1.使用正则完成下列内容的匹配
-
匹配陕西省区号 029-12345
-
匹配邮政编码 745100
-
匹配身份证号 62282519960504337X
python
import re
#- 匹配陕西省区号 029-12345
print(re.match(pattern=r"^029-\d{5}$", string="029-12345"))
#- 匹配邮政编码 745100
print(re.match(pattern=r"^\d{6}$", string="745100"))
#- 匹配邮箱 lijian@xianoupeng.com
print(re.match(pattern=r"^[a-zA-Z0-9_-]+@[a-zA-Z0-9_-]+\.[a-zA-Z0-9_-]+$", string="lijian@xianoupeng.com"))
#- 匹配身份证号 62282519960504337X
print(re.match(pattern=r"^\d{17}[\dXx]$", string="62282519960504337X"))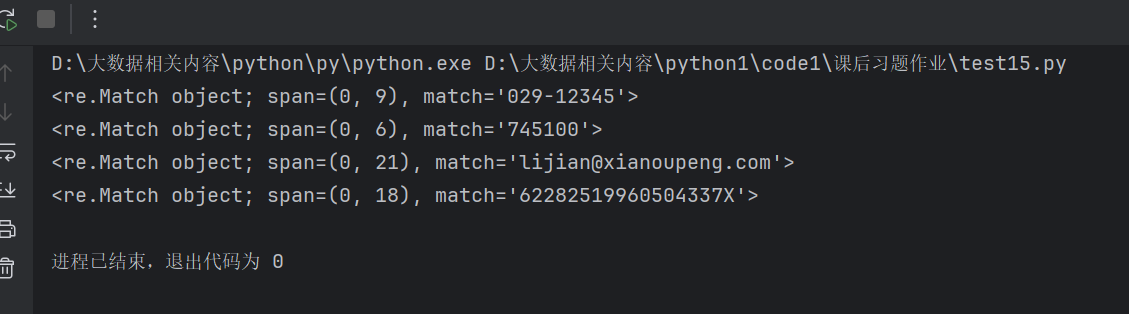
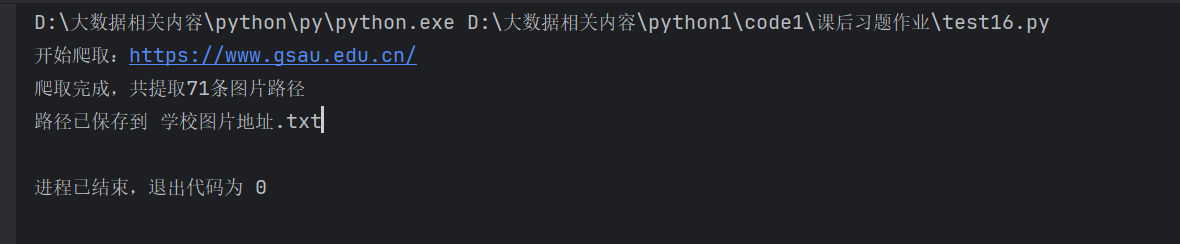
2.爬取学校官网,获取所有图片途径并将路径存储在本地文件中,使用装饰器完成
python
import requests
import re
def log_crawl(func):
def wrapper(url):
print(f"开始爬取:{url}")
result = func(url) # 执行核心爬取函数
print(f"爬取完成,共提取{len(result)}条图片路径")
return result
return wrapper
@log_crawl
def get_img_urls(url):
res = requests.get(url, headers={"User-Agent": "Mozilla/5.0"})
res.encoding = "utf-8"
return re.findall(r'<img src="(.*?)"', res.text)
if __name__ == "__main__":
url = "https://www.gsau.edu.cn/"
img_list = get_img_urls(url)
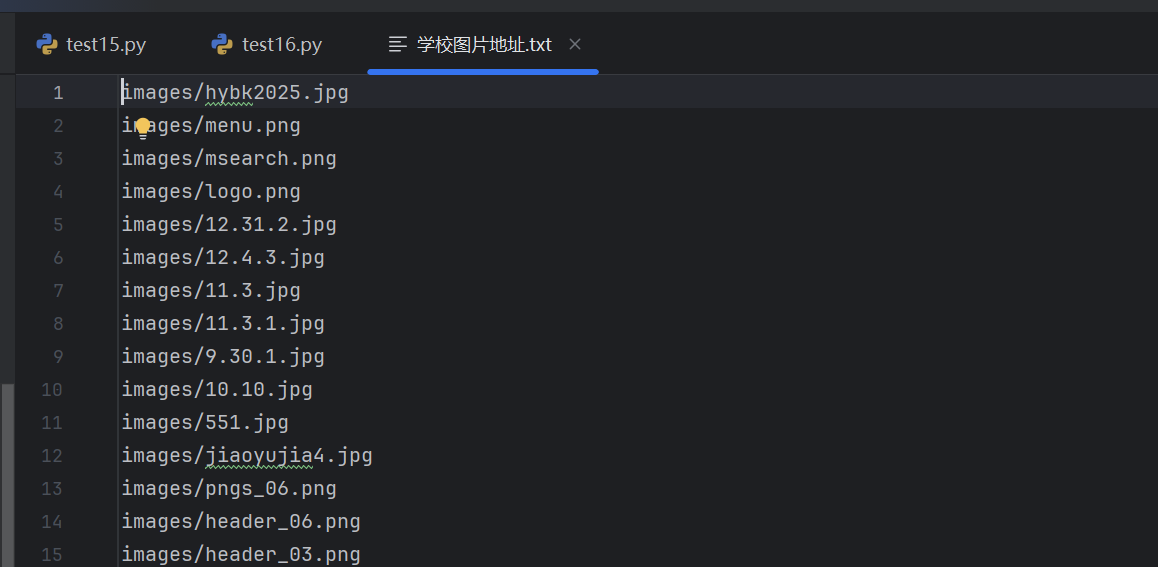
with open("学校图片地址.txt", "w", encoding="utf-8") as f:
f.write("\n".join(img_list))
print("路径已保存到 学校图片地址.txt")