在数据团队的日常中,你是否也常听到这样的声音:
"能不能让我用自然语言问数据?"
"这个 PDF 合同里有没有风险条款?"
"帮我检查下这个货架排放是否和规划一致。"
作为数据开发者,我们熟悉 SQL、数仓分层、ETL 流程,但面对这些需求,往往只能无奈摇头------因为它们背后是大模型、多模态、向量检索等"AI 工程"的地盘。而搭建一套 RAG 系统?那意味着 GPU 集群、LangChain、FastAPI、向量数据库......技术栈陡增,运维成本飙升。
但今天,我想告诉你:这些场景,其实用 SQL 就可以解决。
阿里云 Hologres 深度集成百炼大模型平台,推出 AI Function 能力------无需 Python,无需额外服务,用你熟悉的 SQL,直接调用大模型,实现从结构化数据到图片、PDF、视频的全模态智能分析。
为什么是 Hologres + 百炼?
传统 AI 方案存在三大痛点,而 Hologres + 百炼给出了精准解法:
1. AI 与数据割裂: 数据在数仓,模型在外网,来回搬运不仅慢,还存在安全风险。
→ Hologres 让模型"走进"数据,推理就在数据旁完成,数据不出库。
2. 工程成本高: 自建 LLM 服务需 GPU、API 网关、限流熔断......数据团队难以维护。
→ 百炼提供托管式大模型服务,Hologres 通过函数一键调用,零运维。
3. 技术栈不匹配: SQL 开发者不会写 LangChain,算法工程师不懂数仓分层。
→ 用 SQL 编排 AI 逻辑,让数据团队主导端到端 AI 应用。
百炼是什么?能为数据开发带来什么?
百炼是阿里云推出的一站式大模型开发与应用构建平台,集成了千问(Qwen)、DeepSeek、Kimi 等主流模型,支持文本生成、多模态理解(如 Qwen-VL)、Embedding、翻译等多种能力。
对数据开发者而言,百炼的核心价值是:你只管"怎么用",不用管"怎么跑"。
-
模型部署、弹性扩缩、监控告警全部由平台托管;
-
兼容 OpenAI API,迁移成本低;
-
支持 VPC 内调用,满足企业安全合规要求;
-
按 token 计费,开箱即用,无闲置资源浪费。
Hologres 如何与百炼协同工作?
Hologres 与百炼的集成通过 API Key 方式直接调用,兼顾敏捷性与生产级性能: 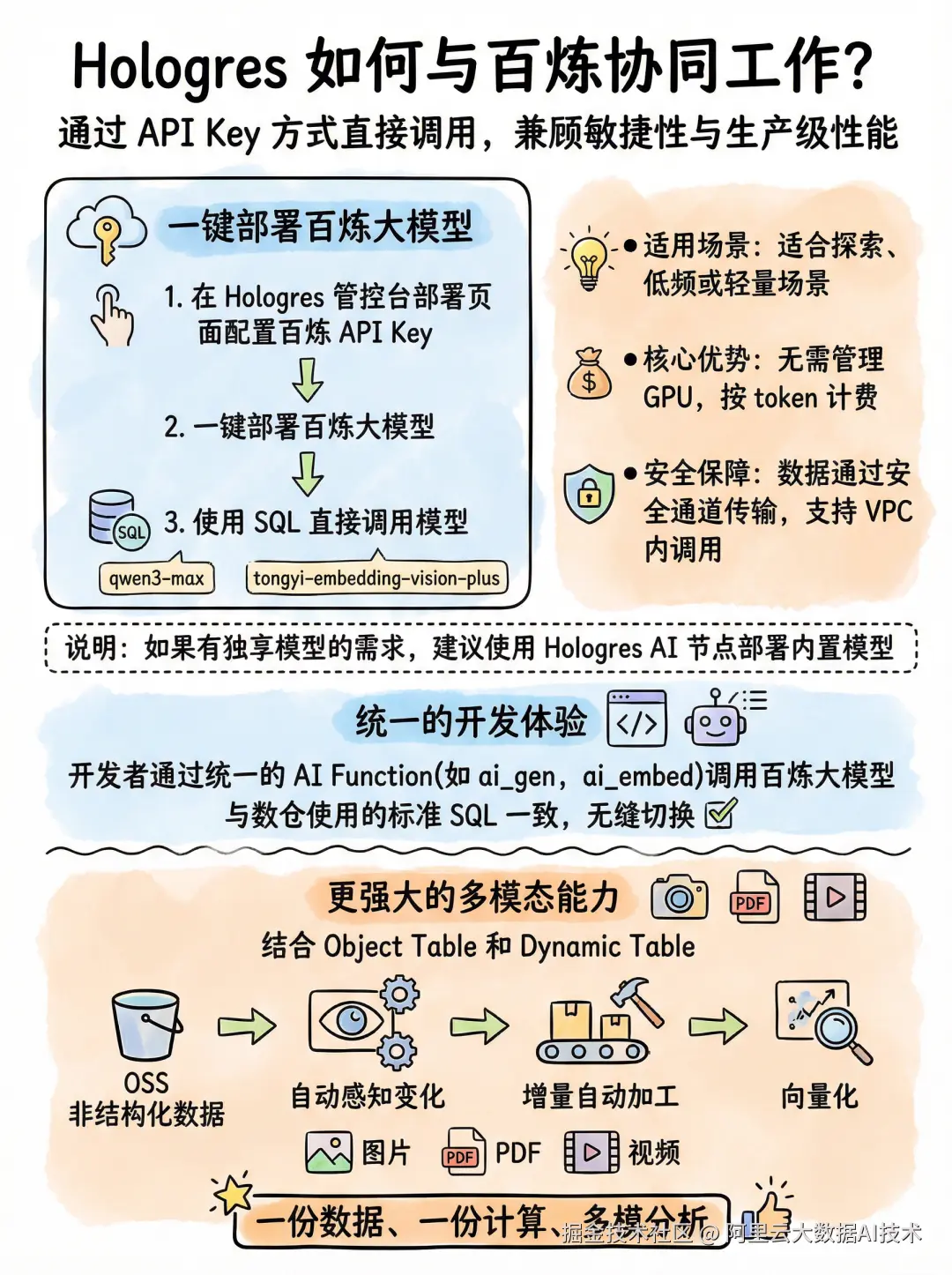 只需在 Hologres 管控台部署页面中配置一个百炼 API Key,随后一键部署百炼大模型,接着使用 SQL 就能直接调用百炼平台上的模型(如 qwen3-max、tongyi-embedding-vision-plus)。
只需在 Hologres 管控台部署页面中配置一个百炼 API Key,随后一键部署百炼大模型,接着使用 SQL 就能直接调用百炼平台上的模型(如 qwen3-max、tongyi-embedding-vision-plus)。
说明:如果有独享模型的需求,建议使用Hologres AI 节点部署内置模型
-
适用场景:适合探索、低频或轻量场景;
-
核心优势:无需管理 GPU,按 token 计费;
-
安全保障:数据通过安全通道传输,支持 VPC 内调用。
统一的开发体验
开发者通过统一的 AI Function(如 ai_gen, ai_embed)调用百炼大模型,与数仓使用的标准SQL一致,无缝切换。
更强大的多模态能力
更强大的是,结合 Object Table 和 Dynamic Table,Hologres 还能自动感知 OSS 中的非结构化数据(如图片、PDF、视频)变化,实现增量自动加工与向量化,真正做到"一份数据、一份计算、多模分析"。
AI Function 详解:SQL 就是你的 AI 编排语言
Hologres 提供丰富的 AI 函数,覆盖从预处理到推理的全链路,全部通过标准 SQL 调用:
| 功能类别 | 函数示例 | 典型用途 |
|---|---|---|
| 多模态解析 | ai_parse_document |
PDF/图片转文本 |
| 文本预处理 | ai_chunk, ai_mask |
长文本切片、敏感信息脱敏 |
| 信息提取 | ai_extract |
抽取合同中的金额、日期等字段 |
| 向量化 | ai_embed |
文本/图像生成 embedding,支持多模态模型 |
| 语义计算 | ai_similarity, ai_rank |
相似度打分、结果重排序 |
| 生成与理解 | ai_gen, ai_summarize, ai_classify, ai_analyze_sentiment |
问答、摘要、分类、情感分析 |
| 翻译 | ai_translate |
多语言互译 |
实战场景:从"写报表"到"看懂非结构化世界"
过去,数据开发的核心战场是结构化数据------我们建模、聚合、调度,最终产出一张张报表。但今天,真正的业务洞察往往藏在 PDF 合同、门店照片、车载视频这些非结构化数据中。如何让这些"沉默的数据"也能被 SQL 查询?Hologres + 百炼给出了答案。 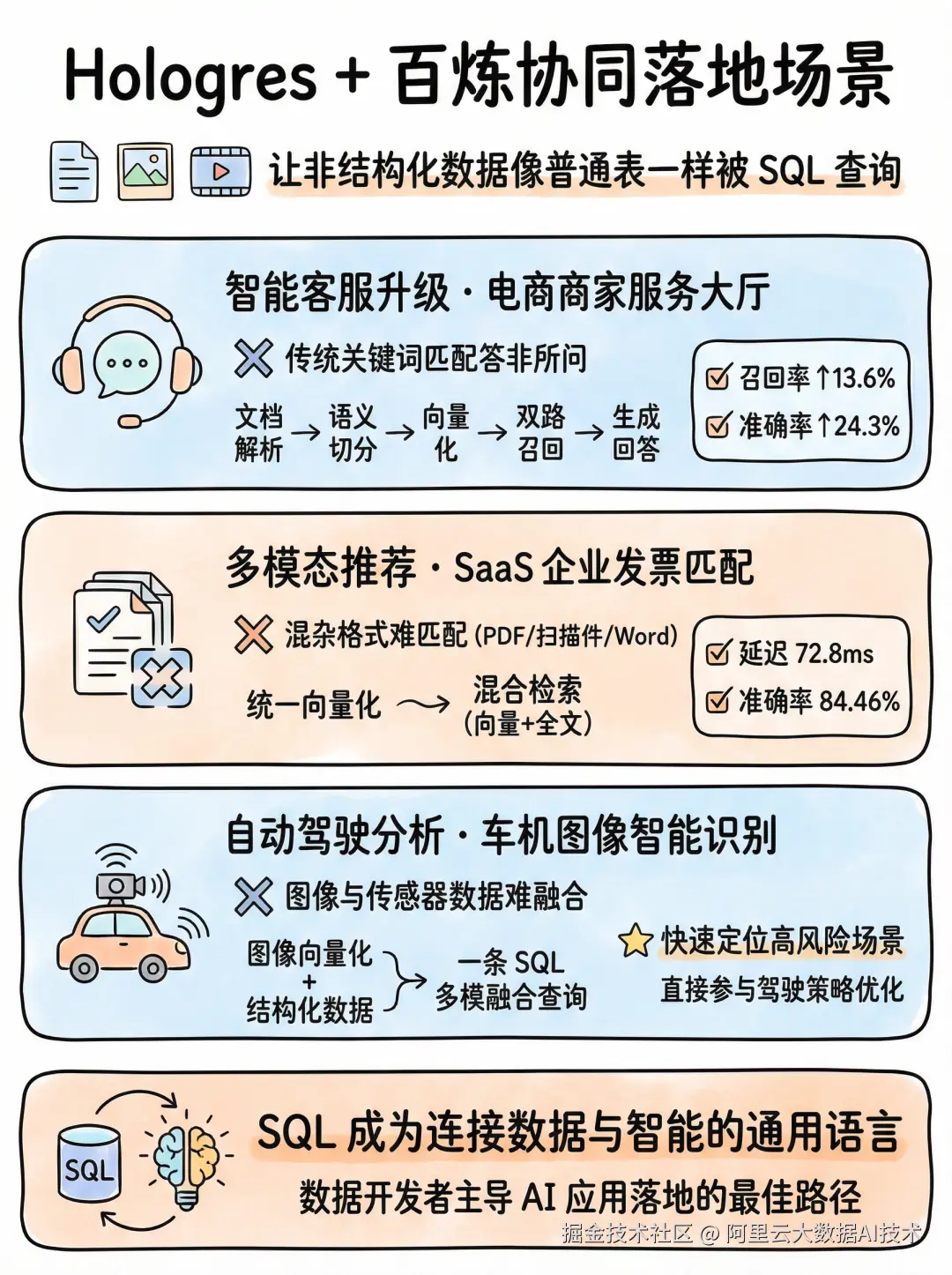
智能客服升级:淘宝商家服务大厅的 RAG 实践
每天有数百万淘宝商家咨询平台规则、售后流程或营销政策,传统基于关键词匹配的知识库系统常常答非所问。阿里巴巴 CCO(客户体验团队)希望构建一个真正理解语义的智能问答系统:当商家输入"怎么处理买家恶意退货?",系统能精准召回并生成相关解决方案。
借助 Hologres,他们将上万篇帮助文档存入 OSS,并通过 Object Table 自动同步文件元信息。利用 Dynamic Table 的声明式能力,系统对新增文档自动调用 ai_parse_document 解析内容,再用 ai_chunk 按语义切分段落,最后通过 ai_embed 调用百炼的 text-embedding-v4 模型生成向量,持久化到 Hologres 表中。当用户提问时,系统先用 ai_embed 将问题向量化,在 Hologres 内完成向量与全文的双路召回,再通过 ai_rank 精排候选结果,最终由 ai_gen(调用 qwen3-max)生成自然语言回答。整个链路无需导出数据、无需外部服务编排,全部由标准 SQL 驱动。上线后,召回率提升 13.6 %,准确率提升 24.3 %,点击率同步显著上升,真正实现了"问得准、答得对"。
SaaS 企业多模态推荐:发票与合同的智能匹配
某全球 Top SaaS 企业提供 ERP 系统,客户每天上传大量发票、合同和流水单据,期望系统能自动推荐历史相似模板,减少重复填写。但这些文件格式混杂(PDF、扫描件、Word),传统 OCR 加规则引擎的方式效果有限,且维护成本高。
该企业将所有非结构化文件统一存入 OSS,通过 Hologres 的 Object Table 自动感知这些非结构化文件的元数据,借助 Dynamic Table,使用增量的能力调用 ai_parse_document 提取文本内容,并使用 ai_embed(基于百炼的 tongyi-embedding-vision-plus 多模态模型)为每份文档生成统一 embedding。查询时,用户上传一份新发票,系统自动将其向量化,并在 Hologres 中执行混合检索------同时结合向量相似度与全文关键词(如客户名称、金额、税号)进行联合打分排序。得益于 Hologres 强大的混合索引与高性能向量引擎,单并发平均延迟仅 72.8ms,40 并发下仍保持毫秒级响应,准确率达 84.46%。更重要的是,数据无需同步至专用向量数据库,统一存储于 Hologres,大幅降低数据冗余、同步复杂度与总体拥有成本(TCO)。
自动驾驶多模分析:让车机图像"可查可算"
在智能驾驶领域,某车企需要从海量车机图像与传感器信号中识别高风险场景,例如"行人突然横穿马路"。传统方案需将图像送至独立 CV 平台处理,推理结果再回流至数仓,不仅链路长,还存在时间戳对齐难、数据不一致等问题。
现在,他们将原始图像存于 OSS,结构化信号(GPS 坐标、车速、刹车压力等)实时写入 Hologres。通过 Object Table,系统自动将图像与对应的结构化事件关联。再利用 Dynamic Table,对新增图像调用 ai_embed(使用百炼部署的 Qwen3-VL 多模态模型)生成视觉 embedding,并与结构化字段拼接成宽表。安全分析团队只需一条 SQL:
plaintext
SELECT image_url, ai_similarity(vision_emb, ai_embed('行人横穿')) AS risk_score
FROM driving_events
WHERE speed > 30 AND brake_pressure > 0.8
ORDER BY risk_score DESC;即可快速定位高风险片段。这种"多模融合分析"能力,让数据团队能直接参与驾驶策略优化与事故归因,而不再只是日志的搬运工。
这些案例共同揭示了一个趋势:AI 正从算法黑盒走向数据基础设施的一部分。Hologres + 百炼让非结构化数据像普通表一样被管理、加工、查询,而 SQL 成为了连接数据与智能的通用语言------这正是数据开发者主导 AI 应用落地的最佳路径。
结语:SQL 开发者的 AI 时代已来
Hologres + 百炼不是"又一个 AI 工具",而是将大模型能力深度融入数据基础设施。它让数据开发者无需转型为 AI 工程师,也能构建前沿的多模态智能应用。
你不需要再写胶水代码,不需要申请 GPU 集群,不需要协调算法团队------用 SQL,就能释放大模型的价值。
现在就行动:
-
在 Hologres 中配置一个百炼 API Key,
-
或部署一个模型到 AI 节点,
-
然后运行这条 SQL:
plaintext
SELECT ai_gen('用一句话总结 Hologres + 百炼的价值');答案会是:让数据开发,真正成为 AI 时代的生产力引擎。