当前词时利用未来的信息。这种方法确保了生成的输出是自回归的,即每个输出仅依赖于之前的输出,而不是未来的输入。
掩码自注意力机制是通过修改基本的注意力机制公式来实现的,基本的注意力公式如下:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V Attention(Q,K,V) = softmax(\frac{QK^{T}}{\sqrt{d_k}})V Attention(Q,K,V)=softmax(dk QKT)V
在这个公式的基础上引入掩码功能,则涉及到下面三个改变:
-
在计算 Q K T QK^T QKT 的点积后,但在应用
softmax函数之前,掩码自注意力机制通过使用一个掩码矩阵来修改这个点积结果。这个掩码矩阵有特定的结构:对于不应该被当前位置注意的所有位置(即未来的位置),掩码会赋予一个非常大的负值(如负无穷)。 -
应用softmax函数:当
softmax函数应用于经过掩码处理的点积矩阵时,那些被掩码覆盖的位置(即未来的位置)的权重实际上会接近于零。这是因为 e 的非常大的负数次幂几乎为零。 -
结果的动态调整:这样处理后,每个位置的输出在计算时只会考虑到它前面的位置或当前位置的信息,确保了生成的每一步都不会"看到"未来的数据。
我们可以来看具体的矩阵------
- 没有掩码时的 Q K T QK^T QKT点积 (此时的Q、K都是从输出矩阵中生成的)
Q K T = q 1 ⋅ k 1 T q 1 ⋅ k 2 T ⋯ q 1 ⋅ k n T q 2 ⋅ k 1 T q 2 ⋅ k 2 T ⋯ q 2 ⋅ k n T ⋮ ⋮ ⋱ ⋮ q n ⋅ k 1 T q n ⋅ k 2 T ⋯ q n ⋅ k n T QK^T = \begin{bmatrix} q_1 \cdot k_1^T & q_1 \cdot k_2^T & \cdots & q_1 \cdot k_n^T \\ q_2 \cdot k_1^T & q_2 \cdot k_2^T & \cdots & q_2 \cdot k_n^T \\ \vdots & \vdots & \ddots & \vdots \\ q_n \cdot k_1^T & q_n \cdot k_2^T & \cdots & q_n \cdot k_n^T \end{bmatrix} QKT= q1⋅k1Tq2⋅k1T⋮qn⋅k1Tq1⋅k2Tq2⋅k2T⋮qn⋅k2T⋯⋯⋱⋯q1⋅knTq2⋅knT⋮qn⋅knT
- 没有掩码时softmax函数结果
s o f t m a x ( Q K T ) = e q 1 ⋅ k 1 T ∑ j = 1 n e q 1 ⋅ k j T e q 1 ⋅ k 2 T ∑ j = 1 n e q 1 ⋅ k j T ⋯ e q 1 ⋅ k n T ∑ j = 1 n e q 1 ⋅ k j T e q 2 ⋅ k 1 T ∑ j = 1 n e q 2 ⋅ k j T e q 2 ⋅ k 2 T ∑ j = 1 n e q 2 ⋅ k j T ⋯ e q 2 ⋅ k n T ∑ j = 1 n e q 2 ⋅ k j T ⋮ ⋮ ⋱ ⋮ e q n ⋅ k 1 T ∑ j = 1 n e q n ⋅ k j T e q n ⋅ k 2 T ∑ j = 1 n e q n ⋅ k j T ⋯ e q n ⋅ k n T ∑ j = 1 n e q n ⋅ k j T softmax(QK^T) = \begin{bmatrix} \frac{e^{q_1 \cdot k_1^T}}{\sum_{j=1}^n e^{q_1 \cdot k_j^T}} & \frac{e^{q_1 \cdot k_2^T}}{\sum_{j=1}^n e^{q_1 \cdot k_j^T}} & \cdots & \frac{e^{q_1 \cdot k_n^T}}{\sum_{j=1}^n e^{q_1 \cdot k_j^T}} \\ \frac{e^{q_2 \cdot k_1^T}}{\sum_{j=1}^n e^{q_2 \cdot k_j^T}} & \frac{e^{q_2 \cdot k_2^T}}{\sum_{j=1}^n e^{q_2 \cdot k_j^T}} & \cdots & \frac{e^{q_2 \cdot k_n^T}}{\sum_{j=1}^n e^{q_2 \cdot k_j^T}} \\ \vdots & \vdots & \ddots & \vdots \\ \frac{e^{q_n \cdot k_1^T}}{\sum_{j=1}^n e^{q_n \cdot k_j^T}} & \frac{e^{q_n \cdot k_2^T}}{\sum_{j=1}^n e^{q_n \cdot k_j^T}} & \cdots & \frac{e^{q_n \cdot k_n^T}}{\sum_{j=1}^n e^{q_n \cdot k_j^T}} \end{bmatrix} softmax(QKT)= ∑j=1neq1⋅kjTeq1⋅k1T∑j=1neq2⋅kjTeq2⋅k1T⋮∑j=1neqn⋅kjTeqn⋅k1T∑j=1neq1⋅kjTeq1⋅k2T∑j=1neq2⋅kjTeq2⋅k2T⋮∑j=1neqn⋅kjTeqn⋅k2T⋯⋯⋱⋯∑j=1neq1⋅kjTeq1⋅knT∑j=1neq2⋅kjTeq2⋅knT⋮∑j=1neqn⋅kjTeqn⋅knT
- 有掩码时,我们使用的掩码矩阵
M = 0 − ∞ − ∞ ⋯ − ∞ 0 0 − ∞ ⋯ − ∞ 0 0 0 ⋯ − ∞ ⋮ ⋮ ⋮ ⋱ ⋮ 0 0 0 ⋯ 0 M = \begin{bmatrix} 0 & -\infty & -\infty & \cdots & -\infty \\ 0 & 0 & -\infty & \cdots & -\infty \\ 0 & 0 & 0 & \cdots & -\infty \\ \vdots & \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & 0 & \cdots & 0 \end{bmatrix} M= 000⋮0−∞00⋮0−∞−∞0⋮0⋯⋯⋯⋱⋯−∞−∞−∞⋮0
正如你所观察到的,这是一个上半部分全部是无穷大、下半部分全部是0的矩阵。在进行掩码时,我们用掩码矩阵与原始 Q K T QK^T QKT点积进行加和,然后再将加和结果放入softmax函数。
- 有掩码时,掩码矩阵对原始 Q K T QK^T QKT矩阵的影响
Q K T + M = q 1 ⋅ k 1 T + 0 q 1 ⋅ k 2 T − ∞ ⋯ q 1 ⋅ k n T − ∞ q 2 ⋅ k 1 T + 0 q 2 ⋅ k 2 T + 0 ⋯ q 2 ⋅ k n T − ∞ ⋮ ⋮ ⋱ ⋮ q n ⋅ k 1 T + 0 q n ⋅ k 2 T + 0 ⋯ q n ⋅ k n T + 0 QK^T + M = \begin{bmatrix} q_1 \cdot k_1^T + 0 & q_1 \cdot k_2^T - \infty & \cdots & q_1 \cdot k_n^T - \infty \\ q_2 \cdot k_1^T + 0 & q_2 \cdot k_2^T + 0 & \cdots & q_2 \cdot k_n^T - \infty \\ \vdots & \vdots & \ddots & \vdots \\ q_n \cdot k_1^T + 0 & q_n \cdot k_2^T + 0 & \cdots & q_n \cdot k_n^T + 0 \end{bmatrix} QKT+M= q1⋅k1T+0q2⋅k1T+0⋮qn⋅k1T+0q1⋅k2T−∞q2⋅k2T+0⋮qn⋅k2T+0⋯⋯⋱⋯q1⋅knT−∞q2⋅knT−∞⋮qn⋅knT+0
= q 1 ⋅ k 1 T − ∞ − ∞ ⋯ − ∞ q 2 ⋅ k 1 T q 2 ⋅ k 2 T − ∞ ⋯ − ∞ ⋮ ⋮ ⋱ ⋮ − ∞ q n ⋅ k 1 T q n ⋅ k 2 T ⋯ q n ⋅ k n − 1 T q n ⋅ k n T = \begin{bmatrix} q_1 \cdot k_1^T & -\infty & -\infty & \cdots & -\infty \\ q_2 \cdot k_1^T & q_2 \cdot k_2^T & -\infty & \cdots & -\infty \\ \vdots & \vdots & \ddots & \vdots & -\infty \\ q_n \cdot k_1^T & q_n \cdot k_2^T & \cdots & q_n \cdot k_{n-1}^T & q_n \cdot k_n^T \end{bmatrix} = q1⋅k1Tq2⋅k1T⋮qn⋅k1T−∞q2⋅k2T⋮qn⋅k2T−∞−∞⋱⋯⋯⋯⋮qn⋅kn−1T−∞−∞−∞qn⋅knT
经过掩码处理过的 Q K T QK^T QKT 矩阵的右上角全部呈现为负无穷,左下角呈现为具体的值,在这种情况下应用 softmax 函数后,会得到:
- 有掩码时,softmax函数应用后的影响
softmax ( Q K T + M ) = e q 1 ⋅ k 1 T e q 1 ⋅ k 1 T 0 0 0 e q 2 ⋅ k 1 T e q 2 ⋅ k 1 T + e q 2 ⋅ k 2 T e q 2 ⋅ k 2 T e q 2 ⋅ k 1 T + e q 2 ⋅ k 2 T 0 0 e q 3 ⋅ k 1 T e q 3 ⋅ k 1 T + e q 3 ⋅ k 2 T + e q 3 ⋅ k 3 T e q 3 ⋅ k 2 T e q 3 ⋅ k 1 T + e q 3 ⋅ k 2 T + e q 3 ⋅ k 3 T e q 3 ⋅ k 3 T e q 3 ⋅ k 1 T + e q 3 ⋅ k 2 T + e q 3 ⋅ k 3 T 0 e q 4 ⋅ k 1 T ∑ j = 1 4 e q 4 ⋅ k j T e q 4 ⋅ k 2 T ∑ j = 1 4 e q 4 ⋅ k j T e q 4 ⋅ k 3 T ∑ j = 1 4 e q 4 ⋅ k j T e q 4 ⋅ k 4 T ∑ j = 1 4 e q 4 ⋅ k j T \text{softmax}(QK^T + M) = \begin{bmatrix} \frac{e^{q_1 \cdot k_1^T}}{e^{q_1 \cdot k_1^T}} & 0 & 0 & 0 \\ \frac{e^{q_2 \cdot k_1^T}}{e^{q_2 \cdot k_1^T} + e^{q_2 \cdot k_2^T}} & \frac{e^{q_2 \cdot k_2^T}}{e^{q_2 \cdot k_1^T} + e^{q_2 \cdot k_2^T}} & 0 & 0 \\ \frac{e^{q_3 \cdot k_1^T}}{e^{q_3 \cdot k_1^T} + e^{q_3 \cdot k_2^T} + e^{q_3 \cdot k_3^T}} & \frac{e^{q_3 \cdot k_2^T}}{e^{q_3 \cdot k_1^T} + e^{q_3 \cdot k_2^T} + e^{q_3 \cdot k_3^T}} & \frac{e^{q_3 \cdot k_3^T}}{e^{q_3 \cdot k_1^T} + e^{q_3 \cdot k_2^T} + e^{q_3 \cdot k_3^T}} & 0 \\ \frac{e^{q_4 \cdot k_1^T}}{\sum_{j=1}^{4} e^{q_4 \cdot k_j^T}} & \frac{e^{q_4 \cdot k_2^T}}{\sum_{j=1}^{4} e^{q_4 \cdot k_j^T}} & \frac{e^{q_4 \cdot k_3^T}}{\sum_{j=1}^{4} e^{q_4 \cdot k_j^T}} & \frac{e^{q_4 \cdot k_4^T}}{\sum_{j=1}^{4} e^{q_4 \cdot k_j^T}} \end{bmatrix} softmax(QKT+M)= eq1⋅k1Teq1⋅k1Teq2⋅k1T+eq2⋅k2Teq2⋅k1Teq3⋅k1T+eq3⋅k2T+eq3⋅k3Teq3⋅k1T∑j=14eq4⋅kjTeq4⋅k1T0eq2⋅k1T+eq2⋅k2Teq2⋅k2Teq3⋅k1T+eq3⋅k2T+eq3⋅k3Teq3⋅k2T∑j=14eq4⋅kjTeq4⋅k2T00eq3⋅k1T+eq3⋅k2T+eq3⋅k3Teq3⋅k3T∑j=14eq4⋅kjTeq4⋅k3T000∑j=14eq4⋅kjTeq4⋅k4T
从 softmax 函数的具体公式来看,当输入值 z z z高度接近负无穷时,以e为底的对数函数的取值会无穷地趋近于0,因此才会得到一个上半个三角全为0的矩阵。通过这种方式,可以让原始矩阵中的一部分信息被"掩盖"(变为0),这个操作就是掩码的本质。
σ ( z ) i = e z i ∑ j = 1 K e z j \sigma(z)i = \frac{e^{z_i}}{\sum{j=1}^{K} e^{z_j}} σ(z)i=∑j=1Kezjezi
在Transformer模型中,特别是在解码器的掩码自注意力机制中,矩阵 Q K T + M QK^T + M QKT+M是一切的关键。这里,掩码矩阵M的作用是确保在生成序列的每个步骤中,模型只能访问到当前和之前的信息,不能"看到"未来的信息。
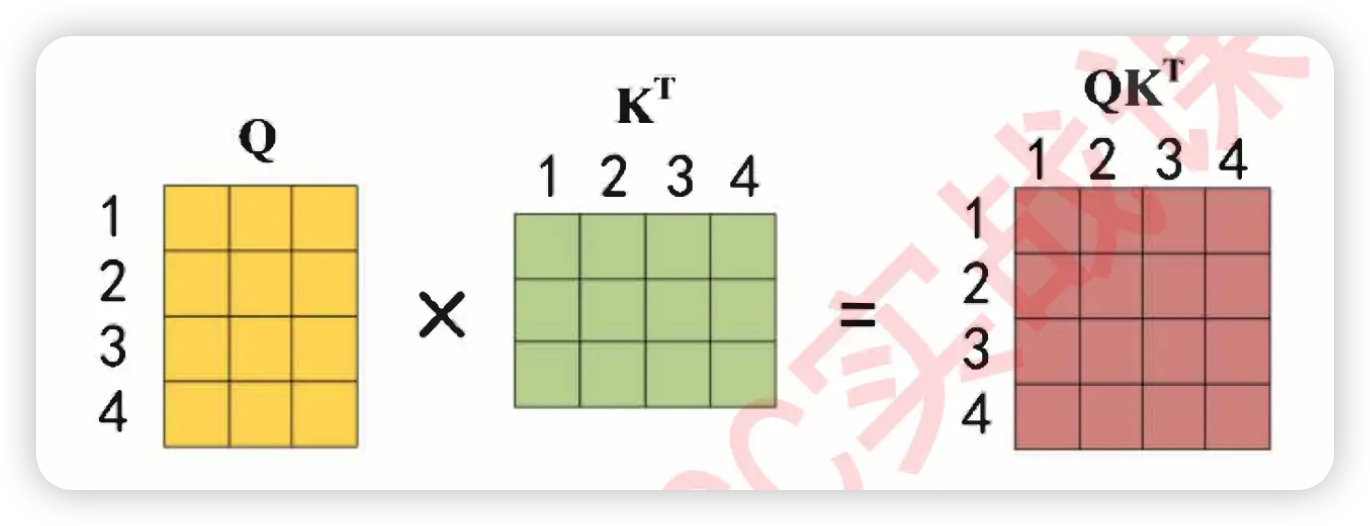
为什么QK.T矩阵的右上角代表模型在观察未来的信息呢?回到最初的QK相乘的图像上,假设现在Q是4行3列、K.T是3行4列,不难发现QK.T矩阵的16个因子分别是这样构成的
KaTeX parse error: Got function '\boldsymbol' with no arguments as subscript at position 34: ...trix} q_\̲b̲o̲l̲d̲s̲y̲m̲b̲o̲l̲{\color{green}{...
使用更简化的写法,你会发现脚标是这样构成的:
Q K T = 1 ⋅ 1 1 ⋅ 2 1 ⋅ 3 1 ⋅ 4 2 ⋅ 1 2 ⋅ 2 2 ⋅ 3 2 ⋅ 4 3 ⋅ 1 3 ⋅ 2 3 ⋅ 3 3 ⋅ 4 4 ⋅ 1 4 ⋅ 2 4 ⋅ 3 4 ⋅ 4 QK^T = \begin{bmatrix} \boldsymbol{\color{green}{1}}\cdot\boldsymbol{\color{green}{1}} & \boldsymbol{\color{green}{1}} \cdot\boldsymbol{\color{red}{2}} & \boldsymbol{\color{green}{1}} \cdot\boldsymbol{\color{red}{3}} & \boldsymbol{\color{green}{1}} \cdot\boldsymbol{\color{red}{4}} \\ \boldsymbol{\color{green}{2}} \cdot \boldsymbol{\color{green}{1}} & \boldsymbol{\color{green}{2}} \cdot \boldsymbol{\color{green}{2}} & \boldsymbol{\color{green}{2}} \cdot \boldsymbol{\color{red}{3}} & \boldsymbol{\color{green}{2}} \cdot \boldsymbol{\color{red}{4}} \\ \boldsymbol{\color{green}{3}} \cdot \boldsymbol{\color{green}{1}} & \boldsymbol{\color{green}{3}} \cdot \boldsymbol{\color{green}{2}} & \boldsymbol{\color{green}{3}} \cdot \boldsymbol{\color{green}{3}} & \boldsymbol{\color{green}{3}} \cdot \boldsymbol{\color{red}{4}} \\ \boldsymbol{\color{green}{4}} \cdot \boldsymbol{\color{green}{1}} & \boldsymbol{\color{green}{4}} \cdot \boldsymbol{\color{green}{2}} & \boldsymbol{\color{green}{4}} \cdot \boldsymbol{\color{green}{3}} & \boldsymbol{\color{green}{4}} \cdot \boldsymbol{\color{green}{4}} \end{bmatrix} QKT= 1⋅12⋅13⋅14⋅11⋅22⋅23⋅24⋅21⋅32⋅33⋅34⋅31⋅42⋅43⋅44⋅4
你发现什么了?QK都是由单词经过embedding后编码的矩阵,因此Q从上至下的顺序就是"从过去到未来、按句子阅读顺序"排列的顺序,而K作为转置矩阵,K从左到右的顺序就是"从过去到未来、按句子阅读顺序"排列的顺序。当我们使用信息Q去询问信息K时,就有------
- Q的脚标 = K的脚标,则Q在询问和自己在同一位置/同一时间点的信息
- Q的脚标 > K的脚标,则Q在询问在句子前方的/过去的时间点的信息
- Q的脚标 < K的脚标,则Q在询问在句子后方的/未来时间点的信息
很显然,Q的脚标 < K的脚标的情况都集中在 Q K T QK^T QKT矩阵的右上角。因此,我们为右上角加上负无穷,并在softmax函数后将该部分信息化为0,就可以避免"未来的信息"泄漏给Transformer算法。
到这里,你就明白−∞的引入、掩码矩阵的引入所具有的意义了:
- 阻止信息泄露 :在解码过程中,为了保持输出的自回归性质(即每个输出仅依赖于先前的输出),模型不能提前访问未来位置的信息。在 Q K T QK^T QKT矩阵中添加负无穷正是为了这一点,将负无穷加到某些位置上,是为了在计算注意力权重时,这些位置的影响被完全忽略。
- 影响softmax函数 :在自注意力机制中,注意力权重是通过对 Q K T QK^T QKT应用softmax函数计算得出的。当softmax函数作用于包含负无穷的值时,这些位置的指数值会趋于零,导致它们在计算最终的注意力权重时的贡献也趋于零。因此,这些未来的位置不会对当前或之前的输出产生影响。
- 保持生成顺序性 :通过这种方式,
Transformer能够按顺序逐个生成输出序列中的元素,每个元素的生成只依赖于之前的元素,从而有效地模拟序列生成任务中的时间顺序性和因果关系。
简而言之,将矩阵 Q K T + M QK^T + M QKT+M中的上半部分变成负无穷实际上是一种控制措施,用于保证解码器在处理如机器翻译或文本生成等任务时,不会由于未来信息的干扰而产生错误或不自然的输出。这是确保模型生成行为的正确性和效率的关键技术手段。
掩码后的注意力机制的输出结果
Decoder中,多头注意力机制输出的softmax结果(这部分信息来自于真实标签y)
softmax ( Q K T + M ) = e q 1 ⋅ k 1 T e q 1 ⋅ k 1 T 0 0 0 e q 2 ⋅ k 1 T e q 2 ⋅ k 1 T + e q 2 ⋅ k 2 T e q 2 ⋅ k 2 T e q 2 ⋅ k 1 T + e q 2 ⋅ k 2 T 0 0 e q 3 ⋅ k 1 T e q 3 ⋅ k 1 T + e q 3 ⋅ k 2 T + e q 3 ⋅ k 3 T e q 3 ⋅ k 2 T e q 3 ⋅ k 1 T + e q 3 ⋅ k 2 T + e q 3 ⋅ k 3 T e q 3 ⋅ k 3 T e q 3 ⋅ k 1 T + e q 3 ⋅ k 2 T + e q 3 ⋅ k 3 T 0 e q 4 ⋅ k 1 T ∑ j = 1 4 e q 4 ⋅ k j T e q 4 ⋅ k 2 T ∑ j = 1 4 e q 4 ⋅ k j T e q 4 ⋅ k 3 T ∑ j = 1 4 e q 4 ⋅ k j T e q 4 ⋅ k 4 T ∑ j = 1 4 e q 4 ⋅ k j T \text{softmax}(QK^T + M) = \begin{bmatrix} \frac{e^{q_1 \cdot k_1^T}}{e^{q_1 \cdot k_1^T}} & 0 & 0 & 0 \\ \frac{e^{q_2 \cdot k_1^T}}{e^{q_2 \cdot k_1^T} + e^{q_2 \cdot k_2^T}} & \frac{e^{q_2 \cdot k_2^T}}{e^{q_2 \cdot k_1^T} + e^{q_2 \cdot k_2^T}} & 0 & 0 \\ \frac{e^{q_3 \cdot k_1^T}}{e^{q_3 \cdot k_1^T} + e^{q_3 \cdot k_2^T} + e^{q_3 \cdot k_3^T}} & \frac{e^{q_3 \cdot k_2^T}}{e^{q_3 \cdot k_1^T} + e^{q_3 \cdot k_2^T} + e^{q_3 \cdot k_3^T}} & \frac{e^{q_3 \cdot k_3^T}}{e^{q_3 \cdot k_1^T} + e^{q_3 \cdot k_2^T} + e^{q_3 \cdot k_3^T}} & 0 \\ \frac{e^{q_4 \cdot k_1^T}}{\sum_{j=1}^{4} e^{q_4 \cdot k_j^T}} & \frac{e^{q_4 \cdot k_2^T}}{\sum_{j=1}^{4} e^{q_4 \cdot k_j^T}} & \frac{e^{q_4 \cdot k_3^T}}{\sum_{j=1}^{4} e^{q_4 \cdot k_j^T}} & \frac{e^{q_4 \cdot k_4^T}}{\sum_{j=1}^{4} e^{q_4 \cdot k_j^T}} \end{bmatrix} softmax(QKT+M)= eq1⋅k1Teq1⋅k1Teq2⋅k1T+eq2⋅k2Teq2⋅k1Teq3⋅k1T+eq3⋅k2T+eq3⋅k3Teq3⋅k1T∑j=14eq4⋅kjTeq4⋅k1T0eq2⋅k1T+eq2⋅k2Teq2⋅k2Teq3⋅k1T+eq3⋅k2T+eq3⋅k3Teq3⋅k2T∑j=14eq4⋅kjTeq4⋅k2T00eq3⋅k1T+eq3⋅k2T+eq3⋅k3Teq3⋅k3T∑j=14eq4⋅kjTeq4⋅k3T000∑j=14eq4⋅kjTeq4⋅k4T
当这个矩阵乘以v后,依然不会改变携带的信息,因此我们可以使用这个脚标来标注整个多头注意力机制输出的结果,使用数字简化则有------
'Decoder' softmax = 1 ⋅ 1 1 ⋅ 2 1 ⋅ 3 1 ⋅ 4 2 ⋅ 1 2 ⋅ 2 2 ⋅ 3 2 ⋅ 4 3 ⋅ 1 3 ⋅ 2 3 ⋅ 3 3 ⋅ 4 4 ⋅ 1 4 ⋅ 2 4 ⋅ 3 4 ⋅ 4 \text{`Decoder` softmax} = \begin{bmatrix} \boldsymbol{\color{green}{1}}\cdot\boldsymbol{\color{green}{1}} & \boldsymbol{\color{green}{1}} \cdot\boldsymbol{\color{red}{2}} & \boldsymbol{\color{green}{1}} \cdot\boldsymbol{\color{red}{3}} & \boldsymbol{\color{green}{1}} \cdot\boldsymbol{\color{red}{4}} \\ \boldsymbol{\color{green}{2}} \cdot \boldsymbol{\color{green}{1}} & \boldsymbol{\color{green}{2}} \cdot \boldsymbol{\color{green}{2}} & \boldsymbol{\color{green}{2}} \cdot \boldsymbol{\color{red}{3}} & \boldsymbol{\color{green}{2}} \cdot \boldsymbol{\color{red}{4}} \\ \boldsymbol{\color{green}{3}} \cdot \boldsymbol{\color{green}{1}} & \boldsymbol{\color{green}{3}} \cdot \boldsymbol{\color{green}{2}} & \boldsymbol{\color{green}{3}} \cdot \boldsymbol{\color{green}{3}} & \boldsymbol{\color{green}{3}} \cdot \boldsymbol{\color{red}{4}} \\ \boldsymbol{\color{green}{4}} \cdot \boldsymbol{\color{green}{1}} & \boldsymbol{\color{green}{4}} \cdot \boldsymbol{\color{green}{2}} & \boldsymbol{\color{green}{4}} \cdot \boldsymbol{\color{green}{3}} & \boldsymbol{\color{green}{4}} \cdot \boldsymbol{\color{green}{4}} \end{bmatrix} 'Decoder' softmax= 1⋅12⋅13⋅14⋅11⋅22⋅23⋅24⋅21⋅32⋅33⋅34⋅31⋅42⋅43⋅44⋅4
经过掩码之后,实际上是------
'Decoder' masked softmax = 1 ⋅ 1 0 0 0 2 ⋅ 1 2 ⋅ 2 0 0 3 ⋅ 1 3 ⋅ 2 3 ⋅ 3 0 4 ⋅ 1 4 ⋅ 2 4 ⋅ 3 4 ⋅ 4 \text{`Decoder` masked softmax} = \begin{bmatrix} \boldsymbol{\color{green}{1}}\cdot\boldsymbol{\color{green}{1}} & 0 & 0 & 0\\ \boldsymbol{\color{green}{2}} \cdot \boldsymbol{\color{green}{1}} & \boldsymbol{\color{green}{2}} \cdot \boldsymbol{\color{green}{2}} & 0 & 0\\ \boldsymbol{\color{green}{3}} \cdot \boldsymbol{\color{green}{1}} & \boldsymbol{\color{green}{3}} \cdot \boldsymbol{\color{green}{2}} & \boldsymbol{\color{green}{3}} \cdot \boldsymbol{\color{green}{3}} & 0\\ \boldsymbol{\color{green}{4}} \cdot \boldsymbol{\color{green}{1}} & \boldsymbol{\color{green}{4}} \cdot \boldsymbol{\color{green}{2}} & \boldsymbol{\color{green}{4}} \cdot \boldsymbol{\color{green}{3}} & \boldsymbol{\color{green}{4}} \cdot \boldsymbol{\color{green}{4}} \end{bmatrix} 'Decoder' masked softmax= 1⋅12⋅13⋅14⋅102⋅23⋅24⋅2003⋅34⋅30004⋅4
转换成注意力得分,则有------
'Decoder'-Masked-Attention = a 11 0 0 0 a 21 a 22 0 0 a 31 a 32 a 33 0 a 41 a 42 a 43 a 44 \text{`Decoder`-Masked-Attention} = \begin{bmatrix} a_{11} & 0 & 0 & 0 \\ a_{21} & a_{22} & 0 & 0 \\ a_{31} & a_{32} & a_{33} & 0 \\ a_{41} & a_{42} & a_{43} & a_{44} \end{bmatrix} 'Decoder'-Masked-Attention= a11a21a31a410a22a32a4200a33a43000a44
假设 V V V 矩阵如下,由于矩阵V是从原始标签y生成的embedding矩阵,因此矩阵V的序列方向是从上到下。
V = v 1 v 1 ... v 1 v 2 v 2 ... v 2 v 3 v 3 ... v 3 v 4 v 4 ... v 4 V = \begin{bmatrix} v_{1} & v_{1} & \ldots & v_{1} \\ v_{2} & v_{2} & \ldots & v_{2} \\ v_{3} & v_{3} & \ldots & v_{3} \\ v_{4} & v_{4} & \ldots & v_{4} \end{bmatrix} V= v1v2v3v4v1v2v3v4............v1v2v3v4
特别注意!在这里为了避免脚标产生混淆,没有写特征维度脚标。此时我们所有的脚标都只代表了时间点,特征维度脚标被省略了!事实上真正的V矩阵应该是------
V = v 1 1 v 1 2 ... v 1 d v 2 1 v 2 2 ... v 2 d v 3 1 v 3 2 ... v 3 d v 4 1 v 4 2 ... v 4 d V = \begin{bmatrix} v_{1}^1 & v_{1}^2 & \ldots & v_{1}^d \\ v_{2}^1 & v_{2}^2 & \ldots & v_{2}^d \\ v_{3}^1 & v_{3}^2 & \ldots & v_{3}^d \\ v_{4}^1 & v_{4}^2 & \ldots & v_{4}^d \end{bmatrix} V= v11v21v31v41v12v22v32v42............v1dv2dv3dv4d
在我们此时的讨论流程中,特征维度脚标只有标识作用,与整体过程理解无关,因此在这里出于教学目的将其省略。但事实上它应该是存在的。
将 'Decoder'-Masked-Attention \text{`Decoder`-Masked-Attention} 'Decoder'-Masked-Attention 矩阵与 V V V 矩阵相乘,得到结果矩阵 C C C,就是带掩码的多头注意力机制的结果------
C = 'Decoder'-Masked-Attention × V C = \text{`Decoder`-Masked-Attention} \times V C='Decoder'-Masked-Attention×V
C = a 11 0 0 0 a 21 a 22 0 0 a 31 a 32 a 33 0 a 41 a 42 a 43 a 44 v 1 v 1 ... v 1 v 2 v 2 ... v 2 v 3 v 3 ... v 3 v 4 v 4 ... v 4 C = \begin{bmatrix} a_{11} & 0 & 0 & 0 \\ a_{21} & a_{22} & 0 & 0 \\ a_{31} & a_{32} & a_{33} & 0 \\ a_{41} & a_{42} & a_{43} & a_{44} \end{bmatrix} \begin{bmatrix} v_{1} & v_{1} & \ldots & v_{1} \\ v_{2} & v_{2} & \ldots & v_{2} \\ v_{3} & v_{3} & \ldots & v_{3} \\ v_{4} & v_{4} & \ldots & v_{4} \end{bmatrix} C= a11a21a31a410a22a32a4200a33a43000a44 v1v2v3v4v1v2v3v4............v1v2v3v4
结果矩阵 C C C 的元素 c i j c_{ij} cij 的计算如下:
c i = ∑ k a i k ⋅ v k c_{i} = \sum_{k} a_{ik} \cdot v_{k} ci=k∑aik⋅vk
具体计算为:
C = a 11 v 1 a 11 v 1 ... a 11 v 1 a 21 v 1 + a 22 v 2 a 21 v 1 + a 22 v 2 ... a 21 v 1 + a 22 v 2 a 31 v 1 + a 32 v 2 + a 33 v 3 a 31 v 1 + a 32 v 2 + a 33 v 3 ... a 31 v 1 + a 32 v 2 + a 33 v 3 a 41 v 1 + a 42 v 2 + a 43 v 3 + a 44 v 4 a 41 v 1 + a 42 v 2 + a 43 v 3 + a 44 v 4 ... a 41 v 1 + a 42 v 2 + a 43 v 2 + a 44 v 4 C = \begin{bmatrix} a_{11}v_{1} & a_{11}v_{1} & \ldots & a_{11}v_{1} \\ a_{21}v_{1} + a_{22}v_{2} & a_{21}v_{1} + a_{22}v_{2} & \ldots & a_{21}v_{1} + a_{22}v_{2} \\ a_{31}v_{1} + a_{32}v_{2} + a_{33}v_{3} & a_{31}v_{1} + a_{32}v_{2} + a_{33}v_{3} & \ldots & a_{31}v_{1} + a_{32}v_{2} + a_{33}v_{3} \\ a_{41}v_{1} + a_{42}v_{2} + a_{43}v_{3} + a_{44}v_{4} & a_{41}v_{1} + a_{42}v_{2} + a_{43}v_{3} + a_{44}v_{4} & \ldots & a_{41}v_{1} + a_{42}v_{2} + a_{43}v_{2} + a_{44}v_{4} \end{bmatrix} C= a11v1a21v1+a22v2a31v1+a32v2+a33v3a41v1+a42v2+a43v3+a44v4a11v1a21v1+a22v2a31v1+a32v2+a33v3a41v1+a42v2+a43v3+a44v4............a11v1a21v1+a22v2a31v1+a32v2+a33v3a41v1+a42v2+a43v2+a44v4
观察这个矩阵,你发现了什么?在这个矩阵中,v上携带的信息的时间点不会超出分数a中携带的信息的时间点,权重和句子信息在交互时都只能与"过去"的信息交互,而不能与"未来"的信息交互。通过这种方式,你可以看到最终带掩码的注意力机制是如何实现未来信息的不泄露的。
2.3 普通掩码 vs 前瞻掩码
在NLP的世界中,掩码最被人熟知的作用就是掩盖未来的信息、避免序列中未来的信息被泄露到算法中,然而掩码(Masking)是一种多功能的机制,其本质是为了"掩盖信息",但并不局限于掩盖未来的信息。在注意力机制中、掩盖未来信息、不允许Q向未来的K发问的掩码被叫做"前瞻掩码"(look-ahead Masking),这里的"前瞻"正是代表了"未来"(对时间序列来说是未来的时间点、对文字序列来说是右侧的信息)。然而,掩码在Transformer中还有另一个巨大的作用,就是掩盖噪音信息,避免噪音影响注意力机制的计算。掩盖噪音的掩码是最普通的掩码之一,在NLP中它主要负责掩盖填充句子时产生的padding。
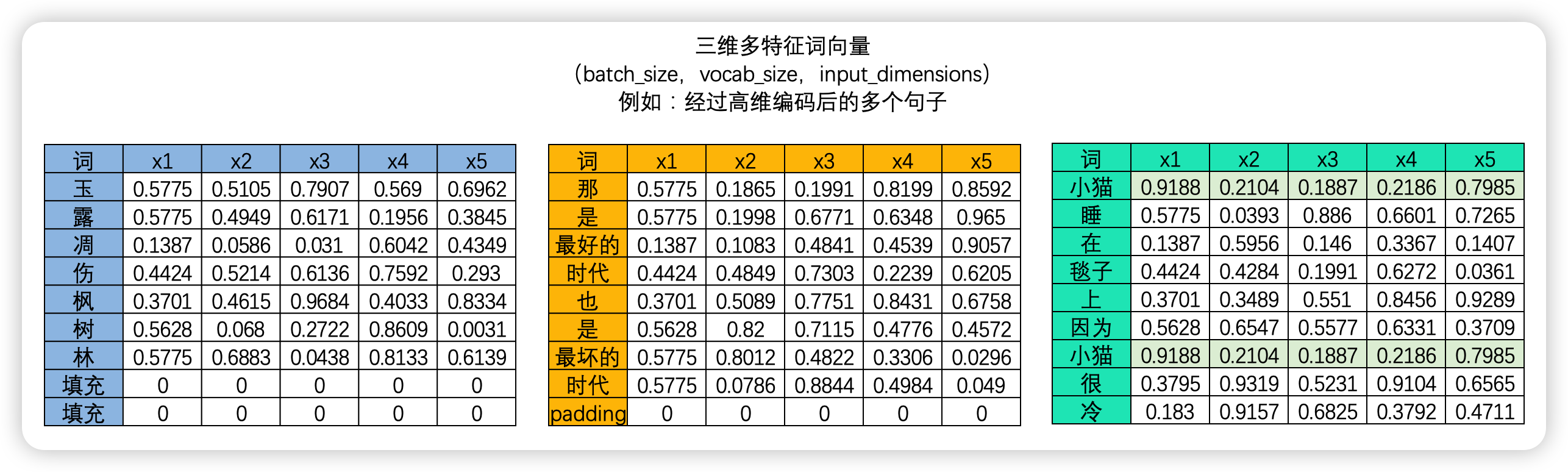
Transformer的输入数据结构为(batch_size, seq_len, input_dimensions),不同句子的seq_len必须保持一致,然而在现实中我们不太可能让每个句子的长度都一致,因此句子过长的部分我们就会截断句子、句子太短的部分我们就会使用填充。这些填充大部分都是0填充,这些0填充与其他token正常编码的结果计算之后,就会在注意力分数中留下许多的噪音值,因此在将这些信息输出之前,我们就会需要在QK.T矩阵上进行"填充掩码",来帮助注意力机制减少噪音带来的影响。
很显然,前瞻掩码通常只是解码器专属的,但是填充掩码是解码器和编码器都可以使用的。在编码器的多头注意力机制中,那个"可选的掩码"就是填充掩码机制。
pytorch 允许我们自创掩码矩阵M,输入到pytorch的各个层里进行掩码(QK.T + M)
- 填充掩码的实现函数
python
import torch
# 创造一个示例数据
batch_size = 4
seq_len = 10
embedding_dim = 8
seq = torch.randint(0, 5, (batch_size, seq_len, embedding_dim)) # 随机生成一些数据
#填充部分
pad_token = 0
seq[0, 7:, :] = pad_token # 设置填充值
seq[1, 9:, :] = pad_token # 设置填充值
seq[3, 5:, :] = pad_token # 设置填充值
#(4,10,8)
print(seq[0])
'''
tensor([[1, 3, 0, 0, 0, 1, 1, 4],
[0, 3, 2, 2, 1, 2, 3, 2],
[2, 3, 3, 0, 3, 2, 0, 3],
[2, 1, 3, 1, 0, 1, 3, 2],
[3, 4, 2, 3, 2, 3, 0, 4],
[0, 1, 1, 1, 3, 3, 3, 0],
[1, 3, 3, 3, 4, 3, 0, 4],
[0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0]])
'''
- reshape与expand的区别
python
s = torch.tensor([[0,1,2,3,4,5]])
s.reshape(-1,3) #将原始的序列拆成2行3列,重组
'''
tensor([[0, 1, 2],
[3, 4, 5]])
'''
#升维之后,在升起的维度上将原始序列复制三遍,构成更高维的结果
s.unsqueeze(1).expand(-1, 3, -1)
'''
tensor([[[0, 1, 2, 3, 4, 5],
[0, 1, 2, 3, 4, 5],
[0, 1, 2, 3, 4, 5]]])
'''但注意!我们并不是随时随地都需要这个升维的过程。具体需要呈现怎样的掩码矩阵,需要根据掩码矩阵使用的时机、以及配合的库来考虑。如果是配合PyTorch中已经设置好的Transformer类来使用,则二维的掩码矩阵就足够了,Transformer类会自动执行将掩码矩阵升维的过程;如果是利用更底层的机制创建的Transformer,则会需要我们手动执行上述流程来匹配掩码的结构。在实际使用时,大家要根据实际情况选择是否主动对掩码矩阵进行升维。
2.4 编码器-解码器注意力层
在Transformer模型的解码器部分,编码器-解码器注意力层(通常称为"交叉注意力"层)起着至关重要的作用。这一层允许解码器的每个位置访问整个编码器的输出,这对于将输入序列的上下文信息整合到输出序列的生成中是必需的。这个层的设计是为了确保解码器能够基于完整的输入序列信息来生成每个输出元素。
首先,编码器-解码器注意力层的输入是来自多头注意力机制的输出结果 。从Decoder的掩码注意力层中输出的是经过掩码后、每一行只携带特定时间段信息的结果 C ' D e c o d e r ' C_{`Decoder`} C'Decoder':
C ' D e c o d e r ' = a 11 v 1 a 11 v 1 ... a 11 v 1 a 21 v 1 + a 22 v 2 a 21 v 1 + a 22 v 2 ... a 21 v 1 + a 22 v 2 a 31 v 1 + a 32 v 2 + a 33 v 3 a 31 v 1 + a 32 v 2 + a 33 v 3 ... a 31 v 1 + a 32 v 2 + a 33 v 3 a 41 v 1 + a 42 v 2 + a 43 v 3 + a 44 v 4 a 41 v 1 + a 42 v 2 + a 43 v 3 + a 44 v 4 ... a 41 v 1 + a 42 v 2 + a 43 v 2 + a 44 v 4 C_{`Decoder`} = \begin{bmatrix} a_{11}v_{1} & a_{11}v_{1} & \ldots & a_{11}v_{1} \\ a_{21}v_{1} + a_{22}v_{2} & a_{21}v_{1} + a_{22}v_{2} & \ldots & a_{21}v_{1} + a_{22}v_{2} \\ a_{31}v_{1} + a_{32}v_{2} + a_{33}v_{3} & a_{31}v_{1} + a_{32}v_{2} + a_{33}v_{3} & \ldots & a_{31}v_{1} + a_{32}v_{2} + a_{33}v_{3} \\ a_{41}v_{1} + a_{42}v_{2} + a_{43}v_{3} + a_{44}v_{4} & a_{41}v_{1} + a_{42}v_{2} + a_{43}v_{3} + a_{44}v_{4} & \ldots & a_{41}v_{1} + a_{42}v_{2} + a_{43}v_{2} + a_{44}v_{4} \end{bmatrix} C'Decoder'= a11v1a21v1+a22v2a31v1+a32v2+a33v3a41v1+a42v2+a43v3+a44v4a11v1a21v1+a22v2a31v1+a32v2+a33v3a41v1+a42v2+a43v3+a44v4............a11v1a21v1+a22v2a31v1+a32v2+a33v3a41v1+a42v2+a43v2+a44v4
当我们使用覆盖的时间点来作为脚标,则有:
C ' D e c o d e r ' = c 1 c 1 ... c 1 c 1 → 2 c 1 → 2 ... c 1 → 2 c 1 → 3 c 1 → 3 ... c 1 → 3 c 1 → 4 c 1 → 4 ... c 1 → 4 C_{`Decoder`} = \begin{bmatrix} c_{1} & c_{1} & \ldots & c_{1} \\ c_{1 \to 2} & c_{1 \to 2} & \ldots & c_{1 \to 2} \\ c_{1 \to 3} & c_{1 \to 3} & \ldots & c_{1 \to 3} \\ c_{1 \to 4} & c_{1 \to 4} & \ldots & c_{1 \to 4} \end{bmatrix} C'Decoder'= c1c1→2c1→3c1→4c1c1→2c1→3c1→4............c1c1→2c1→3c1→4
同样的,这里出于教学目的,省略了特征维度上的脚标。现在你所看到的脚标只代表时间维度/序列长度的维度。
从Encoder中输出的是没有掩码的注意力机制结果 C ' E n c o d e r ' C_{`Encoder`} C'Encoder',由于没有掩码,所以Encoder中的注意力分数为------
A = a 11 a 12 a 13 a 14 a 21 a 22 a 23 a 24 a 31 a 32 a 33 a 34 a 41 a 42 a 43 a 44 \text{A} = \begin{bmatrix} a_{11} & a_{12} & a_{13} & a_{14} \\ a_{21} & a_{22} & a_{23} & a_{24} \\ a_{31} & a_{32} & a_{33} & a_{34} \\ a_{41} & a_{42} & a_{43} & a_{44} \end{bmatrix} A= a11a21a31a41a12a22a32a42a13a23a33a43a14a24a34a44
同时,V矩阵为(省略了特征维度,脚标代表的是时间点、seq_len的信息)------
V = v 1 v 1 ... v 1 v 2 v 2 ... v 2 v 3 v 3 ... v 3 v 4 v 4 ... v 4 V = \begin{bmatrix} v_{1} & v_{1} & \ldots & v_{1} \\ v_{2} & v_{2} & \ldots & v_{2} \\ v_{3} & v_{3} & \ldots & v_{3} \\ v_{4} & v_{4} & \ldots & v_{4} \end{bmatrix} V= v1v2v3v4v1v2v3v4............v1v2v3v4
由于 C 'Encoder' = A × V \text{C}{\text{`Encoder`}} = \text{A} \times V C'Encoder'=A×V,因此最终的结果矩阵 C 'Encoder' \text{C}{\text{`Encoder`}} C'Encoder' 是:
C 'Encoder' = a 11 ⋅ v 1 + a 12 ⋅ v 2 + a 13 ⋅ v 3 + a 14 ⋅ v 4 a 11 ⋅ v 1 + a 12 ⋅ v 2 + a 13 ⋅ v 3 + a 14 ⋅ v 4 ... a 11 ⋅ v 1 + a 12 ⋅ v 2 + a 13 ⋅ v 3 + a 14 ⋅ v 4 a 21 ⋅ v 1 + a 22 ⋅ v 2 + a 23 ⋅ v 3 + a 24 ⋅ v 4 a 21 ⋅ v 1 + a 22 ⋅ v 2 + a 23 ⋅ v 3 + a 24 ⋅ v 4 ... a 21 ⋅ v 1 + a 22 ⋅ v 2 + a 23 ⋅ v 3 + a 24 ⋅ v 4 a 31 ⋅ v 1 + a 32 ⋅ v 2 + a 33 ⋅ v 3 + a 34 ⋅ v 4 a 31 ⋅ v 1 + a 32 ⋅ v 2 + a 33 ⋅ v 3 + a 34 ⋅ v 4 ... a 31 ⋅ v 1 + a 32 ⋅ v 2 + a 33 ⋅ v 3 + a 34 ⋅ v 4 a 41 ⋅ v 1 + a 42 ⋅ v 2 + a 43 ⋅ v 3 + a 44 ⋅ v 4 a 41 ⋅ v 1 + a 42 ⋅ v 2 + a 43 ⋅ v 3 + a 44 ⋅ v 4 ... a 41 ⋅ v 1 + a 42 ⋅ v 2 + a 43 ⋅ v 3 + a 44 ⋅ v 4 \text{C}{\text{`Encoder`}} = \begin{bmatrix} a{11} \cdot v_1 + a_{12} \cdot v_2 + a_{13} \cdot v_3 + a_{14} \cdot v_4 & a_{11} \cdot v_1 + a_{12} \cdot v_2 + a_{13} \cdot v_3 + a_{14} \cdot v_4 & \ldots & a_{11} \cdot v_1 + a_{12} \cdot v_2 + a_{13} \cdot v_3 + a_{14} \cdot v_4 \\ a_{21} \cdot v_1 + a_{22} \cdot v_2 + a_{23} \cdot v_3 + a_{24} \cdot v_4 & a_{21} \cdot v_1 + a_{22} \cdot v_2 + a_{23} \cdot v_3 + a_{24} \cdot v_4 & \ldots & a_{21} \cdot v_1 + a_{22} \cdot v_2 + a_{23} \cdot v_3 + a_{24} \cdot v_4 \\ a_{31} \cdot v_1 + a_{32} \cdot v_2 + a_{33} \cdot v_3 + a_{34} \cdot v_4 & a_{31} \cdot v_1 + a_{32} \cdot v_2 + a_{33} \cdot v_3 + a_{34} \cdot v_4 & \ldots & a_{31} \cdot v_1 + a_{32} \cdot v_2 + a_{33} \cdot v_3 + a_{34} \cdot v_4 \\ a_{41} \cdot v_1 + a_{42} \cdot v_2 + a_{43} \cdot v_3 + a_{44} \cdot v_4 & a_{41} \cdot v_1 + a_{42} \cdot v_2 + a_{43} \cdot v_3 + a_{44} \cdot v_4 & \ldots & a_{41} \cdot v_1 + a_{42} \cdot v_2 + a_{43} \cdot v_3 + a_{44} \cdot v_4 \end{bmatrix} C'Encoder'= a11⋅v1+a12⋅v2+a13⋅v3+a14⋅v4a21⋅v1+a22⋅v2+a23⋅v3+a24⋅v4a31⋅v1+a32⋅v2+a33⋅v3+a34⋅v4a41⋅v1+a42⋅v2+a43⋅v3+a44⋅v4a11⋅v1+a12⋅v2+a13⋅v3+a14⋅v4a21⋅v1+a22⋅v2+a23⋅v3+a24⋅v4a31⋅v1+a32⋅v2+a33⋅v3+a34⋅v4a41⋅v1+a42⋅v2+a43⋅v3+a44⋅v4............a11⋅v1+a12⋅v2+a13⋅v3+a14⋅v4a21⋅v1+a22⋅v2+a23⋅v3+a24⋅v4a31⋅v1+a32⋅v2+a33⋅v3+a34⋅v4a41⋅v1+a42⋅v2+a43⋅v3+a44⋅v4
同样的,当我们使用覆盖的时间点来作为脚标,则有:
C ' E n c o d e r ' = c 1 → 4 c 1 → 4 ... c 1 → 4 c 1 → 4 c 1 → 4 ... c 1 → 4 c 1 → 4 c 1 → 4 ... c 1 → 4 c 1 → 4 c 1 → 4 ... c 1 → 4 C_{`Encoder`} = \begin{bmatrix} c_{1 \to 4} & c_{1 \to 4} & \ldots & c_{1 \to 4} \\ c_{1 \to 4} & c_{1 \to 4} & \ldots & c_{1 \to 4} \\ c_{1 \to 4} & c_{1 \to 4} & \ldots & c_{1 \to 4} \\ c_{1 \to 4} & c_{1 \to 4} & \ldots & c_{1 \to 4} \end{bmatrix} C'Encoder'= c1→4c1→4c1→4c1→4c1→4c1→4c1→4c1→4............c1→4c1→4c1→4c1→4
同样的,这里出于教学目的,省略了特征维度上的脚标。现在你所看到的脚标只代表时间维度/序列长度的维度。事实上4列C虽然覆盖的时间维度一致,但却归属于不同的特征维度。
此时, C ' E n c o d e r ' C_{`Encoder`} C'Encoder'携带的是特征矩阵X的信息, C ' E n c o d e r ' C_{`Encoder`} C'Encoder'中的每个元素都携带了全部时间步上的信息, C ' D e c o d e r ' C_{`Decoder`} C'Decoder'携带的是真实标签的信息, C ' D e c o d e r ' C_{`Decoder`} C'Decoder'中的元素则是每一行代表了一段时间的信息,随着行数的增加这段时间窗口越来越长。编码器-解码器注意力层负责整合这两部分信息。具体来说,编码器解码器输出的结果结合的方式是------将解码器中的标签信息 C ' D e c o d e r ' C_{`Decoder`} C'Decoder'作为Q矩阵,将编码器中输出的特征信息 C ' E n c o d e r ' C_{`Encoder`} C'Encoder'作为K和V矩阵,使用每行Q与全部的K、V相乘,来执行一种特殊的注意力机制。
这种特殊注意力机制的公式如下------
Context 1 = ∑ i Attention ( Q 1 , K i ) × V i \text{Context}1 = \sum{i} \text{Attention}(Q_1, K_i) \times V_i Context1=i∑Attention(Q1,Ki)×Vi
Context 2 = ∑ i Attention ( Q 2 , K i ) × V i \text{Context}2 = \sum{i} \text{Attention}(Q_2, K_i) \times V_i Context2=i∑Attention(Q2,Ki)×Vi
Context 3 = ∑ i Attention ( Q 3 , K i ) × V i \text{Context}3 = \sum{i} \text{Attention}(Q_3, K_i) \times V_i Context3=i∑Attention(Q3,Ki)×Vi
... ... ...... ......
在这个公式中,Q与K转置相乘的地方不再是点积、而是按全新的加和规则相乘相加------转换成矩阵则有, C ' D e c o d e r ' ( Q ) C_{`Decoder`}(Q) C'Decoder'(Q)的第一行乘以 C ' E n c o d e r ' ( K . T ) C_{`Encoder`}(K.T) C'Encoder'(K.T)的第一列,加上 C ' D e c o d e r ' ( Q ) C_{`Decoder`}(Q) C'Decoder'(Q)的第一行乘以 C ' E n c o d e r ' ( K . T ) C_{`Encoder`}(K.T) C'Encoder'(K.T)的第二列,加上 C ' D e c o d e r ' ( Q ) C_{`Decoder`}(Q) C'Decoder'(Q)的第一行乘以 C ' E n c o d e r ' ( K . T ) C_{`Encoder`}(K.T) C'Encoder'(K.T)的第三列......直到所有的列都被乘完为止。
C o n t e x t 1 = c 1 c 1 ... c 1 c 1 → 2 c 1 → 2 ... c 1 → 2 c 1 → 3 c 1 → 3 ... c 1 → 3 c 1 → 4 c 1 → 4 ... c 1 → 4 ⋅ c 1 → 4 c 1 → 4 ... c 1 → 4 c 1 → 4 c 1 → 4 ... c 1 → 4 c 1 → 4 c 1 → 4 ... c 1 → 4 c 1 → 4 c 1 → 4 ... c 1 → 4 Context_1 = \begin{bmatrix} \color{red}{c_{1}} & \color{red}{c_{1}} & \ldots & \color{red}{c_{1}} \\ c_{1 \to 2} & c_{1 \to 2} & \ldots & c_{1 \to 2} \\ c_{1 \to 3} & c_{1 \to 3} & \ldots & c_{1 \to 3} \\ c_{1 \to 4} & c_{1 \to 4} & \ldots & c_{1 \to 4} \end{bmatrix} \cdot \begin{bmatrix} \color{red}{c_{1 \to 4}} & c_{1 \to 4} & \ldots & c_{1 \to 4} \\ \color{red}{c_{1 \to 4}} & c_{1 \to 4} & \ldots & c_{1 \to 4} \\ \color{red}{c_{1 \to 4}} & c_{1 \to 4} & \ldots & c_{1 \to 4} \\ \color{red}{c_{1 \to 4}} & c_{1 \to 4} & \ldots & c_{1 \to 4} \end{bmatrix} Context1= c1c1→2c1→3c1→4c1c1→2c1→3c1→4............c1c1→2c1→3c1→4 ⋅ c1→4c1→4c1→4c1→4c1→4c1→4c1→4c1→4............c1→4c1→4c1→4c1→4
c 1 c 1 ... c 1 c 1 → 2 c 1 → 2 ... c 1 → 2 c 1 → 3 c 1 → 3 ... c 1 → 3 c 1 → 4 c 1 → 4 ... c 1 → 4 ⋅ c 1 → 4 c 1 → 4 ... c 1 → 4 c 1 → 4 c 1 → 4 ... c 1 → 4 c 1 → 4 c 1 → 4 ... c 1 → 4 c 1 → 4 c 1 → 4 ... c 1 → 4 \begin{bmatrix} \color{red}{c_{1}} & \color{red}{c_{1}} & \ldots & \color{red}{c_{1}} \\ c_{1 \to 2} & c_{1 \to 2} & \ldots & c_{1 \to 2} \\ c_{1 \to 3} & c_{1 \to 3} & \ldots & c_{1 \to 3} \\ c_{1 \to 4} & c_{1 \to 4} & \ldots & c_{1 \to 4} \end{bmatrix} \cdot \begin{bmatrix} c_{1 \to 4} & \color{red}{c_{1 \to 4}} & \ldots & c_{1 \to 4} \\ c_{1 \to 4} & \color{red}{c_{1 \to 4}} & \ldots & c_{1 \to 4} \\ c_{1 \to 4} & \color{red}{c_{1 \to 4}} & \ldots & c_{1 \to 4} \\ c_{1 \to 4} & \color{red}{c_{1 \to 4}} & \ldots & c_{1 \to 4} \end{bmatrix} c1c1→2c1→3c1→4c1c1→2c1→3c1→4............c1c1→2c1→3c1→4 ⋅ c1→4c1→4c1→4c1→4c1→4c1→4c1→4c1→4............c1→4c1→4c1→4c1→4
... ... ...... ......
c 1 c 1 ... c 1 c 1 → 2 c 1 → 2 ... c 1 → 2 c 1 → 3 c 1 → 3 ... c 1 → 3 c 1 → 4 c 1 → 4 ... c 1 → 4 ⋅ c 1 → 4 c 1 → 4 ... c 1 → 4 c 1 → 4 c 1 → 4 ... c 1 → 4 c 1 → 4 c 1 → 4 ... c 1 → 4 c 1 → 4 c 1 → 4 ... c 1 → 4 \begin{bmatrix} \color{red}{c_{1}} & \color{red}{c_{1}} & \ldots & \color{red}{c_{1}} \\ c_{1 \to 2} & c_{1 \to 2} & \ldots & c_{1 \to 2} \\ c_{1 \to 3} & c_{1 \to 3} & \ldots & c_{1 \to 3} \\ c_{1 \to 4} & c_{1 \to 4} & \ldots & c_{1 \to 4} \end{bmatrix} \cdot \begin{bmatrix} c_{1 \to 4} & c_{1 \to 4} & \ldots & \color{red}{c_{1 \to 4}} \\ c_{1 \to 4} & c_{1 \to 4} & \ldots & \color{red}{c_{1 \to 4}} \\ c_{1 \to 4} & c_{1 \to 4} & \ldots & \color{red}{c_{1 \to 4}} \\ c_{1 \to 4} & c_{1 \to 4} & \ldots & \color{red}{c_{1 \to 4}} \end{bmatrix} c1c1→2c1→3c1→4c1c1→2c1→3c1→4............c1c1→2c1→3c1→4 ⋅ c1→4c1→4c1→4c1→4c1→4c1→4c1→4c1→4............c1→4c1→4c1→4c1→4
这是标签中的第一个时间步与特征中的所有时间步产生关联。
同样的我们有------
C o n t e x t 2 = c 1 c 1 ... c 1 c 1 → 2 c 1 → 2 ... c 1 → 2 c 1 → 3 c 1 → 3 ... c 1 → 3 c 1 → 4 c 1 → 4 ... c 1 → 4 ⋅ c 1 → 4 c 1 → 4 ... c 1 → 4 c 1 → 4 c 1 → 4 ... c 1 → 4 c 1 → 4 c 1 → 4 ... c 1 → 4 c 1 → 4 c 1 → 4 ... c 1 → 4 Context_2 = \begin{bmatrix} c_{1} & c_{1} & \ldots & c_{1} \\ \color{red}{c_{1 \to 2}} & \color{red}{c_{1 \to 2}} & \ldots & \color{red}{c_{1 \to 2}} \\ c_{1 \to 3} & c_{1 \to 3} & \ldots & c_{1 \to 3} \\ c_{1 \to 4} & c_{1 \to 4} & \ldots & c_{1 \to 4} \end{bmatrix} \cdot \begin{bmatrix} \color{red}{c_{1 \to 4}} & c_{1 \to 4} & \ldots & c_{1 \to 4} \\ \color{red}{c_{1 \to 4}} & c_{1 \to 4} & \ldots & c_{1 \to 4} \\ \color{red}{c_{1 \to 4}} & c_{1 \to 4} & \ldots & c_{1 \to 4} \\ \color{red}{c_{1 \to 4}} & c_{1 \to 4} & \ldots & c_{1 \to 4} \end{bmatrix} Context2= c1c1→2c1→3c1→4c1c1→2c1→3c1→4............c1c1→2c1→3c1→4 ⋅ c1→4c1→4c1→4c1→4c1→4c1→4c1→4c1→4............c1→4c1→4c1→4c1→4
c 1 c 1 ... c 1 c 1 → 2 c 1 → 2 ... c 1 → 2 c 1 → 3 c 1 → 3 ... c 1 → 3 c 1 → 4 c 1 → 4 ... c 1 → 4 ⋅ c 1 → 4 c 1 → 4 ... c 1 → 4 c 1 → 4 c 1 → 4 ... c 1 → 4 c 1 → 4 c 1 → 4 ... c 1 → 4 c 1 → 4 c 1 → 4 ... c 1 → 4 \begin{bmatrix} c_{1} & c_{1} & \ldots & c_{1} \\ \color{red}{c_{1 \to 2}} & \color{red}{c_{1 \to 2}} & \ldots & \color{red}{c_{1 \to 2}} \\ c_{1 \to 3} & c_{1 \to 3} & \ldots & c_{1 \to 3} \\ c_{1 \to 4} & c_{1 \to 4} & \ldots & c_{1 \to 4} \end{bmatrix} \cdot \begin{bmatrix} c_{1 \to 4} & \color{red}{c_{1 \to 4}} & \ldots & c_{1 \to 4} \\ c_{1 \to 4} & \color{red}{c_{1 \to 4}} & \ldots & c_{1 \to 4} \\ c_{1 \to 4} & \color{red}{c_{1 \to 4}} & \ldots & c_{1 \to 4} \\ c_{1 \to 4} & \color{red}{c_{1 \to 4}} & \ldots & c_{1 \to 4} \end{bmatrix} c1c1→2c1→3c1→4c1c1→2c1→3c1→4............c1c1→2c1→3c1→4 ⋅ c1→4c1→4c1→4c1→4c1→4c1→4c1→4c1→4............c1→4c1→4c1→4c1→4
... ... ...... ......
c 1 c 1 ... c 1 c 1 → 2 c 1 → 2 ... c 1 → 2 c 1 → 3 c 1 → 3 ... c 1 → 3 c 1 → 4 c 1 → 4 ... c 1 → 4 ⋅ c 1 → 4 c 1 → 4 ... c 1 → 4 c 1 → 4 c 1 → 4 ... c 1 → 4 c 1 → 4 c 1 → 4 ... c 1 → 4 c 1 → 4 c 1 → 4 ... c 1 → 4 \begin{bmatrix} c_{1} & c_{1} & \ldots & c_{1} \\ \color{red}{c_{1 \to 2}} & \color{red}{c_{1 \to 2}} & \ldots & \color{red}{c_{1 \to 2}} \\ c_{1 \to 3} & c_{1 \to 3} & \ldots & c_{1 \to 3} \\ c_{1 \to 4} & c_{1 \to 4} & \ldots & c_{1 \to 4} \end{bmatrix} \cdot \begin{bmatrix} c_{1 \to 4} & c_{1 \to 4} & \ldots & \color{red}{c_{1 \to 4}} \\ c_{1 \to 4} & c_{1 \to 4} & \ldots & \color{red}{c_{1 \to 4}} \\ c_{1 \to 4} & c_{1 \to 4} & \ldots & \color{red}{c_{1 \to 4}} \\ c_{1 \to 4} & c_{1 \to 4} & \ldots & \color{red}{c_{1 \to 4}} \end{bmatrix} c1c1→2c1→3c1→4c1c1→2c1→3c1→4............c1c1→2c1→3c1→4 ⋅ c1→4c1→4c1→4c1→4c1→4c1→4c1→4c1→4............c1→4c1→4c1→4c1→4
这是标签中的第一个和第二个时间步与特征中的所有时间步产生关联。
以此类推下去,直到形成新的注意力机制矩阵,后续进入softmax、并与V相乘的流程也类似。你是否注意到,这个注意力机制事实上代表了什么 ?还记得我们最初说Decoder结构的输入与输出吗?
在Decoder中我们实际走的训练流程是:
- 第一步,输入ebd_X & ebd_y0 >> 输出yhat0,对应真实标签y0
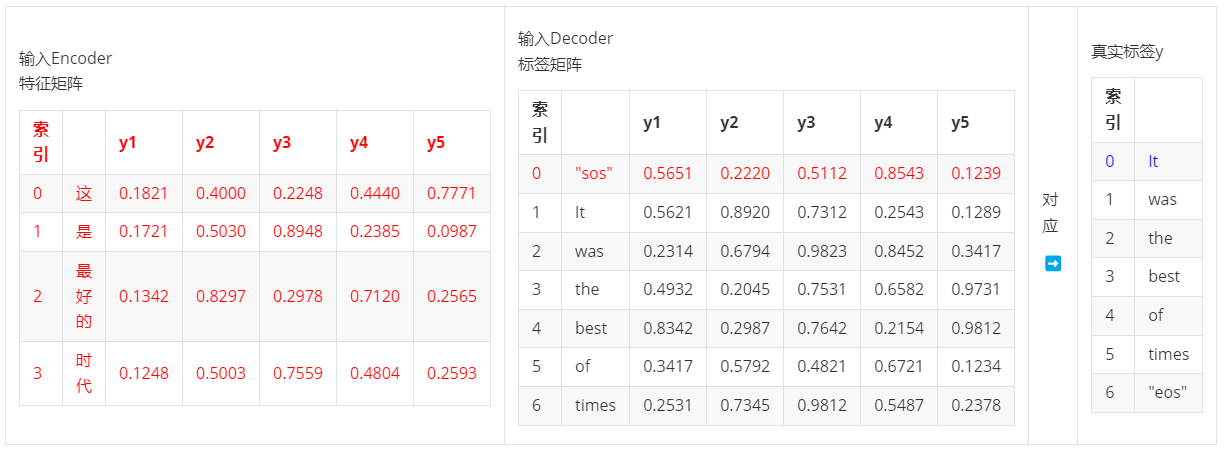
- 第二步,输入ebd_X & ebd_y:1 >> 输出yhat1,对应真实标签y1
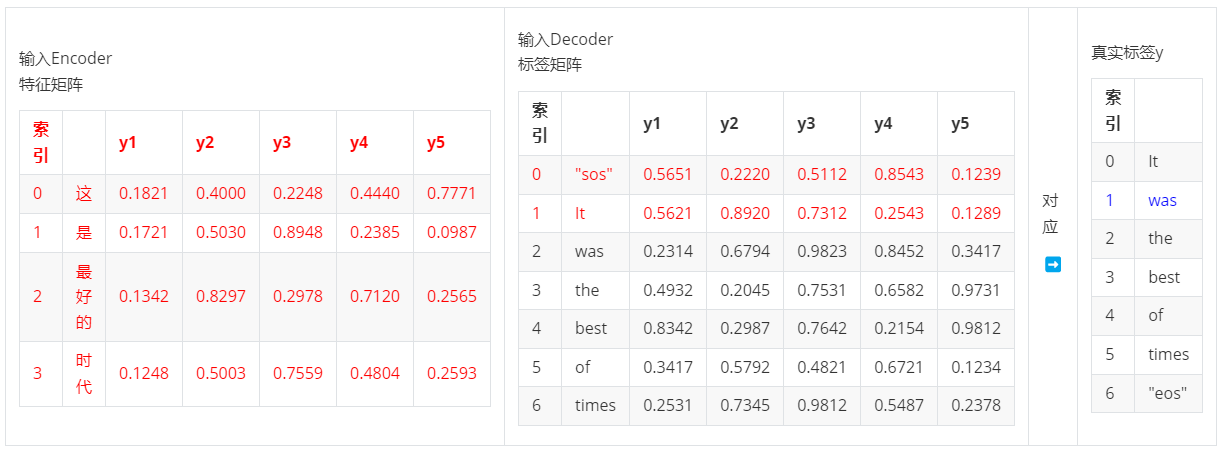
- 第三步,输入ebd_X & ebd_y:2 >> 输出yhat2,对应真实标签y2
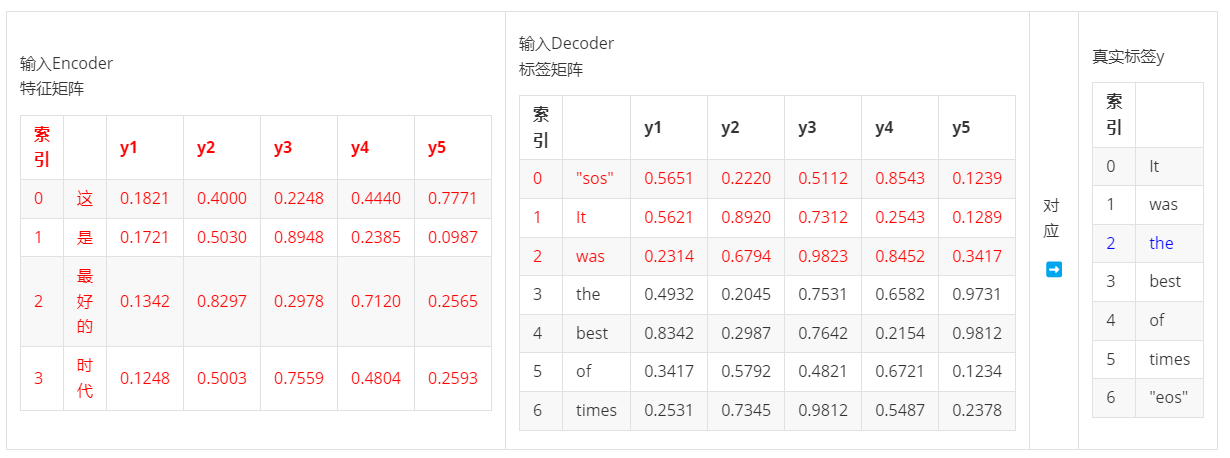
......以此类推下去。很显然,编码器-解码器注意力机制中的数学流程,正是【利用序列X + 序列y的前半段预测序列y的后半段】的计算方式!在这里每一步都是单独的方程,涉及到矩阵中不同的行,因此这里的所有时间步可以并行!本质上实现的是编码器-解码器注意力机制中、下列方程的并行 ↓
Context 1 = ∑ i Attention ( Q 1 , K i ) × V i \text{Context}1 = \sum{i} \text{Attention}(Q_1, K_i) \times V_i Context1=i∑Attention(Q1,Ki)×Vi
Context 2 = ∑ i Attention ( Q 2 , K i ) × V i \text{Context}2 = \sum{i} \text{Attention}(Q_2, K_i) \times V_i Context2=i∑Attention(Q2,Ki)×Vi
Context 3 = ∑ i Attention ( Q 3 , K i ) × V i \text{Context}3 = \sum{i} \text{Attention}(Q_3, K_i) \times V_i Context3=i∑Attention(Q3,Ki)×Vi
所以现在你知道编码器解码器层是如何实现信息整合的了。学到这里,我们来总结一下编码器-解码器注意力层的核心作用------
- 关联输入和输出:在许多任务中,输出序列的生成需要依赖于输入序列的特定部分。这层允许模型学习在生成每个输出元素时应关注输入序列的哪些部分。
- 灵活的上下文捕捉:与自注意力层只能处理解码器自身的先前输出不同,编码器-解码器注意力层可以访问整个输入序列的上下文,这对于任务如机器翻译至关重要。
- 增强解码器能力:通过整合来自编码器的信息,这一设计显著增强了解码器处理复杂输入序列并准确生成输出的能力。
总之,编码器-解码器注意力层是Transformer解码器的核心部分,使解码器能够利用编码器处理的完整输入信息,从而生成语义上连贯且上下文相关的输出。