翻译:TUARAN
欢迎关注 {{前端周刊}},每周更新国外论坛的前端热门文章,紧跟时事,掌握前端技术动态。
1 月 27 日,我收到了邮件通知:JS Bin 挂了。第二天,真实的人类用户开始问「怎么回事」。一直到 30 日晚上 11 点左右,最后一批问题才被解决。
前些天 Jake 问我:到底哪里出了问题?
答案是:几乎所有环节都出了问题。
TL;DR
我知道这篇文章又长又碎。我写嗨了,也很享受把这段经历讲清楚。
简短版是:
- 早点把基础设施升级到最新(但我当时做不到)。
- 520 并不等于「服务器没响应」,它很可能是 Cloudflare 与源站之间的 TLS 协商/响应不兼容。
- 服务器在着火时,别过度依赖 LLM:它能帮你补知识,但也可能把你带进更复杂的岔路。尽量先退一步,盘点现状,再做改变。
如果你愿意读长版,那就开始。
处于"维护模式"的这些年
过去大概 5 年(也可能更久),JS Bin 基本处于一种半自动「维护模式」:每隔 3~6 个月会有一阵小故障需要我出手。JS Bin 快 18 岁了,以 Web 的标准来说已经是「高龄应用」。
通常我需要处理的是站内的不良内容、来自 AWS(JS Bin 托管在那儿)的下架请求,或者偶发的内存异常------有的恢复要花更久。
看过去 11 年的可用性曲线,宕机并不罕见,但这次完全不同(左边那次大故障先不算)。
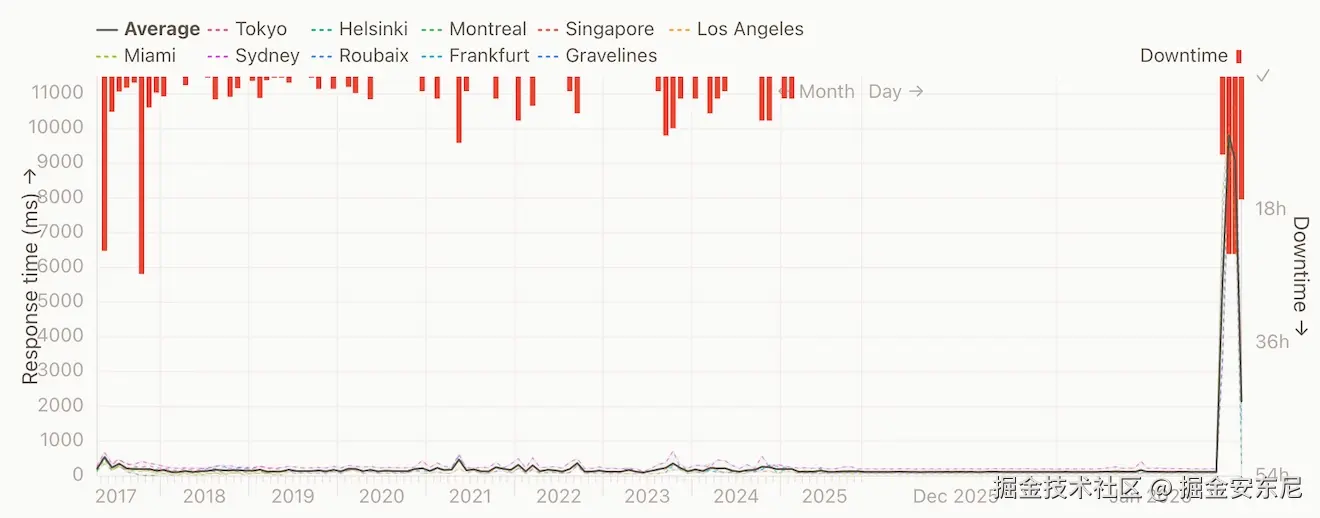
很多「长时间」宕机(我最近才更清楚)是因为机器内存耗尽,系统会像"塌方"一样:我甚至无法 SSH 登录去恢复,只能在 AWS 控制台里强制重启。
而这次更离谱:连「控制台重启」这种真正的「关机重开」都不灵。
重启也起不来
这次宕机,无论怎么重启都回不来。我触发重启后,一直在控制台等 SSH,但完全连不上。
机器的行为像是:重启 → 立刻锁死。
这暗示着:机器外面有持续的巨大压力,而且没有减弱。
我手上唯一的办法,是把机器彻底关机一小时左右,希望"敲门的东西"能先走开。
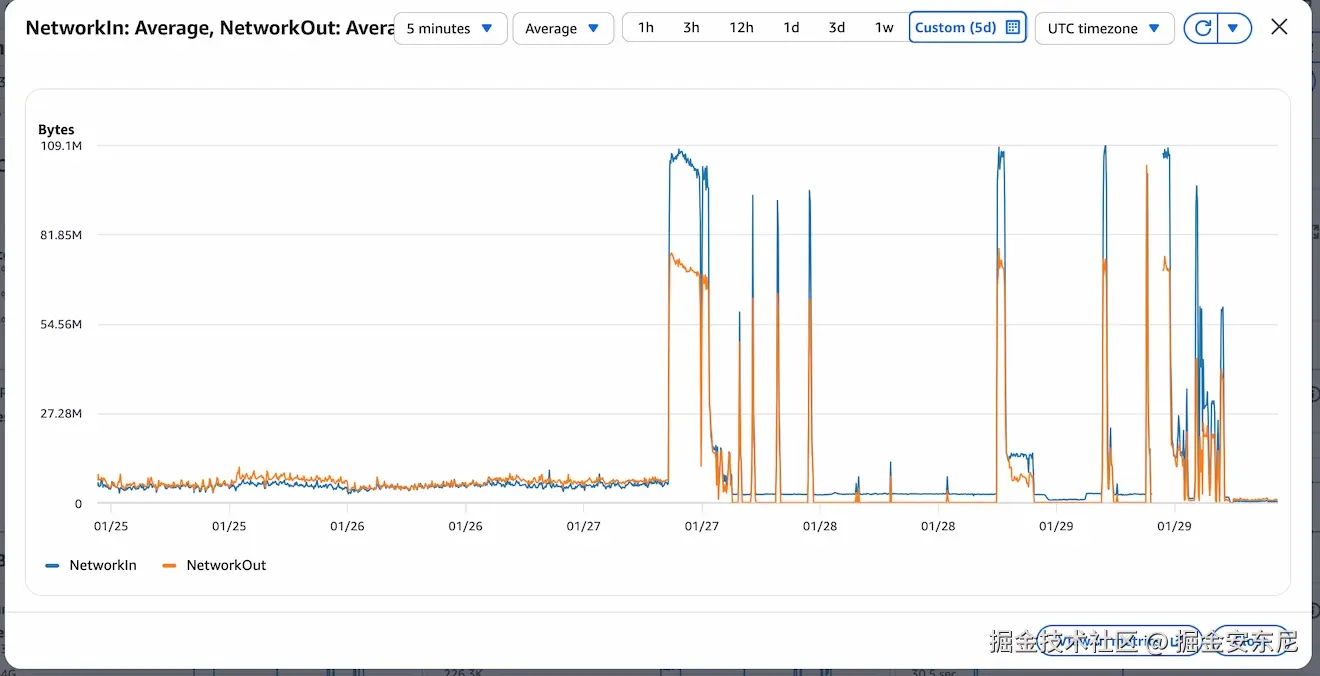
后来我看 CloudWatch,才知道入站流量把机器摁在地上摩擦:几天前还是正常水平,突然变成前所未有的网络入站峰值。图里 cliff edge 之后的那些下跌,是机器扛不住而失去响应。
先把"该死的进程"杀掉
我终于进到机器后,第一件事是看 syslog,找出导致崩溃的东西(更准确说:找出症状)。
很快我看到了 Node 因为 OOM(内存耗尽)而产生的 GC dump 与堆栈。
第一优先级:不要让系统"全盘崩溃",先让最耗内存的进程被杀掉,至少保证我还能登录继续排查。
我加了这条配置:
conf
# /etc/sysctl.conf,然后用 `sudo sysctl -p` 重新加载
vm.oom_kill_allocating_task=1这样内存被打爆时,系统会优先杀掉正在疯狂分配内存的进程(Node),而不是随便杀掉别的关键进程(导致 SSH 也没了)。
这不会让机器"很快",但能让我在流量继续轰炸时至少还能诊断(当然终端会非常慢)。
我能看到 CPU 长时间接近 100%,Node 的内存占用持续上涨(我用 htop)。
然后,ChatGPT 建议我升级 Node------奇怪的是,我并没有告诉它我在用什么版本。
支线任务:Node 真的很老
因为长期"维护模式",我几乎从没动过 Node。结果 JS Bin 居然跑在 Node 7 上(甚至不是"稳定"的 Node 8),可能已经超过十年。
我问 ChatGPT 为什么知道,它说「你告诉过我」。这完全是胡扯。
我追问了很久才发现:当时我的终端屏幕上显示了 Node 版本;在我之后调 nginx 的过程中,ChatGPT 直接"看"到了屏幕内容。
我不知道它是否能读取滚动历史(希望不能),但这依然很不舒服。
我平常用的是浏览器版 ChatGPT,不怎么用"应用"形态;这次给我一个教训:只要屏幕上出现过敏感信息(比如我刚 cat 过 .env),就要假设 LLM 可能看得到。
总之,我把 Node 从 7 升到了 22,居然没出事。幸运的是我在 2024 年做过一轮现代化改造,好让我能在本机跑起来(现代系统当然不愿意跑 Node 7)。
至少,事件循环性能变好了,CPU 压力会小一点。
......但问题依然没解决。
服务器太小,但我当时不想"加钱"
JS Bin 的主服务跑在 AWS t2.micro 上:单核 CPU、1GB 内存。我一直很惊讶它能在这么少资源上撑这么久。
当然,换更大的机器(加钱)可能有用。但当时我没有一键构建新机器的脚本------这台服务器已经多年"稳定运行",我也没有随时可用的重建流程。
而且 JS Bin 虽然有 pro 版,但现金流并不充裕。简而言之:我需要"立刻能做"的事。
在 ChatGPT、Gemini 和 Claude 的帮助下(我用多个 LLM 来交叉验证建议,但说实话没有我希望的那么严谨),我尝试调优 nginx,比如:
- worker 配置
- proxy timeout
- 文件描述符上限
- keep-alive
- 甚至移除 http2 来省内存
例如:
nginx
worker_connections 1024;
worker_processes auto;
keepalive_timeout 10;
keepalive_requests 100;在每秒 1000+ 请求、还有更多请求在排队的情况下,这些改动几乎没有立竿见影的效果。
接着有人(也包括 LLM)提了一个问题:你考虑过 Cloudflare 吗?
把 Cloudflare 放到前面
说实话,把 Cloudflare 放到 JS Bin 前面出奇地顺利。它识别了大多数域名与指向,我只要把 DNS 的 nameserver 从 Route 53 换成 Cloudflare。
1 月 29 日接近午夜时,我开始能在浏览器里打开 jsbin.com 了。
但很快 GitHub 和邮件反馈告诉我:很多人依然在报错。
尤其是 Cloudflare 的 520------后来我才知道,它可能对应很多不同的问题。
请求仍然绕过 Cloudflare
即便能打开页面,我也能在服务器上看到有流量还在直冲源站。
我找到了 Cloudflare 的 IP 段列表,发现还有大量请求并不来自这些 IP 段。于是下一步是:丢弃非 Cloudflare 的流量。
这里开始,LLM 的建议让我引入了更多问题(直到第二天才彻底暴露)。当你忙到"救火模式",很容易在复杂度上失手。
我最先用的方案是:在 nginx 里判断 Cloudflare 的请求头,没带头就丢弃。
nginx
if ($http_cf_ray = "") {
return 444;
}444 会直接断开连接,不返回任何内容。
我还按「Captain GPT」的指引配置了 set_real_ip_from 等(这在之后会坑到我):
nginx
# /etc/nginx/cloudflare.conf
set_real_ip_from 173.245.48.0/20;
set_real_ip_from 103.21.244.0/22;
set_real_ip_from 103.22.200.0/22;
set_real_ip_from 103.31.4.0/22;
set_real_ip_from 141.101.64.0/18;
set_real_ip_from 108.162.192.0/18;
set_real_ip_from 190.93.240.0/20;
set_real_ip_from 188.114.96.0/20;
set_real_ip_from 197.234.240.0/22;
set_real_ip_from 198.41.128.0/17;
set_real_ip_from 162.158.0.0/15;
set_real_ip_from 104.16.0.0/13;
set_real_ip_from 104.24.0.0/14;
set_real_ip_from 172.64.0.0/13;
set_real_ip_from 131.0.72.0/22;
real_ip_header CF-Connecting-IP;
real_ip_recursive on;并在 http {} 里 include:
nginx
http {
include /etc/nginx/cloudflare.conf;
...
}这会让 $remote_addr 变成真实用户 IP,而不是 Cloudflare 的边缘节点 IP。
但问题是:即便这样做,流量仍然很大;而且这种"在 nginx 层处理再丢弃"的方式,依然会消耗资源。
把油继续往火里浇
我还用 ss 查看连接:
bash
ss -tan state established '( sport = :443 )'我依然能看到一些非 Cloudflare 的请求成功建立连接(当时我正处于「改配置 → 失败 → 焦虑 → 问 LLM → 重来」的循环中)。
于是我又换了一种策略:不用请求头,改用来源 IP 是否属于 Cloudflare 的 IP 段来判断。
nginx
geo $is_cloudflare {
default 0;
173.245.48.0/20 1;
103.21.244.0/22 1;
# etc
}然后在 server block 里:
nginx
server {
listen 443 ssl http2 default_server;
if ($is_cloudflare = 0) { return 444; }
if ($cf_valid = 0) { return 444; }
# rest of config unchanged
}我当时没意识到的一点(花了 24 小时才想明白):
- 之前那套配置会说「如果请求来自 Cloudflare,把
$remote_addr改成真实用户 IP」。 - 然后这套规则又说「如果
$remote_addr不是 Cloudflare IP,就丢弃」。
结果:真正的用户(经由 Cloudflare)反而被我丢掉了。
现场变成了最糟糕的两件事同时发生:
- 仍然有绕过 Cloudflare 的流量打进来,继续耗资源
- 真实用户经由 Cloudflare 访问时,大多数却拿到 520
我终于意识到:应该在更靠外的地方(防火墙/安全组)直接丢弃流量。
直接丢弃流量(ufw + AWS 安全组)
我做了"双保险":
- 在服务器上用
ufw(我一直把它当成 iptables)按 IP 段ALLOW/DROP - 在 AWS security group 同样只允许 Cloudflare IP 段访问 80/443
ufw 相对简单:
bash
ufw allow from 173.245.48.0/20 to any port 443
ufw allow from 103.21.244.0/22 to any port 443
# etc
ufw deny 44380 端口同理。
我在测试时还踩了个小坑:想临时放行自己 IP 时搞乱了规则;后来用 ufw status numbered + ufw delete N 解决。
AWS 安全组就麻烦多了:Web UI 不适合大批量改动,非常笨重。
我最后用 AWS CLI 写了脚本(但它不能批量修改,一条条执行还得等待返回再按回车,效率很低):
bash
for CIDR in \
103.21.244.0/22 \
103.22.200.0/22 \
103.31.4.0/22 \
# etc
do
aws ec2 authorize-security-group-ingress --group-id $SG_ID --protocol tcp --port 80 --cidr $CIDR --region us-east-1
aws ec2 authorize-security-group-ingress --group-id $SG_ID --protocol tcp --port 443 --cidr $CIDR --region us-east-1
done做到这一步,服务器终于开始"喘气"了。
但很多用户仍然被 Cloudflare 的 520 拦住(奇怪的是我自己还能访问......)。
520:不是 503/504,而是"不兼容"
我原本以为 520 类似 503(源站挂了)或 504(网关超时),但实际上更像是:
Cloudflare 发起请求,但源站的响应对 Cloudflare 来说"不兼容"。
我能确定一个线索:80 端口的纯 HTTP 没问题,只有 HTTPS 出问题。
有个很关键的观察来自 @robobuljan:
bash
curl jsbin.com # (正常)
curl http://jsbin.com # (正常)
curl https://jsbin.com # 520这一天里,LLM 基本帮不上忙(我也干脆把它们放一边,专心啃问题)。
我在 Cloudflare 的 SSL/TLS 页里看到「Traffic Served Over TLS」显示 TLS 版本分布(我没截图,这些数来自它们的 API):
- TLSv1:36
- TLSv1.1:56
- TLSv1.2:1,922,523
- TLSv1.3:5,216,795
我的 nginx 配置里反复出现这行:
nginx
ssl_protocols TLSv1 TLSv1.1 TLSv1.2;没有 TLSv1.3。
我先尝试在 nginx 加上 TLSv1.3,但 nginx -t 直接失败:当前环境缺模块,而且要做大升级才能装上。
那就换思路:能不能在 Cloudflare 侧禁用 TLS 1.3?
答案是能,但入口很隐蔽:
- 查看支持情况在「Speed / Settings」
- 真正关闭在「SSL/TLS → Edge Certificates」,页面靠后的位置
禁用 TLS 1.3 后,大量真实流量恢复正常。
仍然有部分用户加载失败(static/null 域名)
接着又出现一个问题:部分用户的静态资源加载不了,或者用于运行代码的 iframe 域名(null.jsbin.com)异常。
我花了几个小时才理清:我曾让 nginx 在「请求来自 Cloudflare 时」使用 set_real_ip_from 把 $remote_addr 改写为真实用户 IP,而后续又用 return 444 去丢弃"不符合条件"的请求。
不知为何,这套混乱的规则并没有影响主站首页,但却影响了 static.jsbin.com 与 null.jsbin.com。
这就是熬夜 + 危机模式的典型后果:配置变成一团糟,自己也说不清到底哪些规则在什么时候生效。
当我最终移除这些临时拼凑的检查、IP 改写与一堆由 LLM 引入的"杂质"后,最后那部分流量也恢复了。
JS Bin 全面恢复。
事后复盘
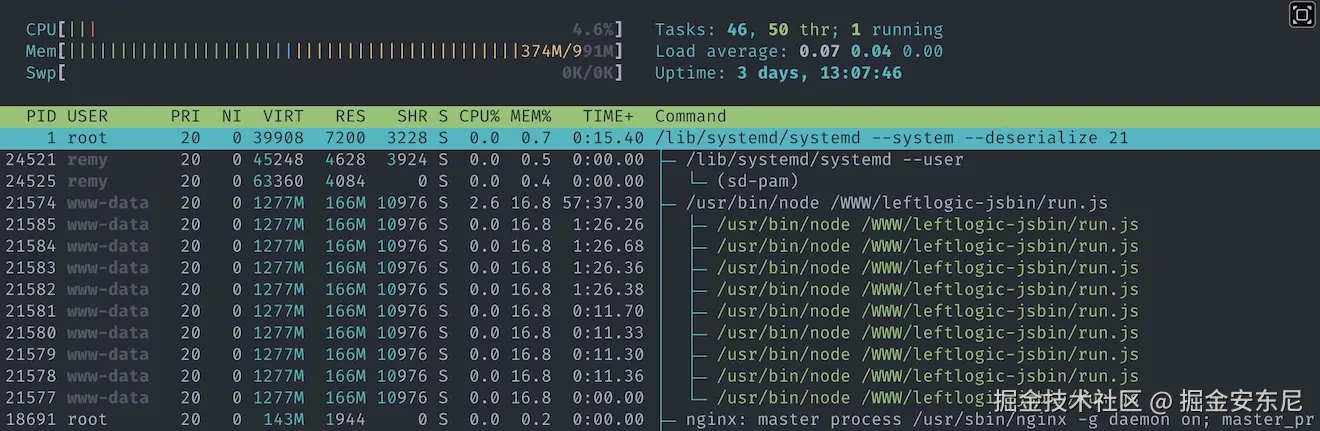
现在 Cloudflare 顶在源站前面,这台 1GB 单核的小机器居然非常从容:CPU 常态只有 4%~5%。
我怀疑如果当时没那么依赖 LLM,我可能会更早意识到自己在不断增加复杂度。但另一方面:我也早该把 Cloudflare 放到 JS Bin 前面------不该等到危机时刻才做。
这次我学到的"坑"主要是:
- TLS 版本不匹配会导致 520
- 520 的语义远比我以为的复杂
从 CloudWatch 看,流量确实回落了;我相信 Cloudflare 已经替我挡掉了很多垃圾流量。看起来其中一大块来自香港------我给那边开了 Cloudflare 的 JS Challenge 才能继续访问:
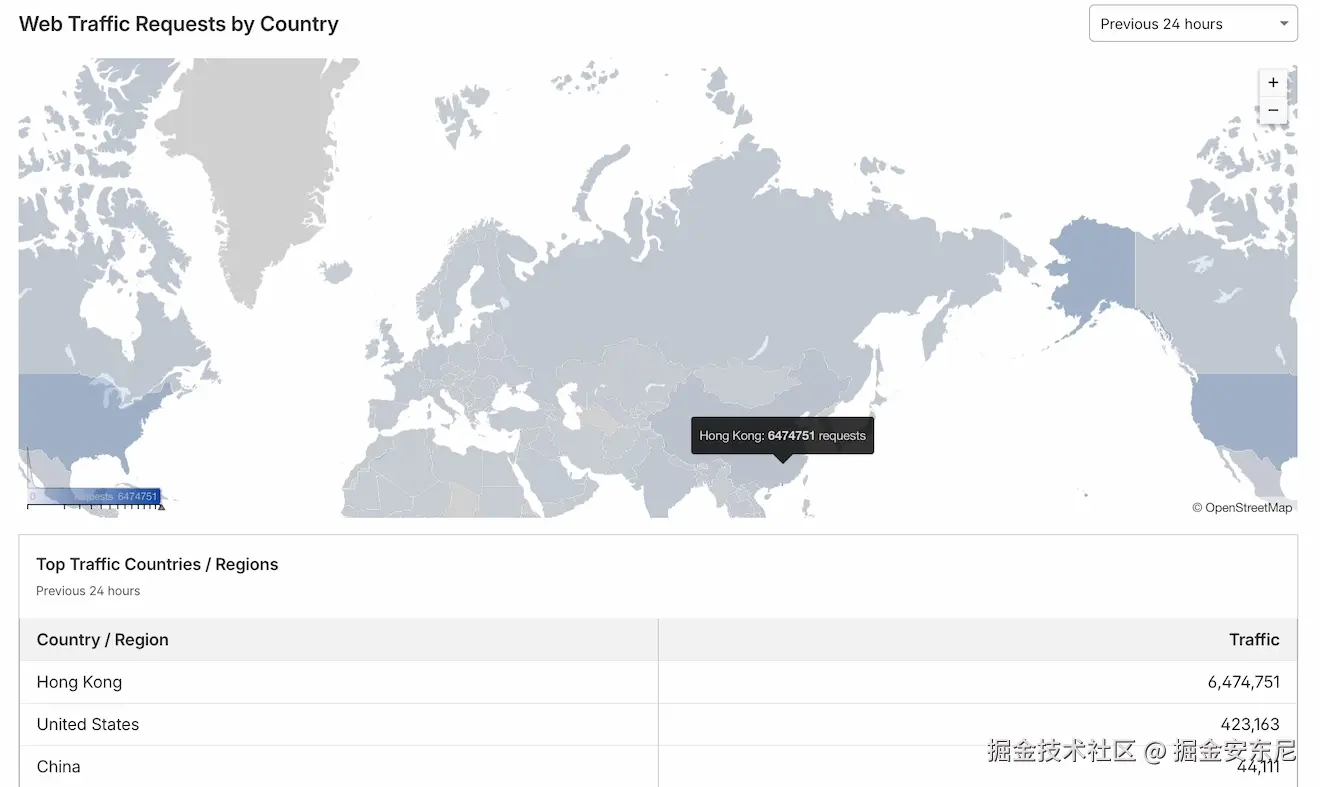
拍截图后 24 小时内香港有 1000 万请求。
至于到底是什么导致这波流量把一切打崩,我恐怕永远无法确定。我直觉怀疑是 AI/LLM 的爬虫在"吸"整个互联网;但反证是:流量并不来自单一 IP。
讽刺的是,我倒是在自己的博客上看到过一个单 IP 爬虫(见这个链接):几个小时内 3GB 数据、32.5 万次请求。好在博客是跑在 Netlify 的纯静态站上,不像 JS Bin 还在跑 Node 7(是的,真的是 Node 7)。