春哥的Agent通关秘籍09:从【句向量】到RAG
本章。我们将梳理RAG的结构设计,以及梳理出如何一步步构建一个RAG系统。
一、组装现有的武器
根据前面的学习,我们知道了【句向量】分别可以产生两种效果。
- 向量化:通过固定的评估规则,把一段文本迅速通过上下文生成一个【句向量】
- 检索:快速通过一个已知的【句向量】,找到临近位置的【句向量】,从而找到这些句向量对应的原文。(这样,就能找到意义相近的原文)
所以,我们可以这样规划我们的RAG架构:
训练过程:
- 把企业文档训练成一个巨大的向量空间,存储到一个【向量数据库】内。
提问过程:
- 【句向量】大模型,负责把用户的问题转换为一个【句向量】。
- 通过【向量数据库】,快速检索到附近的若干个意义相近的文本。
- 组装文本+问题,向【词向量】大模型提问。
- 返回答案。
二、R -> A -> G
想象一下,DeepSeek(或者 GPT)是一个超级学霸。 但他有两个致命的死穴:
-
知识冻结:他虽然博学,但他的记忆停留在他毕业(训练结束)的那一天。你问他"今天晚饭吃什么?",他不知道。
-
不懂隐私:他从来没去过你们公司,没看过你们的《员工手册》或《财务报表》。你问他"怎么报销?",他只能瞎编。
但是,现在我们通过【句向量】(Sentence Embedding)的模型,有了通过语义快速找到私有资料的能力,想象空间是不是瞬间不一样了?
假设,用户对着一个Agent问了一句话:
"我们公司的报销流程是怎么样的?"
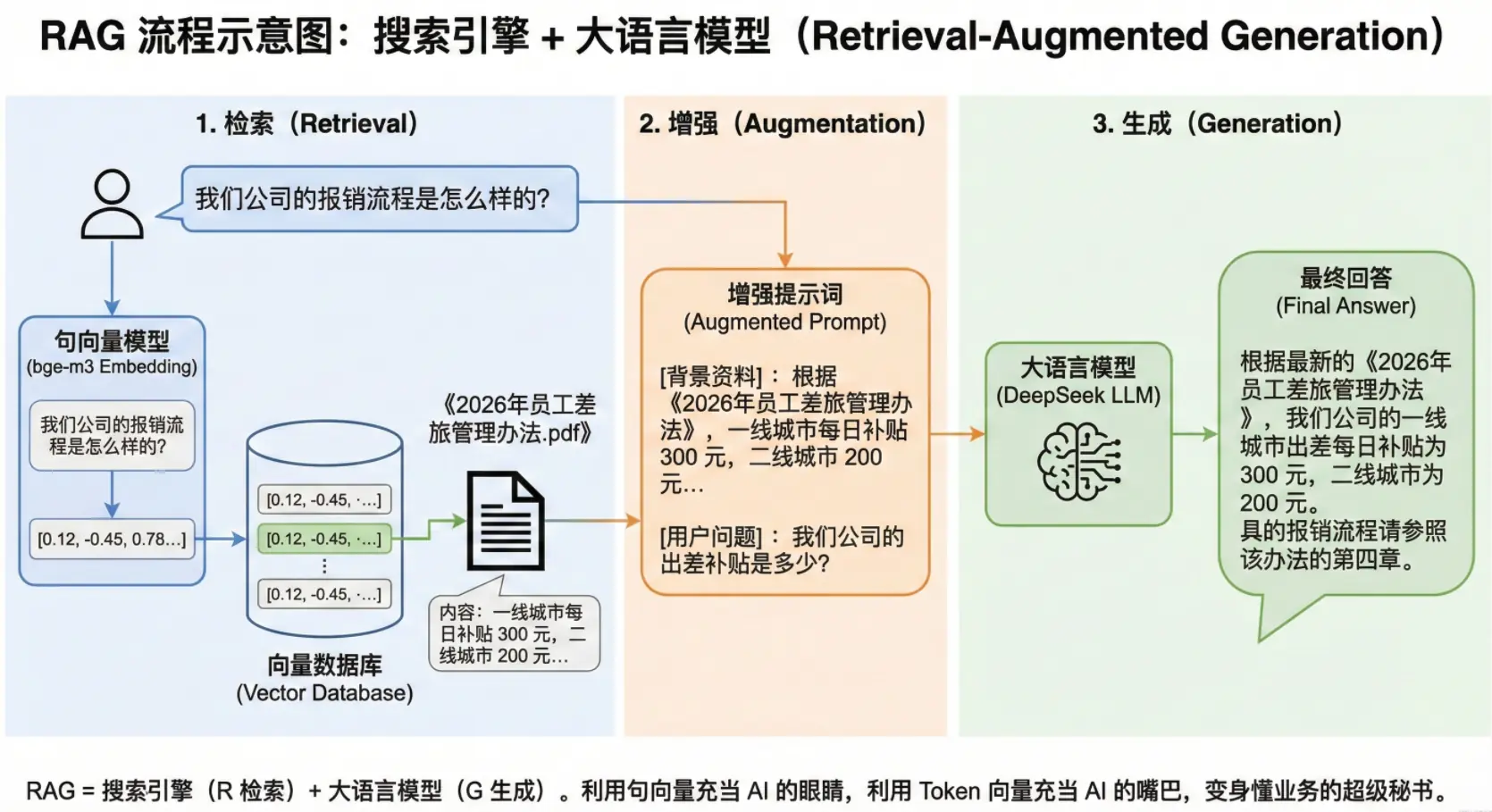
让我们拆解整个流程,把它分成三个部分:
-
检索:Retrieval。
- 系统把问题扔给 bge-m3(Embedding 模型)。
bge-m3把它变成一个【句向量】。- 系统拿着这个向量,去你的向量数据库里"扫一扫"。
- 结果:瞬间找到了距离最近的文档------《2026年员工差旅管理办法.pdf》。
-
增强:Augmented
- 系统悄悄地把原本的问题修改了。 它把找到的文档内容(比如"每日补贴 300 元"),粘贴到了用户的问题前面。
- 实际用户的问题变成了:"背景资料:根据《2026年员工差旅管理办法》,一线城市每日补贴 300 元,二线城市 200 元... 用户问题:我们公司的出差补贴是多少?"
- 这一步叫"增强":因为我们给 AI 提供了它原本不知道的信息。
-
生成:Generation
- DeepSeek 拿到了你附加的【作弊信息】和用户的提问。
- DeepSeek基于充分的上下文线索,然后用它那流畅的语言能力,把答案组织出来。
- DeepSeek给了你准确的答案。
所以,RAG 到底是什么?
RAG = 搜索引擎 + 大语言模型
-
R (检索):利用 句向量,充当 AI 的眼睛,帮它看到外部的最新、最私密的知识。
-
G (生成):利用 Token 向量,充当 AI 的嘴巴,帮它把看到的信息,优雅地讲给你听。
没有 RAG,AI 只是一个记性很好的空想家。 有了 RAG,AI 就变成了一个懂你公司业务的超级秘书。
三、梳理RAG的架构
接下来,让我向你介绍一下目前市面上主流的RAG的架构
我们可以把 RAG 分为两个大的阶段,分别是:
- 准备阶段 (离线)
- 运行阶段 (在线)
🟢 准备阶段:把文档变成【句向量】
-
用户准备私有文档 (Data Source)
- 格式五花八门:PDF, Word, Markdown, Excel 等。
-
数据清洗与切片 (Cleaning & Chunking)
-
这是最关键的一步!
-
为什么要切? Embedding 模型(句向量)有长度限制(比如 512 个字)。你不能把一本 500 页的书直接变成一个向量,那样信息全丢了。
-
做什么? 你需要一个切片器,把《员工手册》切成几百个小段落(Chunk)。每一段作为一个独立的单位。
-
-
句向量模型 (Embedding Model)
- 动作:把上面切好的几百个小段落,一个个变成稠密向量。
-
向量数据库 (Vector DB)
- 动作:把这些向量存起来,并建立索引(HNSW 等),方便快速查找。
🔵 运行阶段:开始回答用户问题 5. Agent/调度 用户提问与编排
diff
- 用户问:"怎么报销?"
- 调度器首先把这个问题也扔给 【句向量】模型,变成一个【句向量】坐标。- 向量检索 (Vector Search)
diff
- 去向量数据库里,找出与问题向量距离最近的 Top 50 个片段。
- 注意:这一步叫"粗排",速度快,但不够准。- 重排序 (Rerank)
diff
- 这是提升效果的秘密武器!
- 向量检索是基于模糊的几何距离,有时候会找回来一些"似是而非"的东西。
- Rerank 模型:这是一个专门的模型(Cross-Encoder)。它会把这 Top 50 个片段,和用户的问题放在一起,精读一遍,然后打分。
- 它会告诉你:"第 1 个片段相关性 99%,第 40 个片段其实只有 10%。"
- 然后我们只取 Top 3 给大模型。- 提示词组装 (Prompt Engineering)
swift
- 你不能只给大模型 3 个片段。你需要把它们包装成话术:
- "你是一个助手。请根据以下参考资料回答用户问题。如果资料里没有,就说不知道。\n\n 参考资料:[片段1]...[片段2]...\n\n 用户问题:怎么报销?"- 【词向量大】模型 (如 DeepSeek)
diff
- 大模型阅读上面的 Prompt,最后生成答案。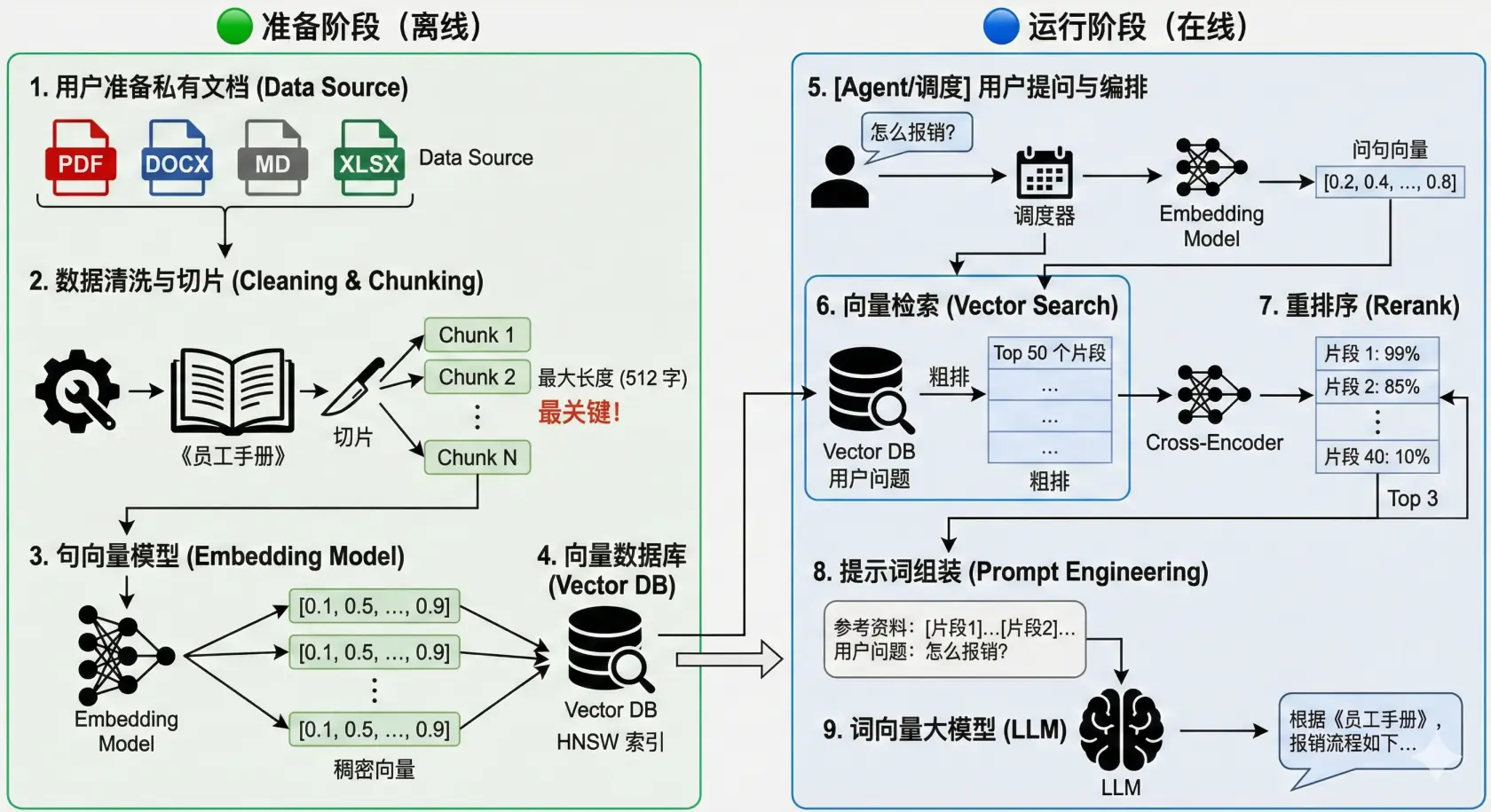
四,Rerank 模型是啥?能先不整吗?
能的,兄弟,能的!
上第七步【重排序 (Rerank)】在学习阶段,以及在文档规模不大的阶段,可以先不做。
等到文档规模达到一定规模后,再增加这个调优阶段即可。
这里简单解释一下,Rerank 是除【词向量】和【句向量】以外,第三种最为主流常见的纯语言大模型。
它存储的不是向量,而是一个评分,它最擅长的领域就是判断一段文本和另一段文本之间是否存在较强因果关系。
这里我们先绕开它,否则一次性接触的工具概念太多容易弄混。
五,重要限制
当你训练自己的【句向量】数据时是,使用了一个A版本的【句向量】B模型,如bge-m3模型。
那么,当你拿问题换【句向量】坐标时,也必须用版本完全一样的A版本的B模型来换取【句向量】坐标。
这一点是必须遵守的。
下一步预告
下节课,我们将开始正式制作一个 RAG "检索增强生成"系统。
敬请期待!
