在规模化部署和商业落地场景中,推理速度的权重日益提升,甚至在许多情况下超过了单纯的模型参数量,成为决定其工程价值的关键因素。尽管自回归(Autoregressive,AR)生成范式凭借稳定性和成熟生态,仍是当前主流解码方式,但其逐 token 生成的内在机制,使模型在推理阶段几乎无法充分利用并行计算资源。 这一限制在长文本生成、复杂推理和高并发服务场景中尤为突出,也直接推高了推理延迟与算力成本。
为突破这一瓶颈,研究界近年来不断探索并行解码路径,其中扩散语言模型(Diffusion Language Models,DLMs)因其「每步生成多个 token」的特性,被视为最具潜力的替代方案之一。 然而,理想与现实之间仍存在明显鸿沟:在真实部署环境中,许多 DLLMs 并未展现出预期中的速度优势,甚至在性能上难以超越高度优化的 AR 推理引擎(如 vLLM)。问题并非源于并行本身,而是隐藏在模型结构与系统层面的深层冲突之中------大量现有扩散方法依赖双向注意力机制,破坏了前缀 KV 缓存这一现代推理系统的效率基石,迫使模型反复重算上下文,抵消了并行带来的潜在收益。
在此背景下,腾讯微信 AI 团队提出了 WeDLM(WeChat Diffusion Language Model), 这是首个在工业级推理引擎(vLLM)优化条件下,推理速度超越同等 AR 模型的扩散语言模型。其核心思想是在保持严格因果掩码的前提下,让每个被掩码位置都能够条件化于当前所有已观测的 token。为此,研究人员引入了一种拓扑重排(Topological Reordering)方法,在不改变 token 逻辑位置的情况下,将已观测 token 移动到物理上的前缀区域。
实验结果表明,WeDLM 在保持强自回归 backbones 生成质量的同时,实现了显著的推理加速,具体而言,其在数学推理等任务上相较 vLLM 部署的 AR 模型实现了 3 倍以上加速,低熵场景的推理效率提速更是达到 10 倍以上。
目前,「WeDLM 高效大语言模型解码框架」已上线 OpenBayes 官网的教程版块,点击下方链接即可体验一键部署教程 ⬇️
教程链接:
Demo 运行
01
Demo 运行阶段
1.登录 OpenBayes.com,在「公共教程」页面,选择「WeDLM 高效大语言模型解码框架」教程。
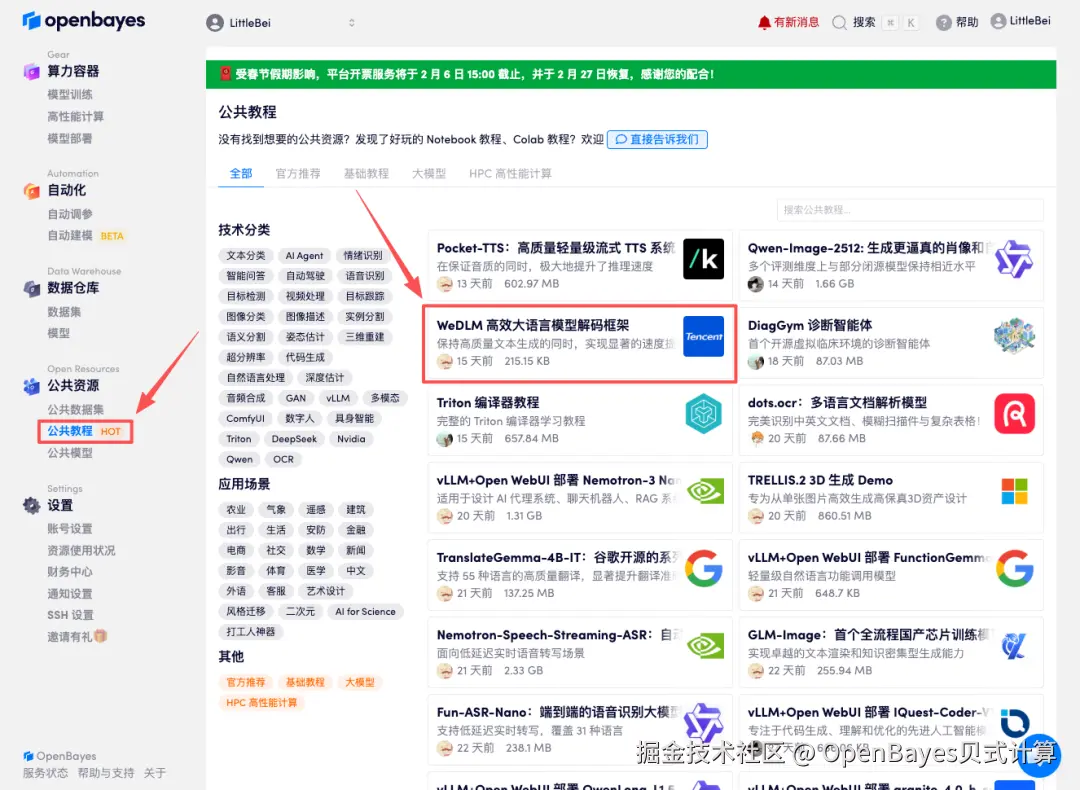
2.页面跳转后,点击右上角「克隆」,将该教程克隆至自己的容器中。
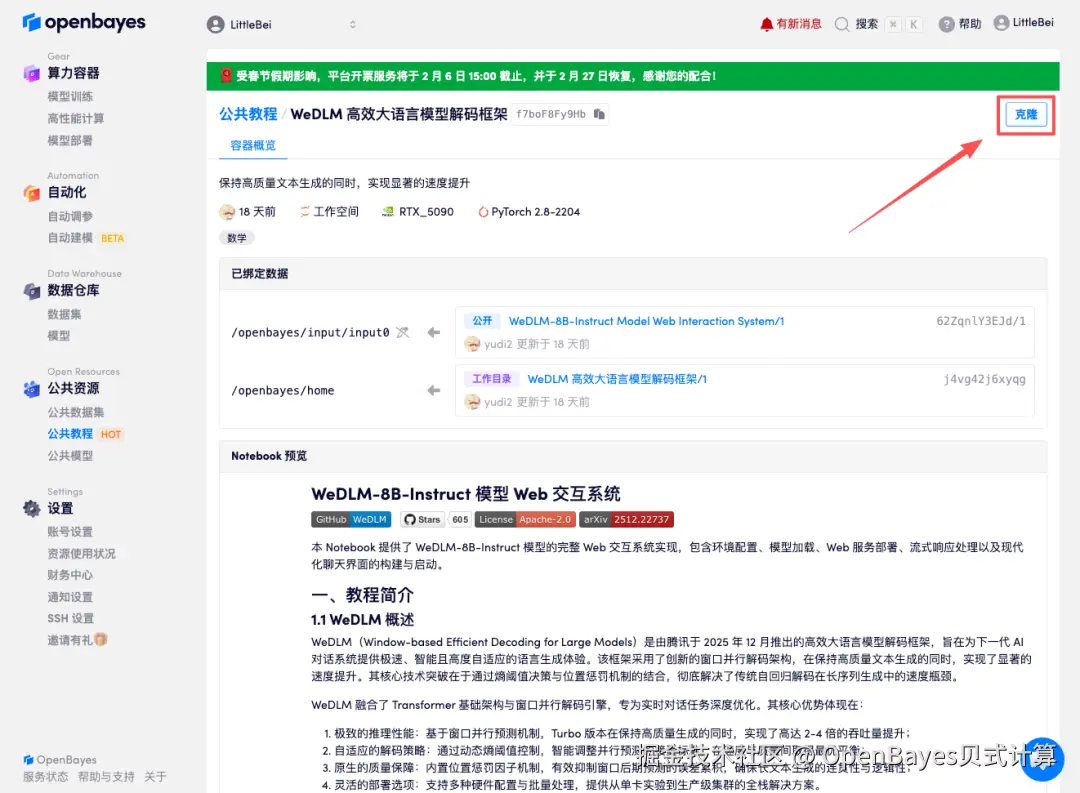
3.选择「NVIDIA GeForce RTX 5090」以及「PyTorch」镜像,按照需求选择「按量付费」或「包日/周/月」,点击「继续执行」。新用户使用下方邀请链接注册,即可获得满 ¥10 赠 ¥10 优惠券,更有机会获得 ¥15 赠金!
小贝总专属邀请链接(直接复制到浏览器打开):
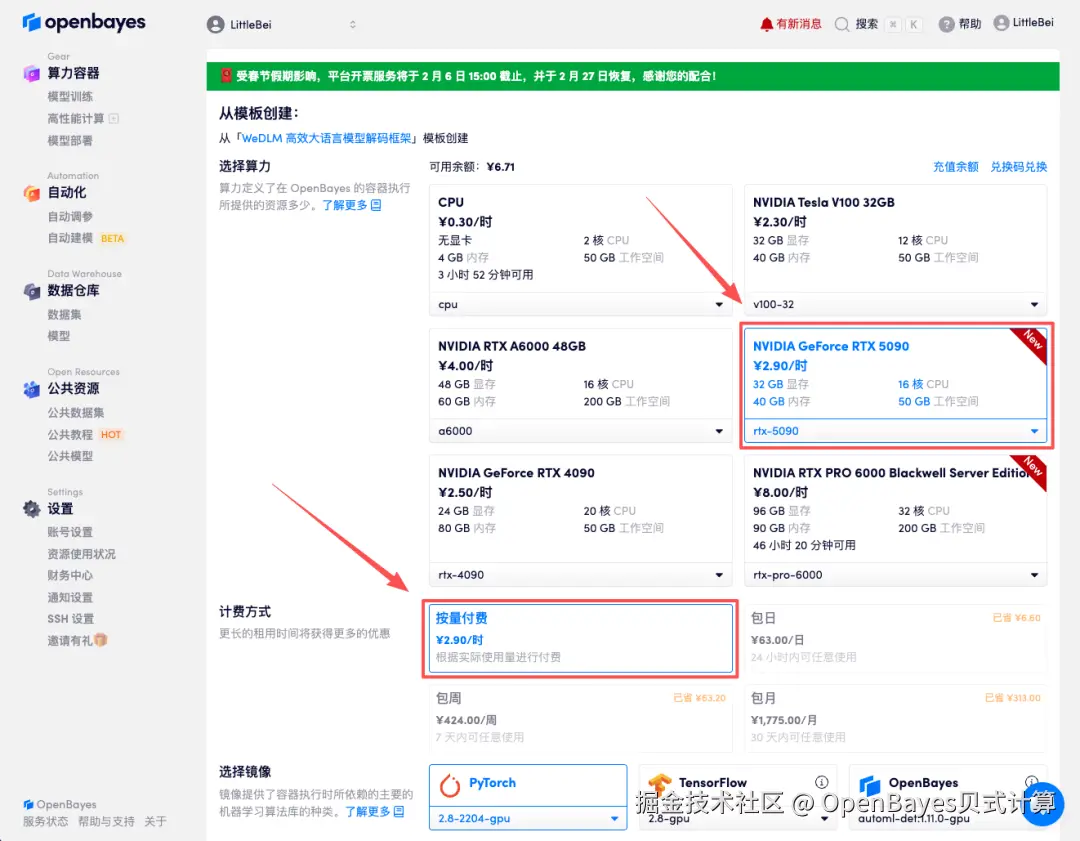
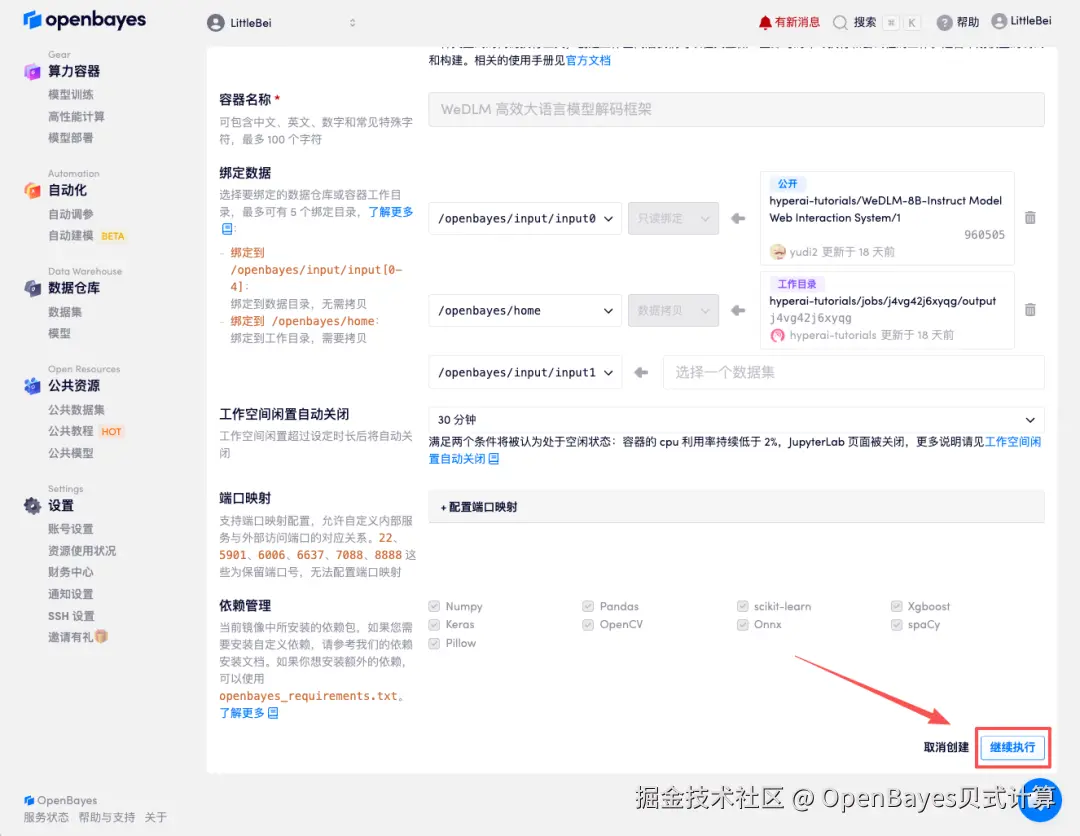
4.等待分配资源,当状态变为「运行中」后,点击「打开工作空间」进入 Jupyter Workspace。
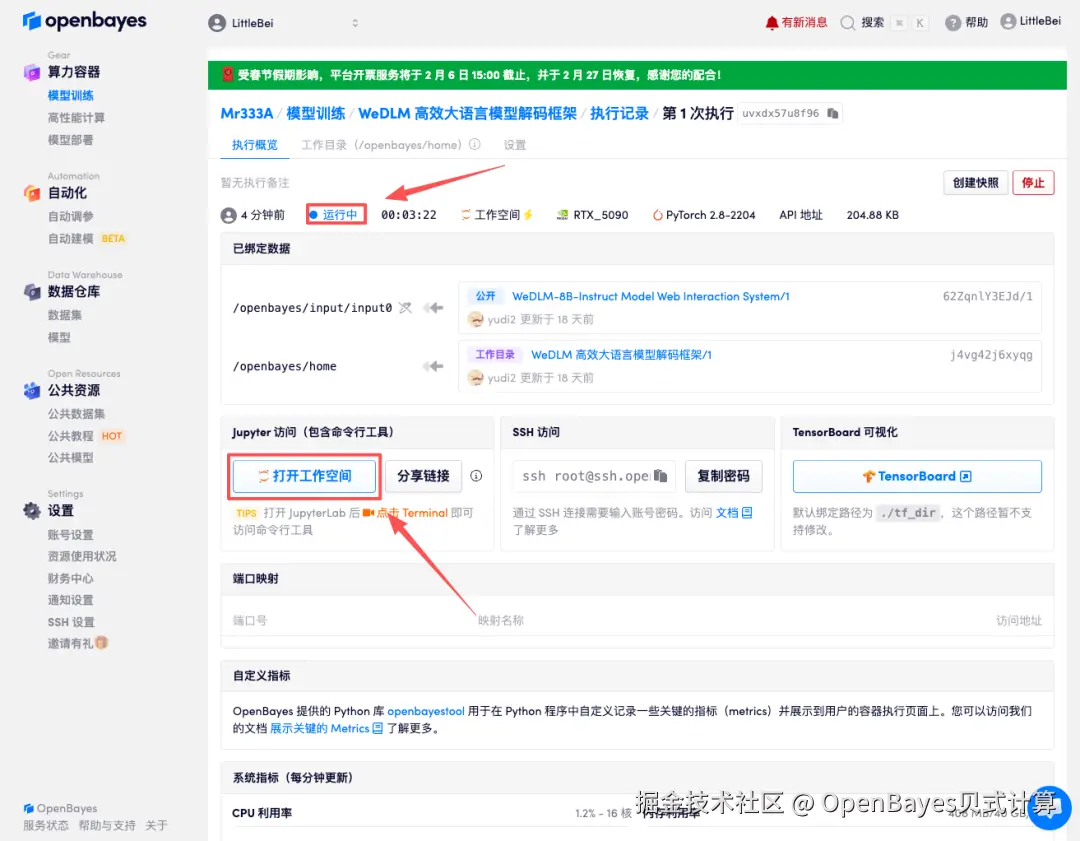
02
效果演示
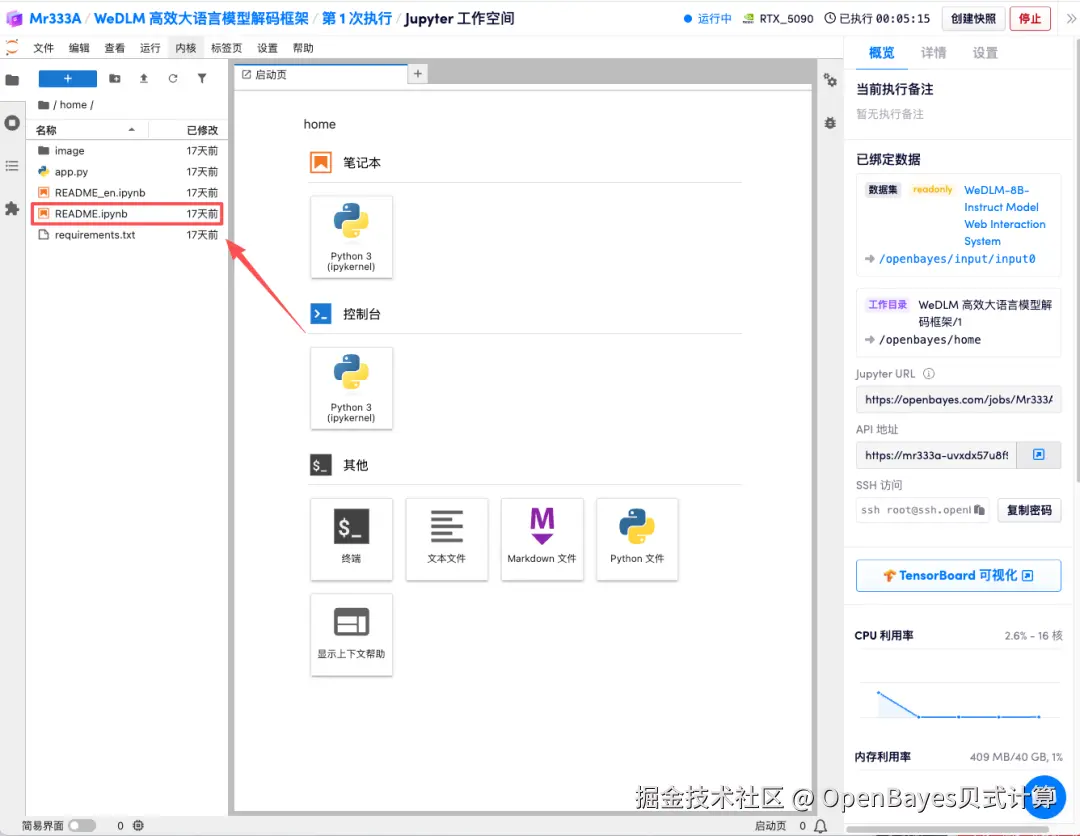
页面跳转后,点击左侧 README 页面,进入后点击上方「运行」。
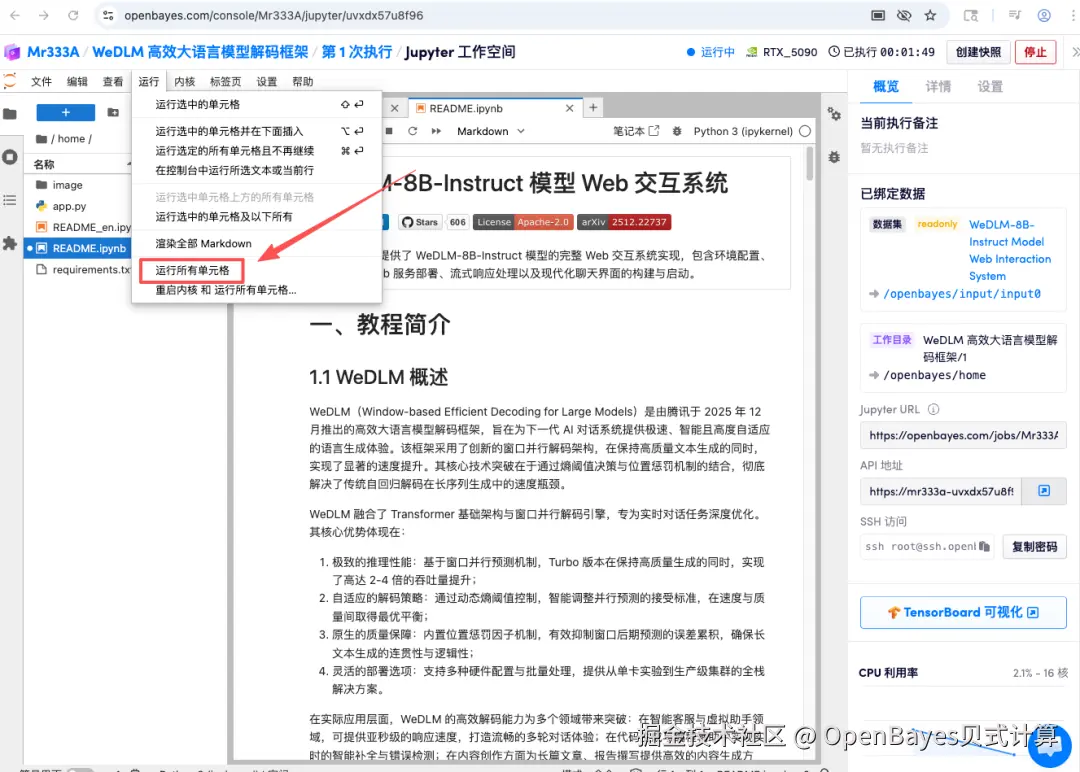
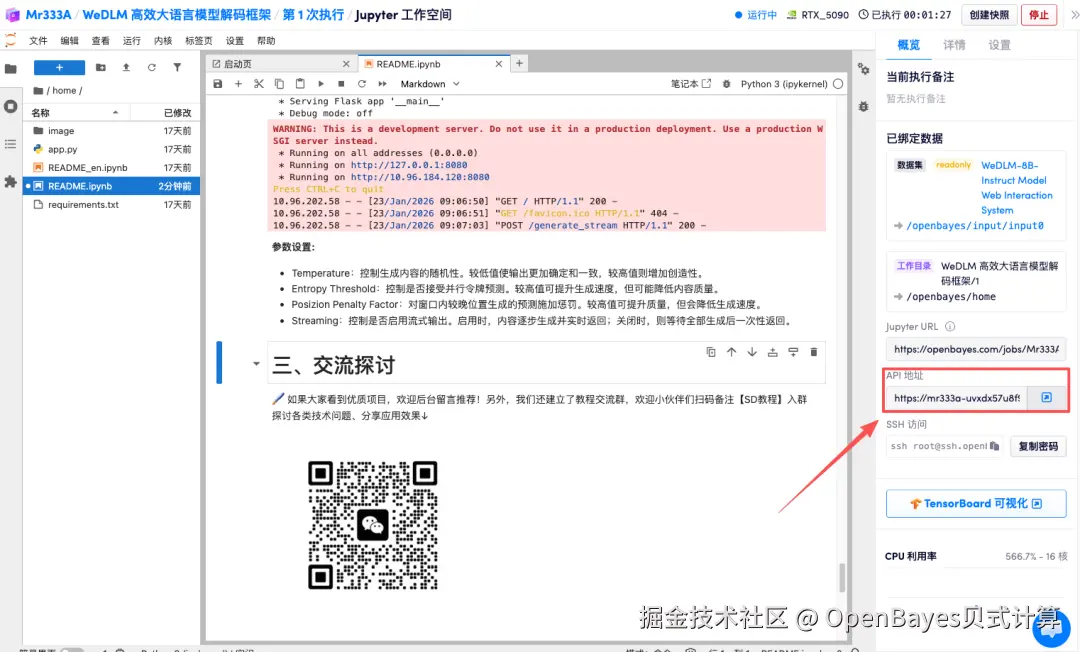
待运行完成,即可点击右侧 API 地址跳转至 demo 页面。
教程链接: