记录我自己零开始学习Linux。
[5.1. 什么是 make/makefile?](#5.1. 什么是 make/makefile?)
[5.2 依赖关系和依赖方法](#5.2 依赖关系和依赖方法)
[5.3 使用方法和原理](#5.3 使用方法和原理)
[5.4 .PHONY 的作用](#5.4 .PHONY 的作用)
[5.5 makefile中符号的使用](#5.5 makefile中符号的使用)
[5.6 Makefile 核心知识点总结](#5.6 Makefile 核心知识点总结)
[git clone](#git clone)
[git status](#git status)
[git add](#git add)
[git commit -m](#git commit -m)
[git push](#git push)
前言
我们已掌握 Linux 下 yum、vim 等基础开发工具,能完成软件安装。本篇文章介绍gcc/g++的使用,可以知道代码是如何从普通文件变成可执行文件的,以及 make/makefile的使用与原理,同时结合前文知识实现进度条小程序,串联知识点并落地实战。
一、背景知识
1. 预处理(进行宏替换)
2. 编译(生成汇编)
3. 汇编(生成机器可识别代码)
4. 连接(生成可执行文件或库文件)
二、gcc如何完成
格式: gcc 选项 要编译的文件 选项 目标文件
注:"目标文件" 通常指最终生成的可执行文件或中间文件
gcc选项:
1. 编译流程阶段选项(对应代码→可执行文件的不同步骤)
-E 仅执行预处理(展开头文件、替换宏),不生成文件,需通过重定向输出(如gcc -E test.c > test.i,得到预处理后的.i 文件)
-S 编译到汇编语言阶段,生成.s 后缀的汇编文件(不进行后续的汇编、链接)
-c 编译到目标代码阶段,生成.o 后缀的二进制目标文件(多个.o 文件可后续链接为可执行文件)2. 输出与链接选项
-o 文件名 指定输出文件的名称(如gcc test.c -o test,将编译结果保存为可执行文件test)
-static 采用静态链接:生成的文件体积较大,但不依赖系统的动态库,可在无对应库的机器上运行
-shared 采用动态链接:生成的文件体积小,但依赖系统已安装的对应动态库,否则无法运行3. 调试与优化选项
-g 生成调试信息:配合 GDB 调试工具使用(如gcc -g test.c -o test,可通过gdb test调试)
-O0/-O1/-O2/-O3 编译优化级别:
- O0:无优化(调试代码时用,保留完整的执行逻辑)
- O1:默认优化
- O3:最高级别优化(发布程序时用,提升运行效率)
4. 警告控制选项
-w 关闭所有警告信息(不建议开发时使用,易忽略潜在问题)
-Wall 开启所有警告信息(开发阶段建议启用,帮助发现代码隐患)
三、从普通文件到可执行文件的过程
C 语言普通文本文件(.c)通过 gcc 编译生成可执行文件,需经历预处理、编译、汇编、链接四个核心阶段,每个阶段完成特定任务,最终生成能在 Linux 上直接运行的二进制文件:
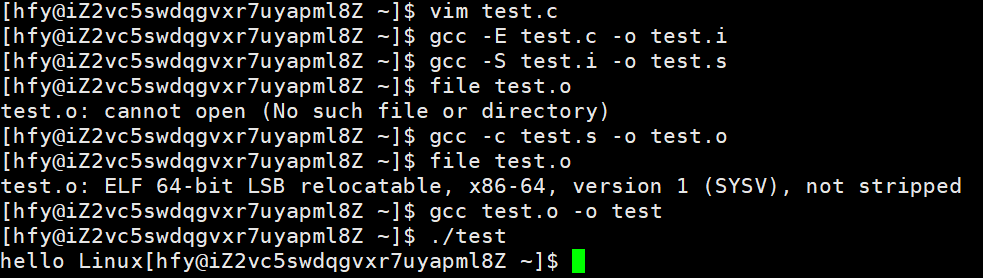
1.预处理 展开头文件(如#include)、替换宏定义(如#define)、删除注释、处理条件编译 gcc -E test.c -o test.i .i 文本文件
2.编译 将预处理后的代码翻译成汇编语言,做语法/语义分析、代码优化,检查语法错误 gcc -S test.i -o test.s .s 文本文件(汇编指令)
3.汇编 将汇编语言代码转化为机器能识别的二进制目标代码(机器指令) gcc -c test.s -o test.o .o 二进制目标文件
4.链接 整合目标文件与系统库(如printf对应的库)、解决函数/变量引用,生成可执行文件 gcc test.o -o test 无后缀(如test) 可执行二进制文件
补充说明:
简化操作:直接执行gcc test.c -o test,gcc 会自动完成上述四阶段,无需分步执行;
链接方式:
静态链接(加-static:gcc test.o -static -o test):把库代码嵌入可执行文件,体积大但不依赖外部库;
动态链接(默认):仅记录库的引用,体积小,运行时需系统存在对应动态库。
总结
核心四阶段:预处理(.i)→ 编译(.s)→ 汇编(.o)→ 链接(可执行文件);
gcc 的-E/-S/-c选项分别对应前三个阶段,可分步查看每个阶段的输出;
链接是收尾关键:整合目标文件与系统库,分静态 / 动态两种方式,影响文件体积和运行依赖。
四、函数库
函数库是预先编译好的可复用代码集合,比如我们代码中用到的printf()、scanf()等函数,并非手写实现,而是来自系统自带的libc函数库。gcc 在链接阶段的核心作用之一,就是将我们的目标文件(.o)与所需的函数库整合,最终生成可执行文件。
函数库主要分为静态库和动态库两类,两者在编译链接方式、文件特性上差异显著: 静态库(.a)
核心特点
编译链接时,gcc 会将静态库中用到的代码完整复制到可执行文件中;
生成的可执行文件体积大,但运行时不依赖任何外部库,可在无对应库的 Linux 机器上直接运行;
静态库后缀为.a(如libmath.a)。
静态库的使用示例(创建 + 链接)
步骤 1:编写库源码(以自定义加法函数为例)
# 1. 创建库源码文件math.c
vim math.c输入代码:
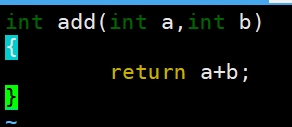
// math.c - 静态库源码
int add(int a, int b) {
return a + b;
}
步骤 2:编译生成目标文件(.o)
gcc -c math.c -o math.o步骤 3:创建静态库(ar 命令)
ar rcs libmath.a math.o # r:替换/添加文件;c:创建库;s:生成索引
# 静态库命名规范:以lib开头,后缀.a步骤 4:链接静态库到主程序
# 主程序test.c(调用add函数)
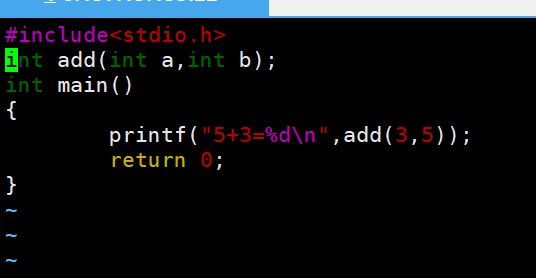
vim test.c输入代码:
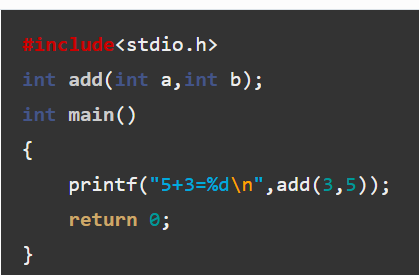
#include <stdio.h>
// 声明库函数
int add(int a, int b);
int main() {
printf("3+5=%d\n", add(3, 5));
return 0;
}步骤 5:编译主程序并链接静态库
gcc test.c -o test_static -L. -lmath # -L.:指定库在当前目录;-lmath:链接libmath.a(省略lib和.a)
# 或直接用-static强制链接系统库为静态(如libc)
gcc test.c -o test_static_all -static -L. -lmath步骤 6:运行验证
./test_static # 输出:3+5=8
动态库(.so)
核心特点
编译链接时,gcc不复制库代码,仅在可执行文件中记录 "依赖的动态库名称和路径";
生成的可执行文件体积小,但运行时必须依赖系统中已安装的对应动态库,否则报错;
动态库后缀为.so(如libc.so.6),Linux 系统默认优先使用动态库链接。
动态库的使用示例(创建 + 链接)
步骤 1:编译生成位置无关的目标文件(-fPIC)
gcc -c -fPIC math.c -o math.o # -fPIC:生成位置无关代码(动态库必需)步骤 2:创建动态库
gcc -shared -o libmath.so math.o # -shared:生成动态库步骤 3:链接动态库到主程序
gcc test.c -o test_dynamic -L. -lmath步骤 4:运行动态链接的程序(解决库路径问题)
临时指定动态库路径(终端生效):
export LD_LIBRARY_PATH=./:$LD_LIBRARY_PATH
./test_dynamic # 输出:3+5=8查看可执行文件的库依赖
通过ldd命令可查看可执行文件依赖的动态库:
ldd test_dynamic # 输出包含libmath.so、libc.so.6等依赖
ldd test_static # 输出:not a dynamic executable(静态库无动态依赖)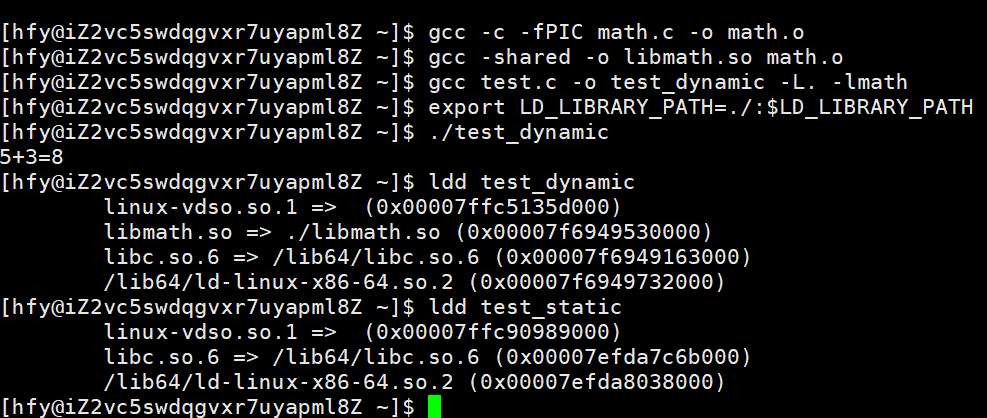
静态库 vs 动态库核心对比
特性 静态库(.a) 动态库(.so)
链接方式 复制代码到可执行文件 仅记录库引用
可执行文件体积 大 小
运行依赖 无外部库依赖 依赖系统动态库
升级维护 库升级需重新编译程序 库升级无需重新编译程序
gcc 编译选项 -static -shared(创建)/ 默认(链接)
总结
函数库是复用代码的集合,gcc 链接阶段需关联对应库才能生成可执行文件;
静态库(.a)编译时嵌入可执行文件,体积大但无依赖;动态库(.so)仅记录引用,体积小但依赖系统库;
静态库用ar rcs创建、-static链接;动态库需加-fPIC/-shared创建,ldd可查看动态依赖。
五、Linux项目自动化构建工具-make/makefile
5.1. 什么是 make/makefile?
一个工程中的源文件不计数,其按类型、功能、模块分别放在若干个目录中,makefile定义了⼀
系列的规则来指定,哪些文件需要先编译,哪些文件需要后编译,哪些文件需要重新编译,甚⾄
于进行更复杂的功能操作。
makefile带来的好处就是------"自动化编译",一旦写好,只需要一个make命令,整个工程完全
自动编译,极大的提高了软件开发的效率。
make是一个命令工具,是一个解释makefile中指令的命令工具,一般来说,大多数的IDE都有这
个命令,比如:Delphi的make,Visual C++的nmake,Linux下GNU的make。可见,makefile
都成为了⼀种在工程方面的编译方法。
make是一条命令,makefile是一个文件,两个搭配使用,完成项目自动化构建。
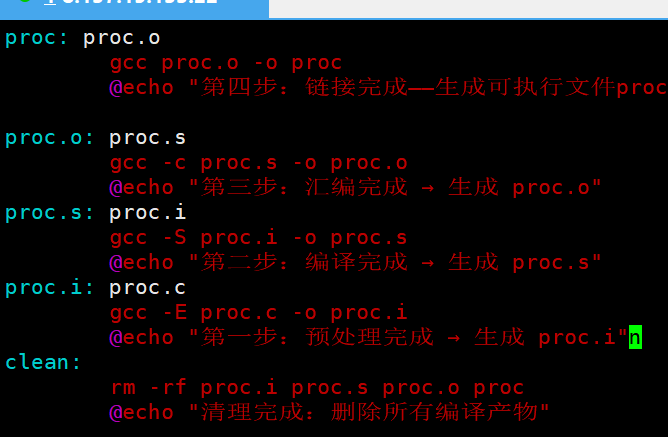
5.2 依赖关系和依赖方法
# 🟥 目标文件:最终要生成的可执行程序
proc: proc.c # 🟦 依赖文件列表:生成proc必须的源文件(冒号右边可跟多个文件)
# 🟩 依赖方法:编译命令(必须以 Tab 开头!⚠️ 用空格会报错)
gcc -o proc proc.c
# 🟪 伪目标:清理生成的文件(.PHONY 避免和同名文件冲突)
.PHONY: clean
clean:
rm -rf proc颜色 标注内容 作用
🟥 红色 proc 目标文件:你最终要得到的可执行程序
🟦 蓝色 proc.c 依赖文件:生成目标必须的 "原材料"
🟩 绿色 gcc -o proc proc.c 依赖方法:把依赖文件变成目标的具体命令
🟪 紫色 .PHONY: clean 伪目标:避免和项目中同名文件冲突,确保清理命令始终执行
目标文件(proc):你最终要生成的结果(这里是可执行程序)。
依赖文件列表(proc.c):冒号右边的 "原材料",生成目标必须的前置文件,多个文件用空格分隔(比如 proc: a.c b.c)。
依赖关系:proc 必须依赖 proc.c 才能生成 ------ 没有 proc.c 就编不出 proc,这就是 "谁依赖谁" 的因果逻辑。
依赖方法:Tab 开头的 gcc -o proc proc.c,是生成目标的 "具体操作步骤"------ 告诉 make "用这条命令把依赖文件变成目标文件"。
⚠️ 语法红线:命令行必须以 Tab 开头,用空格会直接报错!
makefile 的本质是依赖关系和依赖方法的集合。
依赖关系 → 定义 "要生成目标,需要先有哪些文件"
依赖方法 → 定义 "用什么命令把依赖文件变成目标文件"
二者配合,让 make 工具能自动判断 "哪些文件需要更新""怎么更新",真正实现自动化构建。
5.3 使用方法和原理
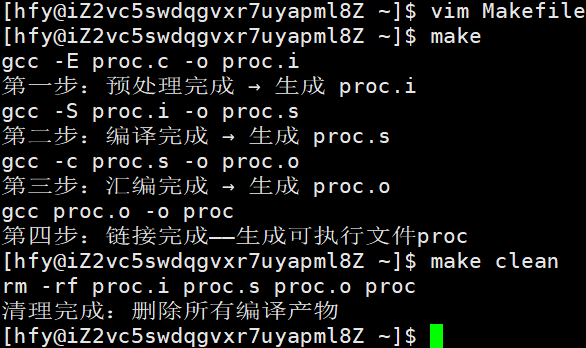
1.makefile文件,会被make从上到下开始扫描,第一个目标名,是缺省形成的。如果我们想执行其它组的依赖关系和依赖方法,就要make name。

输入make,开始执行make指令。检测到源文件 proc.c 后,编译生成可执行文件 proc,通过 ls -l 可以看到这个绿色的可执行文件。

执行清理指令后,编译生成的
proc文件被删除,只保留了原始的源代码文件。

如下图所示:
@:关闭命令回显。如果不加 @,执行时会先输出 echo "hahahahaa" 本身,再输出内容;加了 @ 就只会显示 hahahahaa。
echo:就是 Linux 里的输出命令,这里只是反复打印字符串,你可以换成任意合法的 Shell 指令(比如 gcc 编译命令)。
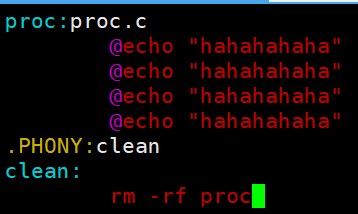
2. make/makefile在执行gcc命令的时候,如果发生了语法错误,就会终止。
如图:
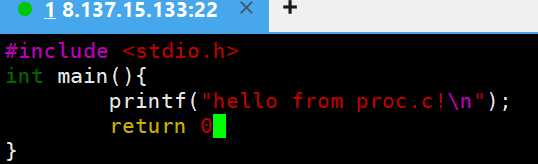
我的C语言代码中街return 0后面没有;那么make/makefile在执行过程中会出现什么问题?
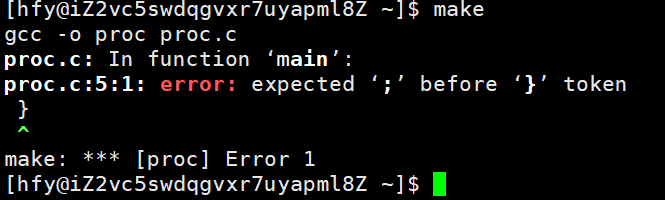
make 工具对命令执行的结果非常敏感,核心规则是:
每个 Shell 命令(包括 gcc)执行后都会返回一个退出码(0 表示成功,非 0 表示失败)。
默认情况下,只要某一条命令返回非 0 退出码(比如 gcc 检测到语法错误),make 就会立即终止后续所有命令的执行,并输出错误信息。
这是 make 的 "安全设计"------ 编译步骤失败后,后续的链接、清理等操作已无意义,终止可避免无效操作和错误累积。
3. make解释makefile的时候,是会自动推导的。一直推导,推导过程不执行依赖方法,直到推导有依赖文件的存在,然后再逆向执行所有的依赖方法。
首先,这是一个新的makefile的代码:
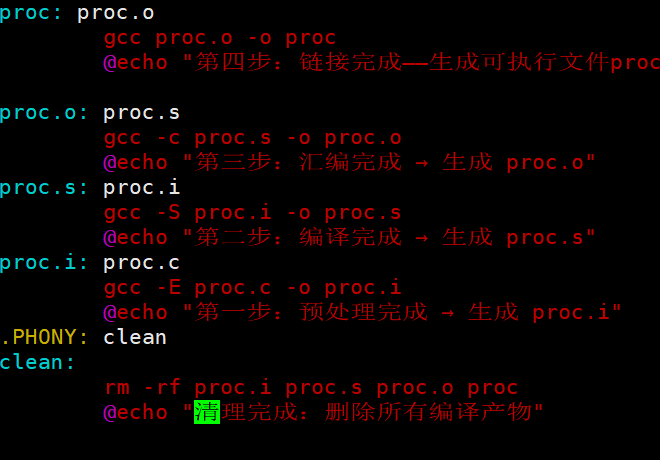
接下来准备proc.c的代码:
进行测试:
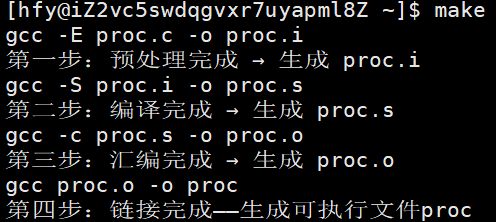
在输入ls -l指令,就可以看到proc.i、proc.s、proc.o、proc 四个文件。

接着输入./proc指令:

再测试make clean指令:


5.4 .PHONY 的作用
.PHONY 是 Makefile 中的一个伪目标声明,它的核心作用是明确告诉 make:这个目标不对应任何实际文件,只是一个需要执行命令的入口。
我们通过 "有无 .PHONY" 的现象对比,再结合底层原理来拆解。
不加 .PHONY 的默认行为
Makefile 内容
执行现象
现象解析:
因为目录中没有名为 clean 的文件,make 会执行 clean 目标对应的命令,正常删除所有编译产物。
这是首次执行时的 "正常表现",容易让你误以为没有问题
如果不小心生成了一个名为 clean 的文件(比如误执行 touch clean),再执行 make clean:
# 生成一个空的clean文件 touch clean # 执行make clean make clean现象解析:
make 会把 clean 当成普通文件目标,检查到它已经存在且没有依赖更新,就会认为 "目标已是最新",完全不执行清理命令。
这就是不加 .PHONY 的核心风险:一旦出现同名文件,清理操作会彻底失效。

最后,make 的默认逻辑是 "目标是文件",只有当文件不存在或依赖更新时才会执行命令。而 clean 是 "操作型目标"(不是生成文件),必须用 .PHONY: clean 声明为伪目标,才能让 make 跳过文件检查,始终执行清理命令。
5.5 makefile中符号的使用
命令控制符号(@、-):控制命令执行的输出 / 容错
@ 符号(关闭命令回显)
无 @的情况(默认行为)
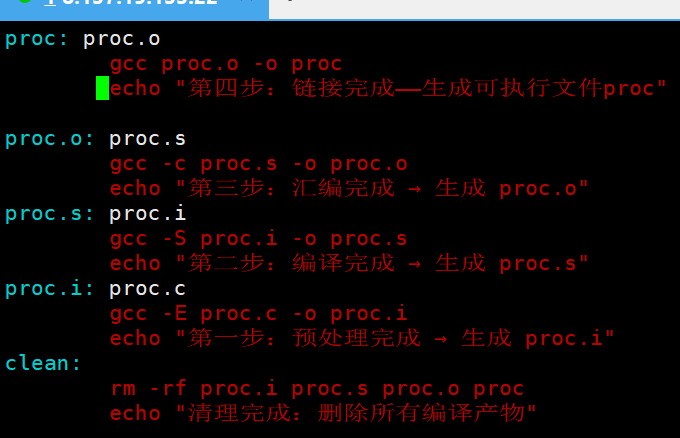
输出结果:
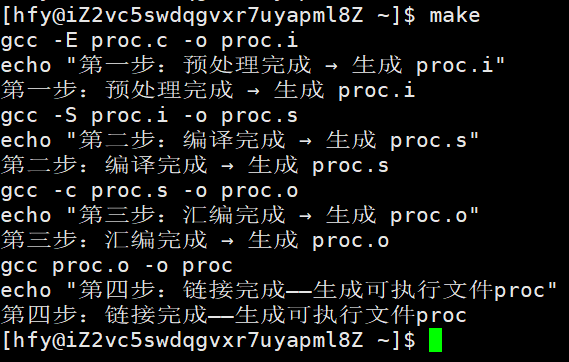
有 @的情况(关闭回显)
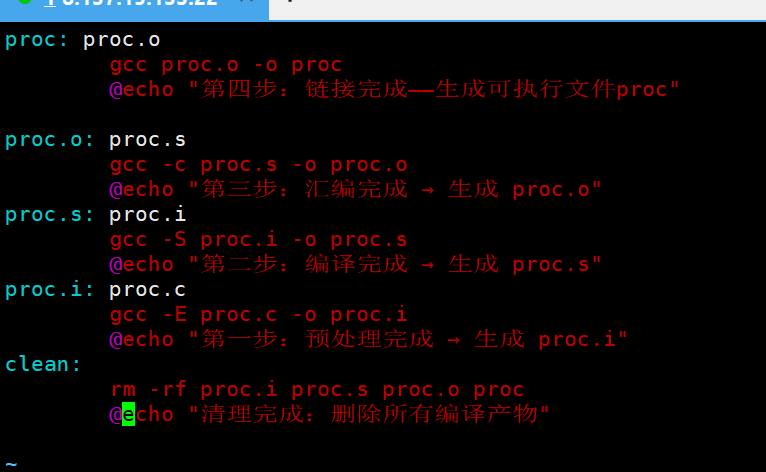
输出结果:
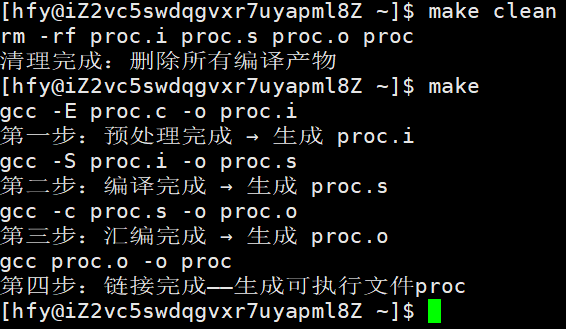
底层逻辑
@ 是命令回显开关,作用是抑制 make 打印命令本身,只输出命令的执行结果,让终端输出更简洁,是 Makefile 中最常用的符号之一。
- 符号(忽略命令执行错误)
无 - 的情况(报错终止)
makefile中
clean:
rm -rf proc # 假设当前目录没有proc文件执行 make clean的输出:
plaintext
rm -rf proc
make: [clean] Error 1 (ignored) # 报错,流程可能中断有 - 的情况(忽略错误)
makefile
clean:
-rm -rf proc # 加-执行 make clean 的输出:
plaintext
rm -rf proc # 即使文件不存在,也不报错,流程继续底层逻辑
- 是错误忽略符,即使命令执行失败(返回非 0 状态码),make 也不会终止后续命令执行,适合清理 / 删除类命令(避免 "文件不存在" 导致流程中断)。
变量赋值符号(=、:=、?=、+=):控制变量的赋值时机 / 方式
Makefile 的变量赋值分 "延迟展开" 和 "立即展开",用实验对比最直观:
= (延迟展开):
VAR = hello
TEST = $(VAR) world # 赋值时暂不计算VAR的值
VAR = hi # 后续修改VAR
all:
@echo $(TEST)执行 make 输出:hi world
底层逻辑
=是延迟展开赋值 ,变量的实际值在使用时才计算,而非赋值时。后续修改原变量,会影响依赖它的变量。
:= (立即展开)
VAR := hello
TEST := $(VAR) world # 赋值时立即计算VAR的值
VAR := hi # 后续修改不影响TEST
all:
@echo $(TEST)执行 make 输出:hello world
底层逻辑
:=是立即展开赋值 ,变量值在赋值时就固定,后续修改原变量不会影响它,适合需要 "固定值" 的场景。
?= (条件赋值)
VAR ?= hello # 只有VAR未定义时才赋值
TEST ?= hi
all:
@echo VAR=$(VAR)
@echo TEST=$(TEST)直接执行 make → 输出:VAR=hello TEST=hi
执行 make VAR=test → 输出:VAR=test TEST=hi
底层逻辑
?=是条件赋值 ,仅当变量未定义时赋值;若变量已定义(如命令行传参),则保留原值,适合给变量设默认值。
+= (追加赋值)
CFLAGS = -Wall # 初始编译参数
CFLAGS += -g -O2 # 追加调试+优化参数
all:
@echo CFLAGS=$(CFLAGS)执行 make 输出:CFLAGS=-Wall -g -O2
底层逻辑
+=是追加赋值,在变量原有值末尾添加新内容,自动加空格分隔,适合逐步构建编译参数(如 CFLAGS、LDFLAGS)。
自动变量符号(、^、$<):简化依赖 / 目标引用
自动变量是 Makefile 的 "快捷变量",能自动匹配目标 / 依赖,避免重复写文件名,核心三个:
符号 含义 实操案例
@ 当前目标名 proc: proc.c → gcc -o @ \^ 等价于 gcc -o proc proc.c ^ 当前目标的所有依赖(去重) proc: a.c b.c → \^ = a.c b.c < 当前目标的第一个依赖 %.o: %.c → $< = 对应的.c 文件
自动变量的简化效果
不用自动变量(冗余)
proc: a.c b.c
gcc -o proc a.c b.c # 文件名重复写,修改麻烦用自动变量(简洁)
proc: a.c b.c
gcc -o $@ $^ # $@=proc,$^=a.c b.c,修改文件名只需改依赖执行效果完全一致,但代码更简洁,维护成本更低。
基础核心符号
1. : (目标 - 依赖分隔符)
作用:分隔 "目标名" 和 "依赖列表",是 Makefile 的核心语法。
示例:proc: proc.c → 左边是目标,右边是依赖。
注意:冒号后可加空格 / 换行,依赖列表换行需用 \ 连接。
2. .PHONY (伪目标声明)
作用:声明目标为 "伪目标",不对应实际文件,强制执行命令。
示例:.PHONY: clean all test → 确保这些目标每次执行都生效,避免同名文件冲突。
核心结论
Makefile 的符号是 "效率工具",核心记住:
命令控制:@ 关回显、- 忽略错误;
变量赋值:= 延迟、:= 立即、?= 默认、+= 追加;
自动变量:$@ 目标、$^ 所有依赖、$< 第一个依赖;
基础符号:: 分隔目标 / 依赖,.PHONY 声明伪目标。
5.6 Makefile 核心知识点总结
1、Makefile 的核心作用
Makefile 文件中保存了编译器、链接器的参数选项,描述了所有源文件的依赖关系。make 程序会读取 Makefile 中的数据,根据规则调用编译器、汇编器、链接器生成最终输出。
2、Makefile 的五大组成部分
显式规则:明确说明如何生成一个或多个目标文件。
隐晦规则:借助 make 的自动推导功能,简化 Makefile 编写(例如自动判断源文件与目标文件的时间关系)。
变量定义:定义的变量会在执行时扩展到引用位置,通常用 $(var) 表示引用。
文件指示:支持在一个 Makefile 中引用另一个 Makefile,类似 C 语言的 include。
注释:用 # 在行首表示行注释。
3、make 命令的默认行为
文件查找顺序:默认在当前目录按顺序查找 GNUmakefile、makefile、Makefile。
默认目标规则:默认只生成第一个目标对象,会递归生成该目标的所有依赖对象后,再生成第一个目标,生成后即退出。
增量编译逻辑:通过对比目标与依赖文件的修改时间,仅当源文件在上次生成后有修改时,才会重新生成目标。
4、伪目标(.PHONY)
伪目标的名称不对应实际文件,与同名实际文件无关联,无论同名文件是否存在,都会执行对应指令。
核心作用:
让目标无论如何都能重新生成;
不生成目标文件,仅用于执行特定指令(如清理、测试)。
声明方式:.PHONY: clean(最典型场景是声明 clean 为伪目标)。
六、进度条的实现
使用vim,gcc/g++,make/makefile写一个偏系统的样例程序 -- 进度条。
首先,先理解一个概念就是回车换行的本质
回车 \r:将光标从当前位置移到本行的第一个字符位置(不换行)。
换行 \n:将光标从当前位置移到下一行的相同列位置(不回到行首)。
新起一行的完整动作:先执行回车 \r,再执行换行 \n(即 \r\n)。
接着,是行缓冲区的原理与刷新规则
输出字符串不会直接打印到终端,而是先暂存到输出缓冲区中,满足刷新条件时才会输出。
两种实验现象对比
代码特征 执行顺序与效果
带 \n(如 printf("hello Linux!\n");) \n 触发行刷新,字符串立即输出到终端,再执行后续代码(如 sleep(2))。
不带 \n(如 printf("hello Linux!");) 字符串暂存于缓冲区,先执行后续代码(如 sleep(2)),程序结束时才输出字符串。
缓冲区刷新策略
自动刷新:遇到 \n 触发行刷新;程序正常结束时自动刷新。
手动刷新:调用 fflush(stdout) 强制将缓冲区内容输出到终端。
了解如上的基础概念后为后续进度条的实现奠定基础。
所以我们选择两点来设计进度条:
动态更新核心 :利用 \r 让光标回到行首,覆盖原有内容,实现进度条的 "原地更新" 效果。
实时显示保证 :每次更新后调用 fflush(stdout) 强制刷新,避免缓冲区延迟。
进度条的实现也采用多文件形式:
process.h:放函数声明
process.c:放函数的实现
main.c:调用函数
版本一:
process.h:函数声明
cpp
#pragma once
#include <stdio.h>
void proce();process.c:函数的实现
cpp
#include"process.h"
#include<string.h>
#include<unistd.h>
#define NUM 101
#define STYLE1 '#'
#define STYLE2 '*'
#define STYLE3 '='
void proce()
{
int cnt=0;
char bar[NUM];
memset(bar,'\0',sizeof(bar));
//旋转光标
char cursor[] = {'|', '\\', '-', '/'};
int len=strlen(cursor);
while(cnt<=100)
{
printf("[%-100s [%d%%] [%c] \r",bar,cnt,cursor[cnt%len]);
fflush(stdout);//强制刷新缓冲区
bar[cnt++]=STYLE1;
if(cnt==NUM)
{
bar[cnt -1]='\0';
printf("[%-100s] [%d%%] [%c] \r",bar,cnt-1,cursor[cnt%len]);
break;
}
bar[cnt]='>';
usleep(50000);
}
printf("\n\r");
}main.c:调用函数
cs
#include "process.h"
int main()
{
proce();
return 0;
}版本二:
process.h:函数声明
cpp
#pragma once
#include<stdio.h>
void FlushProcess(double current,double total);process.c:函数的实现
cpp
#include"process.h"
#include<string.h>
#include<unistd.h>
#define NUM 101 // 100个进度字符 + 1个终止符'\0'
#define STYLE1 '#' // 进度条填充字符
#define STYLE2 '*'
#define STYLE3 '='
void FlushProcess(double current,double total)
{
//1.更新当前进度条的百分比
double rate=(current/total)*100;
//2. 更新进度条主体 1% 更新一个等号
char bar[NUM];
memset(bar,'\0',sizeof(bar));
for(int i=0;i<(int)rate;i++)
{
bar[i]=STYLE2;
}
// 3. 更新旋转光标或其他风格
const char* label = "|/-\\";
static int num =0;
num++;
int len =strlen(label);
num%=len;
printf("[%-100s] [%.1lf%%][%c]\r", bar, rate, label[num]);
fflush(stdout);
}main.c:调用函数
cpp
#include"process.h"
#include<time.h>
#include<stdlib.h>
#include<unistd.h>
typedef void*(*Flush_t)(double current, double total);
double total =2048.0;
int base =100;
double once = 0.5;
void download(Flush_t f)
{
//模拟下载进度
double current =0.0;
while(current<total)
{
int rate=rand()%base+1;
current+=rate*once;
if(current>=total)
current=total;
usleep(5000);
// 更新除本次新的下载量
// 根据真实的应用场景,进行动态刷新
f(current,total);
}
printf("\n");
}
int main()
{
srand(time(NULL));
download((Flush_t)FlushProcess);
return 0;
}七、Linux上git的使用
在Linux建立仓库之前,需要有在Windows下的经验,这样方便操作。
git clone
使用:git clone +地址链接
功能:获取远端仓库,使本地与远端建立联系。git status
使用:git status
功能:查看git仓库的状态。首先先进入到这个仓库的目录中,在查看仓库状态。

下面的三条指令是git上传的基本操作:
git add
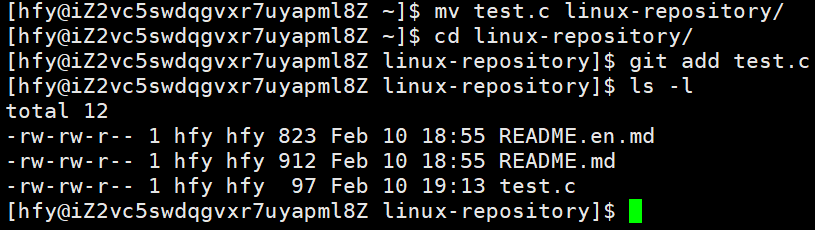
使用:git add 文件名
功能:把文件添加到git的暂存区如图,我想把test.c的内容上传上去。
需要注意的是:我们在linux-repository/ 目录下执行 git add test.c,但这个目录里并没有 test.c 文件,test.c 其实在上级目录 ~ 里。所以我们需要先将test.c mv到这个目录下。
但git add 的作用是把文件添加到 Git 的暂存区(stage),而不是直接提交到版本库。
它只是一个 "预备提交" 的步骤,让 Git 知道你接下来要把哪些修改包含到下一次提交里。
暂存区的修改可以用 git restore --staged <file> 命令撤销(unstage),回到未暂存状态。git commit -m
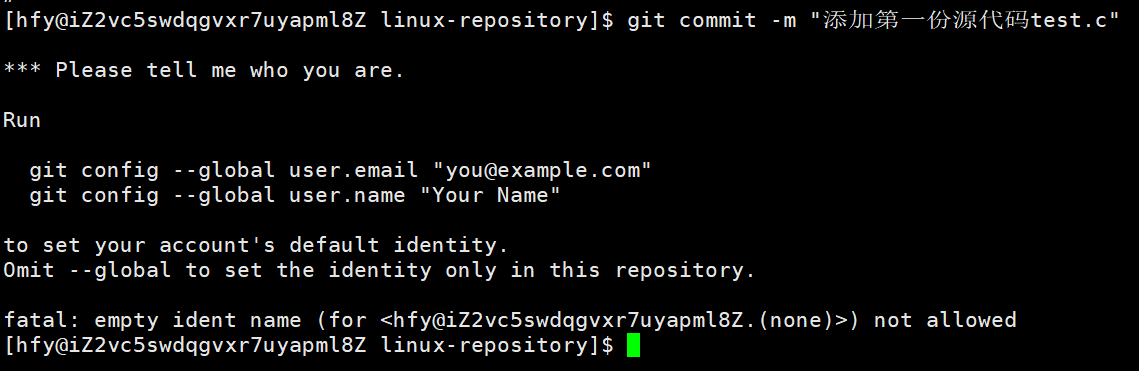
git commit -m "提交说明" 的作用是把暂存区的修改正式提交到本地 Git 仓库,生成一条永久的提交记录。
-m 选项后面必须跟一个字符串,作为本次提交的说明信息,用来描述你做了什么修改。
提交说明不能乱写,要清晰、有意义,方便以后回溯代码。这个报错是因为 Git 还不知道你的身份信息,需要先配置一下 user.email 和 user.name 才能提交。
git config --global user.email "你的邮箱地址"
git config --global user.name "你的名字"
这里的邮箱地址随便填一个就行,不用真的能收邮件,Git 只是要个标识。
现在你的代码已经安全地保存在本地 Git 仓库中了
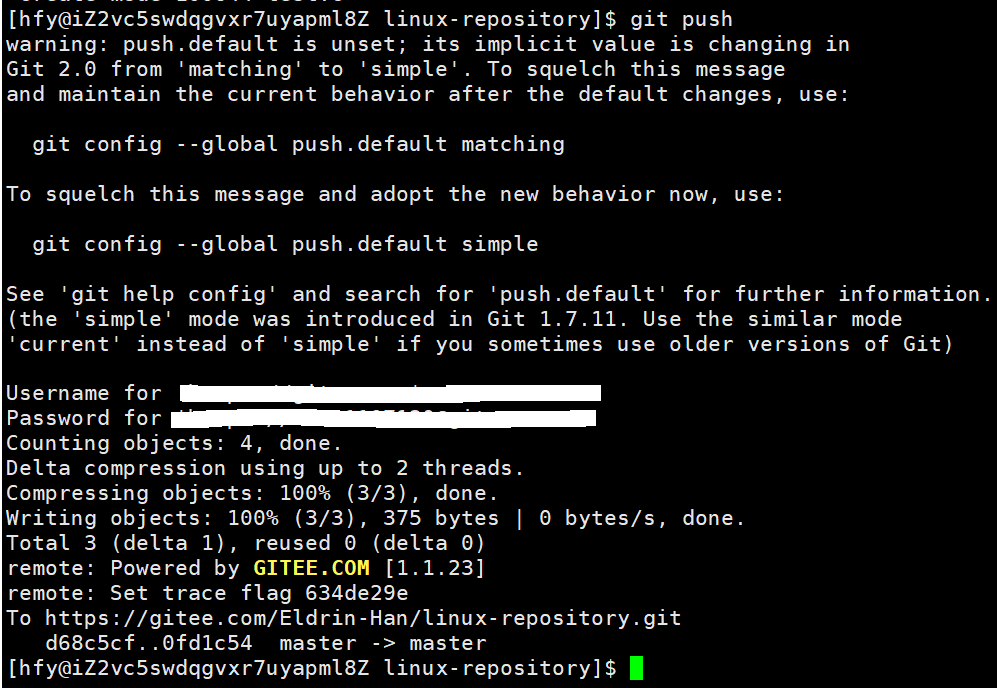
git push
使用:git push
功能:实现本地仓库与远程仓库的同步