前言
在 Linux/Unix 的进程世界中,每个进程都拥有独立的地址空间,就像一个个彼此隔绝的 "孤岛"。而进程间通信(IPC,Inter-Process Communication)就是连接这些孤岛的 "桥梁",让进程之间能够实现数据传输、资源共享、事件通知和进程控制。管道作为 Unix 中最古老的 IPC 形式,是入门进程间通信的必经之路,而匿名管道更是管道通信的基础。本文将从进程间通信的基本概念出发,一步步拆解管道与匿名管道的原理、实现、读写规则和实战应用,用通俗的语言 + 硬核的代码,让你彻底吃透这一经典的 IPC 方式。下面就让我们正式开始吧!
目录
[一、进程间通信基础,为什么需要 IPC?](#一、进程间通信基础,为什么需要 IPC?)
[1.1 进程间通信的四大核心目的](#1.1 进程间通信的四大核心目的)
[1.2 进程间通信的发展与分类](#1.2 进程间通信的发展与分类)
[二、管道的核心认知,Unix 最古老的 IPC "桥梁"](#二、管道的核心认知,Unix 最古老的 IPC “桥梁”)
[2.1 管道的定义:进程间的数据流](#2.1 管道的定义:进程间的数据流)
[2.2 管道的本质:内核维护的环形缓冲区](#2.2 管道的本质:内核维护的环形缓冲区)
[3.1 匿名管道的创建:pipe () 函数](#3.1 匿名管道的创建:pipe () 函数)
[3.1.1 pipe () 函数的接口说明](#3.1.1 pipe () 函数的接口说明)
[3.1.2 pipe () 函数的工作原理](#3.1.2 pipe () 函数的工作原理)
[3.2 匿名管道的核心使用:fork () 共享管道描述符](#3.2 匿名管道的核心使用:fork () 共享管道描述符)
[3.2.1 步骤 1:父进程创建匿名管道](#3.2.1 步骤 1:父进程创建匿名管道)
[3.2.2 步骤 2:父进程 fork () 创建子进程](#3.2.2 步骤 2:父进程 fork () 创建子进程)
[3.2.3 步骤 3:父子进程关闭无用描述符,明确通信方向](#3.2.3 步骤 3:父子进程关闭无用描述符,明确通信方向)
[3.2.4 内核视角:管道的本质是共享的 file 结构](#3.2.4 内核视角:管道的本质是共享的 file 结构)
[3.3 匿名管道的实战代码 1:基础读写实现](#3.3 匿名管道的实战代码 1:基础读写实现)
[3.3.1 代码实现](#3.3.1 代码实现)
[3.3.2 代码解析](#3.3.2 代码解析)
[3.3.3 运行结果](#3.3.3 运行结果)
[3.4 匿名管道的实战代码 2:从键盘读入,管道传输,屏幕输出](#3.4 匿名管道的实战代码 2:从键盘读入,管道传输,屏幕输出)
[3.5 匿名管道的读写规则,这些坑一定要避!](#3.5 匿名管道的读写规则,这些坑一定要避!)
[3.5.1 当管道中没有数据可读时](#3.5.1 当管道中没有数据可读时)
[3.5.2 当管道的缓冲区写满时](#3.5.2 当管道的缓冲区写满时)
[3.5.3 当所有管道写端被关闭时](#3.5.3 当所有管道写端被关闭时)
[3.5.4 当所有管道读端被关闭时](#3.5.4 当所有管道读端被关闭时)
[3.5.5 管道写入的原子性规则](#3.5.5 管道写入的原子性规则)
[3.6 匿名管道的四大核心特点](#3.6 匿名管道的四大核心特点)
[3.6.1 只能用于亲缘进程间通信](#3.6.1 只能用于亲缘进程间通信)
[3.6.2 提供流式服务,无数据边界](#3.6.2 提供流式服务,无数据边界)
[3.6.3 生命周期随进程,进程退出则管道释放](#3.6.3 生命周期随进程,进程退出则管道释放)
[3.6.4 半双工通信,双向通信需要两个管道](#3.6.4 半双工通信,双向通信需要两个管道)
[3.6.5 内核自动实现同步与互斥](#3.6.5 内核自动实现同步与互斥)
[3.7 匿名管道的四种通信场景验证](#3.7 匿名管道的四种通信场景验证)
[3.8 匿名管道的进阶实战:实现简易进程池](#3.8 匿名管道的进阶实战:实现简易进程池)
一、进程间通信基础,为什么需要 IPC?
在学习具体的通信方式前,我们首先要搞清楚进程为什么需要通信 ,以及进程间通信有哪些分类和发展历程,这能帮我们建立起 IPC 的整体认知,理解管道存在的意义。
1.1 进程间通信的四大核心目的
进程作为操作系统调度的基本单位,独立运行的特性决定了它并非孤立存在,实际开发中多个进程协同工作是常态,而通信就是协同的基础,核心目的有四个:
- 数据传输:一个进程需要将自身的数据发送给另一个进程,比如播放器进程从下载进程获取音视频数据。
- 资源共享:多个进程共享同一份系统资源或自定义资源,比如多个进程共享一个配置文件的内容。
- 通知事件:一个进程向其他进程发送消息,告知特定事件发生,比如子进程终止时通知父进程进行资源回收。
- 进程控制:一个进程完全控制另一个进程的执行,比如调试器(Debug)进程拦截被调试进程的异常和陷入,实时获取其状态变化。
如果没有 IPC,每个进程都只能闭门造车,无法实现复杂的业务逻辑,这也是 IPC 成为操作系统核心知识点的原因。
1.2 进程间通信的发展与分类
从 Unix 系统诞生至今,进程间通信的方式经历了三个阶段的发展:管道 → System V IPC → POSIX IPC,不同阶段的 IPC 方式适用于不同的场景,也各有优劣。
而从具体的实现形式来看,进程间通信主要分为三大类,这也是我们学习 IPC 的核心框架:
- 管道 :包括匿名管道(pipe) 和命名管道(FIFO),是最基础、最经典的 IPC 方式,本文核心讲解匿名管道。
- System V IPC:System V 标准下的通信方式,包括共享内存、消息队列、信号量,特点是生命周期随内核,需要手动管理资源。
- POSIX IPC:POSIX 标准下的通信方式,在 System V 基础上做了优化,同样包含共享内存、消息队列、信号量,还新增了互斥量、条件变量、读写锁等同步机制。
管道作为最早的 IPC 方式,虽然功能相对简单,但它的设计思想贯穿了 Linux 的核心理念 ------一切皆文件,这也是管道的核心设计亮点,接下来我们就深入解析管道的本质。
二、管道的核心认知,Unix 最古老的 IPC "桥梁"
管道(Pipe)是 Unix 系统中最古老的进程间通信机制,诞生于 Unix 的早期版本,其设计非常简洁,却完美契合了 Linux 的 "一切皆文件" 思想。
2.1 管道的定义:进程间的数据流
我们可以把管道理解为连接两个进程的一个单向数据流,这个数据流由内核维护,本质上是内核中的一块缓冲区。一个进程将数据写入管道的一端,另一个进程从管道的另一端读取数据,实现进程间的数据传递。
最经典的管道使用场景就是 Linux 命令行中的管道符|,比如我们常用的who | wc -l:
who进程的标准输出(stdout) 会连接到管道的写端,将数据写入内核缓冲区;wc -l进程的标准输入(stdin) 会连接到管道的读端,从内核缓冲区读取数据;- 内核作为中间层,负责维护这块缓冲区,实现两个无亲缘关系进程(命令行进程)的通信。
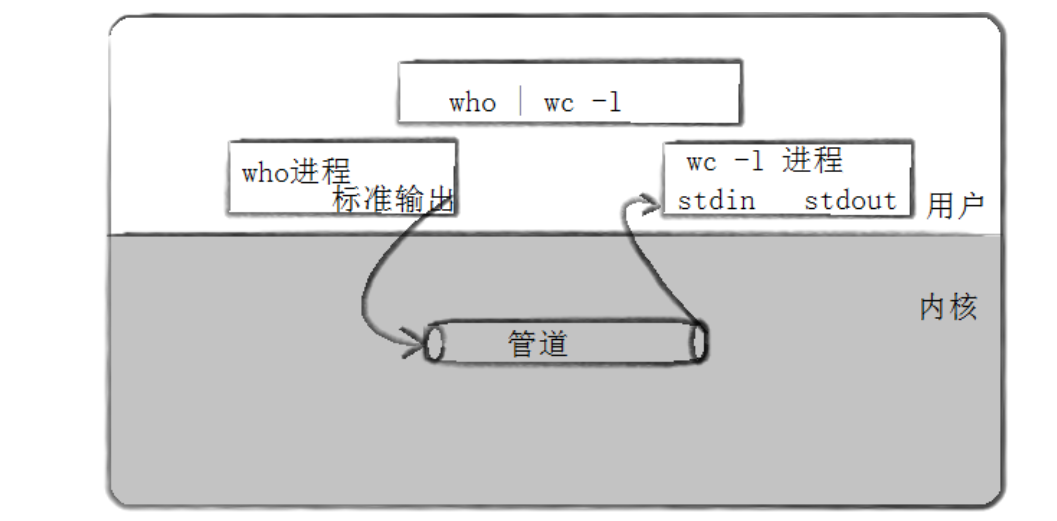
在这个过程中,用户无需关心内核的具体实现,只需要像使用文件一样使用管道,这就是 "一切皆文件" 思想的体现 ------ 管道的操作接口和文件完全一致,都使用read、write、close等系统调用。
2.2 管道的本质:内核维护的环形缓冲区
从底层实现来看,管道并不是物理文件,而是内核为进程创建的一块内存缓冲区,通常是环形缓冲区(避免数据溢出),其大小由系统内核决定(默认一般为 4096 字节,即 1 页内存)。
管道的核心特点是单向通信 ,数据只能从写端流向读端,无法反向传输。如果需要实现两个进程的双向通信,就需要创建两个管道,分别负责两个方向的数据传输,这一点是管道的核心特性,也是后续学习匿名管道的关键。
三、匿名管道深度解析,亲缘进程的通信利器
匿名管道(Anonymous Pipe)是管道的基础形式,也是本文的核心内容。它的 "匿名" 体现在没有对应的磁盘文件,仅存在于内核中,且只能用于具有亲缘关系的进程间通信(比如父进程和子进程、兄弟进程),这是匿名管道与命名管道最核心的区别。
3.1 匿名管道的创建:pipe () 函数
在 Linux 中,我们通过**pipe()**系统调用创建匿名管道,该函数会为进程创建一个管道,并返回两个文件描述符,分别对应管道的读端和写端。
3.1.1 pipe () 函数的接口说明
cpp
#include <unistd.h>
// 功能:创建一个匿名管道
// 参数:fd - 整型数组,长度为2,用于保存管道的读端和写端文件描述符
// fd[0] - 管道的读端,只能执行read操作
// fd[1] - 管道的写端,只能执行write操作
// 返回值:成功返回0,失败返回-1,并设置errno
int pipe(int fd[2]);核心注意点 :**fd[0]和fd[1]**是成对出现的,创建管道后必须通过这两个文件描述符操作管道,且读端只能读、写端只能写,反向操作会报错。
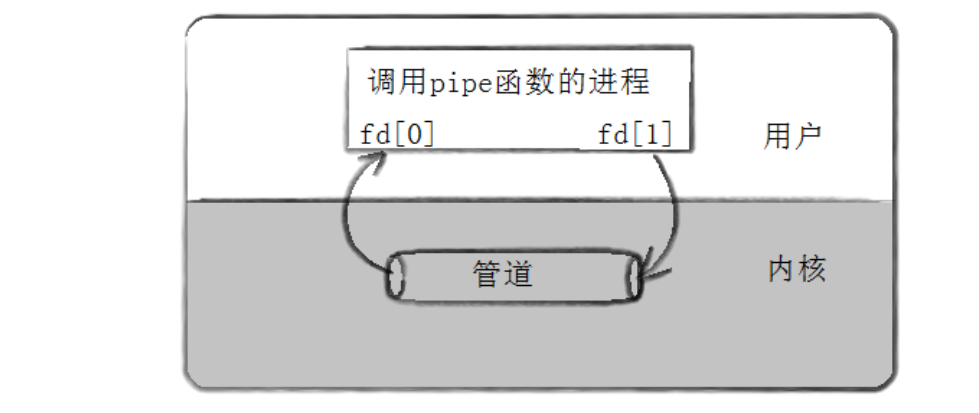
3.1.2 pipe () 函数的工作原理
调用**pipe()**函数的进程会在内核中创建一块管道缓冲区,同时在内核的文件描述符表中为该进程分配两个文件描述符fd[0]和fd[1],分别指向管道的读端和写端。
此时,该进程可以通过fd[1]向管道写入数据,通过fd[0]从管道读取数据,但单个进程使用匿名管道没有实际意义 (自己写自己读,无需通信)。匿名管道的真正价值在于通过 fork () 创建子进程后,实现父子进程间的通信,这也是匿名管道的核心使用场景。
3.2 匿名管道的核心使用:fork () 共享管道描述符
匿名管道只能用于亲缘进程间通信,核心原因是子进程会继承父进程的文件描述符表 。当父进程创建管道后,通过**fork()**创建子进程,子进程会复制父进程的所有文件描述符,包括管道的fd[0]和fd[1],这样父子进程就拥有了对同一个管道的访问权限,进而实现通信。
整个过程分为三步 ,我们从文件描述符角度 和内核角度分别拆解,让你彻底理解其原理。
我们先以一张图来对这一过程的原理有个大致的了解:
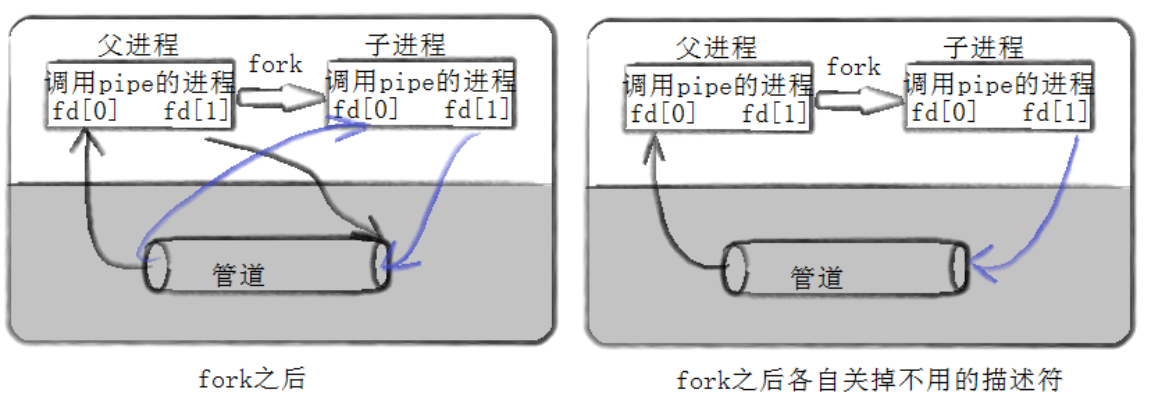
3.2.1 步骤 1:父进程创建匿名管道
父进程调用pipe(fd),内核创建管道缓冲区,并为父进程分配文件描述符fd[0]=3、fd[1]=4(0、1、2 分别为标准输入、标准输出、标准错误),此时父进程的文件描述符表中,3 指向管道读端,4 指向管道写端。
此时父进程既可以读管道,也可以写管道,但单独使用无意义,需要创建子进程共享描述符。
3.2.2 步骤 2:父进程 fork () 创建子进程
父进程调用fork()创建子进程,子进程会完全复制 父进程的文件描述符表、地址空间等资源。此时子进程也拥有fd[0]=3和fd[1]=4,且这两个描述符指向同一个内核管道缓冲区。
此时,父子进程都有对管道的读和写权限,存在两个问题:
- 数据流向混乱,无法确定谁写谁读;
- 容易出现写端未关闭导致读端阻塞的问题。
因此,需要进行第三步 ------关闭无用的文件描述符,明确管道的数据流方向。
3.2.3 步骤 3:父子进程关闭无用描述符,明确通信方向
管道是单向通信的,因此我们需要让父进程只写、子进程只读(或反之),关闭各自无用的文件描述符:
- 父进程关闭读端
fd[0],只保留写端fd[1],负责向管道写入数据;- 子进程关闭写端
fd[1],只保留读端fd[0],负责从管道读取数据。
此时,管道的数据流方向被唯一确定:父进程写端 → 内核缓冲区 → 子进程读端,父子进程的单向通信通道就建立完成了。
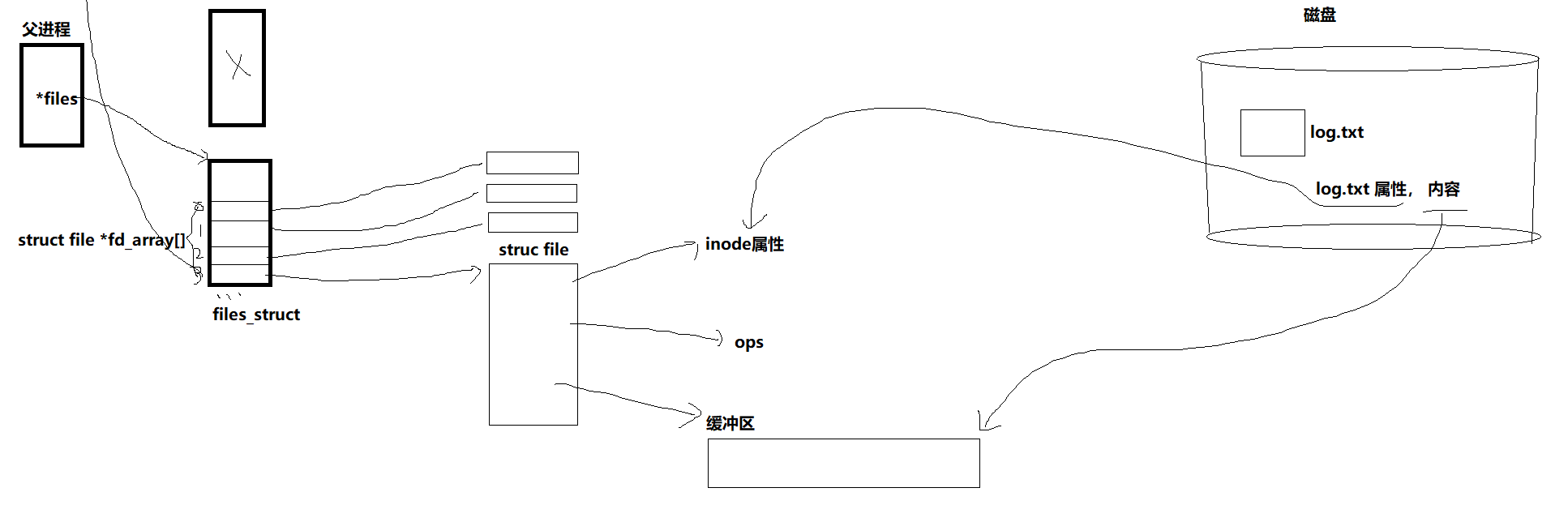
3.2.4 内核视角:管道的本质是共享的 file 结构
从内核角度来看,管道的本质是两个进程共享同一个 file 结构体,而 file 结构体指向内核中的管道缓冲区。
父子进程的fd[0]和fd[1]虽然是不同的文件描述符,但它们最终指向内核中的同一个file结构,该结构包含了管道的读写位置、缓冲区指针、引用计数等信息。当父子进程分别关闭无用描述符后,file结构的引用计数会相应减少,但只要有一个进程持有描述符,管道缓冲区就不会被释放。
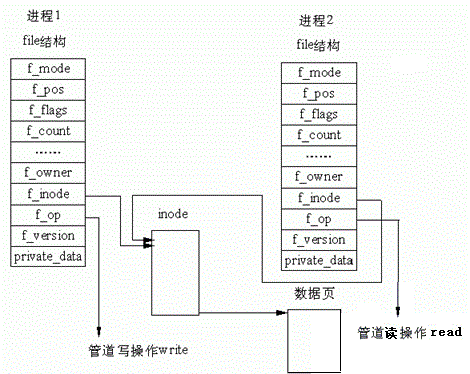
这一设计完美契合了 Linux "一切皆文件" 的思想:进程操作管道,就像操作普通文件一样,内核隐藏了底层的缓冲区实现。
3.3 匿名管道的实战代码 1:基础读写实现
接下来我们通过一段基础代码,实现父进程向管道写入数据,子进程从管道读取数据并打印,让你直观感受匿名管道的使用流程。
3.3.1 代码实现
cpp
#include <unistd.h>
#include <stdlib.h>
#include <stdio.h>
#include <errno.h>
#include <string.h>
// 定义错误处理宏,简化代码
#define ERR_EXIT(m) \
do \
{ \
perror(m); \
exit(EXIT_FAILURE); \
} while(0)
int main(int argc, char *argv[])
{
int pipefd[2];
// 步骤1:父进程创建匿名管道
if (pipe(pipefd) == -1)
ERR_EXIT("pipe error");
// 步骤2:父进程创建子进程
pid_t pid;
pid = fork();
if (pid == -1)
ERR_EXIT("fork error");
// 子进程逻辑:只读,关闭写端
if (pid == 0) {
close(pipefd[1]); // 关闭子进程的写端
char buf[10] = {0};
read(pipefd[0], buf, 10); // 从管道读端读取数据
printf("子进程读取到数据:buf=%s\n", buf);
close(pipefd[0]); // 读取完成,关闭读端
exit(EXIT_SUCCESS);
}
// 父进程逻辑:只写,关闭读端
close(pipefd[0]); // 关闭父进程的读端
write(pipefd[1], "hello", 5); // 向管道写端写入数据
close(pipefd[1]); // 写入完成,关闭写端
// 父进程等待子进程退出,回收资源
waitpid(pid, nullptr, 0);
return 0;
}3.3.2 代码解析
- 父进程首先调用**pipe(pipefd)**创建管道,获取读端
pipefd[0]和写端pipefd[1];- 调用**fork()**创建子进程,子进程继承
pipefd数组,指向同一个管道;- 子进程关闭写端
pipefd[1],通过**read()**从读端读取数据,打印后关闭读端;- 父进程关闭读端
pipefd[0],通过**write()**向写端写入字符串hello,写入后关闭写端;- 父进程通过**waitpid()**等待子进程退出,避免子进程成为僵尸进程。
3.3.3 运行结果
编译并运行代码,输出如下:
子进程读取到数据:buf=hello这说明父子进程通过匿名管道成功实现了数据传输。
3.4 匿名管道的实战代码 2:从键盘读入,管道传输,屏幕输出
另一个经典的场景是:从键盘读取用户输入,写入管道,再从管道读取数据,输出到屏幕,这个案例能更好地体现管道与标准输入、标准输出的结合使用。
cpp
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
int main( void )
{
int fds[2];
char buf[100];
int len;
// 创建匿名管道
if ( pipe(fds) == -1 ) {
perror("make pipe");
exit(1);
}
// 从标准输入(键盘)读取数据,写入管道
while ( fgets(buf, 100, stdin) ) {
len = strlen(buf);
if ( write(fds[1], buf, len) != len ) {
perror("write to pipe");
break;
}
memset(buf, 0x00, sizeof(buf)); // 清空缓冲区
}
// 从管道读取数据,写入标准输出(屏幕)
if ( (len=read(fds[0], buf, 100)) == -1 ) {
perror("read from pipe");
exit(1);
}
if ( write(1, buf, len) != len ) {
perror("write to stdout");
exit(1);
}
// 关闭管道描述符
close(fds[0]);
close(fds[1]);
return 0;
}运行方式 :运行程序后,从键盘输入任意字符串,按Ctrl+D结束输入,程序会将输入的内容从管道读取并输出到屏幕,完美体现了管道的数据流特性。
3.5 匿名管道的读写规则,这些坑一定要避!
匿名管道的读写操作并非随意的,内核为管道制定了严格的读写规则,这些规则直接决定了程序的运行行为,也是面试中的高频考点,我们必须牢牢掌握。
管道的读写规则与是否设置非阻塞模式(O_NONBLOCK) 密切相关,O_NONBLOCK是文件描述符的标志位,用于设置是否为非阻塞 I/O,默认情况下管道的文件描述符为阻塞模式(O_NONBLOCK disable)。
3.5.1 当管道中没有数据可读时
- 阻塞模式(默认) :
read()调用会阻塞,进程暂停执行,直到有其他进程向管道写入数据,才会被唤醒并读取数据;- 非阻塞模式(O_NONBLOCK enable) :
read()调用不会阻塞 ,直接返回-1,并将errno设置为EAGAIN(表示 "资源暂时不可用,可重试")。
3.5.2 当管道的缓冲区写满时
管道的缓冲区大小是固定的(默认 4096 字节),当缓冲区被写满后,写入操作会受到限制:
- 阻塞模式(默认) :
write()调用会阻塞,进程暂停执行,直到有其他进程从管道读取数据,缓冲区有空闲空间,才会被唤醒并继续写入;- 非阻塞模式(O_NONBLOCK enable) :
write()调用不会阻塞 ,直接返回-1,并将errno设置为EAGAIN。
3.5.3 当所有管道写端被关闭时
如果所有持有管道写端的进程都关闭了写端(close(fd[1])),此时管道中剩余的数据可以正常读取,当数据读取完毕后,再次调用read()会返回 0,这与读取普通文件到末尾的行为一致,代表 "管道已无数据,且不会再有新数据写入"。
3.5.4 当所有管道读端被关闭时
如果所有持有管道读端的进程都关闭了读端(close(fd[0])),此时进程向管道写端写入数据时,内核会向该进程发送SIGPIPE 信号 ,该信号的默认处理方式是终止进程。
这是一个非常重要的坑!如果在程序中未处理 SIGPIPE 信号,可能会导致进程意外退出,因此在实际开发中,需要根据需求捕获并处理 SIGPIPE 信号。
3.5.5 管道写入的原子性规则
Linux 内核保证了管道写入的原子性,规则如下:
- 当要写入的数据量不大于 PIPE_BUF(PIPE_BUF 是内核定义的管道缓冲区最大原子写入值,默认 4096 字节)时,内核保证写入操作的原子性 ------ 即数据会被完整地写入管道,不会被其他进程的写入操作打断;
- 当要写入的数据量大于 PIPE_BUF 时,内核不保证写入操作的原子性 ------ 即数据可能会被拆分,与其他进程的写入数据交错存在于管道中。
这一规则保证了多个进程向管道写入小数据量时,数据不会混乱,是管道实现简单同步的基础。
3.6 匿名管道的四大核心特点
结合前面的原理和实战,我们总结出匿名管道的四大核心特点,这是匿名管道的本质属性,也是与其他 IPC 方式的核心区别:
3.6.1 只能用于亲缘进程间通信
匿名管道没有对应的磁盘文件,仅存在于内核中,其文件描述符只能通过fork()继承,因此只能用于具有共同祖先的进程间通信(父进程与子进程、兄弟进程),这是匿名管道最核心的限制。
如果需要实现无亲缘关系进程间的通信 ,就需要使用命名管道(FIFO),这也是我们后续要学习的内容。
3.6.2 提供流式服务,无数据边界
管道提供的是流式服务,即写入管道的数据是一串连续的字节流,内核不会为数据添加任何分隔符或边界。读取进程无法知道写入进程的写入次数,只能根据自己的缓冲区大小读取数据。
例如:写入进程分 3 次写入"a"、"b"、"c",读取进程一次读取可能会得到"abc",无法区分原始的写入边界。这一点与消息队列(有消息边界)形成鲜明对比。
3.6.3 生命周期随进程,进程退出则管道释放
匿名管道是基于进程的资源,没有独立的生命周期,其生命周期与持有管道文件描述符的进程绑定:
- 只要有一个进程持有管道的读端或写端描述符,管道缓冲区就会一直存在;
- 当所有持有管道描述符的进程都退出(或关闭所有描述符),内核会自动释放管道缓冲区,回收资源。
这一点与 System V 共享内存(生命周期随内核)不同,无需手动回收管道资源,降低了开发成本。
3.6.4 半双工通信,双向通信需要两个管道
管道是半双工的,即数据只能沿一个方向流动,读端和写端是固定的,无法在同一个管道中实现双向数据传输。
如果需要实现两个进程的双向通信 ,就需要创建两个匿名管道:
- 管道 1:进程 A 写,进程 B 读;
- 管道 2:进程 B 写,进程 A 读。
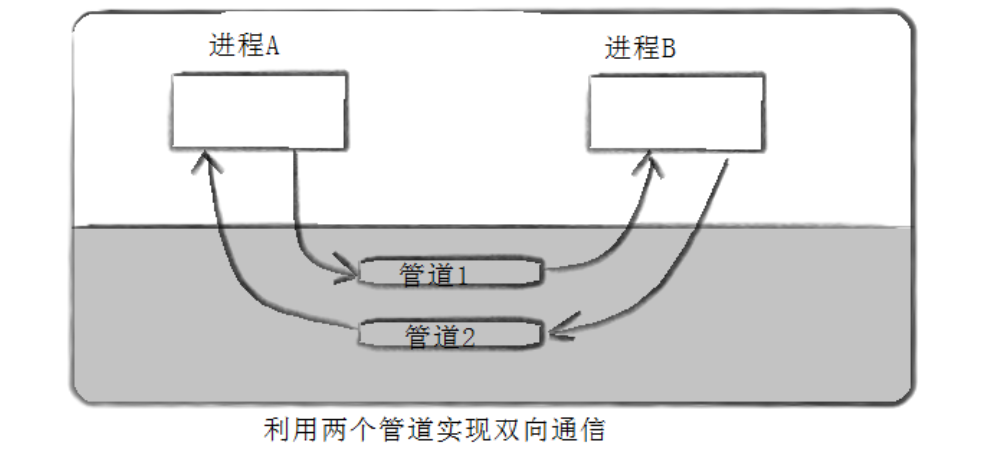
通过两个管道的组合,实现双向的数据流传输。
3.6.5 内核自动实现同步与互斥
内核会对管道的操作进行同步与互斥,避免多个进程同时操作管道导致数据混乱:
- 互斥:同一时刻,只允许一个进程对管道进行读或写操作,避免多个进程同时写入 / 读取导致数据错乱;
- 同步:通过阻塞机制实现同步,比如读端阻塞等待写端写入数据,写端阻塞等待读端读取数据,保证数据的生产和消费节奏一致。
这一特性让我们在使用管道时,无需手动实现同步互斥,简化了开发。
3.7 匿名管道的四种通信场景验证
在实际使用中,匿名管道的通信会出现四种典型场景,我们可以通过代码验证这些场景的运行行为,加深对管道读写规则的理解:
- 读正常 && 写满:读进程正常读取,写进程写入数据直到管道缓冲区满,此时写进程会阻塞,直到读进程读取数据释放缓冲区;
- 写正常 && 读空:写进程正常写入,读进程读取数据直到管道缓冲区空,此时读进程会阻塞,直到写进程继续写入数据;
- 写关闭 && 读正常 :所有写端被关闭,读进程读取管道中剩余数据后,再次调用
read()会返回 0,代表管道已无数据;- 读关闭 && 写正常:所有读端被关闭,写进程向管道写入数据时,会收到 SIGPIPE 信号,默认终止进程。
这四种场景覆盖了管道的所有核心读写规则,建议大家手动编写代码验证,直观感受管道的运行行为。
3.8 匿名管道的进阶实战:实现简易进程池
进程池是开发中常用的技术,用于管理一组子进程,实现任务的并发处理。基于匿名管道的父子进程通信 和描述符继承特性,我们可以实现一个简易的进程池,核心思路是:
- 主进程(Master)创建指定数量的子进程(Worker),每个子进程通过匿名管道与主进程通信;
- 主进程作为任务调度器,将任务通过管道派发给空闲的子进程;
- 子进程从管道中获取任务,执行后等待下一个任务;
- 主进程完成任务派发后,关闭管道,子进程检测到管道关闭后退出,主进程回收子进程资源。
由于进程池的实现代码相对复杂(涉及 C++ 的类、函数对象、管道数组管理等),本文不再贴出完整代码,核心要点如下:
- 主进程为每个子进程创建一个独立的匿名管道,用于任务派发;
- 子进程关闭无用的管道描述符,只保留与主进程通信的管道读端;
- 主进程保留所有子进程的管道写端,通过写端向子进程发送任务指令;
- 使用函数对象(std::function) 封装任务,实现任务的灵活扩展;
- 主进程通过轮询的方式将任务派发给子进程,实现任务的负载均衡。
进程池的实现是匿名管道的高阶应用,完美结合了匿名管道的亲缘进程通信、文件描述符管理、读写规则等知识点,建议大家结合本文附带的 ProcessPool.hpp、Channel.hpp、Task.hpp 等代码深入学习。
四、匿名管道的局限性与解决方案
通过前面的学习,我们知道匿名管道是一种简单、高效的 IPC 方式,但它也存在明显的局限性,这些局限性决定了它的使用场景:
- 只能用于亲缘进程间通信:这是匿名管道最大的限制,无法实现无亲缘关系进程间的通信;
- 半双工通信:数据只能单向流动,双向通信需要创建两个管道,增加了开发复杂度;
- 流式服务无边界:读取进程无法区分写入进程的写入边界,需要手动添加分隔符;
- 无法实现广播:只能实现一对一的进程通信,无法向多个进程同时发送数据。
针对这些局限性,Linux 提供了对应的解决方案:
- 解决无亲缘进程通信 :使用命名管道(FIFO),命名管道有对应的磁盘文件(管道文件),任何进程都可以通过打开该文件访问管道;
- 解决双向通信 :使用套接字(Socket),Socket 支持全双工通信,是跨进程、跨主机通信的主流方式;
- 解决数据边界 :使用消息队列,消息队列以 "消息" 为单位传输数据,每个消息有独立的边界,读取进程可以按消息读取;
- 解决广播通信 :使用信号量 + 共享内存 或消息队列,结合同步机制实现多进程的广播通信。
其中,命名管道(FIFO) 是匿名管道的直接扩展,完全兼容匿名管道的读写规则和操作接口,只是解决了 "匿名" 的问题,让无亲缘进程可以通信。
总结
管道作为 Unix 最古老的 IPC 方式,虽然功能相对简单,但它的设计思想贯穿了 Linux 的核心理念,是学习后续更复杂 IPC 方式(共享内存、消息队列、Socket)的基础。理解了管道的 "一切皆文件" 思想,再学习其他 IPC 方式会事半功倍 ------ 因为共享内存、消息队列等虽然实现不同,但核心都是通过内核资源实现进程间的数据交互。
在学习 IPC 的过程中,建议大家多动手写代码 ,从简单的父子进程管道通信,到进程池的实现,再到命名管道、共享内存的使用,通过实战加深对原理的理解。同时,要注重构建知识体系,明确不同 IPC 方式的优缺点和适用场景,在实际开发中根据需求选择合适的通信方式。
进程间通信是 Linux 开发的核心知识点,也是面试的高频考点,掌握管道与匿名管道,是你踏入 Linux 高级开发的第一步。后续我们将继续讲解命名管道、共享内存、消息队列等 IPC 方式,带你构建完整的 Linux 进程间通信知识体系。