消息中间件:从异步通信到 Kafka 的高可用设计之道
前言
在大型分布式系统中,消息中间件(Message Queue)被誉为架构的"减震器"和"润滑剂"。无论是应对突发的流量洪峰,还是实现复杂服务间的解耦,MQ 都发挥着不可替代的作用。本文将结合消息中间件的通信模式,深入剖析顶级消息队列 Apache Kafka 的核心原理。
一、 为什么分布式系统需要消息中间件?
1.1 通信模式的变革:从"打电话"到"发邮件"
传统的同步调用(RPC/HTTP)好比打电话:张三必须等到李四接听并处理完事务才能挂机,如果李四正忙,张三就只能陷入无尽的等待,浪费大量时间。
消息中间件引入了类似 E-mail 的通信模式:
- 生产者(张三):只需将邮件投递到收件箱,即可去忙其他事情。
- 消费者(李四):在自己空闲时从收件箱拉取邮件处理。
- 消息队列(E-mail系统):作为中转站,确保消息不丢失。
1.2 消息中间件的三大核心价值
-
异步化 :将非核心业务逻辑从主流程中剥离。例如,一个请求原本需要串行执行 610ms,通过 MQ 异步处理非核心逻辑后,用户感知的响应时间可缩短至 10ms 。

添加消息中间件后 :
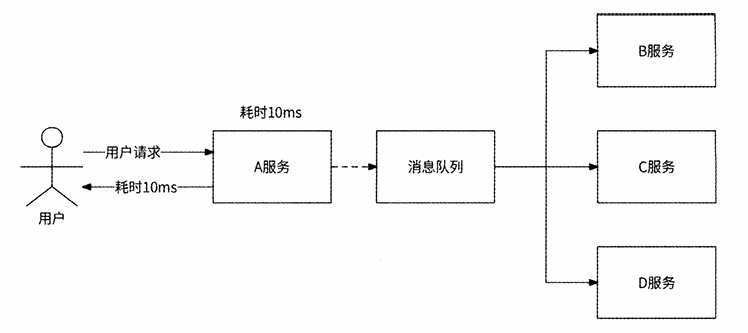
-
流量削峰 :在流量高峰期(如双11),MQ 充当缓冲池。后端服务根据自身的处理能力(如 100 QPS)平滑拉取消息,即使前端瞬时流量达到 10000 QPS,也不会压垮数据库。

-
解耦:实现"发布/订阅"模式。当新业务(如热点服务、策略服务)需要订阅核心业务(如点赞服务)的数据时,无需修改核心服务代码,只需订阅对应的 Topic 即可。
二、 走进 Kafka:核心概念与架构解析
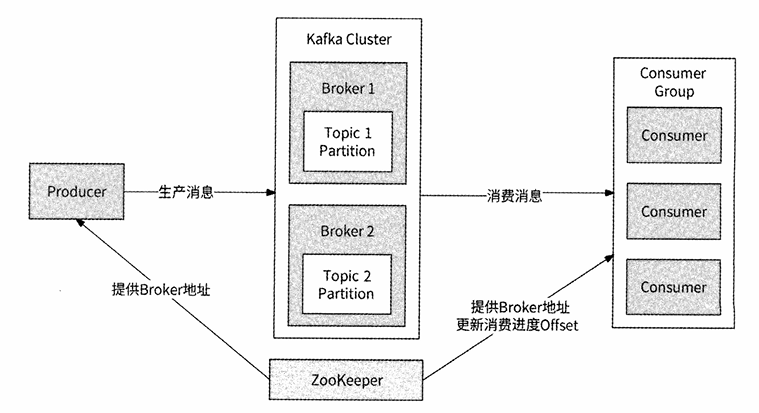
Kafka 是由 LinkedIn 开发的高性能、分布式日志收集及消息系统。其整体架构由以下核心组件构成:
2.1 核心组件清单
- Topic(主题) :消息的分门别类(如:
user_like_events)。 - Partition(分区):实现负载均衡的关键。一个 Topic 可以拆分为多个 Partition,分布在不同的 Broker 上,提升并行处理能力。
- Broker(代理):Kafka 的核心节点,负责消息的存储与收发。
- Consumer Group(消费者组):Kafka 保证一个 Partition 在同一个组内只能被一个消费者消费,避免重复处理。
- ZooKeeper :Kafka 的"大脑",负责元数据管理、Broker 注册、Leader 选举及消费进度(Offset)的维护。
2.2 消息的路由策略
当生产者发送消息时,如何决定去哪个分区?
- 显式指定:直接发送到目标分区。
- Key 哈希:根据消息的 Key 计算 Hash 值,确保相同 Key 的消息进入同一分区(保证局部有序)。
- 轮询(Round Robin):无 Key 且未指定分区时,均匀分配到所有分区。
三、 Kafka 的高可用与故障恢复机制
在分布式环境下,如何保证系统宕机时消息不丢失?Kafka 通过 副本(Replica) 和 ISR 机制 给出了解法。
3.1 副本机制
每个 Partition 都有一个 Leader 和若干 Follower:
- 所有的读写请求都由 Leader 处理。
- Follower 仅负责从 Leader 同步数据,作为热备。
- 为了防范单点故障,Kafka 会尽可能将同一 Partition 的不同副本分散在不同的物理 Broker 上。
3.2 ISR (In-Sync Replicas) 机制
Kafka 没有采用极端的完全同步(性能差)或完全异步(易丢数据),而是发明了 ISR 机制:
- Leader 维护一个与自己保持同步的副本列表(ISR)。
- 只有当 ISR 中所有的 Follower 都确认收到消息,Leader 才认为写入成功。
- 如果某个 Follower 同步太慢,会被踢出 ISR;待其追上进度后再重新加入。
3.3 故障自动恢复流程
当某个 Broker 发生故障,Kafka 依靠 Controller 实现快速恢复:
- 发现故障:ZooKeeper 监测到 Broker 断连并通知 Controller。
- 筛选影响:Controller 查询哪些 Partition 的 Leader 在该故障节点。
- 选举新 Leader :从受影响 Partition 的 ISR 列表 中选出一个 Follower 提升为新 Leader。
- 同步变更:将新的路由信息广播给其他所有相关 Broker。
四、 总结与思考
消息中间件的设计本质上是在性能、可用性与一致性之间做权衡。Kafka 通过分区提升了吞吐量,通过磁盘顺序写保证了持久化,通过 ISR 机制在同步与异步之间找到了精妙的平衡。
在实际项目中,理解这些底层原理能帮助我们更好地进行系统选型和调优。例如,如果你的业务对顺序性要求极高,请务必关注消息的 Key 设计;如果你追求极致的写入吞吐,则需要根据 ISR 规模和 Acks 配置进行权衡。