Hello 我是方才,15人研发leader、5年团队管理&架构经验。
文末,附26年最新软考备考资料+备考交流群,群友可享受每月直播哟!
计划在26年更新100讲 架构知识干货,理论+实践,你的关注就是方才不断更新的动力。
在云原生时代,把存储和计算绑在一起,就像把火箭焊在加油站上------虽然能跑,但注定飞不远。
存算分离(Storage-Compute Separation)的出现,彻底打破了这一僵局。它将"计算"这种昂贵且易变的资源,与"存储"这种廉价且持久的资源解耦,这种模式让系统拥有了无限的弹性。
What:是什么
存算分离(Separation of Storage and Compute)是一种分布式系统架构模式。
核心思想是将负责数据处理的计算层 (Compute Layer)与负责数据持久化的存储层 (Storage Layer)物理隔离。
让两者成为独立的资源池,各自独立部署、弹性伸缩、生命周期管理与故障隔离。通过高速网络进行通信。
在传统架构中,扩容意味着购买新的服务器(同时包含CPU和磁盘);而在存算分离架构下,你可以单独增加CPU来提升查询速度,或者单独购买磁盘来存储更多数据。
 image-20260122072827557
image-20260122072827557
Who + When:起源与发展
-
起源:早期分布式系统(如Hadoop的HDFS+MapReduce)已出现"存储(HDFS)与计算(MapReduce)分离"的雏形,解决单机存储/计算瓶颈;
-
云原生阶段发展:
-
-
2015年CNCF成立后,容器化(Docker)与容器编排(K8s)普及,推动"计算无状态化",为分离模式奠定基础;
-
2016-2018年,云厂商推出标准化云存储(对象存储S3、块存储CSI、分布式文件存储),K8s发布CSI(容器存储接口),实现存储与容器的标准化对接;
-
2019年至今,存储计算分离成为云原生架构的主流模式,广泛应用于大数据、AI、微服务、Serverless等场景。
-
Why:技术价值
传统耦合架构的核心痛点:
-
弹性不同步:计算需快速扩缩(如秒杀、流量突增),但存储扩容慢(需停机/数据迁移),导致资源浪费或业务卡顿;
-
故障域重叠:计算节点故障会导致本地存储数据不可用,存储故障会直接影响绑定的计算节点,业务可用性低;
-
资源利用率低:计算节点闲置时,本地存储资源同步闲置,无法被其他节点复用,TCO(总拥有成本)高;
-
升级维护耦合:计算/存储任一组件升级,需整体停机维护,运维效率低、业务中断风险高;
-
数据共享难:本地存储仅能被绑定计算节点访问,多节点共享数据需额外同步,复杂度高。
而存算分离架构能带来各种好处:
-
资源解耦 :计算与存储的扩容、缩容、升级、维护互不干扰;
-
弹性伸缩 :计算层按需秒级扩缩,存储层按数据量平滑扩容,匹配不同业务的弹性需求;
-
资源池化 :存储资源全局共享,计算节点可按需访问共享存储,避免资源闲置;
-
故障隔离 :计算节点故障不影响存储数据,存储层故障可独立恢复,降低业务影响面;
-
成本优化:按实际使用量分配资源,避免"计算闲置时存储资源浪费"的问题。
 image-20260122075333864
image-20260122075333864
How:如何落地
关键分层
| 层级 | 核心组件 | 核心作用 |
|---|---|---|
| 计算层 | 无状态容器(K8s Pod)、Serverless函数、计算集群(Spark/Flink)、HPA(水平 Pod 自动扩缩) | 无状态化设计,专注业务逻辑处理,按需弹性伸缩,故障后快速重建 |
| 存储层 | 云原生存储(对象存储S3/MinIO、块存储CSI/EBS、分布式文件存储Ceph/GlusterFS、云数据库RDS/Redis) | 持久化存储数据,提供高可用、高吞吐、共享访问能力,支持弹性扩容 |
| 适配&管控层 | 数据访问代理( JDBC)、MinIO 网关 、监控(Prometheus)、容器存储接口(CSI)、kubernetes容器编排 | 解耦计算与存储的协议/权限/调度,实现标准化对接、自动化运维与可观测性 |
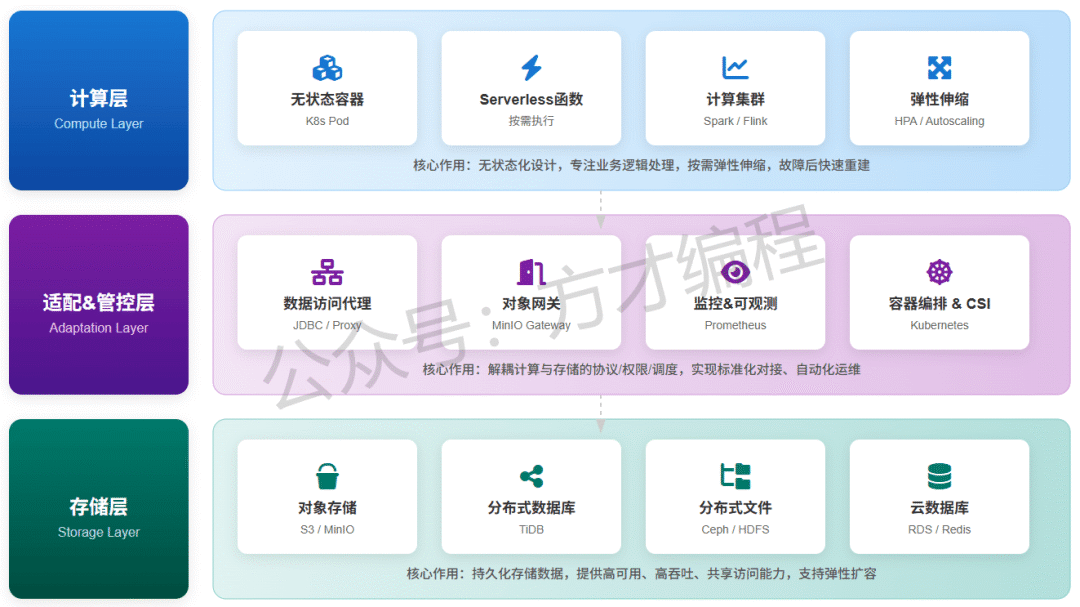 image-20260122075002471
image-20260122075002471
落地6步走
-
业务梳理:区分有状态/无状态业务,识别数据类型(冷数据/热数据、结构化/非结构化);
-
存储选型:按数据特性匹配存储类型(热数据选块存储/分布式文件,冷数据选对象存储,结构化数据选云数据库);
-
计算无状态化:改造应用,剥离本地存储数据至共享存储,移除节点本地状态;
-
适配层部署:安装CSI插件、数据访问代理,实现计算与存储的标准化对接;
-
高可用&弹性配置:配置存储副本/灾备、计算HPA策略,保障故障自愈与弹性能力;
-
监控&优化:搭建可观测体系(监控计算/存储/网络指标),优化存储分级、计算扩缩策略,降低成本。
经典示例
微服务架构
以大家最熟悉的电商微服务架构为例,理解下存储计算分离模式的应用:
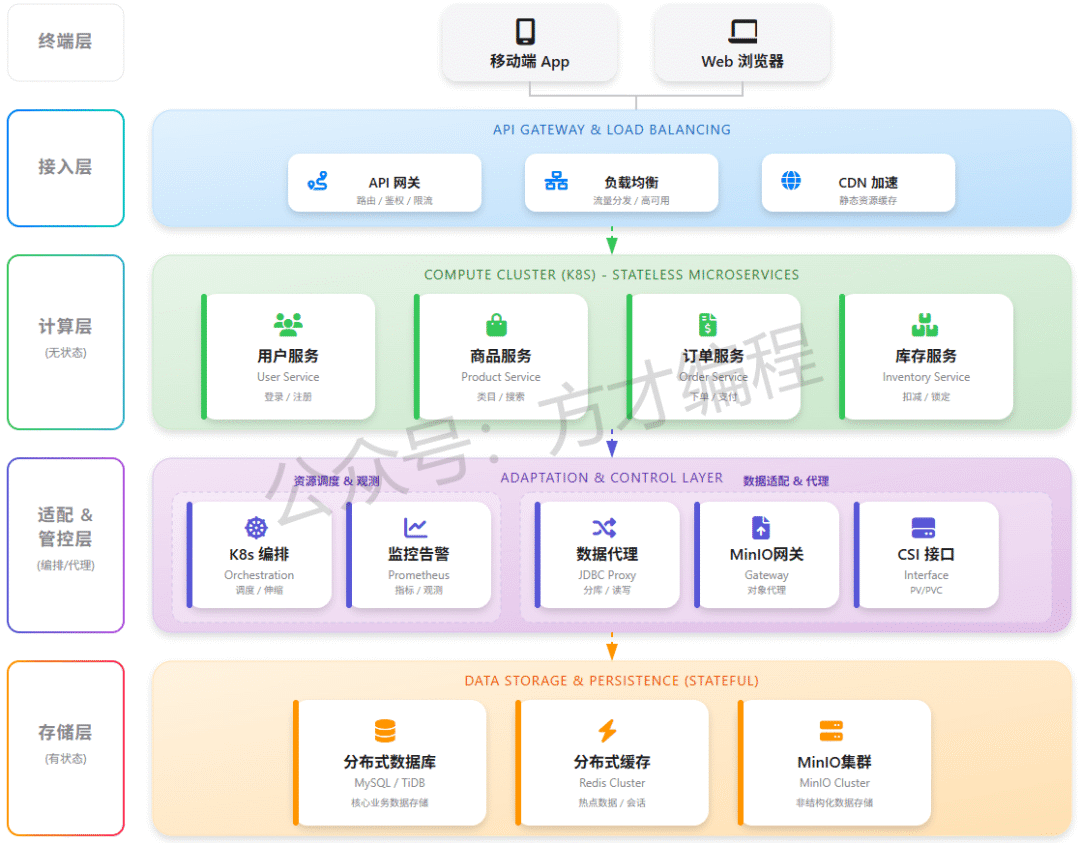 image-20260122083712038
image-20260122083712038
这里方才就只简单讲解下 计算层、存储层和适配&管控层了:
1)计算层(无状态):业务逻辑核心
基于 Kubernetes(K8s)集群运行无状态微服务,每个服务聚焦单一业务域,实现解耦与弹性扩展。
-
用户服务:处理登录、注册、个人信息管理等用户域业务,是账号体系的核心。
-
商品服务:负责商品类目、搜索、详情展示,支撑用户对商品的浏览与检索。
-
订单服务:管理下单、支付、订单状态流转,是交易流程的核心链路。
-
库存服务:处理库存扣减、锁定、回滚,保障交易中库存数据的准确性(防止超卖)。
💡 关键设计:无状态意味着服务不保存会话或业务数据,重启 / 扩容不影响请求处理,因此可通过 K8s 快速扩缩容,轻松应对流量波动(如大促时临时加机器)。
2)存储层(有状态):数据持久化底座
负责数据的安全存储与高性能读写,采用多组件适配不同业务场景:
-
分布式数据库(MySQL/TiDB):存储核心业务数据(如用户、商品、订单),支持事务强一致性,TiDB 等分布式方案还能应对海量数据的水平扩展。
-
分布式缓存(Redis Cluster):缓存热点数据(如高频访问的商品详情)与用户会话(如登录态),加速读写、减轻数据库压力。
-
对象存储(OSS/S3):存储非结构化数据(如商品图片、视频、用户文件),容量大、成本低,适合海量文件的长期存储。
💡 关键设计:当随着系统的运行,数据量增加,可以单独扩展存储节点,比如增加TiKV节点,上层业务计算层是无需感知的;这样存储层就可以按需购买扩容;或者单独增加归档类的冷数据的存储节点,即满足需求,又便宜。
3)适配 &管控层:封装基础能力
这是连接"计算"与"存储"的关键纽带,负责资源编排、数据代理和系统观测。关键组件 :
-
K8s 编排 (Orchestration) :Kubernetes 作为云原生操作系统,负责计算层容器的调度、自动恢复和弹性伸缩。
-
CSI 接口 (Container Storage Interface) :容器存储接口,统一管理底层存储卷(PV/PVC)的挂载,屏蔽底层存储差异。
-
监控告警 (Prometheus) :云原生监控标准,采集各层指标(Metrics),配合 Grafana 展示,实现可观测性。
-
数据代理 (JDBC Proxy) :这是一层虚拟层,一般会通过持久化框架(比如Mybatis Plus),集成在计算层的各种微服务中,便于计算层服务访问数据。
-
MinIO 网关 (MinIO Gateway) : 统一非结构化数据入口 ,所有微服务上传/下载图片、视频等文件时,不直接连接底层 MinIO 集群,而是通过此网关,实现权限统一控制、流量监控和协议适配。
云原生数据库TiDB
后续会更详细讲解TiDB的内容,这里先简单看看,理解下存算分离模式的应用。
TiDB 是一款开源云原生分布式关系型数据库, 适合高可用、强一致要求较高、数据规模较大等各种应用场景。
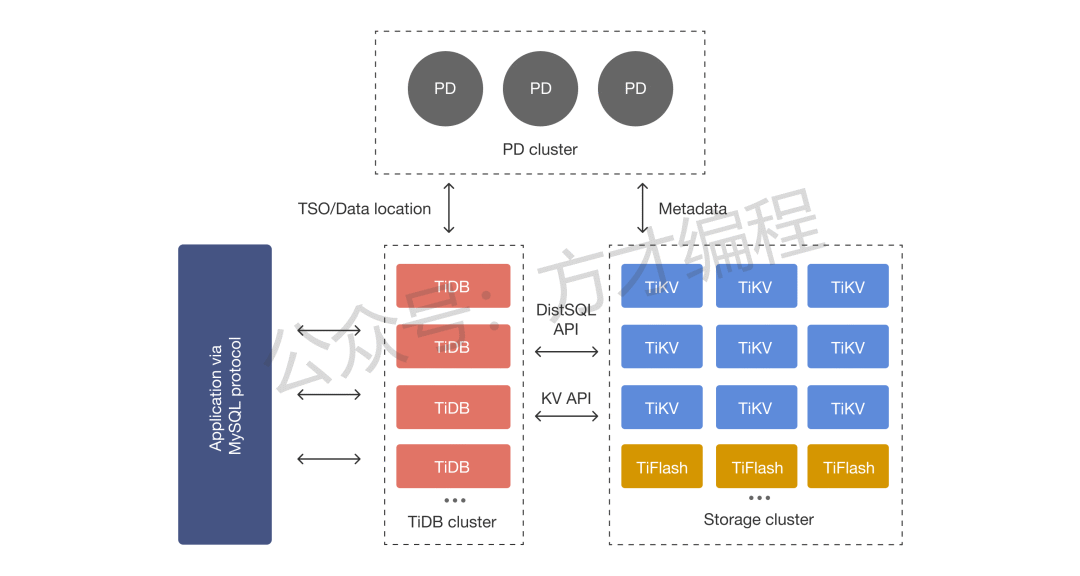 architecture
architecture
-
PD (Placement Driver) Server:是整个集群的"大脑",是整个集群的管控和调度中心,所有核心元数据都由 PD 管理。能力包括:元数据管理、Region调度、副本管控、全局事务协调等等;
-
TiDB Server:无状态的 SQL 处理层,是用户与 TiDB 集群交互的唯一入口,核心功能如下:
-
-
SQL 解析与优化:接收客户端的 SQL 请求后,先做词法 / 语法解析,再通过优化器生成最优的分布式执行计划;
-
分布式执行协调:将优化后的执行计划拆解为多个子任务,分发给存储层的 TiKV 节点执行;
-
结果聚合:收集所有 TiKV 节点返回的子任务结果,汇总后返回给客户端;
-
无状态扩展:TiDB Server 本身不存储任何数据,节点可按需水平扩容(比如从 2 个扩到 10 个),单个节点故障不会影响集群,请求会自动路由到其他节点。
-
-
存储节点
-
-
TiKV Server:分布式、持久化的 KV 存储层,是 TiDB 所有数据的最终存储载体。
-
TiFlash:TiFlash 是一类特殊的存储节点,数据是以列式的形式进行存储,主要的功能是为分析型的场景加速。
-
以一个SQL的执行流程为例:
-
用户的 SQL 请求会直接或者通过
Load Balancer发送到 TiDB Server; -
TiDB Server 会解析
MySQL Protocol Packet,获取请求内容**,对 SQL 进行语法解析和语义分析**,制定和优化查询计划; -
执行查询计划并获取和处理数据:数据全部存储在 TiKV 集群中,所以在这个过程中 TiDB Server 需要和 TiKV 交互,获取数据;
-
最后 TiDB Server 将查询的数据根据SQL语义计算处理后,返回给用户。
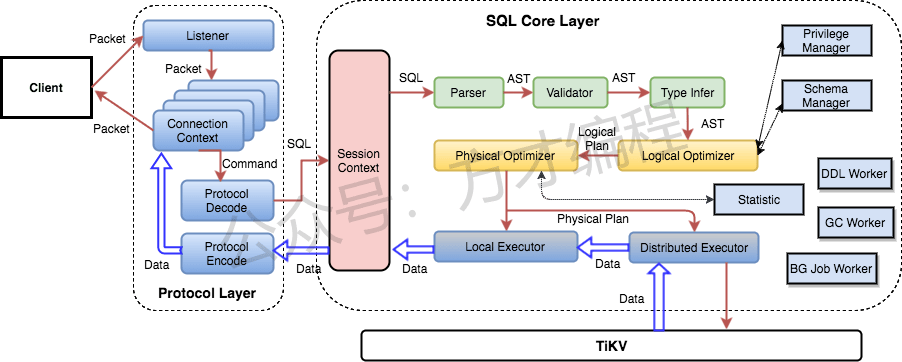 tidb sql layer
tidb sql layer
得益于 TiDB 存储计算分离的架构的设计,可按需对计算、存储分别进行在线扩容或者缩容,扩容或者缩容过程中对应用运维人员透明。
How Much:运行效果
-
性能层面:计算层弹性响应时间从分钟级降至秒级,存储层支持 PB 级数据平滑扩容
-
成本层面:资源利用率提升 30%-70%
-
运维层面:计算 / 存储独立升级,运维停机时间减少80%+,自动化运维(Operator)降低人工操作成本 60%+;
-
扩展性层面:支持万级计算节点与 PB 级存储的横向扩展,无架构天花板。
脆弱性分析
-
网络依赖风险:分离后计算与存储通过网络通信,网络抖动、带宽瓶颈、延迟过高会直接影响业务性能(尤其OLTP低延迟场景);
-
数据一致性风险:多计算节点并发访问共享存储,易出现脏读、写冲突,需额外引入分布式锁/事务机制,增加复杂度;
-
安全风险:数据跨网络传输,需保障传输加密(TLS)、存储加密(AES),否则存在数据泄露风险;权限管控不当易导致越权访问;
-
运维复杂度风险:新增适配层与独立的存储层,需运维团队同时掌握计算、存储、网络技能,运维成本上升;
论文写作思路
必过营的伙伴可参考阅读今日的独家论文范文。
-
云原生存储计算分离的上层计算层落地:无状态化设计与弹性伸缩实践。
-
云原生存储计算分离的底层存储层设计:分布式存储选型与高可用架构构建;
-
云原生存储计算分离的中间适配层实现:结构化数据的数据访问层、非结构化数据的统一存储网关服务;
26年软考资料&备考群
2026最新的系分/架构备考资料和备考交流群,扫码即可领取加入(若提示太频繁,后台回复1即可):
你们的点赞、爱心和评论,就是方才不断更新的功力!  给点鼓励可好
给点鼓励可好
还没关注方才的伙伴,记得点个关注,方才每周至少更新一篇干货知识 