博主介绍:程序喵大人
- 35 - 资深C/C++/Rust/Android/iOS客户端开发
- 10年大厂工作经验
- 嵌入式/人工智能/自动驾驶/音视频/游戏开发入门级选手
- 《C++20高级编程》《C++23高级编程》等多本书籍著译者
- 更多原创精品文章,首发gzh,见文末
- 👇👇记得订阅专栏,以防走丢👇👇
😉C++基础系列专栏
😃C语言基础系列专栏
🤣C++大佬养成攻略专栏
🤓C++训练营
👉🏻个人网站
在分布式系统架构中,当多个服务实例需要访问同一共享资源时,分布式锁成为了保证数据一致性的关键机制。从秒杀系统防止库存超卖,到定时任务避免重复执行,再到支付回调防止重复处理,分布式锁的身影无处不在。
对于准备后端面试的开发者来说,这几乎是绕不开的话题,而面试官往往会从多个角度进行追问:为什么需要分布式锁?有哪些实现方案?各自的优缺点是什么?如何根据业务场景进行选型?这些问题看似简单,但要让面试官满意,需要对各种方案有深入的理解,能够清晰地阐述其背后的原理和权衡。
在单机多线程环境下,我们可以使用 C++ 的 std::mutex 或 std::unique_lock 来保证线程安全,但在分布式系统中,多个服务实例运行在不同的机器上,本地锁已经失效了。
秒杀系统就是一个典型的场景。假设某商品库存仅剩 100 件,但在瞬间有数万请求涌来。如果每个服务实例都独立处理库存扣减,那么多个请求可能同时读到库存为 100,都计算出 99,然后先后写入数据库,最终库存变为 99 而不是 98,这意味着卖出了 101 件商品,造成严重的资损。
分布式锁可以确保在扣减库存的整个逻辑段内,只有一个微服务实例能够执行操作,从而保证数据的一致性。同样的问题也出现在定时任务中,多个节点同时触发可能导致同一个数据处理两次,或者在支付回调中重复处理同一笔支付,这些都需要分布式锁来保护。

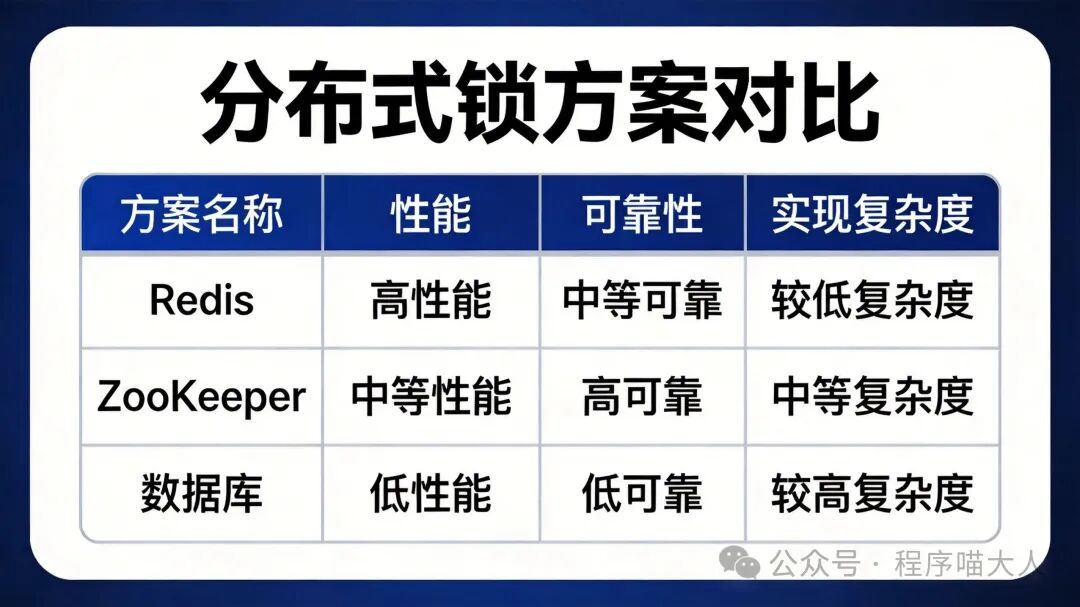
业界主流的分布式锁实现方案主要有三种:
- 基于 Redis
- 基于 ZooKeeper
- 基于数据库
这三种方案各有特点,适合不同的业务场景,理解它们的实现原理和优缺点,是做出正确技术选型的基础。
一、基于 Redis 的分布式锁
Redis 分布式锁是目前互联网企业最常用的方案,核心优势是高性能。其实现原理利用了 Redis 的 SET 命令的原子性特性。
使用 hiredis 库,我们可以这样实现一个基本的 Redis 分布式锁:
cpp
class RedisLock {
private:
redisContext* redis_;
std::string lockKey_;
std::string uniqueValue_;
int lockTimeout_;
std::string generateUniqueId() {
uuid_t uuid;
uuid_generate(uuid);
char uuid_str[37];
uuid_unparse(uuid, uuid_str);
return std::string(uuid_str);
}
public:
RedisLock(const std::string& host, int port,
const std::string& lockKey, int timeout)
: lockKey_(lockKey), lockTimeout_(timeout) {
redis_ = redisConnect(host.c_str(), port);
if (redis_ == nullptr || redis_->err) {
throw std::runtime_error("Failed to connect to Redis");
}
uniqueValue_ = generateUniqueId();
}
bool tryLock() {
std::string command = "SET " + lockKey_ + " " + uniqueValue_ +
" NX PX " + std::to_string(lockTimeout_ * 1000);
redisReply* reply = (redisReply*)redisCommand(redis_, command.c_str());
bool success = false;
if (reply) {
success = (reply->type == REDIS_REPLY_STATUS &&
std::string(reply->str) == "OK");
freeReplyObject(reply);
}
return success;
}
bool unlock() {
std::string luaScript = R"(
if redis.call("get", KEYS[1]) == ARGV[1] then
return redis.call("del", KEYS[1])
else
return 0
end
)";
redisReply* reply = (redisReply*)redisCommand(
redis_, "EVAL %s 1 %s %s",
luaScript.c_str(),
lockKey_.c_str(),
uniqueValue_.c_str()
);
bool success = false;
if (reply) {
success = (reply->type == REDIS_REPLY_INTEGER && reply->integer == 1);
freeReplyObject(reply);
}
return success;
}
};关键设计点说明
-
SET key value NX PX timeout
NX:只有当 key 不存在时才设置,保证互斥性PX:设置毫秒级过期时间,防止死锁
-
value 使用 UUID
用于唯一标识锁的持有者,确保只有加锁的客户端才能解锁,避免误删其他客户端的锁。
-
Lua 脚本解锁
将"校验 value"和"删除 key"两个操作合并为一个原子操作,避免并发问题。

Redis 分布式锁的优缺点
优点
- 纯内存操作,性能极高,QPS 可达 10 万以上
- 实现简单,生态成熟
缺点
- 主从切换可能导致锁丢失
- 过期时间难以准确评估
Watch Dog 自动续期机制
为了解决锁过期时间难以评估的问题,可以引入 Watch Dog 机制:
- 获取锁后启动后台守护线程
- 定期检查锁是否仍然由当前客户端持有
- 若持有则自动延长过期时间
需要注意:
- 实现复杂度上升
- 客户端进程崩溃时,守护线程停止,锁最终仍依赖过期释放
二、基于 ZooKeeper 的分布式锁
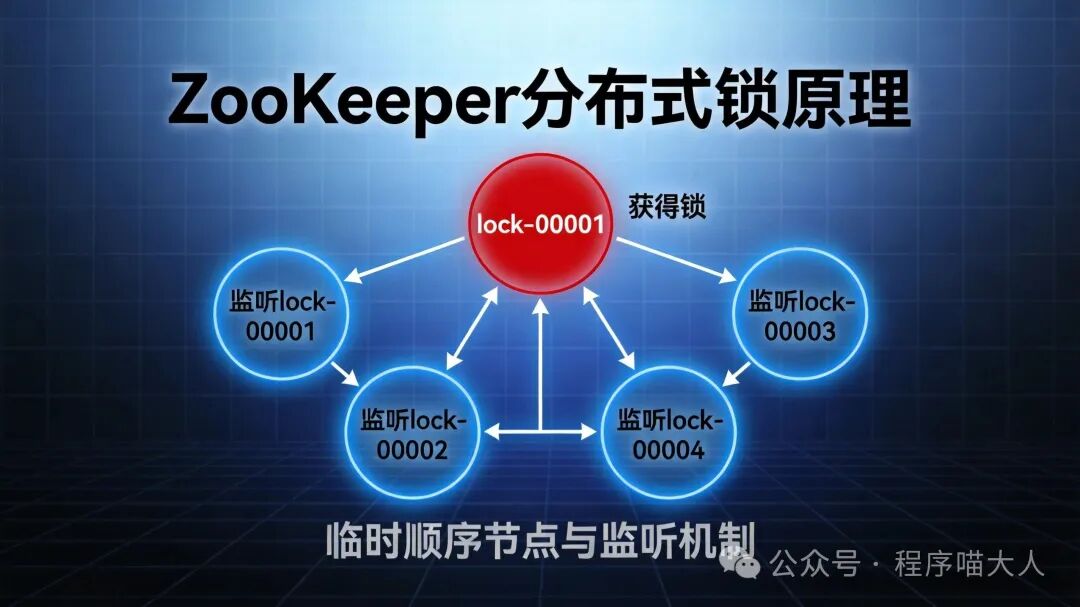
ZooKeeper 分布式锁的核心原理与 Redis 完全不同,它利用了 ZooKeeper 的临时顺序节点 和 Watcher 机制。
实现原理
- 客户端在指定路径下创建一个临时顺序节点,如:
/locks/lock-000000001 - ZooKeeper 保证节点序号全局唯一、单调递增
- 客户端获取所有子节点并排序
- 若自己节点序号最小,则获得锁
- 否则监听前一个序号的节点
- 当前一个节点被删除时,收到通知并重新竞争锁
C 客户端示例代码
cpp
class ZkLock {
private:
zhandle_t* zh_;
std::string lockPath_;
std::string currentPath_;
std::string previousPath_;
std::string lockName_;
static void watcher(zhandle_t* zh, int type, int state,
const char* path, void* watcherCtx) {
if (type == ZOO_DELETED_EVENT) {
ZkLock* lock = static_cast<ZkLock*>(watcherCtx);
lock->checkLock();
}
}
void checkLock() {
String_vector children;
int rc = zoo_get_children(zh_, lockPath_.c_str(), 0, &children);
if (rc != ZOK) return;
std::vector<std::string> sortedNodes;
for (int i = 0; i < children.count; i++) {
sortedNodes.push_back(children.data[i]);
}
std::sort(sortedNodes.begin(), sortedNodes.end());
std::string currentNode = currentPath_.substr(lockPath_.length() + 1);
auto it = std::find(sortedNodes.begin(), sortedNodes.end(), currentNode);
if (it == sortedNodes.begin()) return;
--it;
previousPath_ = lockPath_ + "/" + *it;
zoo_wexists(zh_, previousPath_.c_str(), watcher, this, nullptr);
}
public:
ZkLock(const std::string& hosts, const std::string& lockName)
: lockName_(lockName) {
zh_ = zookeeper_init(hosts.c_str(), watcher, 10000, 0, this, 0);
if (!zh_) throw std::runtime_error("Failed to connect to ZooKeeper");
lockPath_ = "/locks/" + lockName_;
ensurePathExists(lockPath_);
}
void ensurePathExists(const std::string& path) {
char path_buffer[1024];
int rc = zoo_create(zh_, path.c_str(), "", 0,
&ZOO_OPEN_ACL_UNSAFE, 0,
path_buffer, sizeof(path_buffer));
if (rc != ZOK && rc != ZNODEEXISTS) {
throw std::runtime_error("Failed to create path");
}
}
bool lock() {
char path_buffer[1024];
int rc = zoo_create(zh_, (lockPath_ + "/lock-").c_str(), "", 0,
&ZOO_OPEN_ACL_UNSAFE,
ZOO_EPHEMERAL | ZOO_SEQUENCE,
path_buffer, sizeof(path_buffer));
if (rc != ZOK) return false;
currentPath_ = path_buffer;
checkLock();
return true;
}
bool unlock() {
int rc = zoo_delete(zh_, currentPath_.c_str(), -1);
return rc == ZOK;
}
};ZooKeeper 分布式锁的优缺点
优点
- 临时节点随会话消失,天然避免死锁
- 顺序节点保证公平性,避免饥饿
- 基于 ZAB 协议,强一致性,不会丢锁
缺点
- 性能较低,吞吐量一般在 1 万 QPS 左右
- 部署和运维成本高
- 需要注意"羊群效应",需通过监听前一个节点来避免
三、基于数据库的分布式锁
基于数据库的分布式锁是三者中最简单的方案,原理直观:
- 建一张锁表
- 对
lock_key建立唯一索引 - 加锁:插入记录
- 解锁:删除记录
示例代码
cpp
class DatabaseLock {
private:
sql::mysql::MySQL_Driver* driver_;
sql::Connection* conn_;
std::string lockKey_;
std::string owner_;
int lockTimeout_;
public:
DatabaseLock(const std::string& host, const std::string& user,
const std::string& password, const std::string& database,
const std::string& lockKey, int timeout)
: lockKey_(lockKey), lockTimeout_(timeout) {
driver_ = sql::mysql::get_mysql_driver_instance();
conn_ = driver_->connect(host, user, password);
conn_->setSchema(database);
owner_ = "127.0.0.1:" + std::to_string(getpid());
}
bool tryLock() {
try {
std::unique_ptr<sql::PreparedStatement> pstmt(
conn_->prepareStatement(
"INSERT INTO distributed_lock (lock_key, owner, expire_time) "
"VALUES (?, ?, ?)"
)
);
pstmt->setString(1, lockKey_);
pstmt->setString(2, owner_);
pstmt->setString(3, "2025-01-01 00:00:00");
return pstmt->executeUpdate() > 0;
} catch (...) {
return false;
}
}
bool unlock() {
try {
std::unique_ptr<sql::PreparedStatement> pstmt(
conn_->prepareStatement(
"DELETE FROM distributed_lock "
"WHERE lock_key = ? AND owner = ?"
)
);
pstmt->setString(1, lockKey_);
pstmt->setString(2, owner_);
return pstmt->executeUpdate() > 0;
} catch (...) {
return false;
}
}
};数据库分布式锁的优缺点
优点
- 实现简单
- 不需要引入新组件
- 适合小规模系统或原型验证
缺点
- 性能最差,通常只有几百 QPS
- 存在死锁风险,需要额外清理机制
- 长时间占用数据库连接,影响整体性能
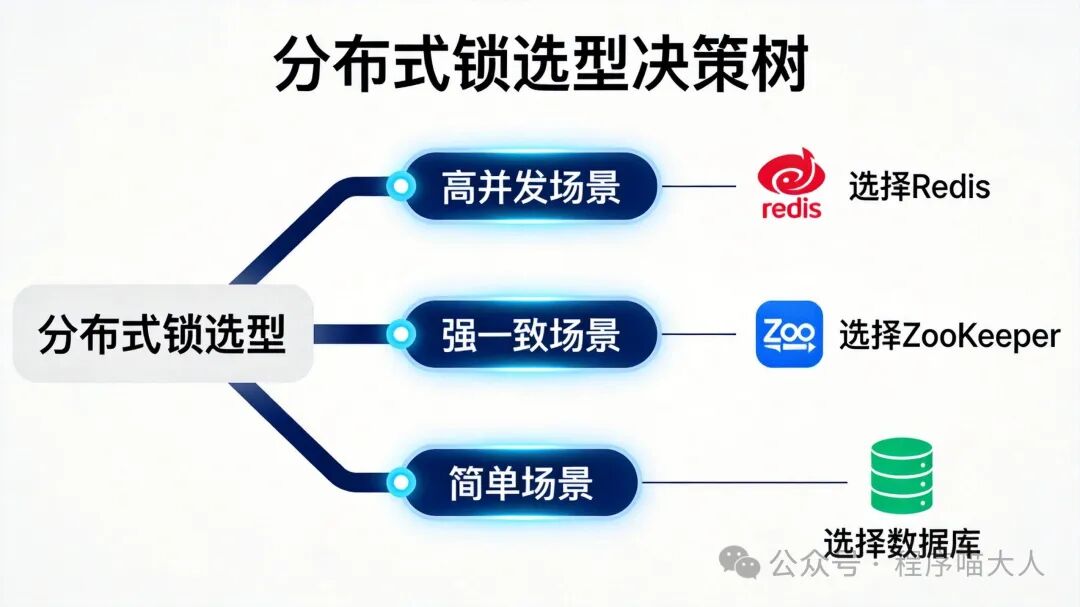
四、如何进行分布式锁选型
-
Redis
- 追求极致性能
- 高并发场景(秒杀、库存扣减)
- 可通过幂等性作为兜底
-
ZooKeeper
- 强一致性优先
- 金融转账、分布式事务、核心业务
-
数据库
- 并发量低
- 对性能要求不高
- 临时方案或小型系统
五、面试中的高频追问点
- Redis 锁为什么要用唯一 value
- 解锁为什么必须使用 Lua 脚本
- ZooKeeper 临时节点的生命周期
- 如何避免 ZooKeeper 羊群效应
- 数据库锁表的索引设计
分布式锁看似只是一个技术点,背后却涉及并发控制、分布式一致性、性能与可靠性的权衡。真正掌握它,不仅能让你在面试中游刃有余,更能在实际项目中做出正确的技术决策,构建稳定可靠的分布式系统。
码字不易,欢迎大家点赞,关注,评论,谢谢!