前言
昨天刷到一篇《OpenTeleDB 测评,XStore 是惊喜!》,心里直犯嘀咕:真有那么神?我直接撸起袖子,上手测试了一下------高并发、高频更新、混合负载全拉满,看看 XStore 在高压场景下,到底是"稳如老狗"还是"昙花一现"。
我按照官方教程,用CentOS安装了OpenTeleDB,整个安装过程出乎意料地顺利,从下载源码到编译安装,全程只用了15分钟。启动命令也很简单:
bash
${pg_install_dir}/bin/pg_ctl -D ${pg_data_dir} start我顺手把端口改成了 15432(避免和本地 PG 冲突),然后用 ps -ef | grep postgres 看了眼进程:
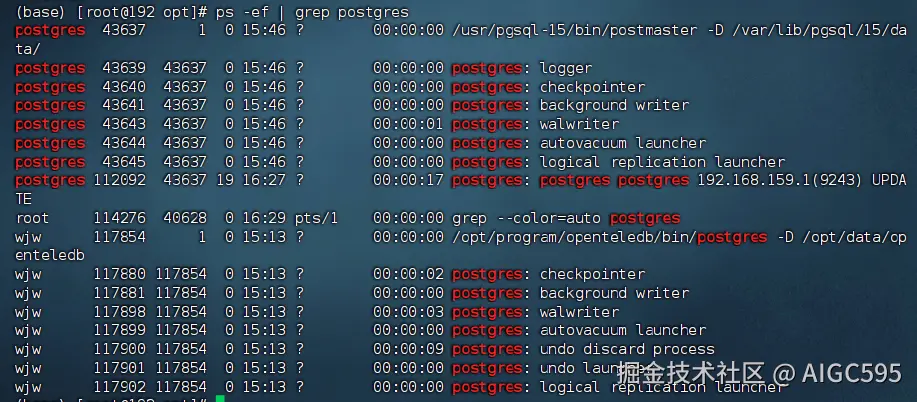
上半部分是标准 PostgreSQL 17,下半部分是 OpenTeleDB,乍看差别不大,但内核早已不同------通过 Python 连接确认,它确实是 基于 PostgreSQL 17 开发,兼容性毫无问题:

接下来就是重头戏:多维度性能与稳定性对比。
插入性能
首先用 INSERT INTO test_benchmark SELECT n, md5(random()::text) FROM generate_series({start_id}, {end_id - 1}) AS n 命令测试纯插入场景(20 线程并发,插入 100 万行数据):
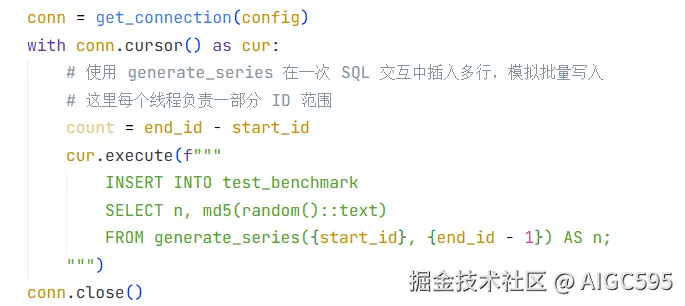
插入性能结果如下:
| 数据库 | 耗时 (s) | 吞吐 (rows/s) |
|---|---|---|
| OpenTeleDB (XStore) | 7.23 | 138,368 |
| PostgreSQL (Native) | 4.80 | 208,425 |
结果不出所料:原生 PG 依然快 。毕竟 XStore 要额外写 Undo Log,相当于"双写",性能损耗在所难免,但请注意------13.8 万行/秒是什么概念?这意味着每秒处理近 14 万条订单、日志或用户行为记录,对绝大多数业务来说已经绰绰有余,更何况,快≠好,我们还得看"代价"。
更新性能
接着用命令 UPDATE test_benchmark SET info = md5(random()::text) WHERE id = {target_id}; 测试 20 线程并发、持续 60 秒的随机 UPDATE:

性能对比结果如下:
| 数据库 | 总事务数 | 平均 TPS |
|---|---|---|
| OpenTeleDB (XStore) | 60,991 | 1,011.56 |
| PostgreSQL (Native) | 80,565 | 1,331.82 |
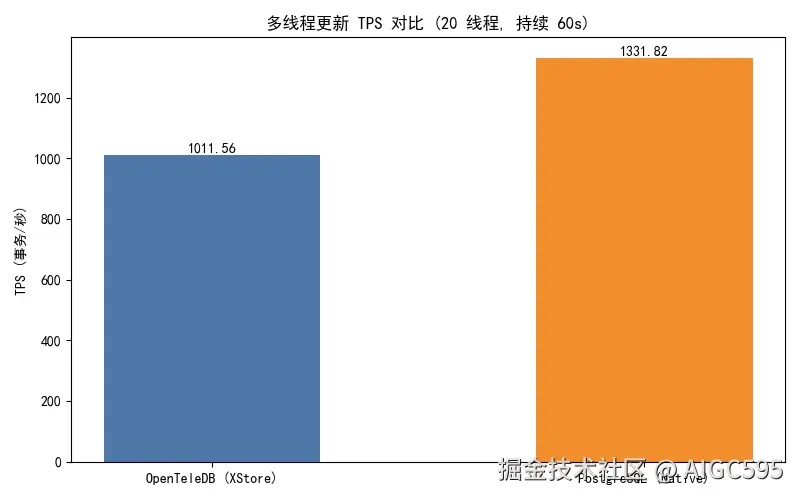
表面上看,PG 的 TPS 高出约 32%。但别急着下结论------高性能的背后,是空间膨胀的隐形税。
空间膨胀
这才是最震撼的部分!我在同样 20 线程、60 秒高频混合负载(INSERT + UPDATE + DELETE)下,观察表的实际磁盘增长:

测试结果如下:
| 数据库 | 初始大小 | 最终大小 | 膨胀量 |
|---|---|---|---|
| OpenTeleDB (XStore) | 106.33 MB | 106.33 MB | 0.00 MB (0%) |
| PostgreSQL (Native) | 86.60 MB | 282.45 MB | +195.84 MB (+226%) |
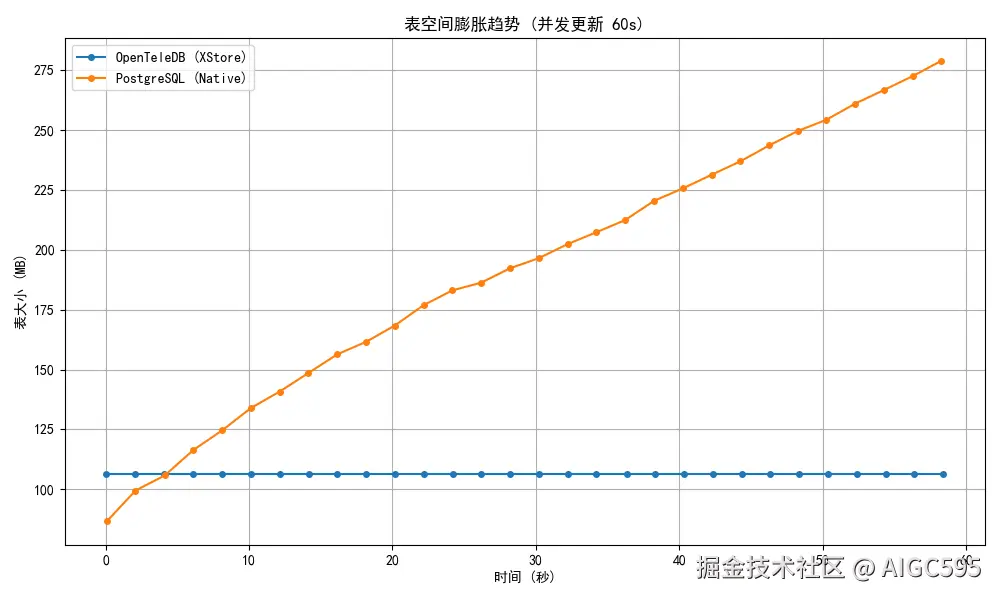
PG 在 1 分钟内膨胀了 3 倍! 这意味着什么?
- 磁盘空间被快速吃掉;
- Index 扫描变慢(因为要跳过大量 dead tuple);
- Vacuum 压力剧增,可能拖垮 I/O;
- 长期运行后,TPS 会断崖式下跌。
而 XStore 表大小纹丝不动 。这不仅仅是"优化",这是架构级的胜利 ,它用原位更新 + Undo Log 的方式,彻底绕开了 MVCC 的膨胀陷阱,这种"稳态性能"------即长时间高负载下仍能保持一致响应与资源消耗才是生产环境真正需要的。
Vacuum 效率
最后,我用命令 UPDATE test_benchmark SET info = md5(random()::text) WHERE id <= {update_rows}; 人为制造 20% 脏数据,然后执行 VACUUM:
Vacuum 耗时对比如下:
| 数据库 | Vacuum 耗时 (s) |
|---|---|
| OpenTeleDB (XStore) | 0.88s |
| PostgreSQL (Native) | 1.14s |
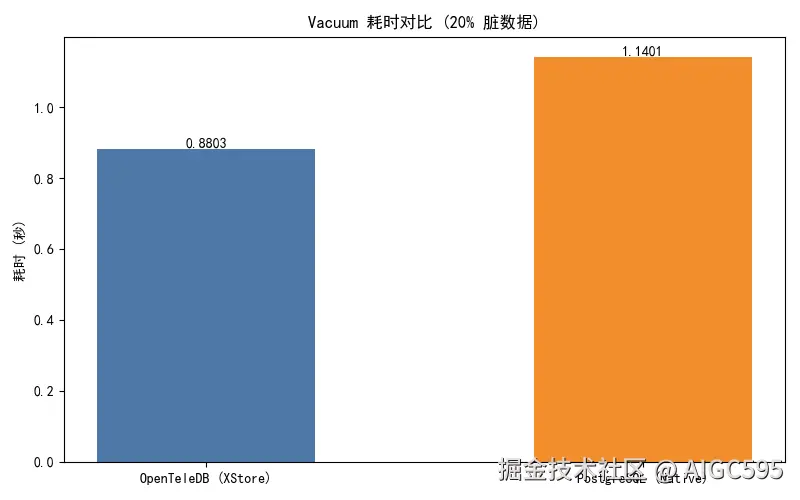
XStore 快了约 23%。原因很简单:主表里几乎没有垃圾,大部分版本管理交给 Undo Log 处理,VACUUM 只需轻量清理元数据即可,而 PG 还得一页一页扫描、标记、跳过 dead tuple,效率自然低。
小结:快 vs 稳,你选哪个?
OpenTeleDB 的 XStore 并不是要"打败" PostgreSQL,而是提供另一种选择:
- 如果你追求极致写入吞吐(如日志采集、监控埋点),原生 PG 仍是王者;
- 但如果你的业务涉及高频更新、长期运行、资源受限(如金融交易、用户账户、订单系统),那么 XStore 的"零膨胀 + 稳定 TPS + 低维护成本"组合,堪称降维打击。
更重要的是,它以插件形式存在,不 fork 内核,能紧跟 PG 主线。这意味着你既能享受新存储引擎的红利,又不会被锁死在某个分支上。
当然,XStore 也有代价:写入略慢、RTO 可能略长(因需回放 Undo)、工具链尚在完善,但正如老话"鱼与熊掌不可兼得" ,关键在于你是否愿意为长期稳定性,牺牲一点点峰值性能?
对我而言,答案是肯定的。
真正的工程之美,不在于瞬间的爆发,而在于持久的可靠。