多智能体新范式:当量子计算遇见社交博弈
开篇导读
当前多智能体研究正面临两大瓶颈:复杂环境下的探索效率与团队协作中的"平庸化"困境。第一篇论文创新性地引入量子计算,为高维动作空间提供"量子罗盘",大幅提升MARL的收敛速度;第二篇则通过自博弈对话,深刻剖析了为何团队协作反而不如专家个体的机制。这两项研究一个从计算底层突破,一个从社交逻辑反思,共同勾勒出下一代智能系统的进化方向,非常值得技术人深读。
- 论文1《Sign In | Research Communities by Springer Nature》:结合变分量子优化与经典策略优化,利用量子计算优势解决高维动作空间探索难题;引入经典控制理论保障系统稳定性;支持异构智能体团队的大规模协调;在收敛速度、奖励积累效率及政策多样性方面均表现优异。
- 论文2《One Model, All Roles: Multi-Turn, Multi-Agent Self-Play Reinforcement Learning for Conversational Social Intelligence》:单一模型同时扮演对话中所有参与者;将自博弈从围棋等结构化游戏成功扩展至群组对话;低成本涌现出精细的社交智能(如同理心);支持可变数量的参与者以模拟多样化场景。
论文1:Sign In | Research Communities by Springer Nature
基本信息
-
资讯条目:1️⃣ Q-CMAPO:量子-经典框架平衡MARL中的探索与利用 ⭐
-
发表来源:generic_meta
这篇论文在解决什么难题
MARL 核心挑战: 探索 - 利用权衡是强化学习的基础问题,在多智能体场景中因智能体间交互、环境部分可观测 / 非平稳性进一步复杂化;经典方法(ε- 贪心、UCB、汤普森采样)在高维、连续动作空间或智能体强耦合环境中效率低下。
量子优化的潜力: 量子算法(QAOA、量子蒙特卡洛)利用叠加、纠缠特性,能更高效探索解空间,但量子优化与 MARL 的融合仍处于起步阶段,面临噪声敏感、硬件依赖、落地难等问题。
研究问题: 对比经典与量子优化在 MARL 探索 - 利用权衡中的效果,构建融合二者优势的统一框架,解决量子优化落地 MARL 的实际挑战。
它最有价值的创新点
创新类型:跨模态量子-经典混合架构创新。本论文提出了Q-CMAPO框架,这是将变分量子优化技术深度融入经典多智能体策略优化的开创性工作。它不单纯依赖经典计算,而是设计了一种量子启发式的组合搜索机制来指导智能体的探索行为。
通俗解释:想象一群人在一个巨大的迷宫中寻找宝藏,传统方法可能像大家各自盲目乱撞或仅凭经验走路;而Q-CMAPO就像是给了这群人一个"量子罗盘",利用量子叠加态能瞬间同时查看多条路径的概率,帮助他们快速锁定宝藏方向,同时又配上了"经典稳定器",确保大家不会因为跑得太快而摔倒,从而既快又稳地到达终点。
核心方法详解
Q-CMAPO(Quantum-Classical Multi-agent Policy Optimization,量子-经典多智能体策略优化)是一种融合量子优化 和经典多智能体强化学习(MARL) 的混合框架,核心解决多智能体系统中探索-利用权衡 的核心难题(即智能体如何平衡"尝试新策略探索环境"和"使用已知策略获取奖励"),同时依托集中式训练-分布式执行(CTDE) 范式,让多个智能体既能协作学习,又能独立执行任务,适用于无人机协同、纳米机器人协作等实际场景。
该方法的核心思路是:用量子算法的叠加、纠缠特性提升高维空间的探索效率,用经典强化学习的鲁棒性保证实际执行的稳定性,通过数学公式定义目标、约束和更新规则,让量子和经典模块协同工作。
Q-CMAPO的所有设计都基于两个经典数学模型的扩展,这是理解后续公式的前提,就像盖房子的"地基":
多智能体的环境模型:随机博弈(Stochastic Game)
把多智能体所在的环境抽象成一个数学元组,定义为:
G=<N,S,{Ai}i∈N,P,{Ri}i∈N,γ>G=<N, S, \{A_i\}{i \in N}, P, \{R_i\}{i \in N}, \gamma>G=<N,S,{Ai}i∈N,P,{Ri}i∈N,γ>
通俗解析:
- NNN:智能体的数量(比如5架无人机、100个纳米机器人);
- SSS:环境的状态空间(比如无人机的位置、高度、周围环境的烟雾浓度,所有可能的环境情况集合);
- AiA_iAi:第iii个智能体的动作空间(比如无人机可以向上飞、向左飞、悬停,单个智能体能做的所有动作);
- PPP:状态转移概率(智能体执行动作后,环境从一个状态变成另一个状态的概率,比如无人机向左飞后,从位置A到位置B的概率);
- RiR_iRi:第iii个智能体的奖励函数(智能体做对动作得到的"分数",比如无人机检测到火灾得10分,撞树扣5分);
- γ\gammaγ:折扣因子 (取值0~1,代表"未来奖励的重要性",比如γ=0.99\gamma=0.99γ=0.99表示100步后的奖励和现在的奖励几乎同等重要,鼓励智能体做长期规划)。
这个模型的核心是:所有智能体同时执行动作,环境根据动作发生状态转移,每个智能体根据转移后的状态获得各自的奖励,完美贴合无人机、机器人等多智能体协同的实际场景。
单智能体基础模型:马尔可夫决策过程(MDP)
单智能体的环境模型是多智能体随机博弈的简化版,定义为:
M=<S,A,P,R>M=<S, A, P, R>M=<S,A,P,R>
通俗解析 :去掉了智能体数量NNN和分智能体的动作/奖励,描述"单个智能体与环境互动"的过程,Q-CMAPO会把这个模型扩展到多智能体,再结合平均场控制处理大规模智能体(比如100个纳米机器人)的场景。
Q-CMAPO的最大创新是量子执行者+经典评价者 的混合架构,简单说就是:让量子模块负责"聪明地探索",经典模块负责"客观地打分",二者通过数学规则联动更新。
量子执行者:用量子电路表示智能体的策略
策略πi\pi_iπi是智能体的"决策规则",表示"在某个环境状态sss下,智能体选择某个动作aaa的概率",经典MARL中策略通常用神经网络表示,而Q-CMAPO中用参数化量子电路(PQC) 表示量子策略πq\pi_qπq:
πq:S→Us(θ)\pi_q: S \to U_s(\theta)πq:S→Us(θ)
通俗解析:
- 智能体先把自己观察到的环境状态sss(比如无人机的局部观测:位置、烟雾浓度)编码成量子态 ∣ψs>|\psi_s>∣ψs>;
- 这个量子态通过带可调参数θ\thetaθ的量子电路Us(θ)U_s(\theta)Us(θ)演化(量子电路由量子门组成,类似经典电路的逻辑门);
- 最后对演化后的量子态做量子测量 ,测量的结果对应智能体的动作选择(比如测量结果0对应向左飞,1对应向上飞),量子的叠加性能让智能体同时"考虑"多个动作,大幅提升高维动作空间的探索效率。
其中,量子电路的核心是QAOA(量子近似优化算法),通过两个哈密顿量构建参数化量子态:
∣ψ(γ,β)>=∏l=1pe−iβlHMe−iγlHC∣ψ0>|\psi(\gamma, \beta)>=\prod_{l=1}^{p} e^{-i \beta_{l} H_{M}} e^{-i \gamma_{l} H_{C}}|\psi_0>∣ψ(γ,β)>=l=1∏pe−iβlHMe−iγlHC∣ψ0>
通俗解析:
- HCH_CHC:代价哈密顿量 (把"智能体的奖励目标"编码成量子物理量,比如检测到火灾的奖励越高,HCH_CHC的取值越优);
- HMH_MHM:混合哈密顿量(负责"打乱"量子态,让智能体探索更多可能的动作,类似经典强化学习的探索机制);
- γ,β\gamma, \betaγ,β:量子电路的可调参数(类似神经网络的权重,需要通过学习优化);
- ppp:量子电路的深度(层数越多,表达能力越强,计算量也越大);
- ∣ψ0>|\psi_0>∣ψ0>:初始量子态(比如所有量子比特都处于0态)。
经典评价者:用神经网络给量子策略"打分"
量子模块能探索出很多动作,但不知道哪个动作"更好",这时候需要经典集中式评价者(用深度神经网络实现)来评估:
评价者的核心是估计团队Q值 Qϕ(s,{ai})Q_{\phi}(s, \{a_i\})Qϕ(s,{ai})(ϕ\phiϕ是神经网络的参数),表示"所有智能体在状态sss下执行联合动作{ai}\{a_i\}{ai},未来能获得的累计奖励总和"。
通俗解析:
- 训练阶段,评价者能获取全局信息(所有智能体的状态、动作、奖励),相当于一个"上帝视角"的裁判;
- 它根据全局信息计算量子策略的"好坏",并把这个评价结果反馈给量子模块,指导量子电路参数θ\thetaθ的优化;
- 执行阶段,评价者"下线",智能体仅依靠量子模块和局部观测独立决策,保证分布式执行的自主性。
Q-CMAPO的学习目标是优化所有智能体的联合策略 ,通过数学公式定义目标函数,把"奖励最大化、探索-利用平衡、智能体协作"三个需求全部融入,核心公式有两个:个体目标函数 和团队目标函数 ,团队目标函数更适用于无人机协同、纳米机器人协作等全合作场景,也是本文的核心:
团队目标函数(核心)
L({πi}i∈N)=∑i∈NEs∼dπ,ai∼πi(⋅∣oi)Ri(s,ai)−λ⋅KL(πi(⋅∣oi)∥πiref(⋅∣oi))+η⋅H(πi(⋅∣oi))\mathcal{L}\left(\{\pi_{i}\}{i \in \mathcal{N}}\right)=\sum{i \in \mathcal{N}} \mathbb{E}{s \sim d^{\pi}, a{i} \sim \pi_{i}\left(\cdot | o_{i}\right)}\leftR_{i}\\left(s, a_{i}\\right)-\\lambda \\cdot KL\\left(\\pi_{i}\\left(\\cdot \| o_{i}\\right) \\\| \\pi_{i}\^{ref}\\left(\\cdot \| o_{i}\\right)\\right)+\\eta \\cdot \\mathcal{H}\\left(\\pi_{i}\\left(\\cdot \| o_{i}\\right)\\right)\\rightL({πi}i∈N)=i∈N∑Es∼dπ,ai∼πi(⋅∣oi)Ri(s,ai)−λ⋅KL(πi(⋅∣oi)∥πiref(⋅∣oi))+η⋅H(πi(⋅∣oi))
通俗解析:
这个公式的核心是让所有智能体的累计奖励期望最大化,同时通过两个正则项平衡探索-利用,公式中各部分的含义:
- Es∼dπ,ai∼πi\mathbb{E}{s \sim d^{\pi}, a{i} \sim \pi_{i}}Es∼dπ,ai∼πi:数学期望 ,表示"在策略π\piπ下,对所有可能的环境状态sss和智能体动作aia_iai取平均值",因为多智能体环境有随机性,取平均能保证学习的稳定性;
- Ri(s,ai)R_{i}\left(s, a_{i}\right)Ri(s,ai):第iii个智能体的即时奖励,这是利用项,鼓励智能体选择能获得高奖励的已知动作;
- −λ⋅KL(πi∥πiref)-\lambda \cdot KL\left(\pi_{i} \| \pi_{i}^{ref}\right)−λ⋅KL(πi∥πiref):KL散度正则项 (λ\lambdaλ是可调系数,πiref\pi_{i}^{ref}πiref是参考策略,比如上一轮的策略),KL散度衡量两个策略的"差异程度",加这个项是为了防止策略更新太激进,避免智能体突然放弃所有已知策略,保证学习的稳定性;
- +η⋅H(πi)+\eta \cdot \mathcal{H}\left(\pi_{i}\right)+η⋅H(πi):熵正则项 (η\etaη是可调系数,H\mathcal{H}H是香农熵),熵越大表示策略的随机性越强,加这个项是为了鼓励探索,让智能体不要一直选同一个动作,尝试新的策略;
- oio_ioi:第iii个智能体的局部观测,保证执行阶段的分布式特性。
简化的团队奖励目标(训练阶段用)
训练阶段为了强化智能体的协作,会用全局的团队奖励替代个体奖励,公式更简洁:
Lteam=Eτ∼π∑t=0TγtRteam(st,at)\mathcal{L}{team }=\mathbb{E}{\tau \sim \pi}\left\\sum_{t=0}\^{T} \\gamma\^{t} R_{team}\\left(s_{t}, a_{t}\\right)\\rightLteam=Eτ∼πt=0∑TγtRteam(st,at)
通俗解析:
- τ\tauτ:智能体的轨迹(从初始状态到结束状态的一系列"状态-动作-奖励");
- RteamR_{team}Rteam:团队总奖励(比如所有无人机检测到的火灾总数对应的奖励);
- ∑t=0Tγt\sum_{t=0}^{T} \gamma^{t}∑t=0Tγt:累计折扣奖励 ,把每一步的团队奖励按折扣因子γ\gammaγ累加,代表未来的总奖励。
这个目标函数的核心是:让所有智能体朝着"团队总奖励最大化"的方向学习,而不是各自为战,解决多智能体协作的核心难题。
Q-CMAPO的执行流程遵循集中式训练-分布式执行(CTDE) 范式,分为训练阶段 和执行阶段,训练阶段量子和经典模块协同工作,执行阶段仅量子模块独立运行,核心流程用伪代码和通俗语言结合讲解,关键步骤对应数学公式的更新:
Q-CMAPO核心执行流程
输入 :量子策略初始参数{θi(0)}\{\theta_i^{(0)}\}{θi(0)}、经典评价者初始参数ϕ(0)\phi^{(0)}ϕ(0)、学习率αθ/αϕ\alpha_\theta/\alpha_\phiαθ/αϕ、参考策略πref\pi_{ref}πref、图拉普拉斯矩阵LLL(智能体通信拓扑)、单轮训练步数TTT
输出 :训练好的量子策略参数{θi}\{\theta_i\}{θi}
- 训练循环(按轮数迭代) :for训练轮数 = 1 to M- 环境初始化 :重置环境,得到初始全局状态s0s_0s0
- 单轮交互(智能体与环境互动) :for 步数 t = 0 to T-1
- 分布式量子决策 :所有智能体并行执行- 编码局部观测oito_i^toit为量子态∣ψit>|\psi_i^t>∣ψit>;
- 通过量子测量采样动作ait∼πi(a∣oit;θi)a_i^t \sim \pi_i(a|o_i^t; \theta_i)ait∼πi(a∣oit;θi);
- 环境交互 :执行所有智能体的联合动作ata^tat,得到下一个状态st+1s_{t+1}st+1和每个智能体的奖励ritr_i^trit;
- 存储轨迹 :把(st,at,{rit},st+1)(s_t, a^t, \{r_i^t\}, s_{t+1})(st,at,{rit},st+1)存入经验回放池(类似"错题本",用来后续学习);
- 分布式量子决策 :所有智能体并行执行- 编码局部观测oito_i^toit为量子态∣ψit>|\psi_i^t>∣ψit>;
- 集中式学习更新 :
- 采样轨迹:从经验回放池随机采样一批轨迹(避免过拟合);
- 量子策略更新 :通过参数偏移规则 计算量子策略梯度∇θiL\nabla_{\theta_i}\mathcal{L}∇θiL,更新量子参数:θi←θi−αθ∇θiL\theta_i \leftarrow \theta_i - \alpha_\theta \nabla_{\theta_i}\mathcal{L}θi←θi−αθ∇θiL;
- ✅ 核心公式:∇θiL=∇θiERi−λ⋅KL+η⋅H\nabla_{\theta_i}\mathcal{L} = \nabla_{\theta_i} \mathbb{E}R_i - \\lambda \\cdot KL + \\eta \\cdot \\mathcal{H}∇θiL=∇θiERi−λ⋅KL+η⋅H
- 经典评价者更新 :用时间差分(TD)学习 更新评价者参数,最小化预测Q值和真实Q值的误差:ϕ←ϕ−αϕ∇ϕ∥Qϕ(st,at)−yt∥2\phi \leftarrow \phi - \alpha_\phi \nabla_\phi \|Q_\phi(s_t, a_t) - y_t\|^2ϕ←ϕ−αϕ∇ϕ∥Qϕ(st,at)−yt∥2;- ✅ 真实Q值yt=rt+γ⋅Qϕ(st+1,at+1)y_t = r_t + \gamma \cdot Q_\phi(s_{t+1}, a_{t+1})yt=rt+γ⋅Qϕ(st+1,at+1)(贝尔曼方程,核心是"现在的奖励+未来的折扣奖励");
- 智能体协同 :通过图拉普拉斯矩阵实现智能体间的信息共识(比如无人机互相传递位置信息),保证协作;
- 单轮交互(智能体与环境互动) :for 步数 t = 0 to T-1
- 训练结束:输出训练好的量子策略参数,部署到每个智能体上。
通俗总结执行流程:
- 试错:多个智能体用量子模块做决策,和环境互动,记录每一步的"状态-动作-奖励",相当于"做实验记笔记";
- 补课:集中起来用经典评价者给"笔记"打分,计算量子策略的好坏,更新量子模块的参数,相当于"老师批改作业,学生订正";
- 协同:智能体之间通过通信共享少量信息,保证动作协调,避免互相干扰;
- 落地:训练完成后,智能体扔掉"老师(经典评价者)",只靠自己的量子模块独立做决策,适应实际场景的分布式需求。
Q-CMAPO给出了三个核心理论保证,通俗理解就是"证明这个方法能学出来、学的稳、不会一直犯错误":
探索-利用权衡有界性(学的"有度")
引理 :若β>0\beta>0β>0,KL散度项KL(π(⋅∣s)∥π0(⋅))KL(\pi(\cdot|s) \| \pi_0(\cdot))KL(π(⋅∣s)∥π0(⋅))会限制策略与先验策略π0\pi_0π0的偏离,保证未探索动作的最小探索概率为e−βH(π0)e^{-\beta H(\pi_0)}e−βH(π0)。
通俗解析:智能体的探索不会无限制,也不会完全不探索,KL散度像一个"刹车",让探索和利用保持平衡,不会太激进也不会太保守。
量子策略收敛性(能学出来)
命题 :若QAOA电路深度ppp固定,经典学习率αt\alpha_tαt随训练步数递减(比如αt=1/t\alpha_t = 1/tαt=1/t),则量子策略πq(t)\pi_q^{(t)}πq(t)以概率1收敛到局部最优解。
通俗解析:只要训练的步数足够多,量子策略的参数会逐渐稳定到一个最优值,不会一直震荡,保证学习能有结果。
无遗憾保证(学的"越来越好")
定理 :若奖励函数RiR_iRi有界且平滑(利普希茨连续),则平均遗憾1T∑t=1TRi(π∗)−Ri(π(t))→0\frac{1}{T} \sum_{t=1}^T R_i(\\pi_\*) - R_i(\\pi\^{(t)}) \to 0T1∑t=1TRi(π∗)−Ri(π(t))→0(T→∞T \to \inftyT→∞)。
通俗解析:
- 遗憾:智能体实际获得的奖励Ri(π(t))R_i(\pi^{(t)})Ri(π(t))和最优策略能获得的奖励Ri(π∗)R_i(\pi_*)Ri(π∗)的差值,代表"本可以得到却没得到的分数";
- 无遗憾:随着训练步数增加,平均遗憾会趋近于0,说明智能体的策略会越来越接近最优策略,不会一直犯低级错误。
均衡鲁棒性(学的"稳")
推论 :在对抗性扰动下(比如环境有噪声、传感器出误差),Q-CMAPO的混合策略能保持纳什均衡的稳定性。
通俗解析:即使环境有干扰,智能体的协作策略也不会崩溃,能保持稳定的性能,这对实际场景(比如无人机遇到强风、传感器有噪声)至关重要。
方法的核心优势:
- 探索效率高:量子的叠加性让智能体在高维动作空间(比如无人机的连续飞行动作)中同时探索多个策略,比经典MARL快得多;
- 执行鲁棒性强:经典评价者的集中式训练保证了策略的稳定性,分布式执行适配实际场景的自主需求;
- 协作性好:通过团队目标函数和图共识算法,让智能体朝着共同目标学习,避免各自为战;
- 数学基础扎实:从随机博弈、MDP到量子QAOA,所有设计都有数学支撑,且证明了收敛性、稳定性,不是"拍脑袋"的设计;
- 能落地:在无人机火灾检测、纳米机器人药物递送等实际场景中验证,计算复杂度与经典MARL相当,能在普通硬件(GPU)+量子仿真平台上运行。
实验与应用价值
实验设置涉及多智能体协作任务环境,配置了异构智能体团队并设定部分可观测条件。对比对象为传统的经典多智能体强化学习算法(如MADDPG等)。结果表明,Q-CMAPO在训练过程中的损失下降速度显著快于对比算法,收敛所需的步数大幅减少;在奖励获取方面,其累积奖励曲线上升更快且最终收益更高;在策略分布上,展现了比基线方法更丰富的动作多样性。
| 观察维度 | 设置/指标 | 结果/结论 |
|---|---|---|
| 收敛性能 | 训练步数与时间成本 | 相比经典算法收敛速度显著提升,训练效率更高;任务效率 |
| 对比基线 | 单专家 vs 多智能体团队 | 观察团队是否真正超过最优个体 |
| 结果趋势 | 性能与鲁棒性指标 | 实验设置涉及多智能体协作任务环境,配置了异构智能体团队并设定部分可观测条... |
| 价值维度 | 解读 |
|---|---|
| 领域贡献 | 首次成功将变分量子优化与经典控制理论结合应用于多智能体强化学习,为解决高维动作空间下的探索效率与收敛稳定性矛盾提供了新的范式,验证了量子计算在复杂人工智能协作任务中的实用价值。 |
| 通俗理解 | 这是一种让多个机器人或虚拟角色合作的新方法。它利用"量子计算"这个超级工具来帮忙做决策,让团队能像开了挂一样迅速学会如何配合。它既能让团队大胆尝试新方法(探索),又能保证团队不乱套(利用),从而更聪明、更稳定地完成任务。 |
| 与日常生活关系 | 就像组织一支分工不同的足球队(异构智能体),传统的教练可能只能凭经验安排战术;而这个新方法就像给教练配备了一个能瞬间计算无数种战术组合的量子AI助手,不仅能让球员配合默契(稳定性),还能在比赛中出其不意(探索多样性),赢得比赛的概率大大增加。 |
论文2:One Model, All Roles: Multi-Turn, Multi-Agent Self-Play Reinforcement Learning for Conversational Social Intelligence
基本信息
-
资讯条目:2️⃣ OMAR:One Model, All Roles - 多智能体自博弈对话社交智能 ⭐⭐
-
发表来源:arXiv
这篇论文在解决什么难题
本文由微软、宾夕法尼亚大学等机构研究者提出,核心是打造OMAR(One Model, All Roles) 强化学习框架,让单一 AI 模型通过多轮多智能体对话自博弈发展社交智能,突破传统训练范式在动态社交交互学习中的局限,为 AI 群体对话社交智能研究提供了新方向。
新一代 AI 需从被动辅助转向社会参与,具备与不同目标、角色的人类沟通协作的社交智能,但现有训练范式存在明显不足。
行为克隆是静态的,仅模仿固定演示;主流 LLM 强化学习方法聚焦单轮优化,无法让模型在多轮多智能体环境中动态交互并追求长期社交目标。
对话的开放性、语言令牌的超大动作空间,以及多角色社交交互的复杂性,让多智能体建模和训练难度大幅提升。
它最有价值的创新点
提出适用于多轮多智能体对话自博弈的通用强化学习范式,实现单模型模拟多角色社交交互。
设计分层优势估计方法,包含轮次级和令牌级双信号,解决长程交互中的训练稳定性问题。
验证动态社交交互训练能让模型习得社交智能,且竞争场景下的训练反而能激发协作行为。
无需人类直接监督,让模型涌现出共情、说服等细粒度的社交智能行为。
识别多轮多智能体强化学习中的核心挑战(奖励黑客),并提出轮次级质量过滤的缓解方案。
核心方法详解
让一个大模型,自己跟自己聊天,而且同时扮演对话里的所有人,练出社交智能。
传统做法:
- 只学单轮回答
- 只模仿人类对话
- 不会长期博弈、不会共情、不会说服
OMAR 做法:
- 一个模型 = 所有人
- 多轮对话、互相博弈、互相合作
- 用强化学习自己教自己
- 最后自动长出:共情、妥协、说服、策略、合作
核心思想:一个模型扮演所有角色
公式怎么写?
yit=fθ(ct,pi)y_i^t = f_\theta(c^t, p_i)yit=fθ(ct,pi)
通俗翻译:
- fθf_\thetafθ:就是同一个大模型
- ctc^tct:到第 t 轮为止的全部聊天记录
- pip_ipi:第 i 个人的角色、人设、目标
- yity_i^tyit:模型假装成第 i 个人说出来的话
也就是说:模型每次说话,只换"人设提示",不换模型本身。
聊天怎么推进?
ct+1=ct⊕{y1t,y2t,...,ynt}c^{t+1} = c^t \oplus \{y_1^t, y_2^t, \dots, y_n^t\}ct+1=ct⊕{y1t,y2t,...,ynt}
通俗翻译:
- 第 t 轮,所有人同时说话
- 把所有人说的话拼进历史
- 变成下一轮的上下文 ct+1c^{t+1}ct+1
这就是:单模型模拟多人多轮对话。
最关键创新:分层优势估计(解决长对话训练崩溃)
普通 PPO 一用到长对话就崩:
- 奖励只在最后给
- 一反向传播,梯度乱飘
- 模型越训越烂
OMAR 提出:把优势分成两层算:轮次级 + 令牌级
第一层:轮次级优势(Turn-level)
把一整轮对话当成一个动作。
公式:
Atturn=rt+γVt+1turn−VtturnA_t^\text{turn} = r_t + \gamma V_{t+1}^\text{turn} - V_t^\text{turn}Atturn=rt+γVt+1turn−Vtturn
通俗翻译:
- 每一轮结束,给这一轮估个价值
- 用 GAE 把未来奖励往回传
- 得到:这一轮到底有多重要
作用:让模型知道:哪几轮对话是关键胜负手。
第二层:令牌级优势(Token-level)
把轮次级优势当成这一轮的总奖励,再往每一个词分摊。
公式:
Aktoken=rkpseudo+γVk+1token−VktokenA_k^\text{token} = r_k^\text{pseudo} + \gamma V_{k+1}^\text{token} - V_k^\text{token}Aktoken=rkpseudo+γVk+1token−Vktoken
其中:
rkpseudo=Atturnr_k^\text{pseudo} = A_t^\text{turn}rkpseudo=Atturn
通俗翻译:
- 这一轮整体好 → 里面每个词都加分
- 这一轮整体烂 → 里面每个词都减分
作用:既稳定,又能精细到每一句话、每一个词。
训练完整流程
前向:聊天
同一个模型,轮流/同时扮演:
- 买家 / 卖家
- 狼人 / 村民
- 朋友 / 对手
生成一整段多轮对话。
打分
对话结束后打分:
- 目标有没有完成
- 有没有说服别人
- 有没有妥协合作
- 狼人有没有赢
反向:分层学习
- 先算每一轮好不好
- 再把奖励摊到每一个词
- 用 PPO 更稳健地更新模型
L=Emin(r(θ)A, clip(r(θ),1−ϵ,1+ϵ)A)\mathcal{L} = \mathbb{E}\Big\\min\\big(r(\\theta)A,\\ \\text{clip}(r(\\theta),1-\\epsilon,1+\\epsilon)A\\big)\\BigL=Emin(r(θ)A, clip(r(θ),1−ϵ,1+ϵ)A)
这就是标准PPO,保证训练不乱飞。
方法流程图与图解:
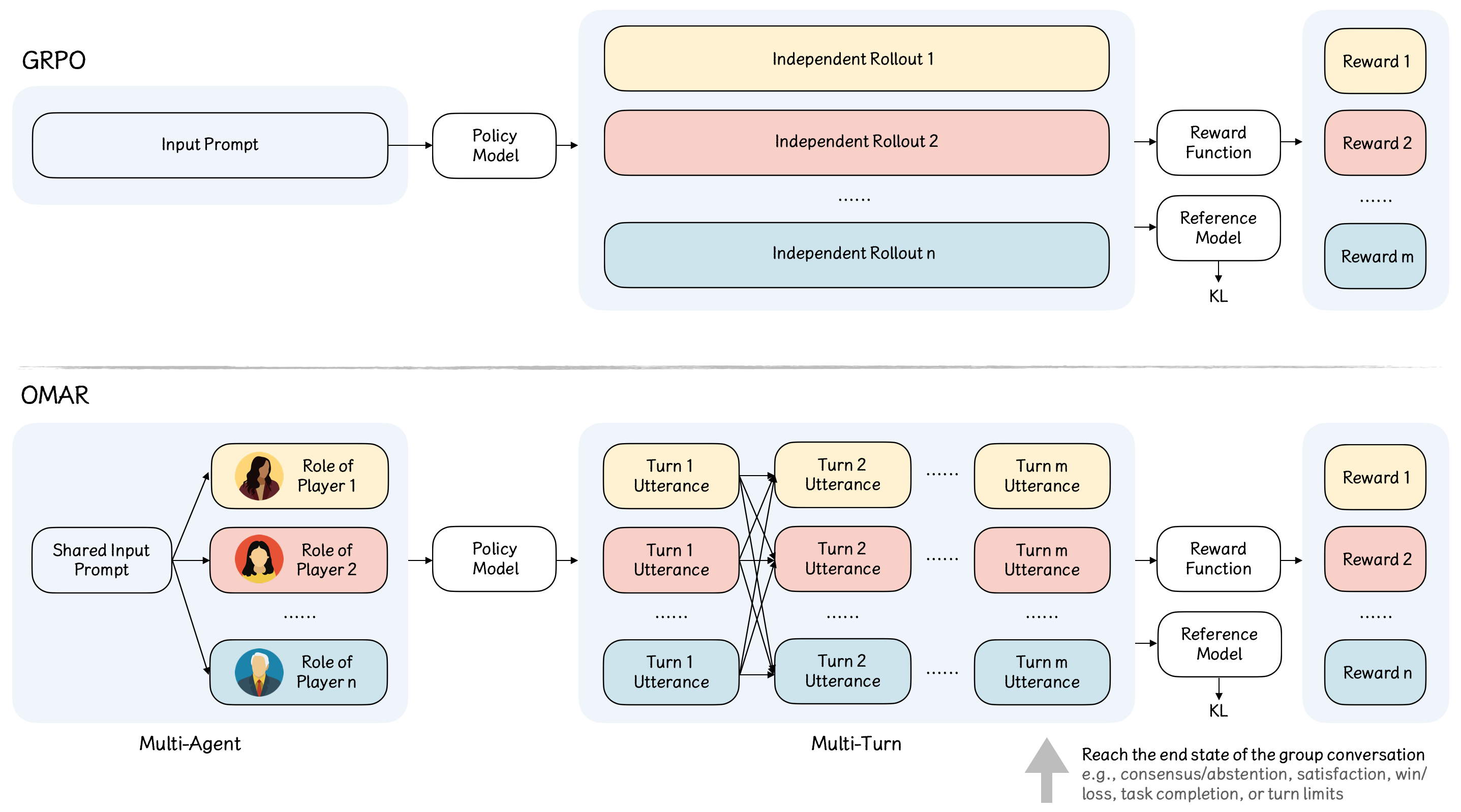
- 图1:标准GRPO框架(顶部)与提出的OMAR框架(底部)的比较。
- 图1解读:该图展示了标准GRPO与提出的OMAR框架对比。上方标准GRPO基于单一提示生成独立推演,下方OMAR则通过添加人格提示,让单个策略模型同时扮演多个参与者。图中关键在于观察对话历史如何在不同角色间聚合共享,以及最终基于环境结果分配奖励,从而实现通过自博弈学习复杂的社交智能。
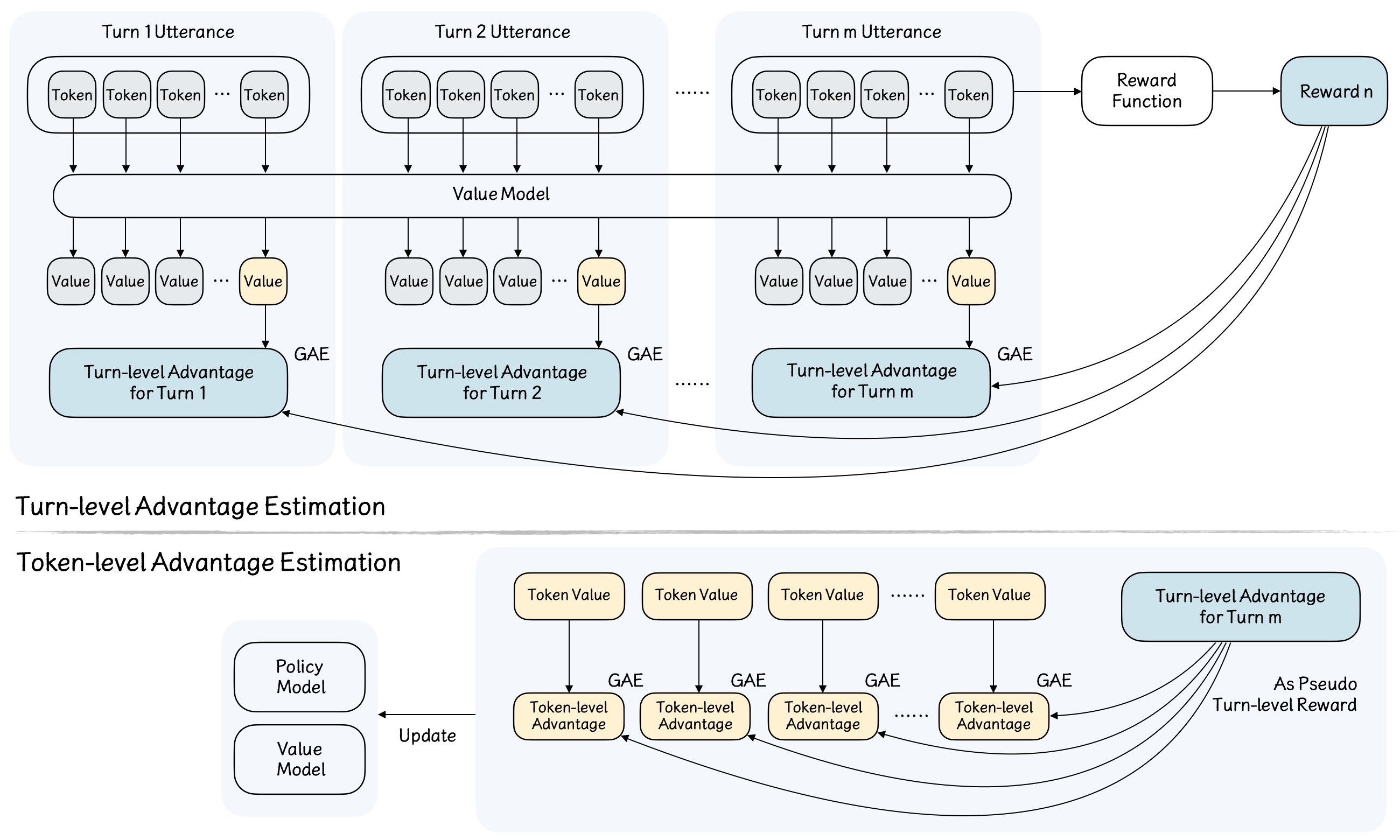
- 图2:用于多轮对话强化学习的分层优势估计。
- 图2解读:此图解释了OMAR如何通过分层优势估计解决长序列奖励传播的高方差问题。读者应关注分为两个阶段的计算流程:顶部深蓝色块利用最终奖励计算轮级优势;底部黄色块将其作为伪奖励,结合词元值计算最终词元优势。这种解耦设计使得模型能够更稳定、有效地在多轮对话中进行策略优化。
实验与应用价值
实验在SOTOPIA社交交互环境 和狼人杀策略游戏两大场景开展,分别验证目标导向对话和竞争场景下的社交智能习得效果,核心实验设置和结果如下:
(一)SOTOPIA社交环境实验
- 基础模型为Qwen-2.5-7B,基于火山引擎LLM强化学习工具训练,以GPT-5为评估裁判,从目标完成、可信度等7个维度打分并作为奖励。
- 设计竞技场评估方案:让训练模型与基础模型、SOTOPIA-RL训练模型分别进行100轮多轮对话,对比社交智能表现。
- 核心结果:
- 训练模型在SOTOPIA原有评估指标上持续优于基线模型;
- 在无训练监督的细粒度指标(妥协、说服、共情、战略承诺、互利)上提升更显著,验证了多轮多智能体强化学习的有效性;
- 即使角色目标对立,模型仍会主动寻求共识、部分目标达成,涌现协作行为。
(二)狼人杀竞争游戏实验
- 基础模型为Qwen-3-4B,以游戏胜负为简单奖励(胜方+1、负方0,早被淘汰者奖励打75折),模型同时扮演狼人、村民等所有角色。
- 核心结果:
- 狼人方胜率从55%提升至72%,高社交智能是存活和获胜的关键;
- 模型涌现出狼人身份隐藏、投票操纵、团队协作 ,以及村民保护神职、识别欺骗等社交行为,且存活玩家的这类行为占比远高于被淘汰玩家;
- 验证零和竞争场景下,模型为实现最终目标会主动发展协作策略。
OMAR框架成功将自博弈范式从围棋等结构化游戏拓展至自然语言群体对话,让单一模型通过多轮多智能体自博弈,在无需人类直接监督的情况下,涌现出共情、说服、妥协等细粒度社交智能;且在狼人杀这类零和竞争场景中,模型为实现最终目标,会自然激发协作行为,验证了该框架的有效性。
本研究是对话自博弈和社交智能AI的初步探索,为下一代能从动态经验中学习、在社会环境中进化的智能系统奠定了基础。
总结
这两篇研究预示着多智能体技术正在从"堆规模"转向"调机制"。Q-CMAPO展示了量子计算在解决复杂AI任务中的实用潜力,为未来大规模异构系统的落地提供了新算力思路;而对话智能的研究则警示我们,真正的协作不能止步于形式上的交流,更需深挖信息流动的断点。对普通读者而言,这不仅是技术进步,更是对团队协作本质的深刻洞察:高效的系统,既需要强大的个体算力,更需要不折损智慧的组织架构。