兄弟们,心态崩了。
昨晚本来想趁着字节 Seedance 2.0 刚出,赶紧接个 API 跑个 Demo 看看效果。官方文档写得倒是挺"简洁",就给了个 curl 示例。我寻思这还不简单?直接用 requests 库一把梭。
结果,代码跑起来,这报错直接给我整不会了: json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0)
排查了两个小时,才发现这 API 的流式响应(SSE)简直是灾难。

- 踩坑现场
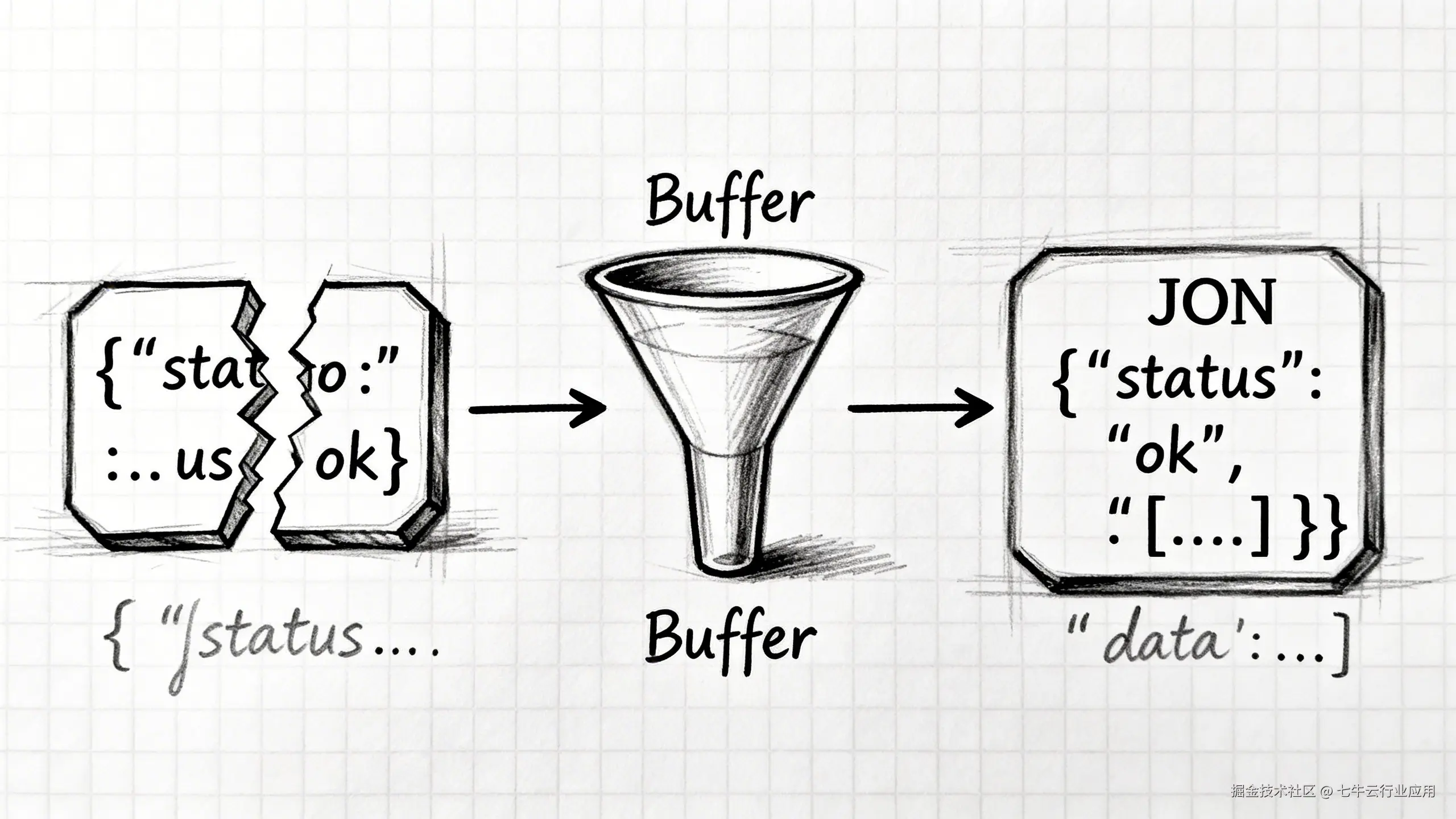
Seedance 的 API 是流式返回进度的 (stream=True)。问题在于,它吐出来的 chunks 不是按 JSON 边界切割的!
有时候网络一抖,一个完整的 JSON 对象会被切成两半:
● Chunk 1: data: {"status": "processing", "progre
● Chunk 2: ss": 45}
你直接对 Chunk 1 做 json.loads,必挂无疑。
- 暴力解法 (Python)
官方 SDK 还没出,只能自己手撸一个 Buffer 缓冲池。逻辑很简单:拼! 拼完了再试着解,解不开就继续拼下一个 chunk。
废话不多说,直接上代码。这段代码可以直接 copy 用,亲测稳得一匹。
Python
python
import requests
import json
def generate_video_safe(prompt):
url = "https://api.seedance.byte/v2/video/generate"
headers = {"Authorization": "Bearer YOUR_API_KEY"}
payload = {"prompt": prompt, "stream": True}
try:
# 必须开启 stream=True
response = requests.post(url, json=payload, headers=headers, stream=True)
buffer = "" # 定义一个缓冲池
for chunk in response.iter_content(chunk_size=1024):
if chunk:
# 1. 解码当前 chunk 并拼接到 buffer
part = chunk.decode('utf-8')
buffer += part
# 2. 尝试按行分割 (SSE 通常以 \n\n 分隔)
while "\n\n" in buffer:
message, buffer = buffer.split("\n\n", 1)
if message.startswith("data: "):
json_str = message.replace("data: ", "")
try:
# 3. 尝试解析 JSON
data = json.loads(json_str)
print(f"进度: {data.get('progress')}%")
# 4. 获取最终视频地址
if data.get('status') == 'succeeded':
video_url = data.get('output_url')
return optimize_url(video_url)
except json.JSONDecodeError:
# 解析失败说明数据不完整,跳过,等待下一个 chunk 拼接
continue
except Exception as e:
print(f"请求炸了: {e}")
# 【优化点】
# Seedance 原生出来的视频 URL(S3 链接)在国内访问巨慢,经常卡顿
# 建议在配置里套一层七牛云的 CDN 或者是 Kodo 的回源地址
# 否则前端 img 标签加载会转圈转到死
def optimize_url(origin_url):
# 这里记得换成你自己的七牛 CDN 域名
cdn_host = "https://cdn-video.your-domain.com"
# 简单的字符串替换,生产环境建议用正则
return origin_url.replace("https://tos-source.byte.com", cdn_host)
if __name__ == "__main__":
final_url = generate_video_safe("一只在敲代码的猫,赛博朋克风格")
print(f"生成完毕,加速链接: {final_url}")-
避坑总结
-
不要信 curl 示例: 生产环境必须处理 TCP 拆包粘包问题。
-
Buffer 是必须的: 别想着用 response.json() 直接拿结果,那是同步接口才配享有的待遇。
-
源站很慢: 如果你的应用是面向国内用户的,千万别直接下发源站 URL。我在代码里加了个 optimize_url 函数,把域名替换成了七牛云的 CDN 链接,加载速度从 10s 变成了 300ms,这才是用户能接受的体验。
代码拿走不谢,记得点个赞,今晚别通宵了。