Tianyi Zhang * 明尼苏达大学 {zhan9167}@umn.edu
Antoine Simoulin & Kai Li Meta
Sana Lakdawala & Shiqing Yu & Arpit Mittal & Hongyu Fu {sanalakdawala,sqy,arpitmittal,hongyufu}@meta.com
Yu Lin Meta {yulin0077}@meta.com
https://arxiv.org/pdf/2602.00531v1
摘要
传统目标检测系统通常局限于预定义类别,限制了其在动态环境中的适用性。相比之下,开放词汇目标检测(OVD)能够识别训练集中不存在的新类别物体。视觉-语言模型的最新进展显著推动了OVD的发展。然而,先前工作在将CLIP的单尺度图像主干适配到检测框架或将视觉-语言对齐做得稳健方面面临挑战。我们提出视觉-语言检测(VLDet),一种通过重构特征金字塔实现细粒度视觉-语言对齐的新框架,从而提升OVD性能。借助VL-PUB模块,VLDet有效利用CLIP中的视觉-语言知识,并通过特征金字塔将主干网络适配到目标检测任务。此外,我们引入SigRPN模块,该模块结合基于Sigmoid的锚点-文本对比对齐损失,以改进新类别的检测。通过大量实验,我们的方法在COCO2017上对新类别达到58.7 AP,在LVIS上达到24.8 AP,超越所有现有最先进方法,分别实现27.6%和6.9%的显著提升。此外,VLDet在闭集目标检测的零样本性能方面也表现出色。
1 引言
随着视觉-语言模型(VLM)(Radford et al., 2021; Zeng et al., 2023; Zhai et al., 2023)的发展,近期研究已将传统目标检测框架扩展为能够检测训练集中不存在类别的开放世界目标检测器 (Li et al., 2022a; Zhong et al., 2022; Liu et al., 2023; Cheng et al., 2024; Zhou et al., 2022; Gao et al., 2022)。作为先驱,OVR-CNN (Zareian et al., 2021) 通过引入使用图像-标题对预训练阶段来对齐图像和文本编码器,提出了开放词汇目标检测。随后,检测模型采用对齐后的图像编码器作为其主干网络,根据图像特征与文本编码器生成的类别名称文本嵌入之间的相似性对边界框进行分类。尽管后续工作 (Gu et al., 2021; Wu et al., 2023a) 通过从CLIP (Radford et al., 2021) 蒸馏知识用于区域级分类提高了性能,但它们仍依赖于图像级对齐的视觉-语言知识。更精确的检测需要细粒度的区域级视觉-语言对齐 (Zhong et al., 2022)。
许多实现区域级对齐的工作已被提出以弥补这一差距,例如RegionCLIP (Zhong et al., 2022) 和YOLO-World (Cheng et al., 2024)。然而,这些方法也带来了若干挑战。首先,它们难以将CLIP中的图像编码器适配到检测模型中。一些方法简单采用CLIP的单尺度主干网络,这损害了空间信息和检测精度;另一些方法尝试使用由零样本检测器(如GLIP (Li et al., 2022a))在大规模数据集上生成的伪标注区域(即边界框)从头训练多尺度主干网络。这些伪标签需要大量额外处理工作 (Li et al., 2022a; Yao et al., 2022; Liu et al., 2023; Cheng et al., 2024),极大限制了其可复现性。其次,这些方法偏向区域级对齐,忽略了图像级对齐对视觉-语言建模同样有益 (Zeng et al., 2023)。最后,上述方法要么采用单阶段检测器,要么使用普通的区域建议网络(RPN)。一个复杂的RPN可以通过提议任何潜在类别的物体显著提升OVD性能 (Gu et al., 2021)。

为应对这些挑战,我们提出一种新框架------视觉-语言检测(VLDet)。通过引入视觉-语言金字塔上采样块(VL-PUB),我们将CLIP的图像和文本编码器集成到框架中,有效利用其丰富的视觉-语言潜在空间并构建特征金字塔以检测不同尺寸的物体。为增强视觉-语言对齐,我们在多个层次引入对比损失,实现多层次细粒度对齐。具体而言,我们采用:(i) 图像-标题对比损失,提供对完整图像与标题之间关系的更广泛理解。该损失在小批量内计算,以平衡图像级和区域级视觉-语言对齐的训练;(ii) 区域-文本对比损失 (Li et al., 2022a) 以实现图像区域与物体类别文本之间的细粒度对齐;(iii) 额外的锚点-文本二元视觉-语言对齐,增强RPN区分背景与任何类别物体的能力,并促进学习适用于任何类别的通用语义信息,从而提高对新类别的泛化能力,如图1所示。值得注意的是,VLDet仅在检测数据集Objects365 (Shao et al., 2019)上进行预训练,其中可利用任意基础VLM生成标题。与对大规模图像-标题对进行边界框伪标注相比,该方法显著提高了效率和可复现性。通过对公共OVD数据集的全面实验,VLDet超越所有基线方法,并在传统目标检测的零样本推理和微调方面也展现出卓越性能。
主要贡献总结如下:
- 我们提出VL-PUB模块,有效将CLIP的图像和文本编码器适配到开放世界目标检测器中,利用丰富的视觉-语言潜在空间并利用多尺度图像特征增强检测性能。
- 我们设计SigRPN------首个用于OVD的RPN,使用基于Sigmoid的视觉-语言对比学习区分背景与任何类别的物体,有助于提议所有潜在新类别的物体,并显著增强OVD场景中对新类别的泛化能力。
- 我们进一步集成图像级对比损失以实现更稳健的视觉-语言对齐。
- 通过在公共数据集上的广泛实验,所提出的VLDet在OVD上超越最先进方法,特别是在COCO2017上将新类别的mAP从46.0提升至58.7,在LVIS上从23.2提升至24.8,展示了VLDet卓越的泛化能力。
2 相关工作
2.1 传统目标检测
传统目标检测器在具有预定义类别的数据集上训练,随后在该固定类别集内检测物体(即闭集)。流行的目标检测器可分为三类:单阶段、两阶段和基于查询的检测器。YOLO系列 (Redmon, 2016; Redmon & Farhadi, 2017; Redmon, 2018; Jocher & Qiu, 2024) 是第一类的代表工作,利用卷积架构实现实时目标检测。DETR (Carion et al., 2020) 开创性地将Transformer (Zhang et al., 2024c; Cai et al., 2025; Zhang et al., 2024b,a) 用于目标检测,启发了众多基于查询的方法 (Kamath et al., 2021; Zhang et al., 2022; Zong et al., 2023; Ren et al., 2023)。两阶段检测器 (Ren et al., 2016; He et al., 2017; Cai & Vasconcelos, 2019),如Faster R-CNN (Ren et al., 2016),采用两阶段框架进行提议生成和感兴趣区域(RoI)分类与回归。虽然两阶段中的RPN学习区分所有类别(无论新旧)背景与物体的通用信息,但本文强调RPN对OVD的重要性。
2.2 开放世界目标检测
开放集目标检测领域主要有两个分支:开放词汇目标检测(OVD)和零样本目标检测(ZOD)。
OVD最早由OVR-CNN (Zareian et al., 2021) 提出,其中视觉编码器在图像-文本对上预训练以学习物体概念,从而能够检测训练集中未包含的额外类别。随后,ViLD (Gu et al., 2021) 和DetPro (Du et al., 2022) 通过从预训练CLIP模型蒸馏视觉特征来训练目标检测器。RegionCLIP (Zhong et al., 2022) 进一步通过从预训练CLIP模型提供的"伪"区域-文本对学习区域表示推进了这一方向。Detic (Zhou et al., 2022) 在具有更广泛词汇表的ImageNet21K上训练检测器的分类器。BARON (Bica et al., 2024) 将上下文相关的区域分组为包,并对区域包的嵌入进行对齐,超越单个区域的对齐。
在ZOD方面,近期方法从GLIP (Li et al., 2022a; Liu et al., 2023; Shen et al., 2024; Cheng et al., 2024; Jiang et al., 2024) 开始,通过将短语定位任务与目标检测集成来实现。这种集成利用定位数据集(例如由 (Kamath et al., 2021) 从 (Plummer et al., 2015; Krishna et al., 2017; Hudson & Manning, 2019) 整理的GoldG)和带有伪标注边界框的大规模图像-标题对 (Sharma et al., 2018; Ordonez et al., 2011),通过从图像标题中提取词语提供大量类别。我们的方法主要针对OVD,但也展示了有前景的ZOD能力,通过仅在Objects365上预训练并避免边界框伪标注,从而增强可复现性。
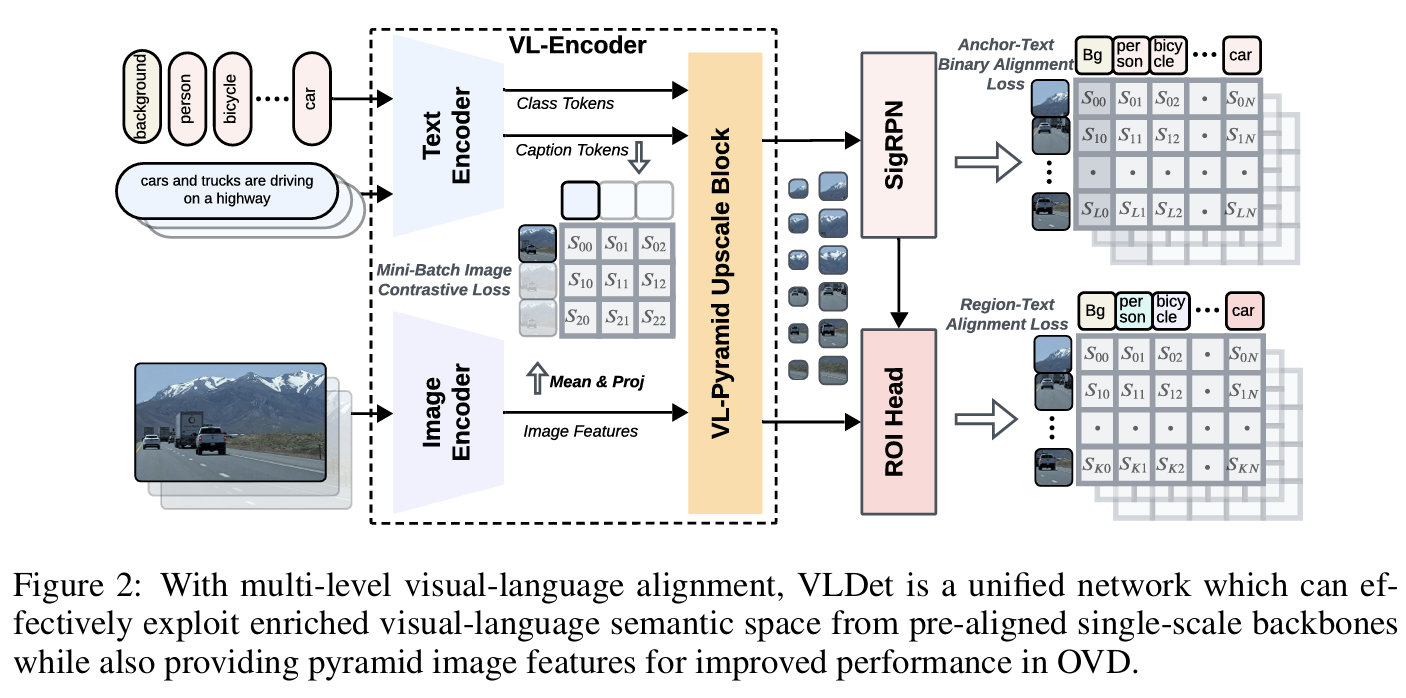
单尺度ViT主干网络被研究者广泛用于与图像-标题对的视觉-语言对齐 (Radford et al., 2021; Zareian et al., 2021; Zhai et al., 2023)。它们产生丰富的多模态嵌入空间,但空间信息有限。为解决此问题,VLDet设计为将任意单尺度视觉-语言主干网络统一到目标检测器中,提供多尺度特征以增强检测性能,如图2所示。
3 方法
3.1 整体架构
为利用CLIP对齐图像和文本编码器中的丰富语义信息,我们设计了视觉-语言编码器(VL-Encoder),将这两个编码器与视觉-语言金字塔上采样块(VL-PUB)集成。虽然CLIP图像编码器在单尺度提取特征,但VL-PUB在与文本特征融合后将输出特征投射到多尺度,增强对不同尺寸物体的检测性能 (Lin et al., 2017)。先前工作 (Li et al., 2022a) 将所有类别名称组合在一起并为这个长序列生成嵌入,导致两个显著问题:首先,它为不同类别分配不同数量的token,计算与视觉特征的相似度时需要token分组;其次,当数据集(例如Objects365或LVIS)包含过多类别时,需要非平凡的调整以适应文本编码器的最大token长度(例如256)。相比之下,我们使用CLIP文本编码器将每个类别名称嵌入为单个token,这对对比损失计算更为系统化,并自然支持任意数量的类别而无需额外修改。此外,值得注意的是,我们仅在推理时使用类别名称作为文本输入,而在训练阶段包含额外的图像标题分支。该设计通过在训练时提供更丰富的文本上下文,有利于类别名称的文本特征提取。通过在进行图像级对比学习时利用这种信息丰富的文本特征,我们进一步增强了目标检测的视觉-语言对齐。
具体而言,输入图像 x∈RH×W×3\boldsymbol{x} \in \mathbb{R}^{H \times W \times 3}x∈RH×W×3(HHH 为图像高度,WWW 为宽度)首先通过图像编码器嵌入为单尺度图像特征 v0∈RHp×Wp×Cv\boldsymbol{v}0 \in \mathbb{R}^{\frac{H}{p} \times \frac{W}{p} \times C_v}v0∈RpH×pW×Cv,其中 CvC_vCv 为视觉维度数量,ppp 为patch大小。类别提示被嵌入为语言特征 lcls∈RN×Cl\boldsymbol{l}{cls} \in \mathbb{R}^{N \times C_l}lcls∈RN×Cl,其中 NNN 为训练数据中类别数量(包括背景类别,例如Objects365为366),ClC_lCl 为语言特征维度。图像标题也通过文本编码器嵌入为单个token lcap∈R1×Cl\boldsymbol{l}_{cap} \in \mathbb{R}^{1 \times C_l}lcap∈R1×Cl。我们添加一个线性层,将提取的图像特征 v0\boldsymbol{v}0v0 在所有视觉token上的均值投影到与标题嵌入 lcap\boldsymbol{l}{cap}lcap 相同的维度,用于图像级视觉-语言对比学习,从而实现更好的视觉-语言对齐。
为更好捕获不同尺寸的物体,提取的文本特征 lcls,lcap\boldsymbol{l}{cls}, \boldsymbol{l}{cap}lcls,lcap 和图像特征 v0\boldsymbol{v}0v0 首先通过VL-PUB生成多尺度图像特征。该块首先通过双向交叉注意力 (Li et al., 2022a) 融合图像特征与文本特征,然后采用单个Transformer层进一步将文本特征嵌入为更深的嵌入 lcls′∈RN×Cl\boldsymbol{l}{cls}' \in \mathbb{R}^{N \times C_l}lcls′∈RN×Cl,并利用多个反卷积、最大池化和卷积层生成不同尺度的图像特征 vi\boldsymbol{v}_ivi,其中 i∈{1,2,...,Z}i \in \{1,2,...,Z\}i∈{1,2,...,Z},ZZZ 为超参数,表示输出尺度数量。生成的图像特征尺度范围从 H4p×W4p\frac{H}{4p} \times \frac{W}{4p}4pH×4pW 到 4Hp×4Wp\frac{4H}{p} \times \frac{4W}{p}p4H×p4W,视觉维度 CvC_vCv 变为256。为简化起见,后续章节中使用 Cv=256C_v=256Cv=256。
提取的多尺度图像特征 vi,i∈{1,2,...,Z}\boldsymbol{v}i, i \in \{1,2,...,Z\}vi,i∈{1,2,...,Z} 和文本特征 lcls′\boldsymbol{l}{cls}'lcls′ 被输入到视觉-语言RPN模块(SigRPN)中,用于预测任何潜在物体类别的提议。在SigRPN中,文本特征首先通过双向交叉注意力 (Li et al., 2022a) 与多尺度图像特征融合,然后通过单个Transformer层获得更具信息量的特征 lcls′′∈RN×Cl\boldsymbol{l}_{cls}'' \in \mathbb{R}^{N \times C_l}lcls′′∈RN×Cl。与文本特征融合后,不同尺度的图像特征被输入到若干卷积层。每个尺度 vi∈Rhi×wi×Cv\boldsymbol{v}_i \in \mathbb{R}^{h_i \times w_i \times C_v}vi∈Rhi×wi×Cv(hih_ihi 和 wiw_iwi 表示第 iii 个尺度特征图的高度和宽度)生成对应的物体性logits ai∈Rhi×wi×A×Cl\boldsymbol{a}_i \in \mathbb{R}^{h_i \times w_i \times A \times C_l}ai∈Rhi×wi×A×Cl,其中 AAA 表示每个空间位置的锚点数量,以及锚点偏移量 di∈Rhi×wi×A×4\boldsymbol{d}_i \in \mathbb{R}^{h_i \times w_i \times A \times 4}di∈Rhi×wi×A×4 (Ren et al., 2016)。最后,基于SigRPN的提议,ROI Head从多尺度图像特征 vi,i∈{1,2,...,Z}\boldsymbol{v}_i, i \in \{1,2,...,Z\}vi,i∈{1,2,...,Z} 中提取区域级特征用于物体分类(实验中 Z=5Z=5Z=5)。
3.2 视觉-语言金字塔上采样块
尽管CLIP中预对齐的图像和文本编码器包含丰富的语义信息(在包含4亿图像-标题对的数据集上训练),但图像编码器仅在单尺度输出视觉特征。多尺度图像特征通常在目标检测中表现更好 (Lin et al., 2017; Li et al., 2022b),因为图像中的物体尺寸各异,多尺度特征图可提供更全面的空间信息。遵循相同思路,在将图像编码器生成的图像特征直接输入后续RPN和ROI Head之前,我们引入视觉-语言金字塔上采样块(VL-PUB)以提取不同尺度的特征图,如图3所示。
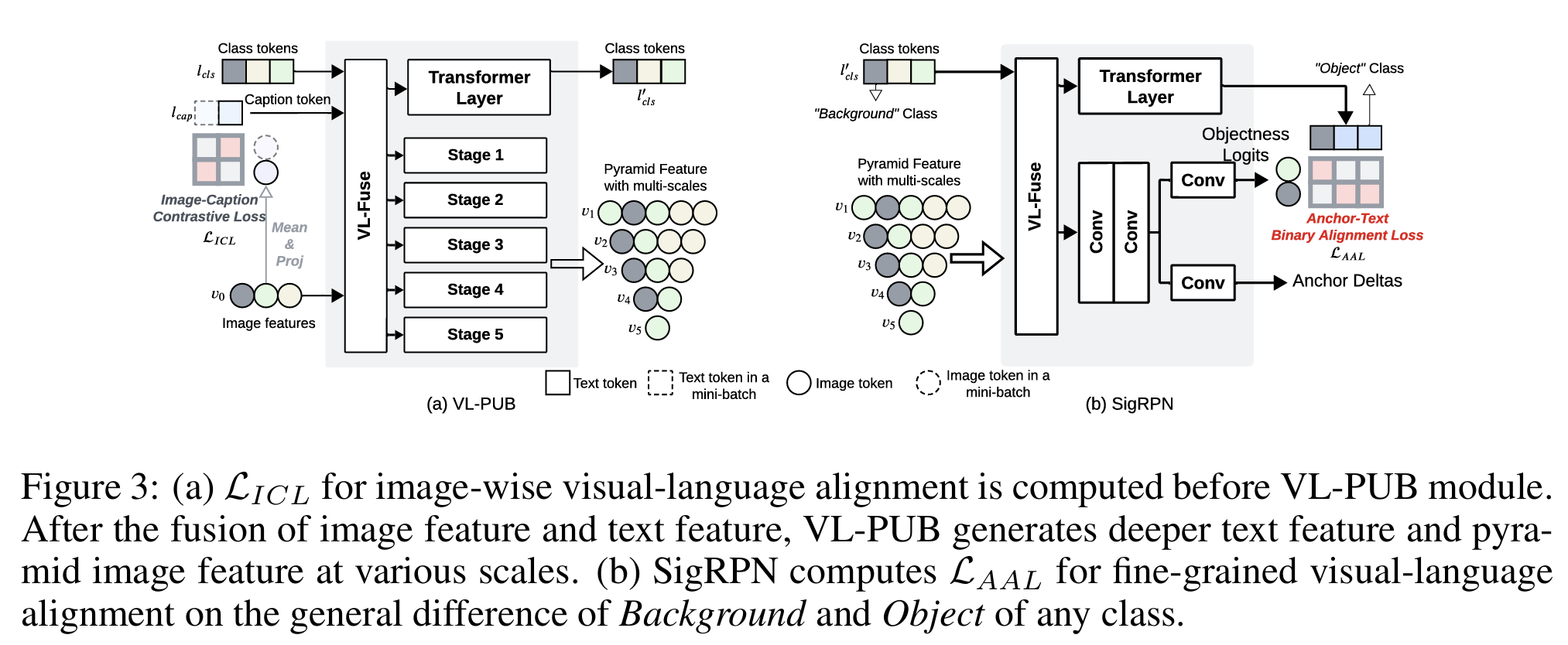
具体而言,假设我们已从文本编码器 EL\mathrm{E}LEL 和图像编码器 EV\mathrm{E}VEV 获得文本特征 lcls,lcap\boldsymbol{l}{cls}, \boldsymbol{l}{cap}lcls,lcap 和图像特征 v0\boldsymbol{v}_0v0,如下所示:
lcls=EL(CLS),lcap=EL(CAP),v0=EV(x)\boldsymbol{l}_{cls} = \mathrm{E}L(\mathrm{CLS}), \quad \boldsymbol{l}{cap} = \mathrm{E}_L(\mathrm{CAP}), \quad \boldsymbol{v}_0 = \mathrm{E}_V(\boldsymbol{x})lcls=EL(CLS),lcap=EL(CAP),v0=EV(x)
其中 x\boldsymbol{x}x 为输入图像,CAP、CLS分别表示对应的标题和类别提示。我们分别编码CLS和CAP以减少CLS的token数量(因为类别名称比标题短得多),从而降低内存消耗和计算量。
先前工作证明视觉和语言特征的早期融合可带来性能提升 (Li et al., 2022a; Liu et al., 2023)。我们首先采用视觉-语言融合层(VL-Fuse)在连接类别token和标题token后,通过双向交叉注意力增强文本和图像特征,如下所示:
vf,lf=VLFuse(v0,Concat(lcls,lcap))\boldsymbol{v}_f, \boldsymbol{l}f = \mathrm{VLFuse}(\boldsymbol{v}0, \mathrm{Concat}(\boldsymbol{l}{cls}, \boldsymbol{l}{cap}))vf,lf=VLFuse(v0,Concat(lcls,lcap))
其中 vf,lf\boldsymbol{v}_f, \boldsymbol{l}fvf,lf 表示VL-Fuse层融合后的视觉特征和语言特征。接下来,文本特征通过单个Transformer层生成更深的文本嵌入 lcls′\boldsymbol{l}{cls}'lcls′。
对于图像特征,VL-PUB在与文本嵌入融合后,采用具有多阶段的金字塔特征模块生成不同尺度的图像特征。遵循Lin et al. (2017); Li et al. (2022b),我们利用反卷积层和最大池化层进行特征图的上采样和下采样,生成5种不同尺度的特征图。
3.3 视觉-语言区域建议网络
由于OD中的RPN旨在为任何类别(无论基础类或新类)提议区域,我们在本节强调RPN模块对OVD的重要性。鉴于基于区域的视觉-语言对齐在区域分类方面的先前成功 (Zhong et al., 2022; Li et al., 2022a) 以及Sigmoid损失相对于Softmax对比损失的优越性 (Zhai et al., 2023),我们提出一种新颖的SigRPN模块,采用基于Sigmoid的视觉-语言对齐来增强模型对新类别的泛化能力。
具体而言,VL-Fuse层首先使用双向交叉注意力将文本特征与各种尺度的视觉特征融合,以增强上下文理解并生成更具信息量的特征表示,如下所示:
vf′,lf′=VLFuse(Concat(v1,v2,v3,v4,v5),lcls′)\boldsymbol{v}_f', \boldsymbol{l}_f' = \mathrm{VLFuse}(\mathrm{Concat}(\boldsymbol{v}_1, \boldsymbol{v}_2, \boldsymbol{v}_3, \boldsymbol{v}_4, \boldsymbol{v}5), \boldsymbol{l}{cls}')vf′,lf′=VLFuse(Concat(v1,v2,v3,v4,v5),lcls′)
其中 vf′,lf′\boldsymbol{v}_f', \boldsymbol{l}f'vf′,lf′ 分别表示SigRPN的VL-Fuse层融合后的视觉特征和语言特征。文本特征将通过单个Transformer层生成更具上下文信息的嵌入 lcls′′\boldsymbol{l}{cls}''lcls′′。
对于视觉特征图,两个卷积层首先增强每个尺度的视觉表示。然后将增强后的视觉特征输入到两个并行卷积层,为每个锚点生成物体性logits和锚点偏移量。物体性logits以对比方式用于提议的二元分类,以确定该锚点属于背景还是前景物体;锚点偏移量用于将锚点转换为边界框提议。
3.4 多层次细粒度对齐损失
为实现更稳健的视觉-语言对齐,我们在多个阶段引入对齐损失并有效组合它们以实现更好性能。
小批量图像对比损失。 为充分利用CLIP中预对齐的图像和文本编码器,我们将传统的CLIP训练损失融入VLDet框架进行图像级对齐。尽管CLIP推荐使用大批次进行对比学习,但我们发现这会导致更差的检测性能,因为它引起严重的损失平衡问题,并过度强调图像级视觉-语言对齐而忽视RPN和ROI损失。为减小图像级对比损失的规模并防止其主导训练过程,我们将输入划分为小批量并计算图像级对比损失如下:
LICL=−12B∑k=1B/M∑mk=1M(logexp(ϕ(vmk,lmk)/τ)∑nk=1Mexp(ϕ(vmk,lnk)/τ)+logexp(ϕ(lmk,vmk)/τ)∑nk=1Mexp(ϕ(lmk,vnk)/τ))\mathcal{L}{ICL} = -\frac{1}{2B}\sum{k=1}^{B/M}\sum_{m_k=1}^{M}\left(\log\frac{\exp(\phi(\boldsymbol{v}{m_k}, \boldsymbol{l}{m_k})/\tau)}{\sum_{n_k=1}^{M}\exp(\phi(\boldsymbol{v}{m_k}, \boldsymbol{l}{n_k})/\tau)} + \log\frac{\exp(\phi(\boldsymbol{l}{m_k}, \boldsymbol{v}{m_k})/\tau)}{\sum_{n_k=1}^{M}\exp(\phi(\boldsymbol{l}{m_k}, \boldsymbol{v}{n_k})/\tau)}\right)LICL=−2B1k=1∑B/Mmk=1∑M(log∑nk=1Mexp(ϕ(vmk,lnk)/τ)exp(ϕ(vmk,lmk)/τ)+log∑nk=1Mexp(ϕ(lmk,vnk)/τ)exp(ϕ(lmk,vmk)/τ))
其中 BBB 为批次大小,MMM 为表示小批量大小的超参数。实验中,我们发现 M=8M=8M=8 在损失之间取得最佳平衡。ϕ(v,l)\phi(\boldsymbol{v}, \boldsymbol{l})ϕ(v,l) 为视觉和语言嵌入之间的余弦相似度,τ\tauτ 为温度参数 (Wu et al., 2018)。
锚点-文本二元对齐损失。 除在粗粒度上对齐图像特征和文本特征的图像级对比损失外,我们引入两种区域级对齐损失用于细粒度对齐。第一种是SigRPN模块内的锚点-文本二元对齐损失(AAL)。传统RPN通常通过二元分类解决背景-前景问题。在SigRPN中,我们以对比方式处理此问题。具体而言,我们首先计算视觉特征与所有类别(包括背景)文本特征的相似度。然后使用所有前景物体类别相似度的均值减去与背景的相似度作为最终物体性分数 sobj\boldsymbol{s}_{obj}sobj,如下所示:
sobj=(1N′∑i=1N′ϕ(v,li)−ϕ(v,l0))/τ\boldsymbol{s}{obj} = \left(\frac{1}{N'}\sum{i=1}^{N'}\phi(\boldsymbol{v}, \boldsymbol{l}_i) - \phi(\boldsymbol{v}, \boldsymbol{l}_0)\right)/\tausobj= N′1i=1∑N′ϕ(v,li)−ϕ(v,l0) /τ
其中 N′N'N′ 表示前景物体类别数量,l0\boldsymbol{l}0l0 为背景的文本特征。我们将 sobj\boldsymbol{s}{obj}sobj 包裹在二元交叉熵(BCE)损失中作为RPN分类损失 LAAL\mathcal{L}_{AAL}LAAL。
区域-文本对齐损失。 对于ROI,我们遵循Li et al. (2022a),将视觉特征与文本特征的相似度包裹在类别交叉熵中作为区域-文本对齐损失 LRAL\mathcal{L}_{RAL}LRAL。
4 实验结果
数据集。 遵循先前工作 (Zareian et al., 2021; Gu et al., 2021; Zhong et al., 2022; Cheng et al., 2024),我们在两个公共数据集上评估我们的方法:COCO2017 (Lin et al., 2014) 和LVIS (Gupta et al., 2019)。为评估开放词汇目标检测性能,我们遵循标准协议将物体类别划分为基础集和新集,仅使用基础类别的标注训练模型,并在基础集、新集及全部类别上进行评估。对于COCO2017,我们遵循Zareian et al. (2021) 的数据划分,包含48个基础类别和17个新类别,全部集合包含65个类别,产生107,761张训练图像和4,836张测试图像。在LVIS上,遵循Gu et al. (2021),我们采用包含866个基础类别(常见和频繁物体)和337个新类别(稀有物体)的类别划分。此外,VLDet仅使用一个公共数据集Objects365进行预训练,其中标题由BLIP-2通过提示"用一句话描述此图像"生成,包含约170万图像-标题对。
实现细节。 我们采用两阶段Cascade RCNN (Cai & Vasconcelos, 2019) 作为基本检测框架。我们分别采用ViT-B和ViT-L图像编码器及对应的CLIP文本编码器作为图像编码器和文本编码器。预训练期间,语言主干网络采用 1×10−51 \times 10^{-5}1×10−5 的学习率,其余模块采用 1×10−41 \times 10^{-4}1×10−4。我们配置AdamW优化器,权重衰减为 1×10−41 \times 10^{-4}1×10−4。VLDet-B的批次大小为2,VLDet-L为1。在OVD微调阶段,我们将所有层的学习率降至 1×10−51 \times 10^{-5}1×10−5 并冻结视觉到语言投影层(V2L),其他设置保持不变。模型在预训练阶段最多训练50个epoch,微调阶段训练15个epoch。此外,我们将标题的最大token长度设置为64,并将类别名称填充至最长者(例如COCO2017上每个类别5个token)。所有实验在64块NVIDIA A100 GPU上进行。
4.1 VLDet在开放词汇目标检测上的表现
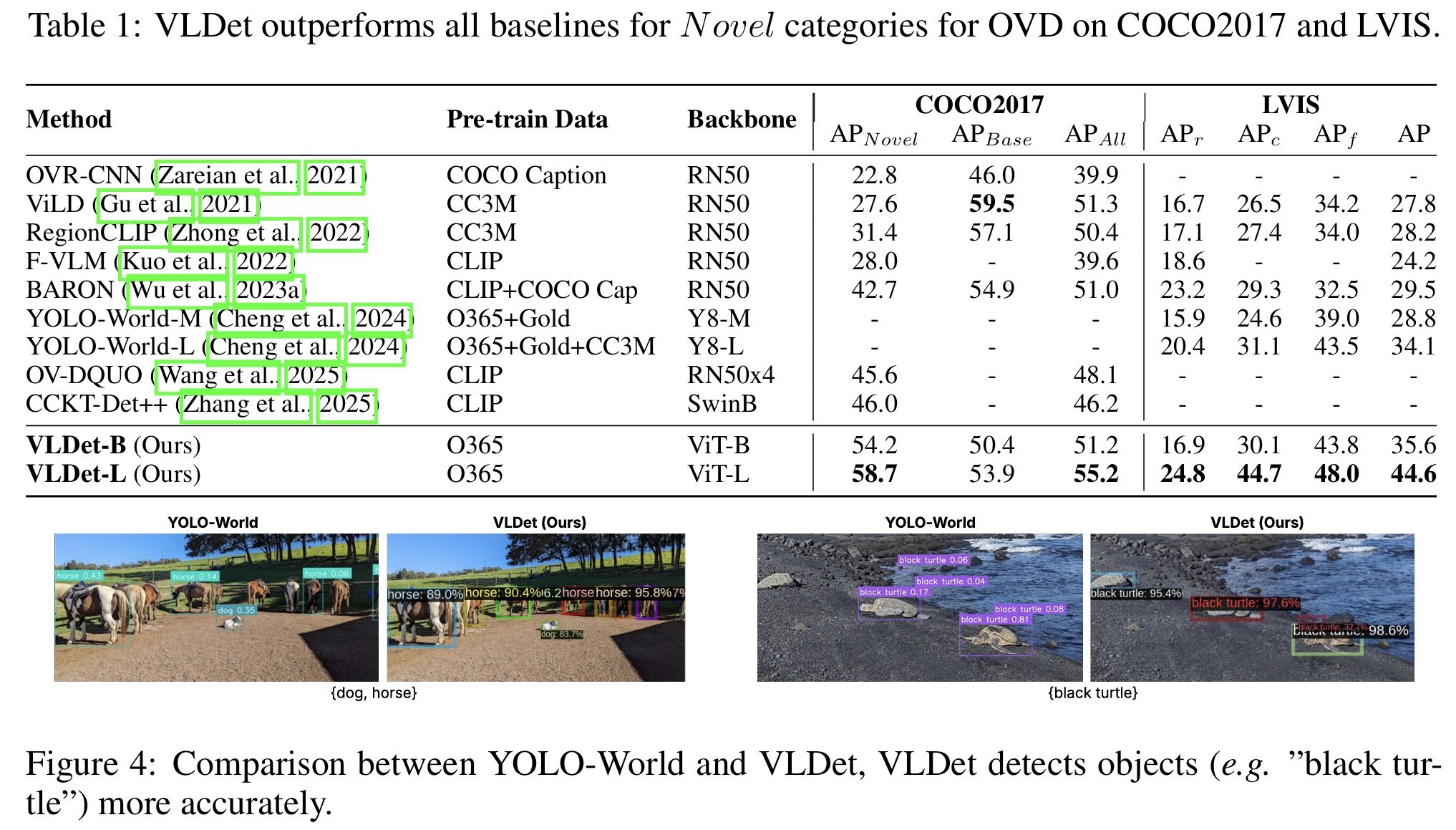
我们在COCO2017和LVIS上评估预训练于Objects365的VLDet进行OVD,与基线方法的详细比较见表1。在COCO2017和LVIS上实验时,我们仅使用基础类别(LVIS上为常见和频繁类别)进行训练,并在不同类别集上评估。
与所有基线方法相比,采用ViT-L主干网络的VLDet-L在全部类别上达到最高AP。更重要的是,它在新类别上也取得最佳性能,在COCO2017上将AP从CCKT-Det++ (Zhang et al., 2025) 的46.0提升至58.7,在LVIS上从BARON (Wu et al., 2023a) 的23.2提升至24.8。这证明了其对新类别的卓越泛化能力。值得注意的是,对于包含17个新类别的COCO2017,VLDet在新类别上的AP超过了基础类别。此外,VLDet-B也取得优越性能,进一步凸显了我们的多层次对齐损失对视觉-语言对齐的益处。ViLD (Gu et al., 2021) 通过大规模抖动 (Ghiasi et al., 2021) 的数据增强和显著更长的训练计划在基础类别上达到最佳AP。鉴于LVIS包含337个新类别,远多于COCO2017,采用ViT-B主干网络的VLDet-B表现有限。然而,我们更大的模型VLDet-L在所有指标上均超越所有基线方法。值得注意的是,与在更大规模数据上预训练的YOLO-World-L (Cheng et al., 2024) 相比,VLDet将新类别的AP提高了4.43,证明了两阶段框架和SigRPN对OVD的优越性。我们在图4中展示可视化比较。
4.2 VLDet在闭集目标检测上的表现
对于闭集OD,我们评估两种场景:首先,我们在COCO2017数据集上对预训练模型进行零样本评估(ZOD);其次,我们评估模型微调后的性能(FOD)。
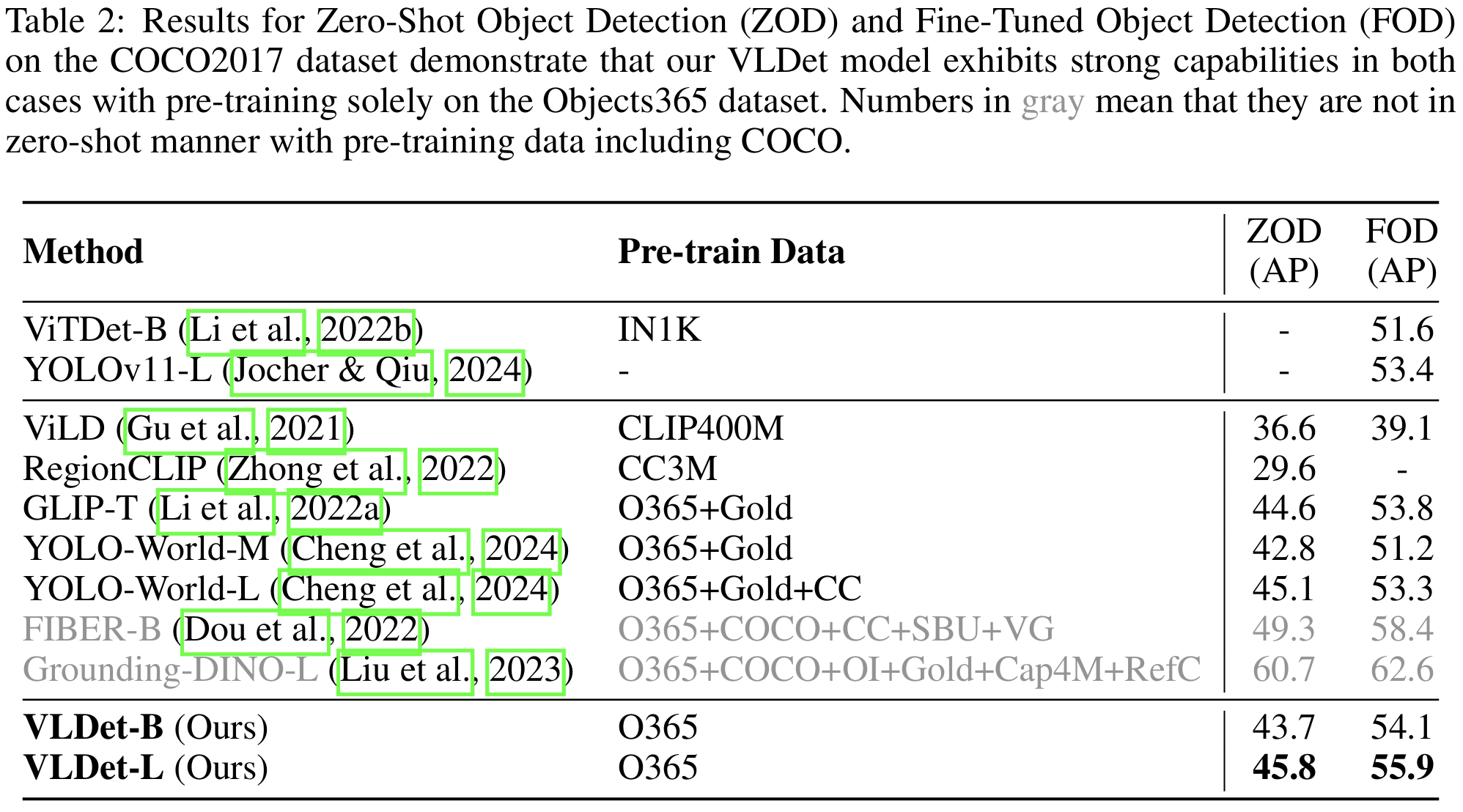
如表2所示,对于ZOD,VLDet-L达到45.8的AP,超越在相似或更大规模数据上预训练的基线方法,例如YOLO-World (Cheng et al., 2024),后者在CC3M上包含伪标注边界框并利用从定位数据集标题中提取的大量类别集。这证明了我们框架的有效性,该框架将CLIP中预对齐的图像和文本编码器与丰富的视觉-语言语义空间适配,并集成了更稳健的视觉-语言对齐策略。VLDet效率更高,引入层仅需221 GLOPs,而GLIP (Li et al., 2022a) 中的VLDyHead需要407 GLOPs。此外,对于FOD,VLDet模型也表现出优越性能,在5个epoch内微调后达到55.9的AP。这不仅超越了开放世界目标检测器,也超越了最先进传统目标检测器YOLOv11 (Jocher & Qiu, 2024)。我们还包含了FIBER-B (Dou et al., 2022) 和Grounding-DINO-L (Liu et al., 2023) 的结果,它们报告了优异的零样本性能。然而,它们在显著更大规模的数据集上预训练,甚至包含COCO(因此不严格符合零样本推理)。
4.3 消融实验
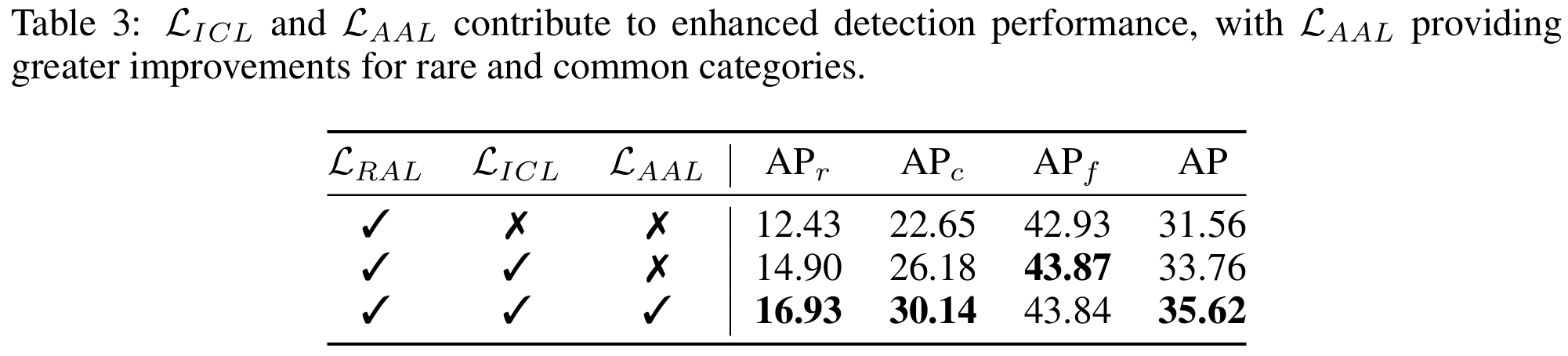
多层次对齐损失。 在表3中,我们展示了VLDet-B在LVIS数据集上针对开放词汇目标检测(OVD)使用不同损失的微调结果。我们发现,我们引入的图像级损失 LICL\mathcal{L}{ICL}LICL 和锚点-文本二元对齐损失 LAAL\mathcal{L}{AAL}LAAL 不仅能增强全部类别的整体AP,也能提升新类别的AP。这些结果证明多层次损失对视觉-语言对齐有益。具体而言,小批量图像对比损失将LVIS数据集新类别的AP从12.43提升至14.90(提升2.47),然后SigRPN进一步将其提升至16.93(提升2.03)。此外,全部类别的整体AP也从31.56提升至35.62。
重要的是,借助SigRPN和 LAAL\mathcal{L}_{AAL}LAAL,我们观察到频繁类别的AP保持一致,而稀有和常见类别的AP显著增加。值得注意的是,我们的训练数据不包含稀有类别,这凸显了SigRPN通过使RPN能够利用视觉-语言多模态嵌入空间对背景和任何类别的物体进行二元区分,从而泛化到新类别的卓越能力。
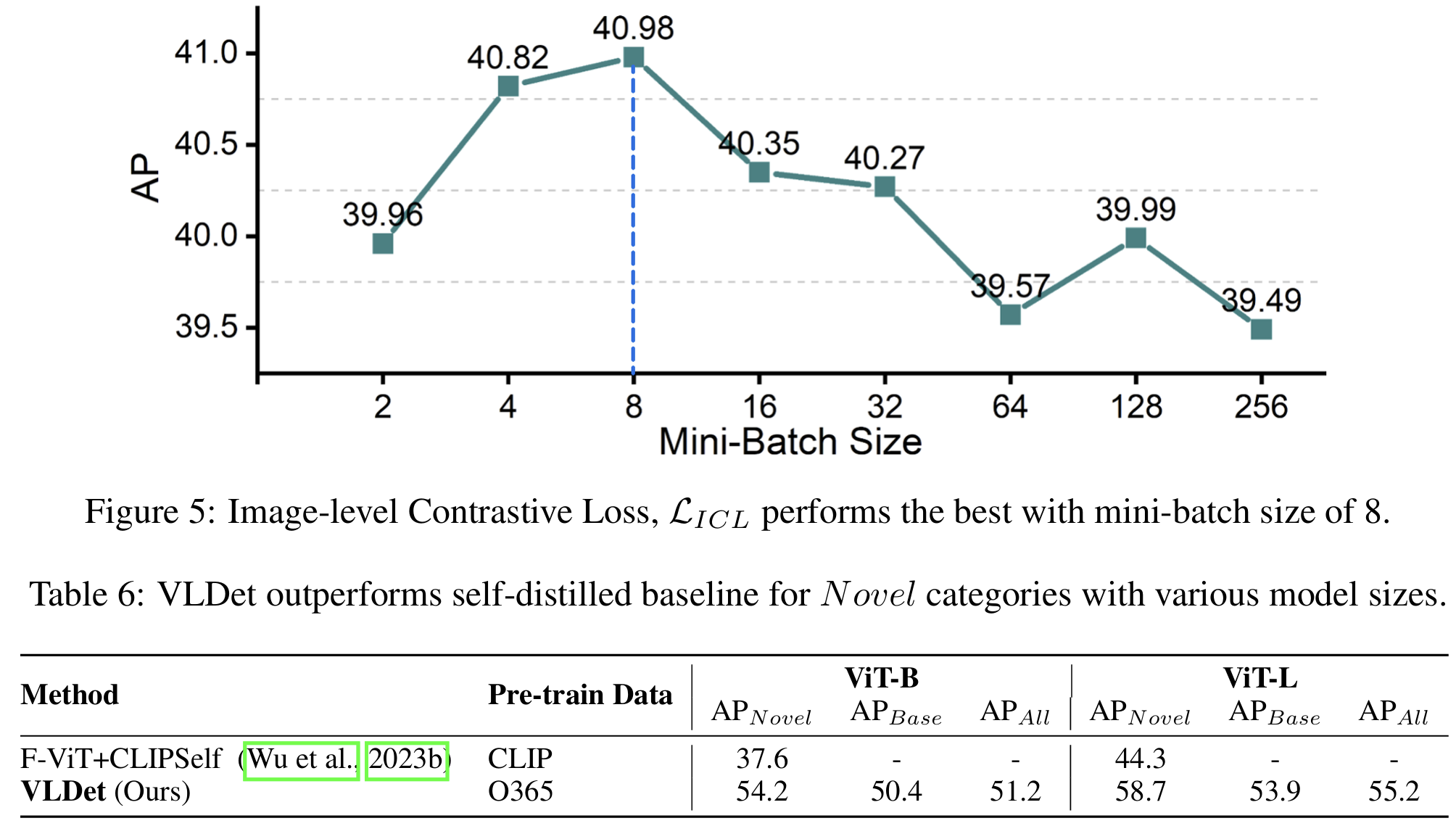
我们比较了VLDet-B在标准目标检测任务中使用COCO2017数据集从头训练的不同变体性能,使用不同小批量大小平衡图像级视觉-语言对齐与最终检测精度。我们发现小批量大小为8时性能最佳,达到40.98的AP。详细结果见附录B。
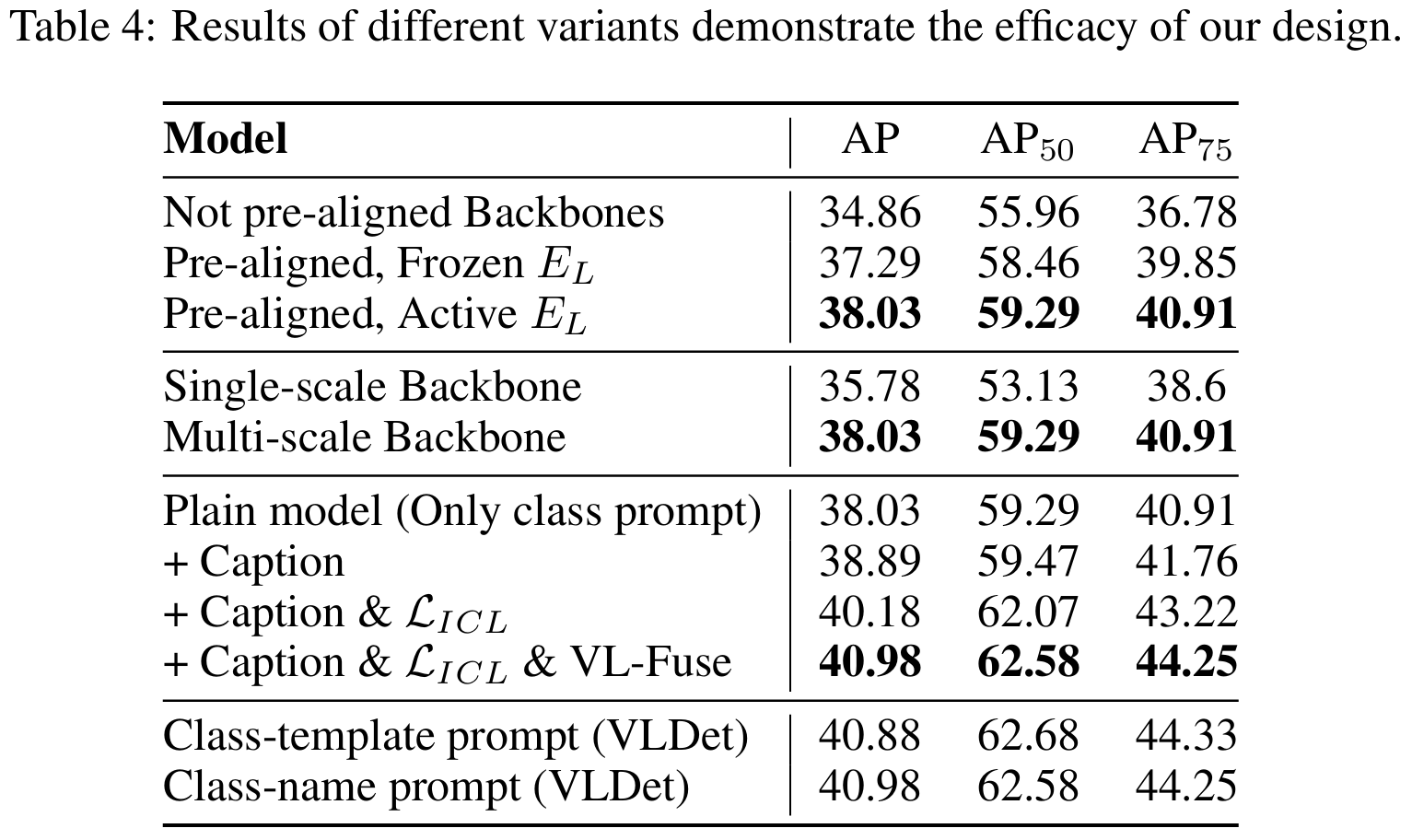
VL-Encoder的具体设计。 本节通过在COCO2017数据集上从头训练VLDet-B进行传统目标检测,详细说明VL-Encoder的设计。首先,我们将CLIP中ViT-B/16的预对齐文本编码器替换为ViT-B/32,同时保留ViT-B/16作为图像编码器。我们观察到预对齐主干网络即使冻结也提供显著更高的AP,凸显了继承CLIP中丰富预对齐语义信息的优越性。随后,我们发现采用VL-PUB的多尺度主干网络(而非单尺度模型)将AP从35.78提升至38.03。这证明金字塔特征通过提供更丰富的空间信息增强了检测精度。此外,通过比较有无标题训练的模型,我们发现结合类别提示使用标题提供额外上下文信息,将AP从38.03提升至38.89。此外,我们发现添加 LICL\mathcal{L}_{ICL}LICL 将AP从38.89提升至40.18,VL-Fuse层进一步将其提升至40.98。最后,我们尝试了先前工作 (Radford et al., 2021) 中的文本提示模板,例如"一张{label}的照片",但未观察到性能增益。该方法相比使用纯类别名称(即COCO上仅5个token)需要更多token,引入额外计算成本。因此,我们设计类别提示使用纯类别名称。
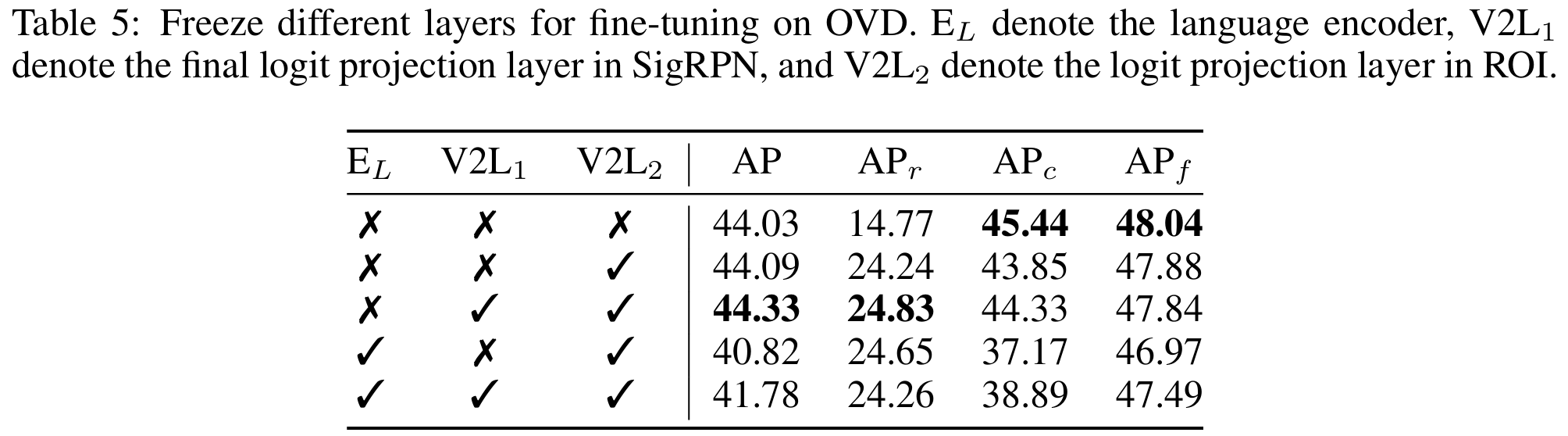
微调策略。 对于在COCO2017或LVIS上微调OVD的预训练模型,冻结视觉投影层(即V2L)(Zareian et al., 2021) 至关重要。若不执行此步骤,模型容易过拟合基础类别,导致新类别性能显著下降。如表5所示,当不冻结任何层时,基础类别(即 APc\mathrm{AP}_cAPc 和 APf\mathrm{AP}_fAPf)上的AP保持较高,但 APr\mathrm{AP}_rAPr 因过拟合而显著偏低。我们还观察到冻结语言主干可能导致一些精度损失。最优微调策略是冻结两个V2L层。
5 结论
我们成功将CLIP中具有广泛视觉-语言潜在空间的预对齐图像和文本编码器扩展到新颖的OVD框架------视觉-语言检测(VLDet)中。VLDet在视觉和语言特征融合后保留特征金字塔结构,以增强空间信号。我们进一步引入三种对比损失以实现多层次细粒度视觉-语言对齐,从而在OVD场景中获得卓越检测性能。VLDet在COCO2017上将新类别的AP显著提升27.6%,在LVIS上提升6.9%,并在仅在Objects365上预训练的情况下超越零样本目标检测基线方法。
附录
A 双向交叉注意力
双向交叉注意力广泛用于视觉-语言特征融合 (Li et al., 2022a; Liu et al., 2023)。具体而言,该机制将一种模态视为Query,另一种视为Key/Value。这在两个方向发生:
-
视觉到语言 :视觉特征关注语言特征以融入语义上下文。
vout=v+MHCA(Q=vWqv,K=lWkl,V=lWvl)\boldsymbol{v}_{out} = \boldsymbol{v} + \mathrm{MHCA}(\boldsymbol{Q}=\boldsymbol{v}\boldsymbol{W}_q^v, \boldsymbol{K}=\boldsymbol{l}\boldsymbol{W}_k^l, \boldsymbol{V}=\boldsymbol{l}\boldsymbol{W}_v^l)vout=v+MHCA(Q=vWqv,K=lWkl,V=lWvl) -
语言到视觉 :语言特征关注视觉特征以将文本锚定在特定图像内容中。
lout=l+MHCA(Q=lWql,K=vWkv,V=vWvv)\boldsymbol{l}_{out} = \boldsymbol{l} + \mathrm{MHCA}(\boldsymbol{Q}=\boldsymbol{l}\boldsymbol{W}_q^l, \boldsymbol{K}=\boldsymbol{v}\boldsymbol{W}_k^v, \boldsymbol{V}=\boldsymbol{v}\boldsymbol{W}_v^v)lout=l+MHCA(Q=lWql,K=vWkv,V=vWvv)
其中 W\boldsymbol{W}W 项为可学习投影矩阵,MHCA表示多头交叉注意力。该机制应用于单尺度特征的公式(2)和多尺度特征的公式(3)。
B 小批量大小探索
尽管先前工作(如CLIP)建议大批次对对比学习效果更好,但它们可能主导训练过程并降低最终检测性能。
为平衡图像级和区域级视觉-语言对齐,我们探索了一系列小批量大小。实验表明批次大小为8时性能最佳,如图5所示。
C 与自蒸馏基线的比较
在正文部分,我们的比较主要集中在使用ResNet作为视觉主干网络并通过知识蒸馏从CLIP等大型视觉-语言模型转移视觉-语言知识的基线方法上。
此处,我们提供与另一种同样直接利用预对齐视觉-语言模型中Vision Transformer(ViT)的最先进方法------CLIPSelf (Wu et al., 2023b) 的关键比较。CLIPSelf采用自蒸馏技术来优化CLIP ViT的密集特征图,使其更适用于密集预测任务中的定位。该方法使得ViT主干网络能够直接用于开放词汇目标检测(OVD)。
如表6所示,VLDet在COCO新类别基准测试中,无论是采用ViT-B还是ViT-L作为视觉主干网络,均显著优于CLIPSelf。这种持续优越的性能进一步验证了我们框架的有效性和鲁棒性------通过多层次细粒度对比损失将预对齐视觉编码器适配到OVD检测器中。