


专栏:JavaEE 进阶跃迁营
个人主页:手握风云
目录
[一、MyBatis 的基础操作](#一、MyBatis 的基础操作)
[1.1. 增(insert)](#1.1. 增(insert))
[1.2. 删(delete)](#1.2. 删(delete))
[1.3. 改(update)](#1.3. 改(update))
[二、MyBatis XML 配置文件](#二、MyBatis XML 配置文件)
[2.1. 添加 mapper 接口](#2.1. 添加 mapper 接口)
[2.2. 添加对应的 XXX.xml 映射文件](#2.2. 添加对应的 XXX.xml 映射文件)
[2.3. 增删查改操作](#2.3. 增删查改操作)
[1. 查(Select)](#1. 查(Select))
[2. 增(Insert)](#2. 增(Insert))
[3. 删(Delete)](#3. 删(Delete))
[4. 改(Update)](#4. 改(Update))
[3.1. 多表查询](#3.1. 多表查询)
[3.2. #{} 和 {}](#{} 和 {})
[1. 使用方式与底层实现差异](#1. 使用方式与底层实现差异)
[2. 核心区别](#2. 核心区别)
[3. {} 的不可替代使用场景](#3. {} 的不可替代使用场景)
[4. 使用原则](#4. 使用原则)
一、MyBatis 的基础操作
1.1. 增(insert)
Mapper 接口通过 @Insert 注解编写插入 SQL,使用#{实体类属性名}绑定动态参数,方法接收对应实体类对象,返回值为 Integer 类型,代表受影响的行数。
java
@Insert("INSERT INTO user_info (username, `password`, age) VALUE (#{username}, #{password}, #{age})")
Integer insertUser(UserInfo userInfo);
java
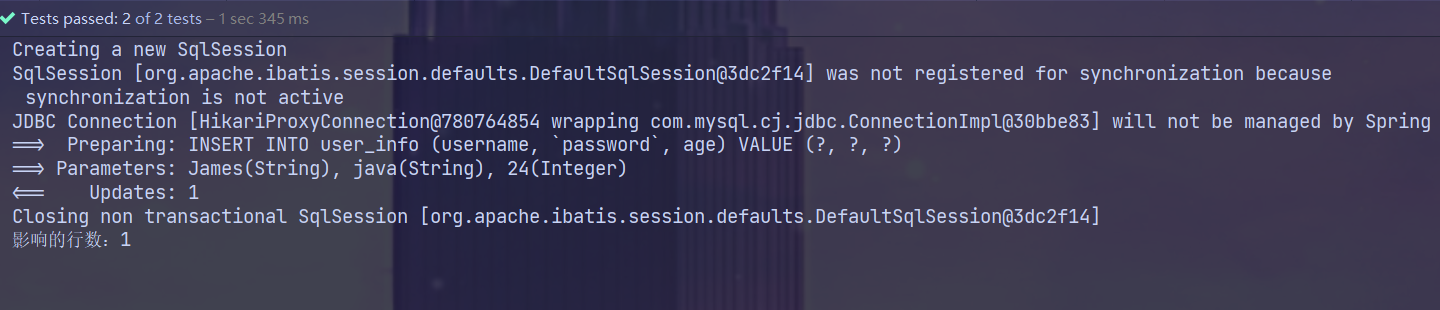
@Test
void insertUser() {
UserInfo userInfo = new UserInfo("James", "java", 24);
Integer rows = userInfoMapper2.insertUser(userInfo);
System.out.println("影响的行数:" + rows);
}
若方法参数通过 @Param 设置别名,SQL 中需通过#{别名.实体类属性名}获取参数。
java
@Insert("insert into user_info (username, `password`, age) VALUE(#{userInfo.username}, #{userInfo.password}, #{userInfo.age} )")
Integer insertUser2(@Param("userInfo") UserInfo userInfo);
java
@Test
void insertUser2() {
UserInfo userInfo = new UserInfo("Linux", "C", 25);
Integer rows = userInfoMapper2.insertUser2(userInfo);
System.out.println("影响的行数:" + rows);
}在 @Insert 注解上添加@Options(useGeneratedKeys = true, keyProperty = "id"),开启自增主键获取功能;useGeneratedKeys 表示启用 JDBC 的自增主键获取,keyProperty指定将自增主键赋值到实体类的 id 属性;方法返回值仍为受影响行数,自增的主键 ID 会自动赋值到实体类对象的对应属性中。
java
@Options(useGeneratedKeys = true, keyProperty = "id")
@Insert("insert into user_info (username, `password`, age) VALUE(#{username}, #{password}, #{age} )")
Integer insertUser3(UserInfo userInfo);
java
@Test
void insertUser3() {
UserInfo userInfo = new UserInfo("Tom", "C++", 26);
Integer rows = userInfoMapper2.insertUser3(userInfo);
System.out.println("影响行数:"+ rows+", 自增id:" + userInfo.getId());
}1.2. 删(delete)
通过@Delete注解编写删除 SQL,使用#{参数名}绑定动态的 id 参数,Mapper 接口方法接收Integer类型的 id 参数,实现根据主键 id 删除数据库中指定数据。
java
@Delete("delete from user_info where id = #{id}")
Integer deleteUser(Integer id);
java
@Test
void deleteUser() {
Integer rows = userInfoMapper2.deleteUser(7);
System.out.println("影响行数:"+ rows);
}1.3. 改(update)
通过@Update注解编写更新 SQL,使用#{实体类属性名}绑定动态参数(如修改的字段值、主键 id),Mapper 接口方法接收对应实体类对象,实现根据主键 id 修改数据库中指定字段的值。
java
@Update("update user_info set gender = #{gender}, delete_flag = #{deleteFlag} where id = #{id}")
Integer updateUser(UserInfo userInfo);
java
@Test
void updateUser() {
UserInfo userInfo = new UserInfo();
userInfo.setId(6);
userInfo.setGender(1);
userInfo.setDeleteFlag(1);
Integer rows = userInfoMapper2.updateUser(userInfo);
System.out.println("影响行数:"+ rows);
}二、MyBatis XML 配置文件
2.1. 添加 mapper 接口
创建持久层接口,添加 @Mapper 注解,让 MyBatis 识别该接口并交由 Spring IOC 容器管理,与注解方式的接口注解使用一致;接口中定义需要的数据库操作抽象方法(如查询所有用户的queryAllUser()),方法的返回值、参数与业务需求匹配即可。
2.2. 添加对应的 XXX.xml 映射文件
我们需要先在配置文件 application.yml 中,mybatis.mapper-locations 指定的路径下,与配置匹配。
XML
mybatis:
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
map-underscore-to-camel-case: true #自动驼峰转换
mapper-locations: classpath:mapper/*Mapper.xml接着我们需要固定 XML 格式,里面必须包含 XML 声明、MyBatis 的 DOCTYPE 约束,以及根标签 <mapper>,是 MyBatis XML 的基础规范。
java
package com.yang.test2_9_1.mapper;
import com.yang.test2_9_1.model.UserInfo;
import org.apache.ibatis.annotations.Mapper;
import java.util.List;
@Mapper
public interface UserInfoMapperXmlMapper {
List<UserInfo> selectList();
}
XML
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.yang.test2_3_1.mapper.UserInfoMapperXML">
<select id="selectList" resultType="com.yang.test2_3_1.model.UserInfo">
SELECT * FROM `user_info`
</select>
</mapper><mapper> 标签:通过 namespace 属性指定对应 mapper 接口的全限定名,建立 XML 与接口的唯一关联;SQL 实现标签(如 <select> ):标签的 id 属性必须与接口中的方法名完全一致,resultType 属性指定方法返回数据对应的实体类全限定名,标签内部编写具体的 SQL 语句;
2.3. 增删查改操作
1. 查(Select)
使用 <select> 标签,id 属性与接口方法名一致,resultType 指定查询结果的封装实体类,基础查询 XML 代码:
java
@Test
void selectList() {
System.out.println(userInfoMapperXml.selectList());
}
@Test
void selectList2() {
System.out.println(userInfoMapperXml.selectList2());
}
@Test
void selectList3() {
System.out.println(userInfoMapperXml.selectList3());
}
XML
<select id="selectList" resultType="com.yang.test2_9_1.model.UserInfo">
select * from user_info
</select>
<select id="selectList2" resultType="com.yang.test2_9_1.model.UserInfo">
SELECT id, username, `password`, age, gender, phone, delete_flag AS deleteFlag,
create_time AS createTime, update_time AS updateTime FROM `user_info`
</select>
<select id="selectList3" resultMap="BaseMap1">
select * from user_info
</select>
<resultMap id="BaseMap1" type="com.yang.test2_9_1.model.UserInfo">
<id column="id" property="id"></id>
<result column="delete_flag" property="deleteFlag"></result>
<result column="create_time" property="createTime"></result>
<result column="update_time" property="updateTime"></result>
</resultMap>对于上面的 3 个查询我们都使用到了同一条 SQL 语句,我们可以借助下面的语法来实现复用
SQL 片段。
java
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.yang.test2_9_1.mapper.UserInfoMapperXml">
<sql id="sql">
select * from user_info
</sql>
<select id="selectList" resultType="com.yang.test2_9_1.model.UserInfo">
-- select * from user_info
<include refid="sql"></include>
</select>
<select id="selectList2" resultType="com.yang.test2_9_1.model.UserInfo">
/*SELECT id, username, `password`, age, gender, phone, delete_flag AS deleteFlag,
create_time AS createTime, update_time AS updateTime FROM `user_info`*/
<include refid="sql"></include>
</select>
<select id="selectList3" resultMap="BaseMap1">
-- select * from user_info
<include refid="sql"></include>
</select>
<resultMap id="BaseMap1" type="com.yang.test2_9_1.model.UserInfo">
<id column="id" property="id"></id>
<result column="delete_flag" property="deleteFlag"></result>
<result column="create_time" property="createTime"></result>
<result column="update_time" property="updateTime"></result>
</resultMap>
</mapper>2. 增(Insert)
在 UserInfoMapperXml 接口中定义新增方法,接收用户实体类对象作为参数,返回受影响行数。
java
Integer insertUser1(UserInfo userInfo);
XML
<insert id="insertUser1">
insert into user_info (username, `password`, age) VALUE(#{username}, #{password}, #{age} )
</insert>若需给参数设置别名,接口定义为:
java
Integer insertUser(@Param("userInfo") UserInfo userInfo);若需要返回新插入数据的自增 id,无需修改接口,仅在 <insert> 标签中添加两个属性即可,自增 id 会自动赋值到实体类的对应属性中:
XML
<insert id="insertUser2" useGeneratedKeys="true" keyProperty="id">
insert into user_info (username, `password`, age)
VALUE(#{userInfo.username}, #{userInfo.password}, #{userInfo.age} )
</insert>useGeneratedKeys=true:启用 MyBatis 获取数据库自动生成的主键功能;keyProperty="id":指定将自增主键赋值到实体类的 id 属性。
3. 删(Delete)
定义删除方法,接收 id 作为参数,返回受影响行数:
java
Integer deleteUserById(Integer id);使用 <delete> 标签,id 属性与接口方法名一致,直接通过 #{id} 获取传入的主键参数:
XML
<delete id="deleteUserBuId">
delete from user_info where id = #{id}
</delete>4. 改(Update)
定义修改方法,接收用户实体类对象作为参数,返回受影响行数:
java
Integer updateUser(UserInfo userInfo);使用 <update> 标签,id 属性与接口方法名一致,通过 #{属性名} 获取实体类中的更新字段和条件字段:
XML
<update id="updateUser">
update user_info set gender = #{gender}, delete_flag = #{deleteFlag} where id = #{id}
</update>三、其他查询操作
3.1. 多表查询
- 数据准备
sql
-- 创建文章表
DROP TABLE IF EXISTS articleinfo;
CREATE TABLE articleinfo (
id INT PRIMARY KEY auto_increment,
title VARCHAR ( 100 ) NOT NULL,
content TEXT NOT NULL,
uid INT NOT NULL,
delete_flag TINYINT ( 4 ) DEFAULT 0 COMMENT '0-正常, 1-删除',
create_time DATETIME DEFAULT now(),
update_time DATETIME DEFAULT now()
) DEFAULT charset 'utf8mb4';
-- 插入测试数据
INSERT INTO articleinfo ( title, content, uid ) VALUES ( 'Java', 'Java正文', 1 );
java
package com.yang.test2_10_1.model;
import lombok.Data;
import java.util.Date;
@Data
public class ArticleInfo {
private Integer id;
private String title;
private String content;
private Integer uid;
private Integer deleteFlag;
private Date createTime;
private Date updateTime;
private String username;
private Integer age;
}- 查询工作
sql
SELECT ta.*, tb.username, tb.age
FROM articleinfo ta
LEFT JOIN user_info tb
ON ta.uid = tb.id WHERE ta.id;
java
package com.yang.test2_10_1.mapper;
import com.yang.test2_10_1.model.ArticleInfo;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Select;
@Mapper
public interface ArticleInfoMapper {
@Select("select ta.*, tb.username, tb.age from articleinfo ta " +
"left join user_info tb on ta.uid = tb.id " +
"where ta.id= #{id}")
ArticleInfo queryArticleInfo(Integer id);
}
java
package com.yang.test2_10_1.mapper;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import static org.junit.jupiter.api.Assertions.*;
@SpringBootTest
class ArticleInfoMapperTest {
@Autowired
private ArticleInfoMapper articleInfoMapper;
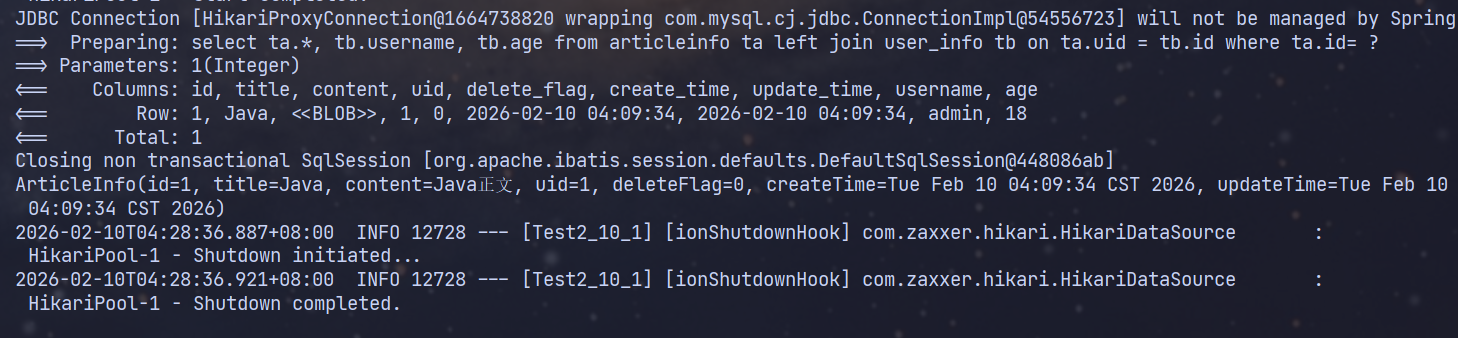
@Test
void queryArticleInfo() {
System.out.println(articleInfoMapper.queryArticleInfo(1));
}
}
在实际工作中,多表查询(尤其是多表关联查询)的使用场景被严格限制。首先,多表查询会带来显著的性能与资源开销。复杂的多表关联(如 JOIN 操作)会大幅提升数据库的 CPU、内存和磁盘 IO 负载,容易生成执行效率低下的慢 SQL,不仅拖慢单条查询的响应时间,还会挤占数据库集群的整体资源,影响其他业务的正常运行。同时,多表查询的执行时间通常更长,会持续占用数据库连接资源,像图中 MySQL 集群提供的 1000 个链接是多个项目共享的,若大量多表查询长时间占用连接,会导致连接池耗尽,新的业务请求无法及时处理,严重降低系统的并发能力。
其次,多表查询不利于系统的可维护性与扩展性。多表关联的 SQL 语句往往逻辑复杂、可读性差,当业务迭代需要调整表结构或关联逻辑时,修改成本高且容易引入 bug;在分库分表等架构演进场景中,跨库、跨表的多表查询兼容性问题会更加突出,限制了系统的扩展能力。此外,数据库字段的修改代价极大,DBA 在慢 SQL 治理中会严格约束多表查询的使用,避免因复杂查询导致数据库性能瓶颈,保障核心业务的稳定性。
最后,多表查询的适用场景本身就很有限。它更适合离线大数据分析、对性能要求不高的 B 端场景,而在线业务(尤其是 C 端)对响应时间和并发能力要求极高,因此开发中通常会优先采用 "单表查询 + 应用层关联" 的方式,将计算压力转移到应用服务,既提升了查询性能,又降低了数据库的负载,保障了系统的高效稳定运行。
3.2. #{} 和 ${}
1. 使用方式与底层实现差异
- #{} :采用预编译 SQL 实现,会将 SQL 中的 #{} 替换为?占位符,先对 SQL 进行编译并缓存,后续仅将参数填充到占位符中;会根据参数类型自动拼接引号(字符串类型加单引号,数值类型不加),无需手动处理。
- ${} :采用即时 SQL 实现,会直接将参数进行字符替换 ,与 SQL 语句拼接后一起编译执行;不会自动添加引号,字符串类型参数需要手动在 SQL 中加单引号,数值类型加引号可能导致数据库索引失效、性能下降。
java
@Select("SELECT * FROM `user_info` where id = #{id}")
UserInfo selectById(Integer id);
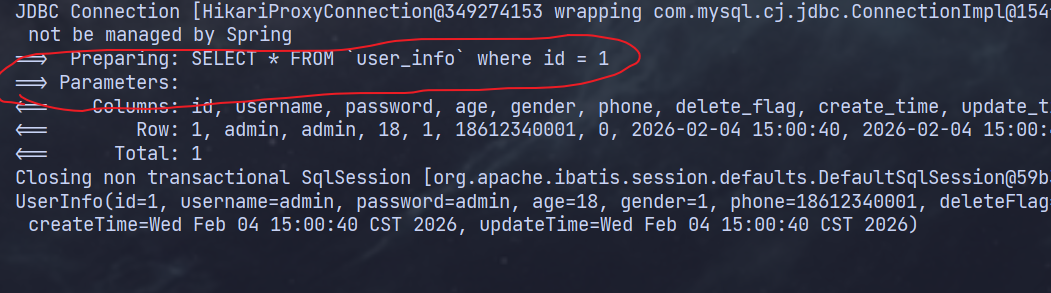
@Select("SELECT * FROM `user_info` where id = ${id}")
UserInfo selectById2(Integer id);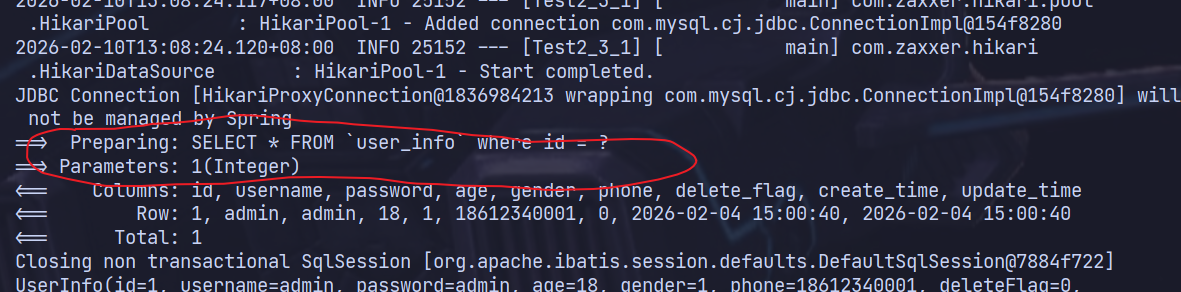
2. 核心区别
二者的本质区别是预编译 SQL 和即时 SQL 的区别,直接导致性能和安全性上的显著差异:
- 性能层面:#{} 预编译后会缓存编译结果,相同 SQL 多次执行时无需重复解析、优化、编译,效率更高;${} 每次执行都会重新编译拼接后的 SQL,性能较低。
- 安全层面 :#{} 能有效防止 SQL 注入,是推荐的使用方式;${} 存在严重的 SQL 注入风险,恶意参数会被直接拼接到 SQL 中改变执行逻辑。
3. ${} 的不可替代使用场景
#{} 虽安全高效,但因会自动加引号,在部分 SQL 语法中会导致语法错误,此时需使用 ${},核心场景包括:
- 动态排序 :排序规则(
asc/desc)动态传入时,SQL 中order by 字段 ${sort},若用 #{} 会拼接为order by 字段 'asc',加引号后违反 SQL 语法,导致执行报错。 - 动态表名 / 字段名 :当表名、查询字段名需要动态传入时,只能使用{},如`select {column} from ${tableName}`,#{} 的自动加引号会导致表名 / 字段名被识别为字符串,触发语法错误。
4. 使用原则
- 优先使用 #{}:绝大多数业务场景(如增删改查的普通参数传递)均使用 #{},兼顾性能与安全。
- 谨慎使用 ${} :仅在动态排序、动态表名 / 字段名 等 #{} 无法满足的场景使用,且使用时必须对传入的参数做严格的校验(如限制排序参数仅能为
asc/desc,表名仅能为指定白名单),避免 SQL 注入。