提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- [2. 软件⽣命周期](#2. 软件⽣命周期)
- [2. 功能架构介绍-租房](#2. 功能架构介绍-租房)
- [3. 编写](#3. 编写)
- [4. 建立关系](#4. 建立关系)
- [5. 逻辑设计](#5. 逻辑设计)
- 总结
前言
(⾯试题)
- 请描述数据库设计的主要步骤,并说明每个步骤的重点?
- 请解释⼀下数据库设计中的范式,并举例说明它们的应⽤?
- 数据库范式可以解决什么问题?
- 在设计数据库表时,如何考虑数据的完整性和安全性?
- 请举例说明⼀对⼀、⼀对多和多对多关系在数据库设计中的实现⽅式?
- 请描述如何使⽤ E - R 图进⾏数据库设计,并举例说明?
- 如何在数据库设计阶段考虑系统的扩展性?
2. 软件⽣命周期
软件⽣命周期中以划分为可⾏性研究、需求分析、概要设计、详细设计、实现、组装(集成)测试、确认测试、使⽤、维护、退役10个阶段


数据库设计步骤
❤️ 可以分为四个阶段
• 需求分析
• 概念设计
• 逻辑设计
• 物理设计
需求分析
• 需求分析阶段产出的需求⽂档将指导数据库的设计,包括数据模型的构建和数据库结构的规划。
• 需求分析还包括数据的安全性和隐私保护要求,以及数据备份和恢复策略。
概念设计
• 概念性设计阶段,设计师需要构建数据模型,包括实体-关系模型(ER模型)和类图。
• ER模型通过实体、属性和关系来描述数据结构,是理解数据关系的重要⼯具。
• 类图则更侧重于对象之间的关系,适⽤于⾯向对象的数据库设计

逻辑设计
• 逻辑设计阶段,将概念设计转化为具体的数据库结构,包括表结构和视图的定义。
• 表结构定义包括字段的名称、数据类型、⻓度等属性,以及表之间的关系。
• 通过创建视图,可以简化复杂的查询,提⾼数据的安全性和易⽤性。
物理设计
• 物理设计阶段,需要考虑数据库的存储细节,包括⽂件的存储位置、是否创建索引和数据分区。
• ⽂件存储位置的选择会影响数据的访问速度和备份策略。
• 索引的创建需要权衡查询效率和维护成本。
• 数据分区可以提⾼⼤规模数据库的管理效率
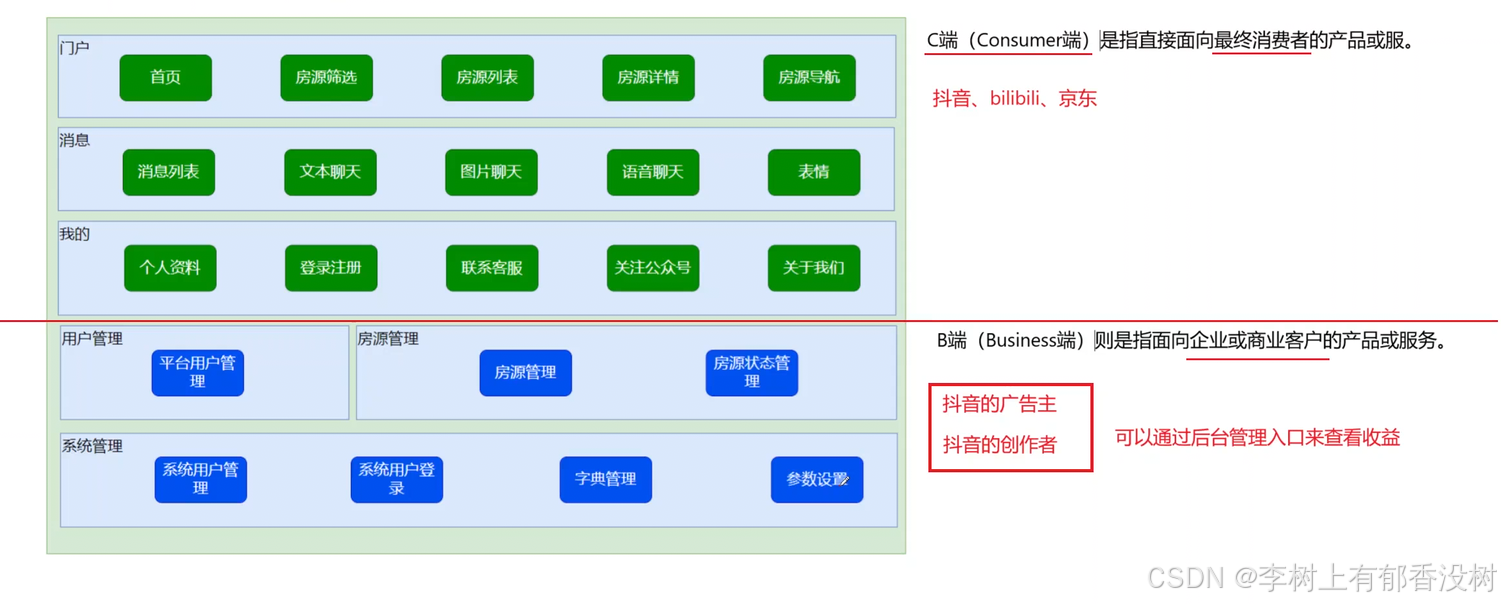
2. 功能架构介绍-租房
3. 编写
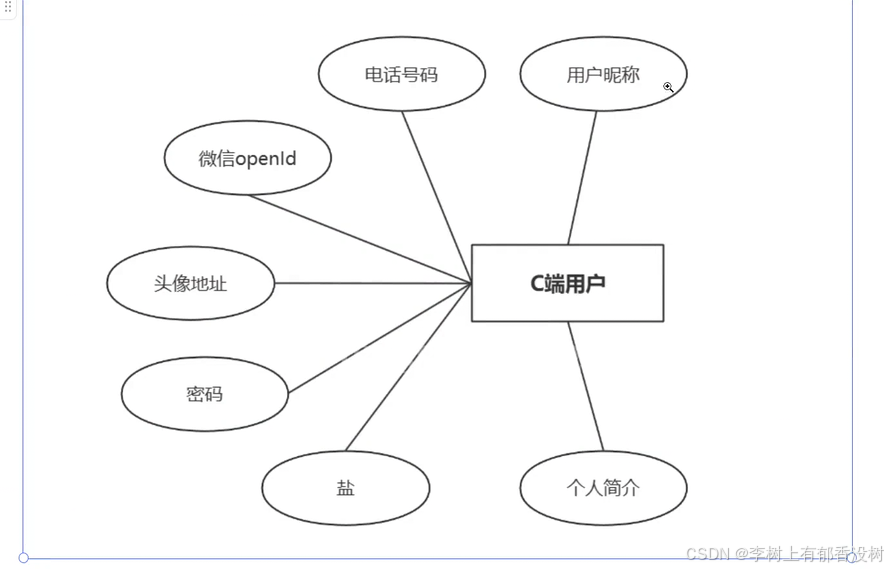
绘制ER图
sql
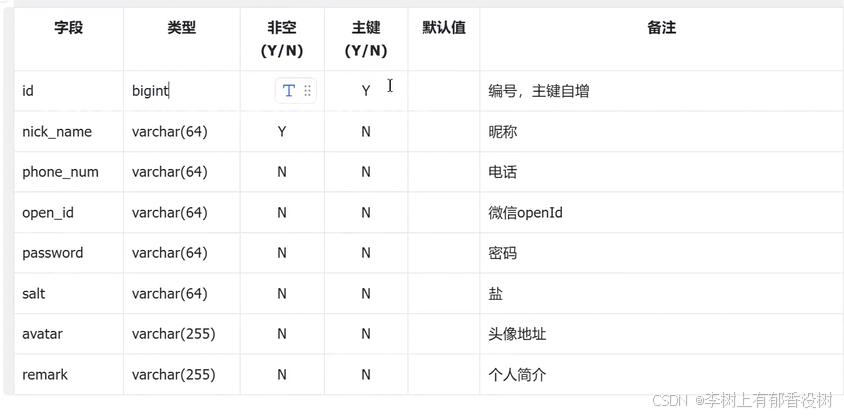
-- 创建C端用户表app_usre
create table app_usre (
id bigint primary key auto_increment comment '编号,主键自增',
nick_name varchar(64) not null comment '昵称',
phone_num varchar(64) comment '电话',
open_id varchar(64) comment '微信openId',
password varchar(64) comment '密码',
salt varchar(64) comment '盐',
avatar varchar(255) comment '头像地址',
remark varchar(255) comment '个人简介'
);
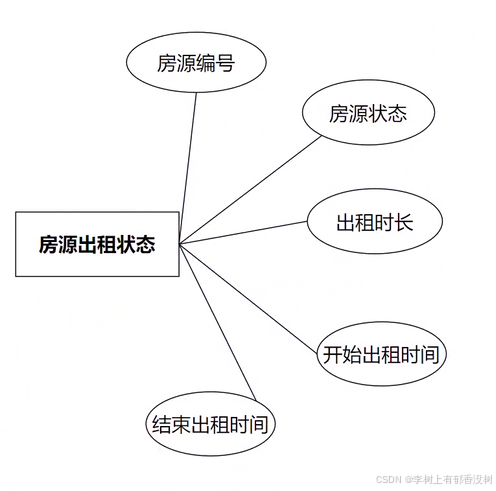
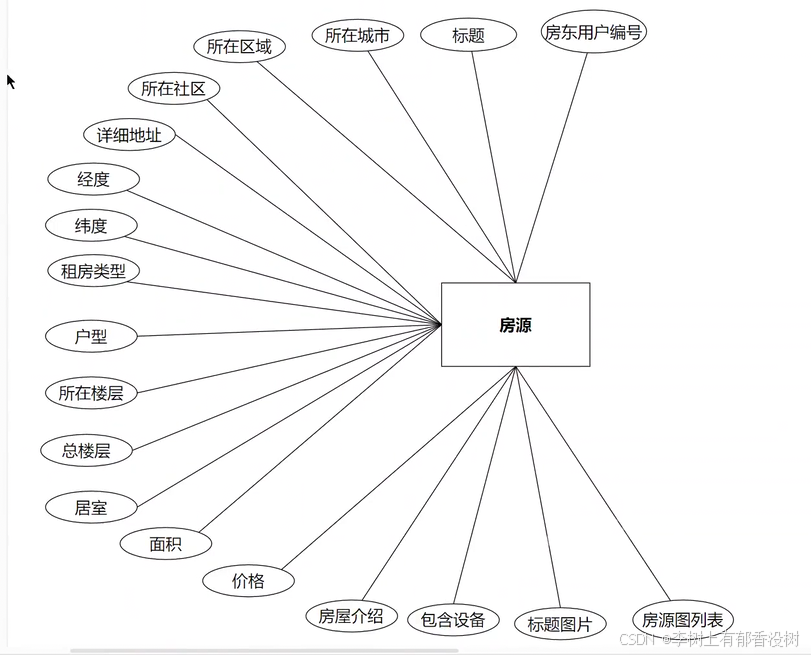
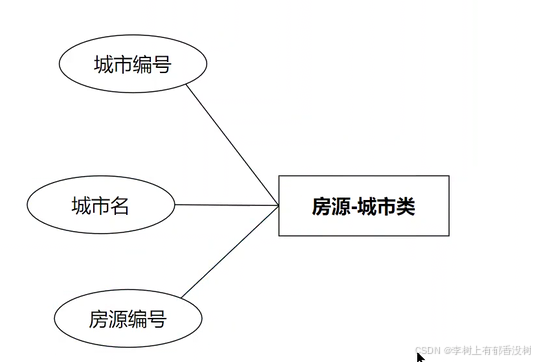
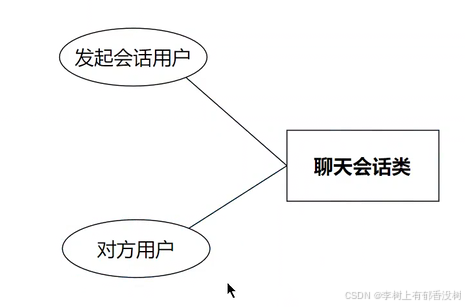
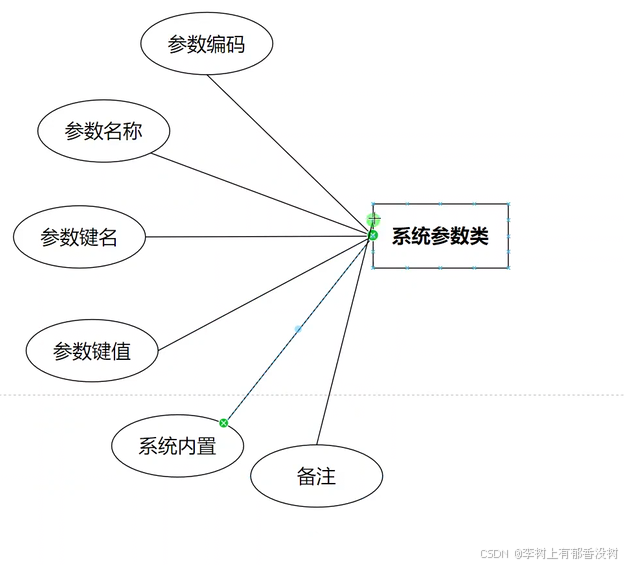
4. 建立关系
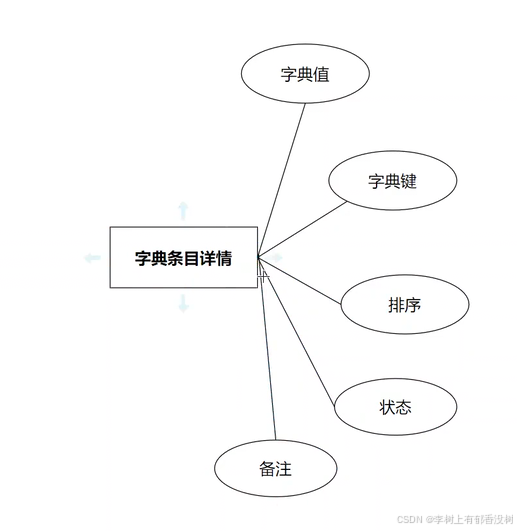
字典类型-字典条⽬
字典类型-字典条⽬之间是⼀对多系,⼀个类型下可以配置多个条⽬
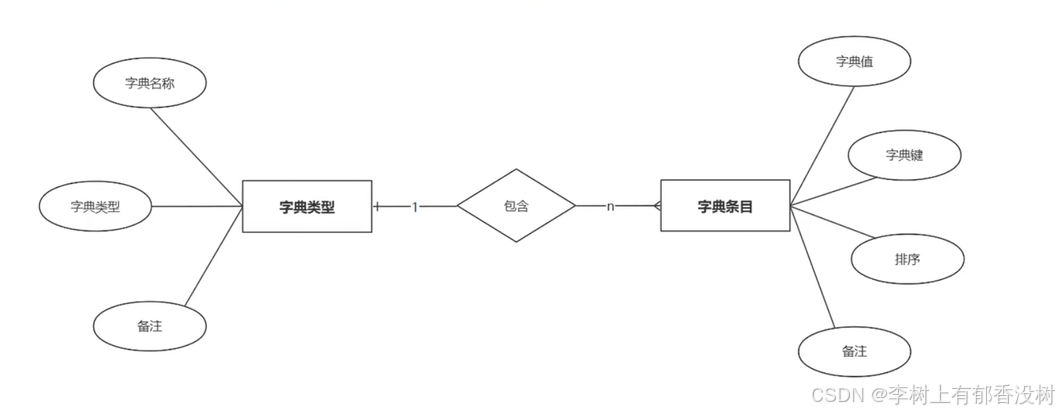
1个字典有多个条目,就是有多个选择,下拉框有多个选择
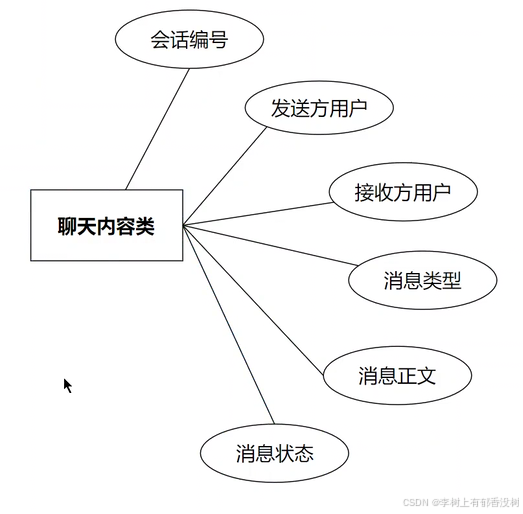
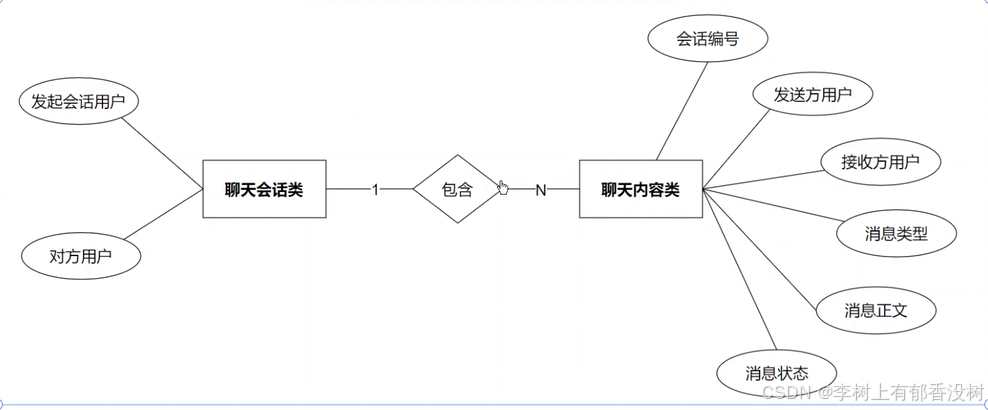
聊天会话-聊天内容
聊天会话-聊天内容之间是⼀对多系,⼀个会话下多条聊天内容
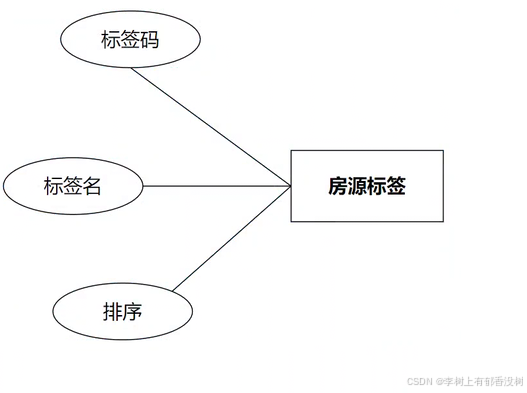
房源与关联表
• 出租状态是房源是⼀对⼀关系
• 房源标签与房源是多对多关系
• 房源与⾏政区域是多对⼀关系
⼀对多关系在从表中通过关联字段与主表建⽴关系
多对多关系通过单独创建关系表建⽴两表之间的关系
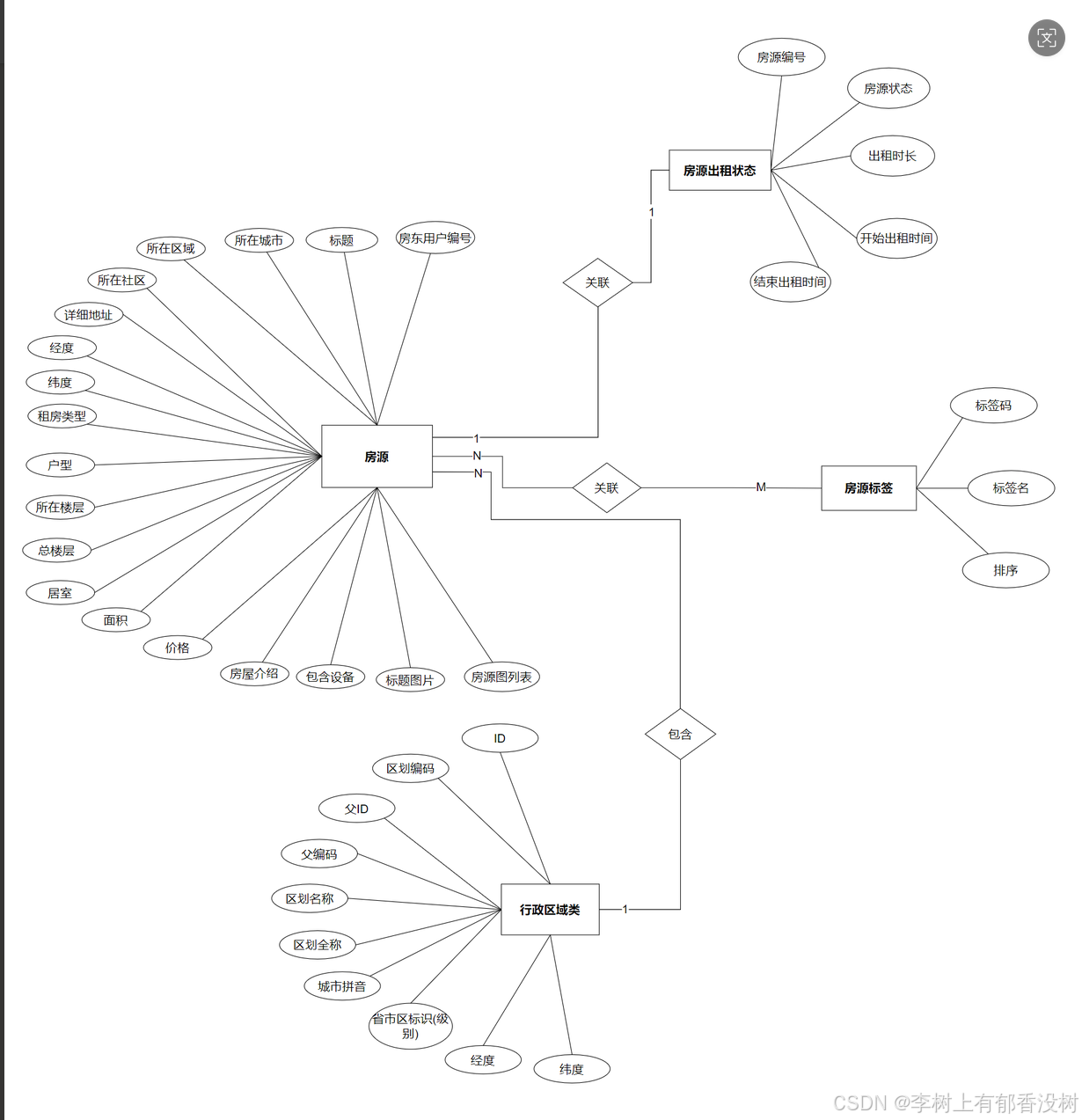
5. 逻辑设计
数据库名: bit-zufang
表名前缀:为每个表添加必要的前缀,以便区分所⽀撑的业务类型,常⻅的前缀类型:
• 系统表(sys_):如系统⽤⼾表(sys_user)、系统⻆⾊表(sys_role)
• 业务表(app_):如⽤⼾表(app_user)、房源表(app_house)
• 字典表(dic_):如地区表(dic_region)、ICD编码(dic_icd)
• 关系表(rel_):如rel_user_role,保存多对多关系数据
• 统计表(sta_):如sta_product_sale,从其他表中计算得出统计数据
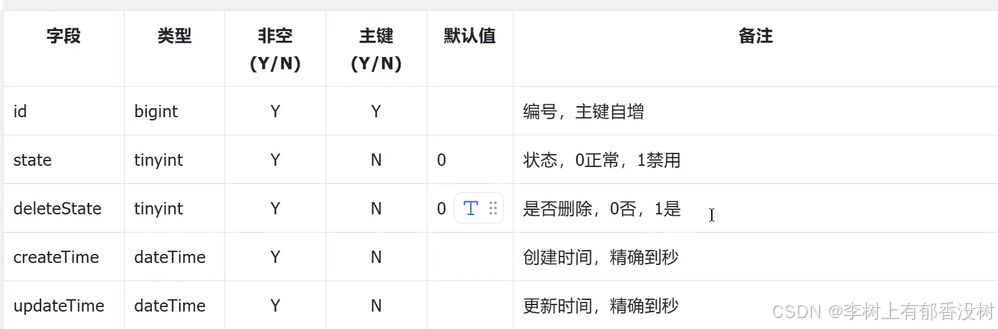
公共字段:⽆特殊说明的情况下,每张表必须有⻓整型的⾃增主键,删除状态、创建时间、更新时间,如下所⽰:
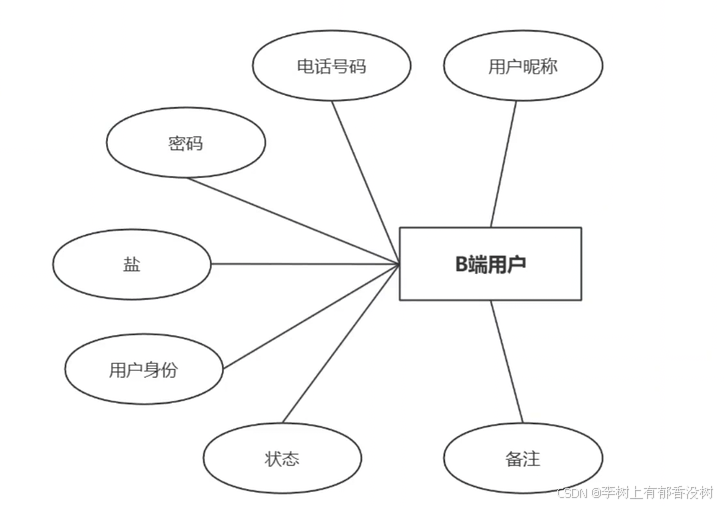
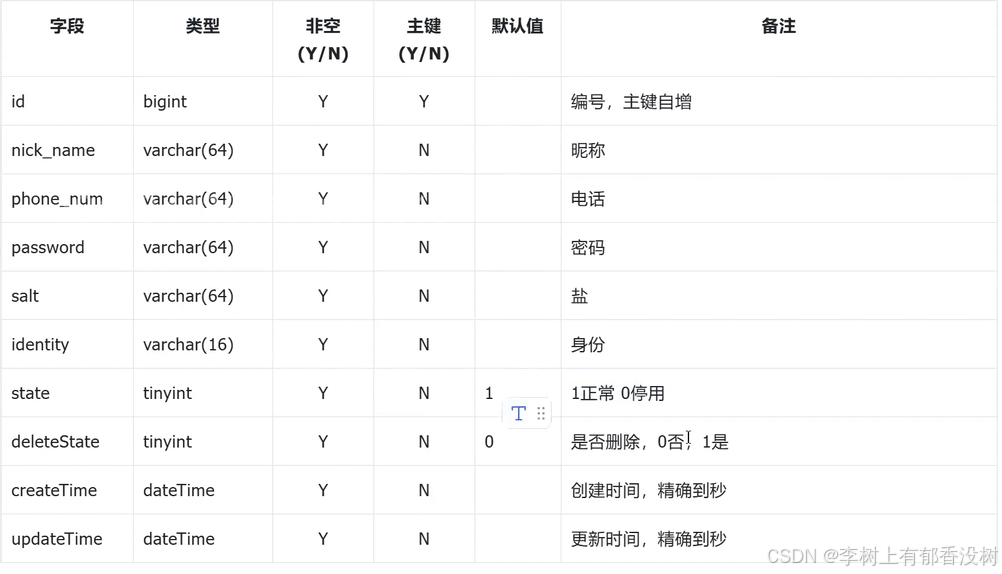
B端⽤⼾表sys_usre
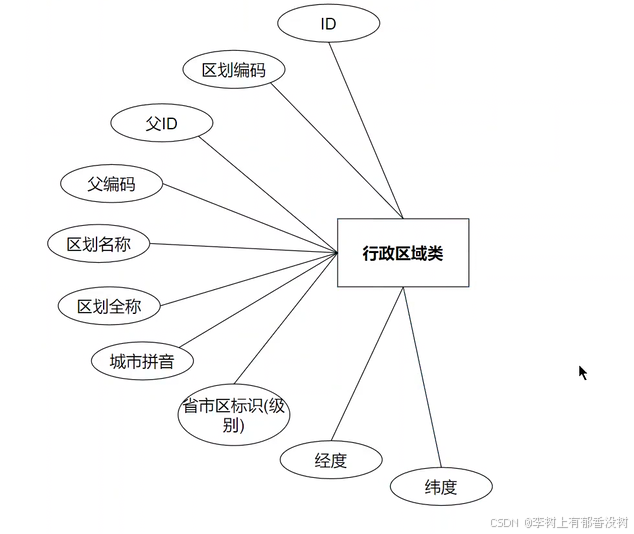
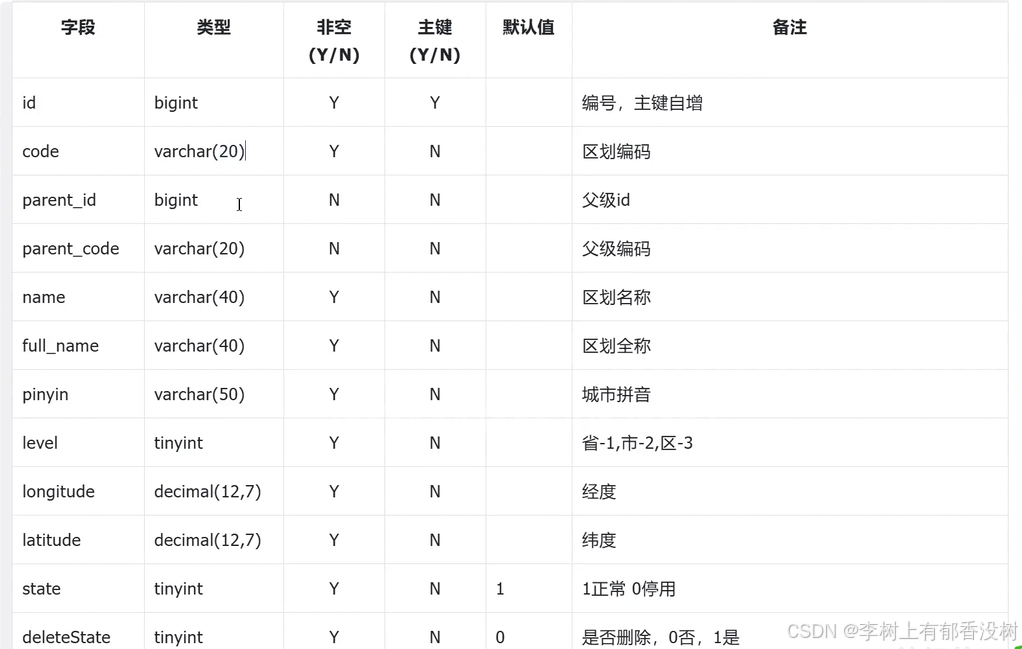
⾏政区域表sys_region
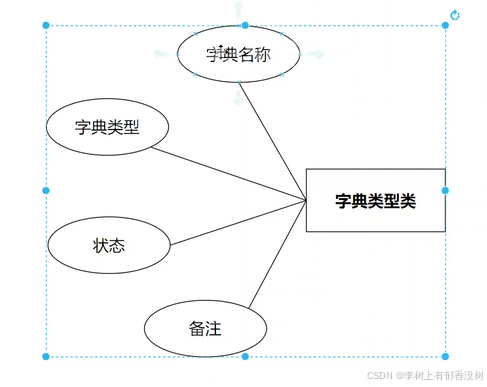
字典类型表sys_dic_type
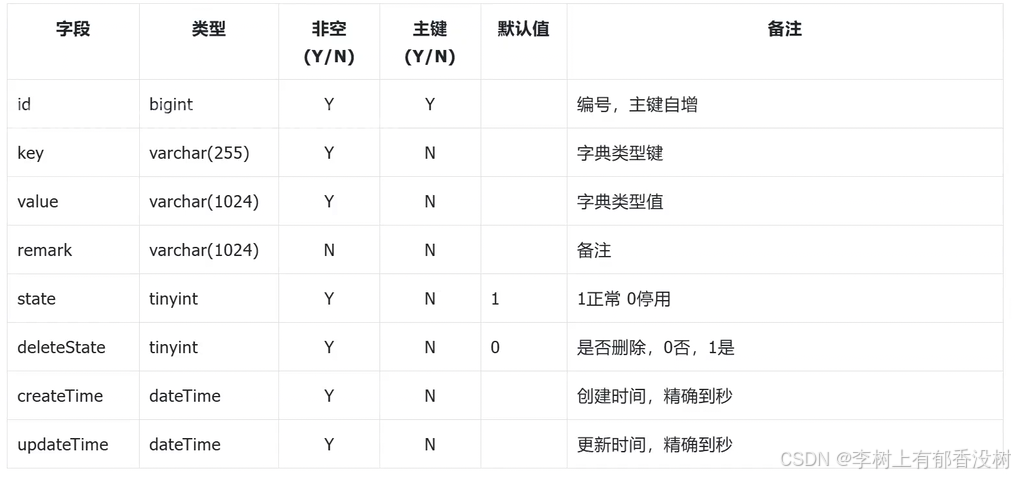
等等就不全部弄出来了
最后就是编写SQL了