㊗️本期内容已收录至专栏《Python爬虫实战》,持续完善知识体系与项目实战,建议先订阅收藏,后续查阅更方便~
㊙️本期爬虫难度指数:⭐⭐⭐
🉐福利: 一次订阅后,专栏内的所有文章可永久免费看,持续更新中,保底1000+(篇)硬核实战内容。

全文目录:
-
-
- [🌟 开篇语](#🌟 开篇语)
- [1️⃣ 摘要(Abstract) 🏗️](#1️⃣ 摘要(Abstract) 🏗️)
- [2️⃣ 背景与需求(Why)📐](#2️⃣ 背景与需求(Why)📐)
- [3️⃣ 合规与注意事项(必写)🛡️](#3️⃣ 合规与注意事项(必写)🛡️)
- [4️⃣ 技术选型与整体流程(What/How)🧩](#4️⃣ 技术选型与整体流程(What/How)🧩)
- [5️⃣ 环境准备与依赖安装(可复现)📦](#5️⃣ 环境准备与依赖安装(可复现)📦)
- [6️⃣ 核心实现:版本化数据模型 (The Versioned Model) 🏷️](#6️⃣ 核心实现:版本化数据模型 (The Versioned Model) 🏷️)
- [7️⃣ 核心实现:动态 SQL 适配器 (The Adaptive Pipeline) 📡](#7️⃣ 核心实现:动态 SQL 适配器 (The Adaptive Pipeline) 📡)
- [8️⃣ 核心实现:演化场景模拟 (The Evolution Simulator) ⚙️](#8️⃣ 核心实现:演化场景模拟 (The Evolution Simulator) ⚙️)
- [9️⃣ 关键代码解析(Expert Deep Dive)🧐](#9️⃣ 关键代码解析(Expert Deep Dive)🧐)
- [🔟 常见问题与排错(Troubleshooting)🆘](#🔟 常见问题与排错(Troubleshooting)🆘)
- [1️⃣1️⃣ 进阶优化:自动 Schema 检测 🚀](#1️⃣1️⃣ 进阶优化:自动 Schema 检测 🚀)
- [1️⃣2️⃣ 总结与延伸阅读 📝](#1️⃣2️⃣ 总结与延伸阅读 📝)
- [🌟 文末](#🌟 文末)
-
- [✅ 专栏持续更新中|建议收藏 + 订阅](#✅ 专栏持续更新中|建议收藏 + 订阅)
- [✅ 互动征集](#✅ 互动征集)
- [✅ 免责声明](#✅ 免责声明)
-
🌟 开篇语
哈喽,各位小伙伴们你们好呀~我是【喵手】。
运营社区: C站 / 掘金 / 腾讯云 / 阿里云 / 华为云 / 51CTO
欢迎大家常来逛逛,一起学习,一起进步~🌟
我长期专注 Python 爬虫工程化实战 ,主理专栏 《Python爬虫实战》:从采集策略 到反爬对抗 ,从数据清洗 到分布式调度 ,持续输出可复用的方法论与可落地案例。内容主打一个"能跑、能用、能扩展 ",让数据价值真正做到------抓得到、洗得净、用得上。
📌 专栏食用指南(建议收藏)
- ✅ 入门基础:环境搭建 / 请求与解析 / 数据落库
- ✅ 进阶提升:登录鉴权 / 动态渲染 / 反爬对抗
- ✅ 工程实战:异步并发 / 分布式调度 / 监控与容错
- ✅ 项目落地:数据治理 / 可视化分析 / 场景化应用
📣 专栏推广时间 :如果你想系统学爬虫,而不是碎片化东拼西凑,欢迎订阅专栏👉《Python爬虫实战》👈,一次订阅后,专栏内的所有文章可永久免费阅读,持续更新中。
💕订阅后更新会优先推送,按目录学习更高效💯~
1️⃣ 摘要(Abstract) 🏗️
本文将引入 Schema 版本控制 思想,通过在 Pydantic 模型中嵌入版本号,并结合数据库的 动态列映射(Dynamic Mapping),实现爬虫在字段增删改时的"零宕机"迁移。
读完你将获得:
- 掌握如何利用版本号(Version Tagging)隔离不同时期的抓取逻辑。
- 学会编写"宽容型"Pipeline,自动处理数据库缺损字段。
- 理解数据湖(Data Lake)思维在爬虫存储中的应用,实现"先存后算"的灵活性。
2️⃣ 背景与需求(Why)📐
为什么要搞字段演化处理?
- 硬编码风险: 如果你的代码里写死了
insert into table (col1, col2),一旦网页新增了col3,你的爬虫就会因为参数不匹配而报错。 - 历史回溯难: 去年抓的数据没有"评价数",今年有了。如何在同一张表里区分并处理这两批数据?
- Pipeline 脆弱性: 一个字段的解析失败不应导致整条流水线的毁灭。
核心逻辑:
- 数据打标: 给每一条 Item 加上
schema_version。 - 模型兼容: 使用可选字段(Optional Fields)和默认值处理缺失。
- 动态入库: 数据库逻辑不再依赖固定 SQL,而是根据字典键名动态生成。
3️⃣ 合规与注意事项(必写)🛡️
- 数据一致性: 虽然字段可以演化,但核心主键(如
item_id)必须保持稳定,否则会导致数据重叠。 - 版本记录: 每次 Schema 变更(如从 v1 升级到 v2)都应在文档或代码注释中记录变更原因和时间。
- 存储选择: 对于字段变动极其频繁的站点,建议优先选择 NoSQL(如 MongoDB),如果使用 SQL,则需预留
ext_data(JSON) 字段作为缓冲。
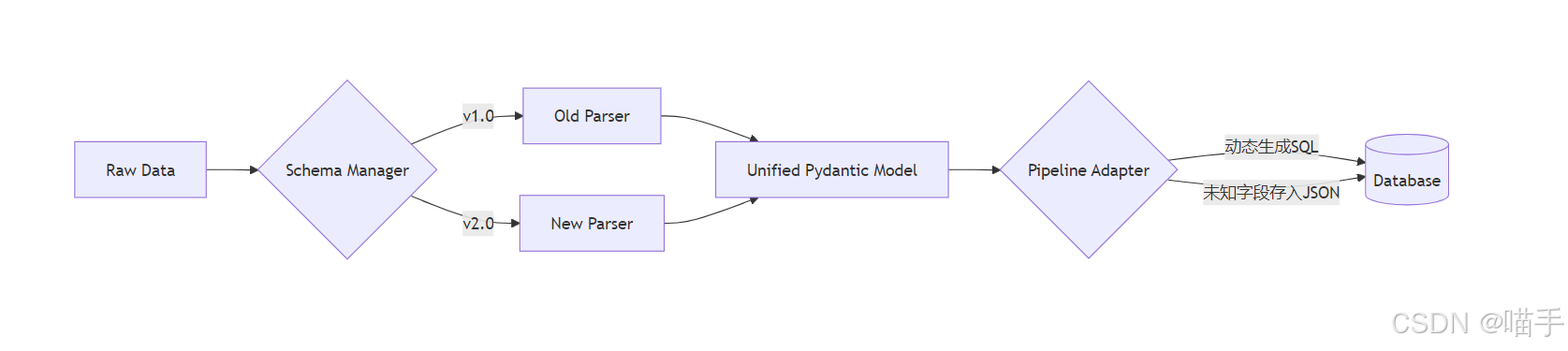
4️⃣ 技术选型与整体流程(What/How)🧩
技术栈:
- 模型校验:
Pydantic(利用其extra='allow'特性处理未知字段)。 - 存储引擎:
SQLite+JSONB模拟思想(或动态 SQL 生成)。 - 控制中心:
SchemaManager(负责版本分发)。
**字段演化流程图:中心: SchemaManager(负责版本分发)。
字段演化流程图:
5️⃣ 环境准备与依赖安装(可复现)📦
bash
pip install pydantic6️⃣ 核心实现:版本化数据模型 (The Versioned Model) 🏷️
我们定义一个基类,所有抓取的 Item 必须携带版本信息。
python
from pydantic import BaseModel, Field, Extra
from typing import Optional, Dict, Any
from datetime import datetime
class BaseBookItem(BaseModel):
# 元数据
item_id: str
schema_version: str = "1.0"
crawled_at: datetime = Field(default_factory=datetime.now)
# 核心字段 (v1.0)
title: str
price: float
# 扩展字段 (v2.0 新增,设为可选以兼容 v1.0 数据)
rating: Optional[int] = 0
stock_status: Optional[str] = "Unknown"
# 关键设置:允许额外字段进入,不直接抛错炸掉
class Config:
extra = Extra.allow 7️⃣ 核心实现:动态 SQL 适配器 (The Adaptive Pipeline) 📡
传统的 INSERT 语句是死板的。我们要写一个能根据字典 key 自动调整的入库逻辑。
python
import sqlite3
class AdaptivePipeline:
def __init__(self, db_path="flexible_books.db"):
self.conn = sqlite3.connect(db_path)
self.cursor = self.conn.cursor()
self._ensure_base_table()
def _ensure_base_table(self):
"""确保基础表存在,并预留一个 json 格式的 extra 列"""
self.cursor.execute('''
CREATE TABLE IF NOT EXISTS books (
item_id TEXT PRIMARY KEY,
schema_version TEXT,
title TEXT,
price REAL,
extra_data TEXT -- 存储未来可能新增的所有字段
)
''')
self.conn.commit()
def process_item(self, item_dict: Dict[str, Any]):
"""
核心逻辑:提取已知列,剩下的全塞进 extra_data
"""
# 1. 定义数据库已有的物理列
physical_columns = ['item_id', 'schema_version', 'title', 'price']
# 2. 提取物理列数据
main_data = {k: v for k, v in item_dict.items() if k in physical_columns}
# 3. 提取剩下的"演化字段"
extra_data = {k: v for k, v in item_dict.items() if k not in physical_columns}
import json
main_data['extra_data'] = json.dumps(extra_data)
# 4. 动态构建 SQL
keys = main_data.keys()
columns = ", ".join(keys)
placeholders = ", ".join(["?"] * len(keys))
sql = f"INSERT OR REPLACE INTO books ({columns}) VALUES ({placeholders})"
try:
self.cursor.execute(sql, list(main_data.values()))
self.conn.commit()
print(f"✅ [Version {item_dict['schema_version']}] 数据已平滑入库: {item_dict['item_id']}")
except Exception as e:
print(f"💥 入库失败: {e}")8️⃣ 核心实现:演化场景模拟 (The Evolution Simulator) ⚙️
python
def simulate_crawl():
pipeline = AdaptivePipeline()
# 场景 A: 抓取旧版网页 (v1.0)
old_data = {
"item_id": "B001",
"schema_version": "1.0",
"title": "Old Python Book",
"price": 29.9
}
pipeline.process_item(old_data)
# 场景 B: 网页改版,多了"评分"和"库存",进入 v2.0
new_data = {
"item_id": "B002",
"schema_version": "2.0",
"title": "New Python AI",
"price": 59.9,
"rating": 5, # 新增
"stock_status": "In Stock", # 新增
"author": "Guido" # 甚至出现了我们没预料到的字段
}
pipeline.process_item(new_data)
if __name__ == "__main__":
simulate_crawl()9️⃣ 关键代码解析(Expert Deep Dive)🧐
-
xtra.allow的妙用:在 Pydantic 中,默认碰到未定义的字段会抛出
ValidationError。通过允许额外字段,我们的爬虫即使在解析层多抓了东西,也不会在校验层"炸裂"。 -
"宽表"与"高高频变动表"的平衡: 我们使用了 "固定列 + JSON 扩展列" 的混合模式。。
- 固定列(如 ID, Title):用于高频索引和基础分析。
- JSON 列 (extra_data):负责容纳所有"演化"出来的字段。这保证了数据库 Schema 不需要频繁执行
ALTER TABLE,那在生产环境下是非常危险的操作。
-
hema Versioning 的价值:
在查询时,你可以根据
WHERE schema_version = '2.0'快速筛选出具备新特性的数据,而不会被旧数据的 Null 值干扰。
🔟 常见问题与排错(Troubleshooting)🆘
- 数据分析时 JSON 字段难用?
- 对策: 如果某个演化字段(如
rating)已经稳定存在了很久,且需要高频查询,此时应发起一次数据库迁移 ,将其从extra_data提取出来变成真正的物理列。
- 旧版本代码解析新网页报错?
- 对策: 这是一个经典问题。建议在爬虫入口处检查网页特征。如果发现新标签,立即在日志中触发
CRITICAL预警,提醒工程师更新代码至新版本。
- 字段类型冲突?
- 现象: v1.0 里
price是字符串,v2.0 变成了数字。 - 对策: 在 Pydantic 的
validator中写好强制转换逻辑,无论什么版本进来,出厂时必须是统一类型。
1️⃣1️⃣ 进阶优化:自动 Schema 检测 🚀
- 数据漂控 (Drift Detection): 编写一个脚本,每天统计
extra_data中出现频率最高的 key。如果某个未定义 key 出现频率超过 90%,说明网站已经完成了永久性改版。 - 多版本共存: 在大型项目中,可能存在某些节点在跑旧代码,某些在跑新代码。通过
schema_version可以轻松实现数据的负载均衡和灰度发布。
1️⃣2️⃣ 总结与延伸阅读 📝
复盘:
今天我们讨论的不是怎么"爬",而是怎么"接"。一个稳健的爬虫系统必须假设**"解析一定会变"**。通过版本号和动态存储,我们让 Pipeline 变得无比丝滑。
- v1.0: 满足生存。
- v2.0: 优雅演化。
- JSON 缓冲区: 拥抱未知。
这种架构思维不仅适用于爬虫,也适用于任何处理非结构化数据的分布式系统。
下一步:
既然字段已经能动态处理了,我们要不要考虑结合 自动化告警系统 ?当检测到大量数据掉入 extra_data 时,自动给你的企微/钉钉发个消息提醒:"主人,网站改版啦,快来看看新字段!"
🌟 文末
好啦~以上就是本期的全部内容啦!如果你在实践过程中遇到任何疑问,欢迎在评论区留言交流,我看到都会尽量回复~咱们下期见!
小伙伴们在批阅的过程中,如果觉得文章不错,欢迎点赞、收藏、关注哦~
三连就是对我写作道路上最好的鼓励与支持! ❤️🔥
✅ 专栏持续更新中|建议收藏 + 订阅
墙裂推荐订阅专栏 👉 《Python爬虫实战》,本专栏秉承着以"入门 → 进阶 → 工程化 → 项目落地"的路线持续更新,争取让每一期内容都做到:
✅ 讲得清楚(原理)|✅ 跑得起来(代码)|✅ 用得上(场景)|✅ 扛得住(工程化)
📣 想系统提升的小伙伴 :强烈建议先订阅专栏 《Python爬虫实战》,再按目录大纲顺序学习,效率十倍上升~

✅ 互动征集
想让我把【某站点/某反爬/某验证码/某分布式方案】等写成某期实战?
评论区留言告诉我你的需求,我会优先安排实现(更新)哒~
⭐️ 若喜欢我,就请关注我叭~(更新不迷路)
⭐️ 若对你有用,就请点赞支持一下叭~(给我一点点动力)
⭐️ 若有疑问,就请评论留言告诉我叭~(我会补坑 & 更新迭代)
✅ 免责声明
本文爬虫思路、相关技术和代码仅用于学习参考,对阅读本文后的进行爬虫行为的用户本作者不承担任何法律责任。
使用或者参考本项目即表示您已阅读并同意以下条款:
- 合法使用: 不得将本项目用于任何违法、违规或侵犯他人权益的行为,包括但不限于网络攻击、诈骗、绕过身份验证、未经授权的数据抓取等。
- 风险自负: 任何因使用本项目而产生的法律责任、技术风险或经济损失,由使用者自行承担,项目作者不承担任何形式的责任。
- 禁止滥用: 不得将本项目用于违法牟利、黑产活动或其他不当商业用途。
- 使用或者参考本项目即视为同意上述条款,即 "谁使用,谁负责" 。如不同意,请立即停止使用并删除本项目。!!!
