在深度学习与高性能计算的赛道上,算子的性能不仅取决于算法与内存优化,更深层的瓶颈往往藏在 硬件指令的执行效率 里。对于 CANN(Compute Architecture for Neural Networks)平台而言,要想让模型推理或训练达到硬件的理论峰值,就必须让计算"说"硬件听得懂、执行快的 原生语言 ------ 也就是 ISA(Instruction Set Architecture,指令集架构)。
华为 CANN 生态中的 pto-isa 库 (全称 Portable Tensor Operator Instruction Set Abstraction ,可移植张量算子指令集抽象库),正是面向这一需求的底层利器。它提供了一套 跨平台、高层次封装的 ISA 编程接口,让开发者可以直接针对 AI Core 的指令集编写、优化、调试自定义算子,而不必陷入繁杂的裸机汇编与硬件细节。
如果说之前的 catlass 是用模板打造高性能 kernel,asc-devkit 是简化算子开发流程,那么 pto-isa 就是让你打开硬件"黑盒"、直接雕刻算力的雕刻刀。
一、pto-isa 是什么?为什么要用它?
pto-isa 是 CANN 中专为 AI Core 指令级编程 设计的库,核心目标是:
-
抽象 AI Core 专属指令(如向量乘加、矩阵乘、归约、数据搬移等),提供 C++ 风格的高层 API;
-
实现可移植性:同一套代码可在不同代际的芯片(如 300I Duo、910B)之间迁移,底层自动适配指令集差异;
-
兼顾性能与控制:既能精细控制指令流水线与寄存器分配,又避免手写纯汇编的易错与难维护。
为什么需要 ISA 级编程?
-
极致性能调优:通用算子库难以覆盖所有业务场景,某些特殊模式(如稀疏注意力、低比特量化卷积)必须通过定制指令流才能发挥硬件极限。
-
新硬件特性快速利用:当新一代 AI Core 增加专用指令(如 INT4 向量乘加、BF16 矩阵乘)时,用 pto-isa 可在编译期切换指令集,无需重写全部代码。
-
教学与研究的利器:深入理解 AI Core 执行模型,验证新型计算范式的可行性。
二、pto-isa 的核心架构与模块
pto-isa 的架构围绕 **"指令抽象层 + 可移植适配层 + 执行调度层"** 构建:
(一)指令抽象层(Instruction Abstraction Layer)
将 AI Core 的物理指令映射为 C++ 对象与函数,例如:
-
Vector MAC (向量乘加):
PtoVecMac(dst, src1, src2, len) -
Matrix Multiply (矩阵乘):
PtoMatMul(dst, a, b, m, k, n) -
ReduceMax/Sum (归约):
PtoReduceMax(dst, src, dim) -
DMA 搬移 :
PtoDmaCopy(dst, src, size, mode)
这些接口封装了寄存器分配、指令排队、标志位处理等细节。
(二)可移植适配层(Portability Adaptation Layer)
通过 编译期宏与特征检测,自动选择当前芯片支持的指令集实现:
-
在 910B 上使用最新矢量扩展指令;
-
在旧款 300I 上退回到兼容的基础指令集;
-
对不支持的指令给出编译错误或自动 fallback 到软件模拟实现。
(三)执行调度层(Execution Scheduler Layer)
负责任务切分、流水线编排与并行执行:
-
将大规模计算划分为 Block → Warp → Vector 三级粒度;
-
自动插入 指令间依赖屏障 与 同步点,防止数据 hazard;
-
提供 异步执行接口 ,使 DMA 与计算并行(类似 CUDA 的
cudaStream)。
三、代码示例:用 pto-isa 实现 FP16 向量乘加
下面展示一个简化的 FP16 向量乘加(Vector MAC)示例,计算 z[i] = x[i] * y[i] + z[i]:
#include "pto-isa/core/vector_ops.h"
#include "pto-isa/dma/dma_engine.h"
#include <vector>
#include <cstdint>
void fused_vector_mac_fp16(
uint8_t* x_ptr, // device ptr to FP16 vector x
uint8_t* y_ptr, // device ptr to FP16 vector y
uint8_t* z_ptr, // device ptr to FP16 vector z (in-place)
int32_t len // length of vectors
) {
// 初始化 ISA 执行上下文(自动检测硬件特性)
pto::IsaExecutor executor;
// 配置向量指令参数
constexpr int kVecLen = 128; // 每次处理 128 个 FP16(256 bytes)
const int num_blocks = (len + kVecLen - 1) / kVecLen;
// 异步 DMA 预取(将 x, y 从 global memory 拉入 local buffer)
pto::DmaPrefetchJob dma_job_x{x_ptr, /*local_buf_x*/..., len * sizeof(uint16_t)};
pto::DmaPrefetchJob dma_job_y{y_ptr, /*local_buf_y*/..., len * sizeof(uint16_t)};
executor.submit_dma(dma_job_x);
executor.submit_dma(dma_job_y);
executor.wait_dma(); // 等待 DMA 完成
// 主计算循环(指令级并行)
for (int blk = 0; blk < num_blocks; ++blk) {
const int offset = blk * kVecLen;
const int curr_len = std::min(kVecLen, len - offset);
// 调用 ISA 向量乘加指令
pto::vec::mac_fp16(
/*dst=*/z_ptr + offset,
/*src1=*/x_ptr + offset,
/*src2=*/y_ptr + offset,
/*len=*/curr_len
);
}
// 可选:插入同步屏障,确保后续指令可见更新结果
executor.sync();
}亮点:
-
指令调用与通用 C++ 函数几乎无异;
-
DMA 与计算可重叠,隐藏访存延迟;
-
自动适配不同芯片的向量长度上限。
四、pto-isa 的独特优势
| 维度 | 手写汇编 | pto-isa 高层 API |
|---|---|---|
| 可读性 | 极低(指令十六进制/二进制) | 高(C++ 风格函数) |
| 可维护性 | 难(芯片换代需重写) | 易(可移植适配层) |
| 安全性 | 易出错(寄存器冲突、依赖违例) | 自动处理依赖与同步 |
| 性能 | 理论上限最高 | 接近手写汇编(编译器优化 + 人工微调) |
| 开发效率 | 低(数月实现复杂 kernel) | 高(数周完成同类工作) |
五、pto-isa 使用流程图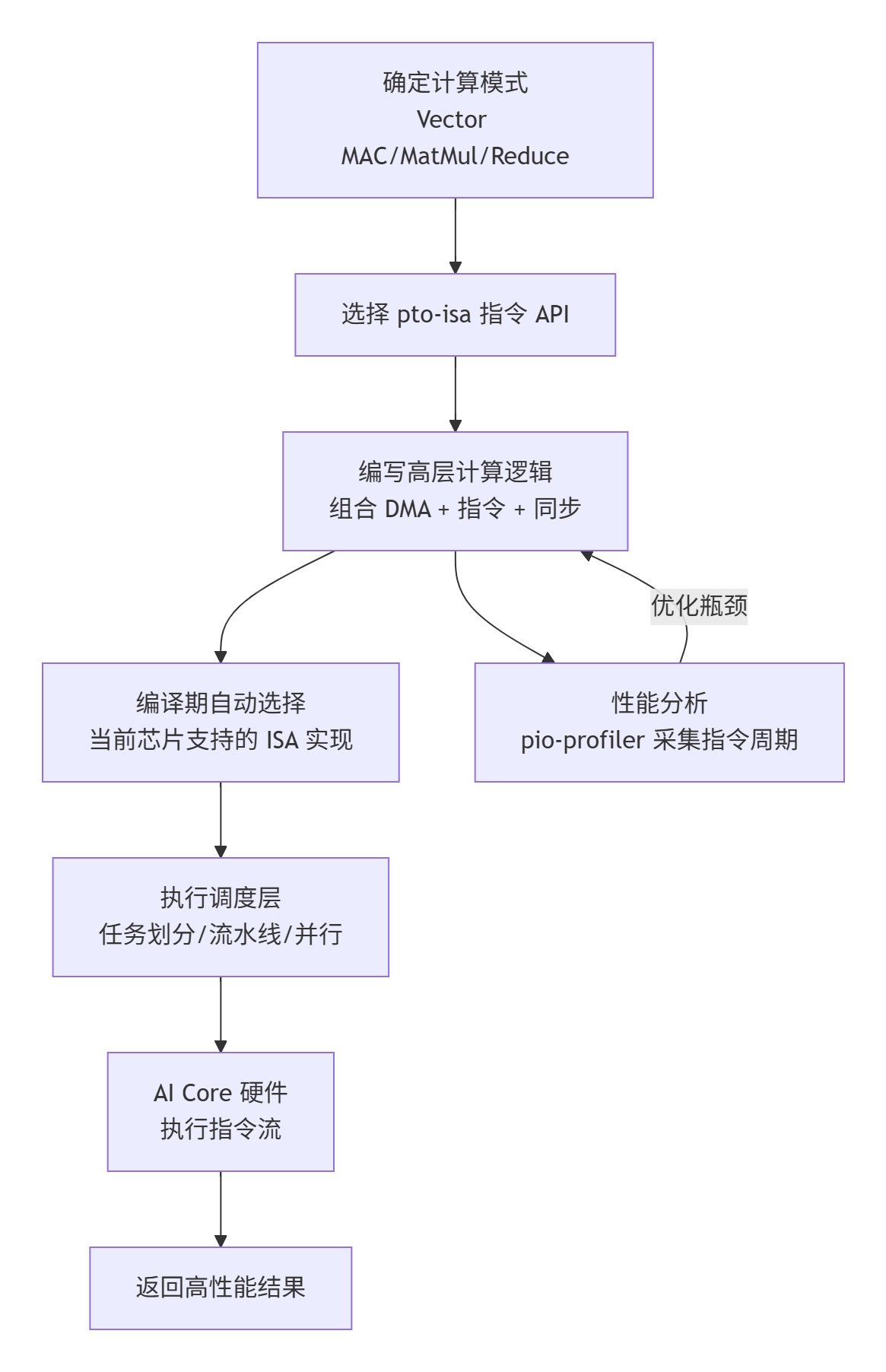
六、典型应用场景
-
自研稀疏/量化算子
利用 INT4/INT8 专用向量指令与矩阵乘指令,实现比通用 kernel 更高的吞吐。
-
新型注意力机制
针对长序列或局部注意力的特殊访存模式,手工编排 DMA + Reduce 指令,降低延迟。
-
硬件特性验证
快速验证新发布 AI Core 的指令特性(如 BF16 向量单元),为后续库开发提供数据。
-
教学与原型研究
在高校或研究机构中,用于演示指令级并行与硬件执行模型的关系。
七、总结与展望
pto-isa 库是 CANN 生态中唯一面向 ISA 级可控编程 的底层工具,它让开发者得以在保持一定生产效率的同时,直接对话 AI Core 的硬件指令集,实现通用库无法触及的性能极限。与 catlass 的模板化、asc-devkit 的低代码开发形成互补,pto-isa 为"极致性能调优"与"新硬件特性探索"提供了最后一层可控空间。
未来,随着芯片引入更多专用指令(如稀疏计算指令、光计算互连指令),pto-isa 的可移植适配层将进一步增强,让在多代硬件上平滑演进,成为 AI Core 指令级开发的"标准语言"。
📌 仓库地址 :https://atomgit.com/cann/pto-isa
📌 CANN组织地址 :https://atomgit.com/cann