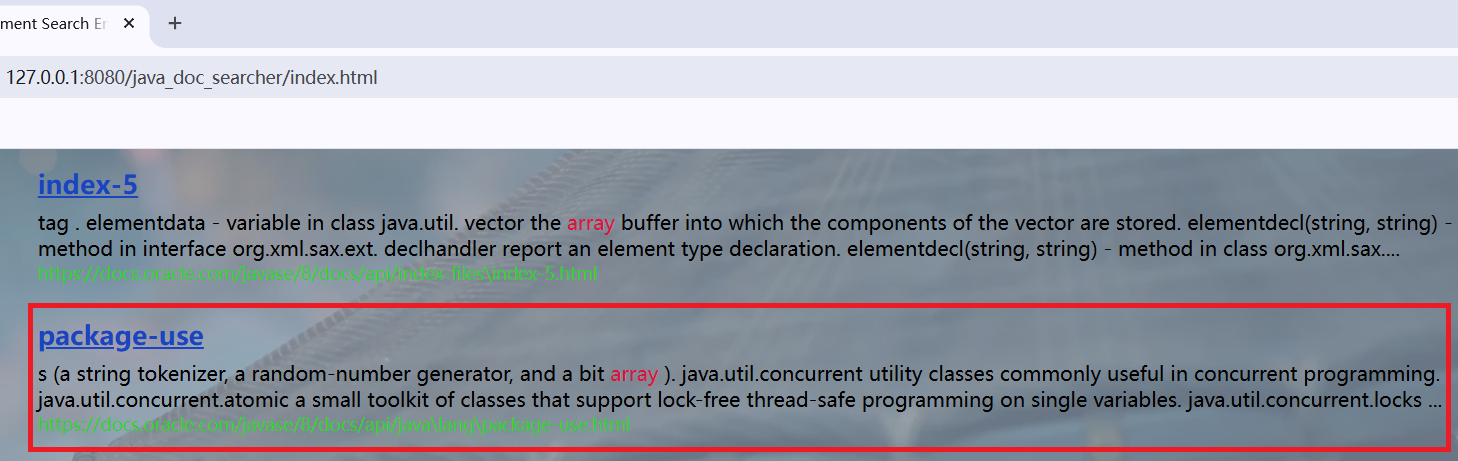
本专栏已实现搜索引擎的web模块后端程序,见下文:
前端程序见下文:
本文进行查询词标红的优化处理。
目录
[1. 查询词标红](#1. 查询词标红)
[2. 独立成词匹配的边界问题](#2. 独立成词匹配的边界问题)
1. 查询词标红
修改后端代码,在生成搜索结果的描述时,把其中包含查询词的部分加上标记,如套上一层<i>标签先令查询词在前端显示为斜体。
1.1 修改后端
修改后端DocSearcher类的GenDesc方法:
java
// 根据正文生成描述
private String GenDesc(String content, List<Term> terms){
int firstPos = -1;
// 在content中查找存在的分词结果
for(Term term: terms){
String word = term.getName();
firstPos = content.toLowerCase().indexOf(" "+word+" ");
if(firstPos >= 0)
break;
}
if(firstPos == -1){
// 所有分词结果都不在正文结果中
// 直接取正文前300个字符作为描述
return content.substring(0, 300)+"...";
}
// 从firstPos作为基准,向前找300个字符作为描述的起始位置
String desc = "";
int descBeg = firstPos < 60 ? 0 : firstPos - 60;
if(descBeg + 300 > content.length()){
desc = content.substring(descBeg);
}else{
desc = content.substring(descBeg, descBeg+300)+"...";
}
/* 实现标红新增部分:
把描述中和分词结果相同的部分加上<i>标签
*/
for(Term term: terms){
String word = term.getName();
desc = desc.replaceAll("(?i) "+word+" ","<i> "+word+" </i>");
}
return desc;
}注:(?i)表示忽略大小写进行匹配。
1.2 修改前端
再在前端处针对<i>标签设置样式,将其字体颜色设置为红色即可:
在index.html的<style>标签下增加选择器:
html
.item .desc i{
color: Crimson;
/* 去掉斜体 */
font-style:normal;
}重启服务器,再次访问index.html进行查询,以synchronous为例:
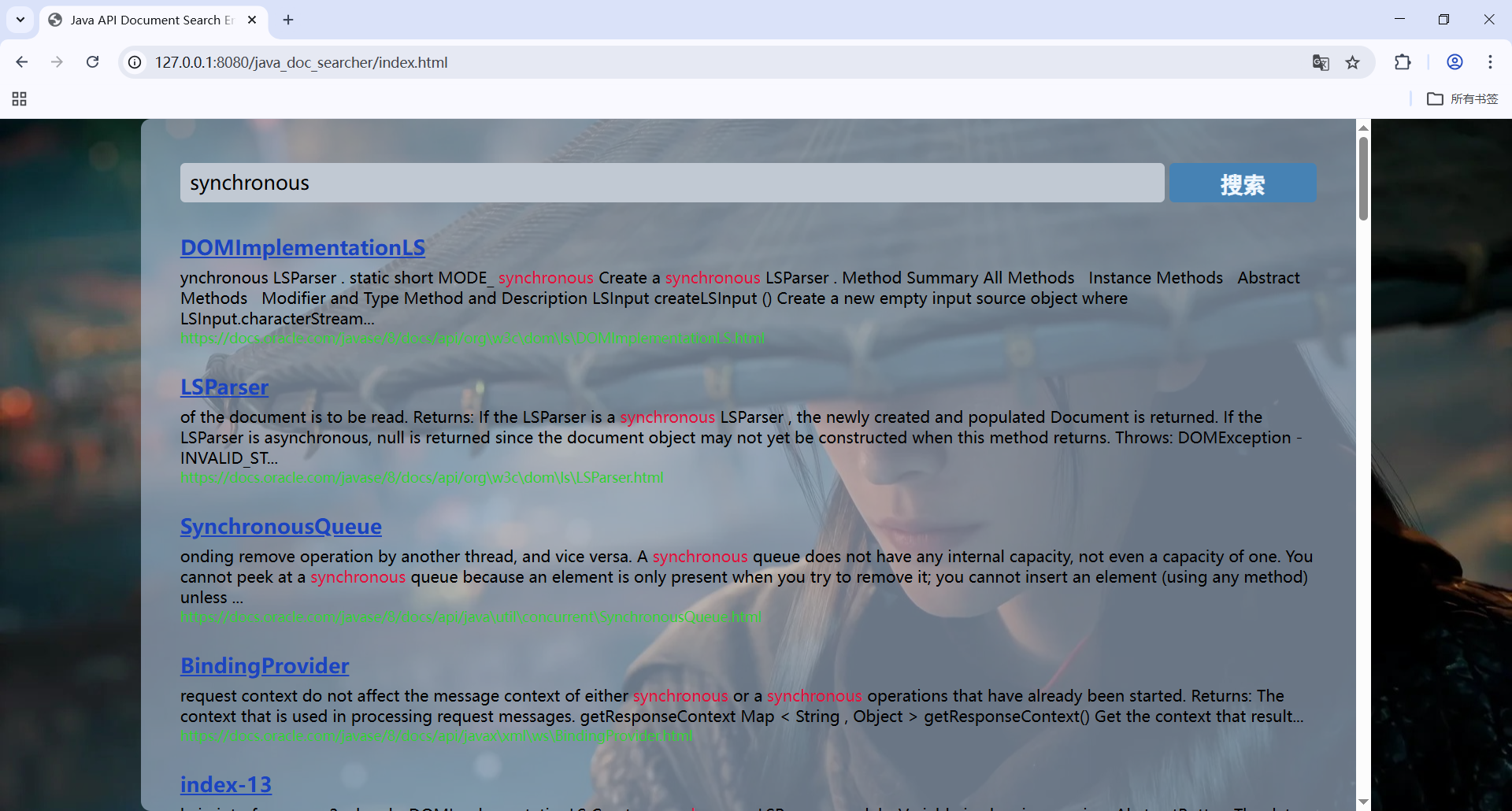
可见在描述中,查询词已经被标红。
2. 独立成词匹配的边界问题
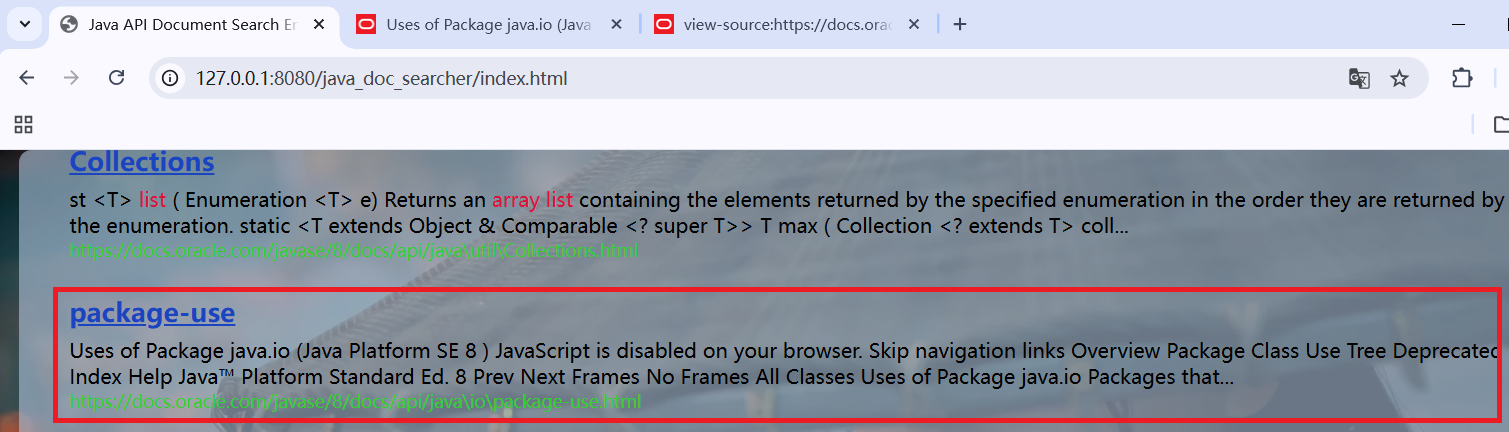
仍然以查询array list为例,在结果中找到一个描述中没有被标红的查询词的结果:
使用Ctrl+U打开HTML网页源码,Ctrl+F搜索list,可见在标签内容中是存在list的:
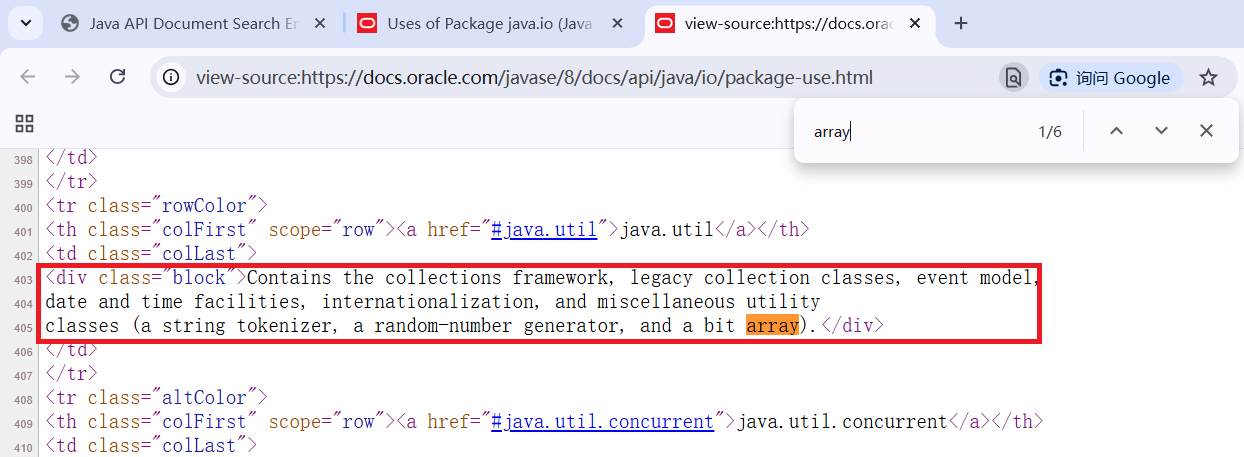
我们目前使用的独立成词匹配方式是在查询词两端各加上一个空格,这使得当前这种但是由于list后紧跟一个右括号(或其他字符)的情况都无法匹配。
Java的String类的indexOf方法不支持\b的正则匹配,此处采用将\b替换为空格后,再使用原本的独立成词匹配方式。修改GenDesc方法中在content中查找存在分词结果的思路:
java
for(Term term: terms){
String word = term.getName();
content = content.toLowerCase().replaceAll("\\b"+ word+"\\b"," "+word+" ");
firstPos = content.indexOf(" "+word+" ");
if(firstPos >= 0)
break;
}重启服务器进行重新部署,对照上一次的网页源码,可见这次标红成功: