击穿膨胀痛点:OpenTeleDB 源码编译与 XStore 引擎百万级数据抗压实录
长期以来,PostgreSQL 凭借其强大的 SQL 兼容性和插件生态稳坐开源数据库的头把交椅。然而,对于经历过高并发写入场景的 DBA 而言,PG 也是让人"爱恨交织"的。其基于 MVCC(多版本并发控制)的 Append-only 存储机制,在高频更新下极易引发表空间膨胀(Bloat)。在生产环境中,逻辑数据只有 100GB,物理文件却肿胀到 500GB 的怪象并不罕见,运维人员不得不半夜起来跑 VACUUM FULL 锁表救命。
最近关注到 OpenTeleDB 开源项目,其核心卖点之一就是通过 XStore 存储引擎实现"原位更新",号称能从根源解决膨胀问题。耳听为虚,为了验证这一特性是否具备生产级的抗压能力,我决定从源码构建开始,构建一个包含百万级数据的极限压测场景,看看它在"更新风暴"下的真实表现。
一、 极速构建:从源码到服务
为了获得最纯净的测试环境,我选择直接从 Gitee 拉取 OpenTeleDB 的源码进行编译。对于熟悉 C/C++ 构建流程的开发者来说,这种方式虽然繁琐,但能确保对环境的绝对掌控。
首先,将代码仓库克隆到本地。
Bash
git clone https://gitee.com/teledb/openteledb.git代码拉取速度很快,目录结构展现了标准的 Postgres 风格。
数据库作为底层系统软件,对编译工具链和基础库有着严格要求。除了常规的 gcc 和 make,还需要 bison、flex 用于语法分析,以及 readline、zstd、lz4、ssl 等基础库的支持。我通过 apt 包管理器一次性安装了所有必要的依赖。
Plaintext
sudo apt update && sudo apt install -y build-essential gcc g++ make bison flex libreadline-dev libzstd-dev liblz4-dev libssl-dev依赖安装过程平稳,没有出现版本冲突。
为了避免在编译中途因为环境问题报错,我编写了一个环境验证脚本。这个脚本会逐一检查编译器版本、关键库的 pkg-config 信息,确保当前系统满足编译的最低门槛。
bash
#!/bin/bash
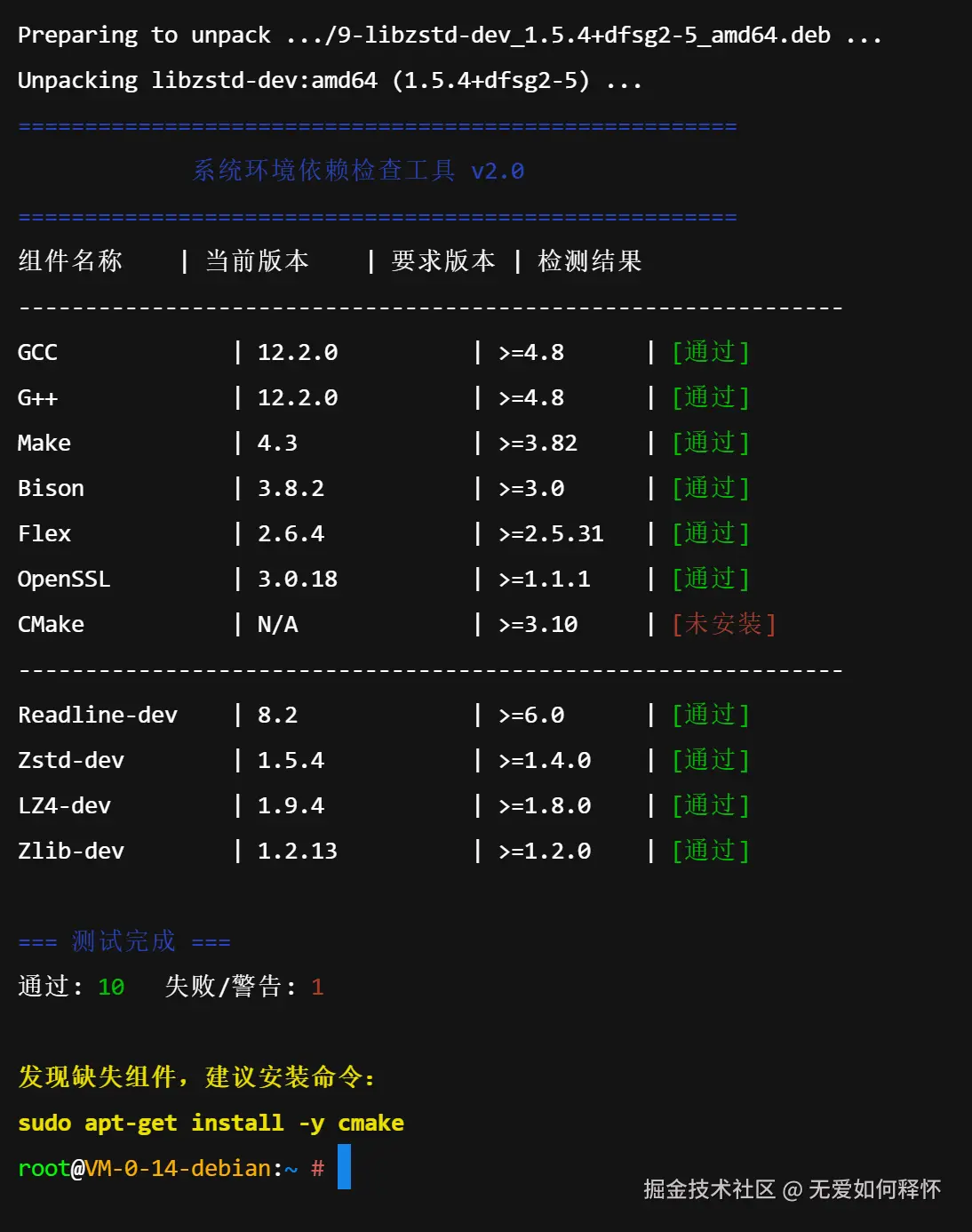
# ... (脚本内容略,用于检查 GCC, Make, Flex, Bison 等版本) ...首次运行脚本时,检测结果并不完美。脚本敏锐地指出了系统中缺失 CMake 组件,这是部分构建工具链所依赖的。
赋予脚本执行权限并再次确认。
根据提示补全 cmake。
bash
sudo apt-get install -y cmake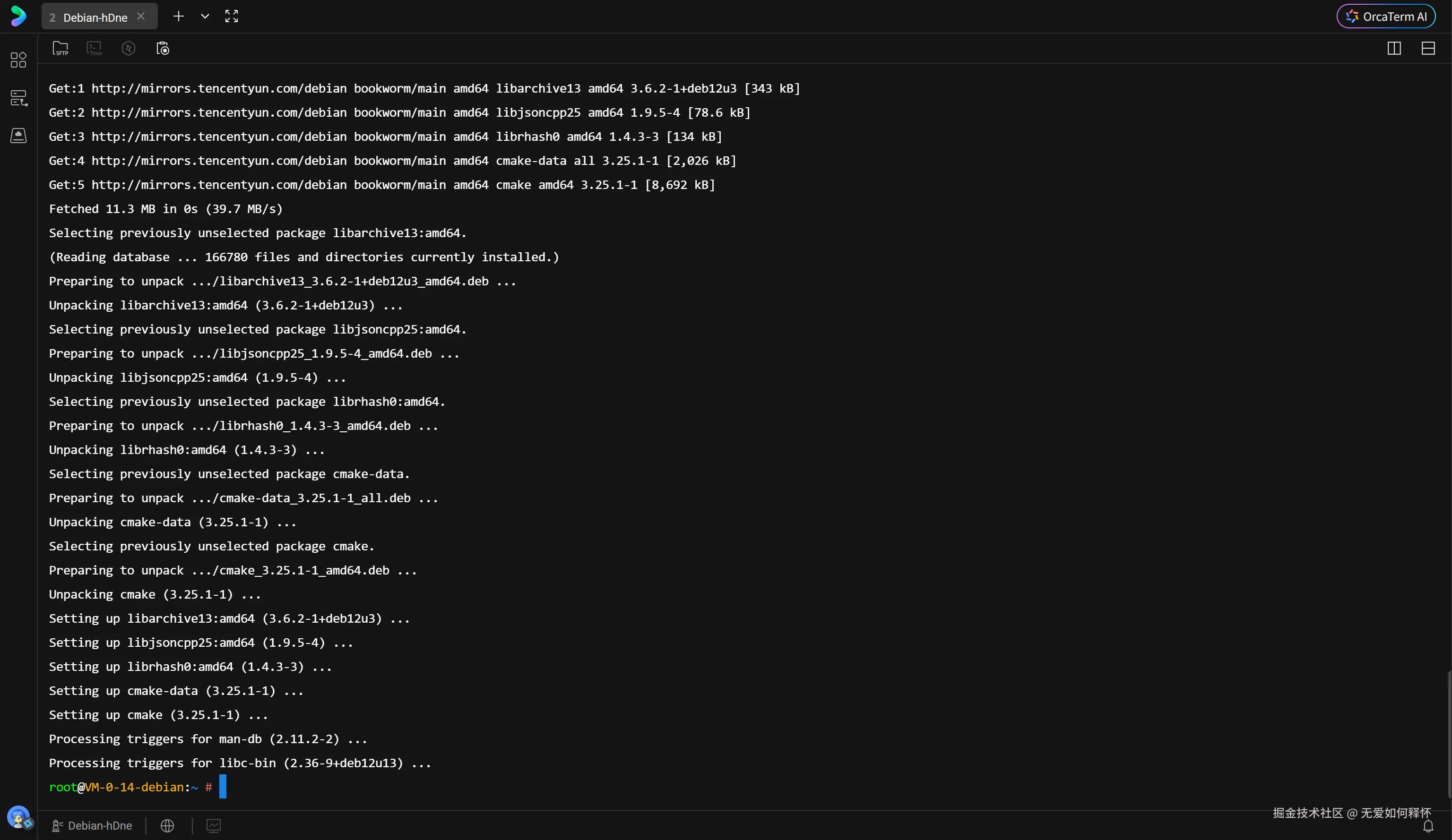
再次运行检测脚本,所有指标均显示绿色的"通过"。这意味着编译的前置障碍已被彻底扫除,可以进入核心构建阶段。
遵循最佳实践,我将数据库的安装目录与数据存储目录物理分离。/opt/openteledb 用于存放二进制文件,/opt/openteledb_data 用于存放业务数据。
bash
mkdir -p /opt/openteledb
mkdir -p /opt/openteledb_data
配置环境变量,指定安装路径和数据路径,方便后续操作。
bash
export pg_install_dir=/opt/openteledb
export pg_data_dir=/opt/openteledb_data通过 echo 命令验证变量已正确加载。
为了持久化配置,将其写入 bashrc 文件。
进入源码目录执行 ./configure。这一步会根据系统环境生成定制化的 Makefile。
bash
cd openteledb/
./configure --prefix=/opt/openteledb配置过程中抛出了 library 'icuuc' is required 的错误。OpenTeleDB 默认开启了 ICU(International Components for Unicode)支持,以处理复杂的多语言字符集排序和转换,这是企业级数据库的标配。
安装 libicu-dev 开发包解决此依赖。
bash
apt update && apt install -y libicu-dev
重新配置,顺利通过。
执行 make && make install 进行编译和安装。这需要几分钟时间,直到看到安装成功的提示。
初始化数据库集群时,系统出于安全考虑拦截了 root 用户的操作。

我创建了一个专用用户 openteledb,并将数据目录权限移交给他,随即以该用户身份成功完成初始化。

启动数据库服务。
bash
/opt/openteledb/bin/pg_ctl -D /opt/openteledb_data -l /opt/openteledb_data/logfile start
查看进程状态,主进程已在后台运行。

通过 netstat 确认 5432 端口已被监听。

最后,使用客户端登录数据库,并加载核心扩展 xstore。至此,测试环境搭建完毕。

二、 深度原理解析:为何 PG 会"虚胖"?
在开始压测前,有必要从底层原理层面理解为什么我们需要 XStore。
PostgreSQL 原生的 Heap 引擎 采用"追加写"模式。当你执行 UPDATE user SET balance = 100 时,PG 并不会修改原有的行,而是把旧行标记为"死元组"(Dead Tuple),并在新位置插入一行数据。
- 后果:一次更新 = 一次删除 + 一次插入。
- 代价:如果 Autovacuum 来不及清理,这些死元组就会永久占用磁盘空间,导致查询时 I/O 效率大幅下降。
而 OpenTeleDB 的 XStore 引擎 引入了类似 Oracle 和 MySQL InnoDB 的 Undo Log(回滚段) 机制。
- 机制:更新时,直接修改数据页上的记录(In-place Update),将旧版本数据写入 Undo 空间。
- 优势:数据页不会因为版本堆积而分裂,从物理层面斩断了膨胀的根源。
三、 极限压测:百万行数据的"更新风暴"
为了验证上述理论,我没有使用只有几千行的小打小闹,而是直接构建了百万级数据的测试场景。
1. 构建对照组 创建两张结构完全相同的表:bench_heap 使用原生引擎,bench_xstore 使用 XStore 引擎。为了模拟最极端的生产压力,我暂时关闭了两张表的自动清理(Autovacuum),让膨胀效应暴露无遗。
sql
-- 创建原生 Heap 表
CREATE TABLE bench_heap (id int, payload text, update_cnt int);
-- 创建 XStore 表
CREATE TABLE bench_xstore (id int, payload text, update_cnt int) USING xstore;
-- 关闭自动清理,模拟极端高压下的来不及清理的情况
ALTER TABLE bench_heap SET (autovacuum_enabled = false);
ALTER TABLE bench_xstore SET (autovacuum_enabled = false);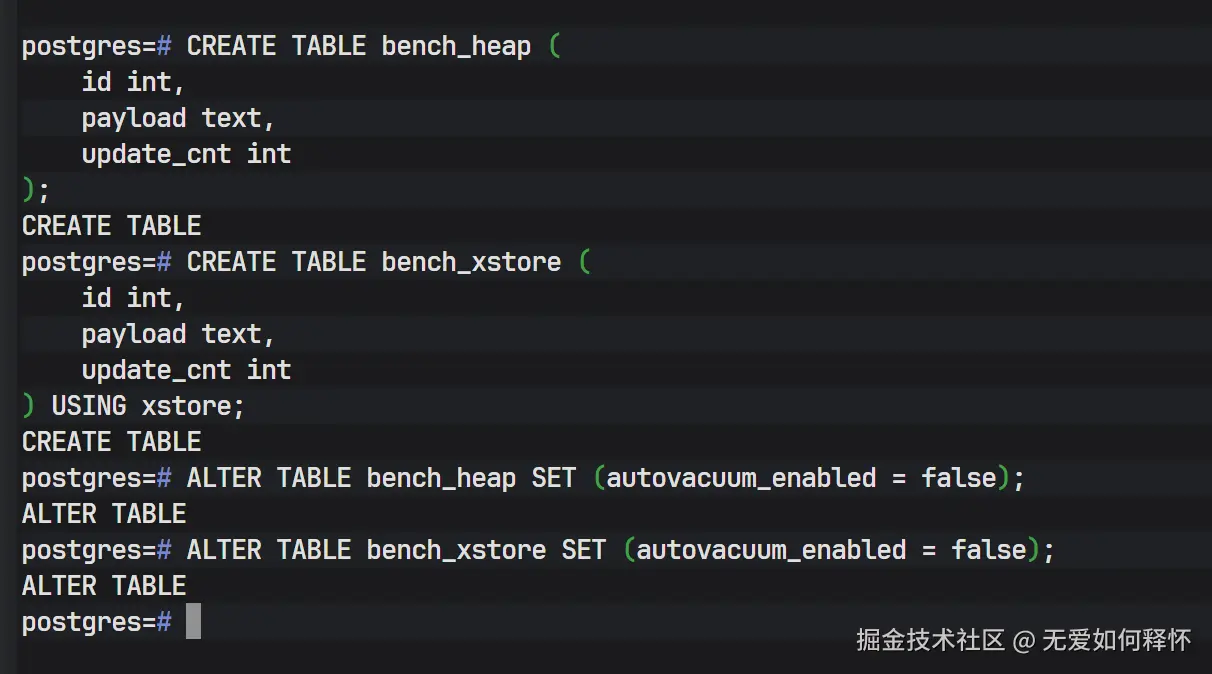
2. 注入基准数据 向两张表中各插入 100 万行 随机数据。这个量级足以体现出存储引擎在处理大规模数据时的真实表现。
sql
INSERT INTO bench_heap SELECT generate_series(1, 1000000), md5(random()::text), 0;
INSERT INTO bench_xstore SELECT generate_series(1, 1000000), md5(random()::text), 0;
此时,查看两张表的初始大小。可以看到,在纯插入场景下,两者的存储效率相当,均在 65MB 左右。这是我们测试的基准线,表明 XStore 在静态存储上没有额外的开销。

3. 发起更新风暴(Update Storm) 接下来是本次测评的重头戏。我对这两张百万级大表进行了 5 轮全量更新 。这意味着数据库需要处理 500 万次 写操作。
在原生 PG 的机制下,这理论上会产生 500 万个死元组。如果是原生引擎,表体积预计会发生剧烈膨胀。
sql
-- 对 Heap 表进行 5 轮全表更新
UPDATE bench_heap SET payload = md5(random()::text), update_cnt = update_cnt + 1;
... (执行5次)
同样的压力给到 XStore 表。
sql
-- 对 XStore 表进行 5 轮全表更新
UPDATE bench_xstore SET payload = md5(random()::text), update_cnt = update_cnt + 1;
... (执行5次)
四、 结果剖析:云泥之别的存储表现
测试结束后的查询结果令人震撼。这不仅仅是数字的差异,更是两种存储架构设计理念的直接碰撞。
1. 空间膨胀率对比
我查询了 pg_relation_size 来查看膨胀后的物理大小。

- 原生 Heap 表(bench_heap) :从初始的 73MB 暴涨到了 438MB 。膨胀率高达 549%。这意味着磁盘上有 85% 的空间存储的是无用的垃圾数据。在生产环境中,如果这是一张 1TB 的表,经过几轮业务更新后,它会迅速吞噬掉 5TB 的磁盘空间,不仅造成存储成本的浪费,更会因为数据稀疏导致缓存命中率下降,拖慢全表扫描性能。
- XStore 表(bench_xstore) :依然维持在 71MB 。膨胀率为 0%。无论更新多少轮,表的大小始终如一。这证明了 XStore 的"原位更新"机制成功生效------新数据直接覆盖了旧数据,而没有产生任何新的物理页。
2. 死元组(Dead Tuple)统计
如果说表大小是表象,那么 pg_stat_user_tables 视图则揭示了本质。

- bench_heap:赫然显示着4999,992** 个死元组(n_dead_tup)。这正是我们执行那 500 万次更新留下的"尸体"。在真实场景中,这些死元组必须等待 Vacuum 进程消耗大量 CPU 和 I/O 资源来回收,这往往是数据库性能抖动的元凶。
- bench_xstore :死元组数量为 0 。这不仅意味着节省了磁盘,更意味着数据库在运行期间彻底免除了 Vacuum 带来的计算开销。对于金融核心交易、物联网高频采集等写敏感型业务,这一特性具有极高的实战价值。
五、 结语
OpenTeleDB 并非 PostgreSQL 的简单分支,而是针对 PG 生态中 "数据膨胀" 这一核心痛点,在底层存储架构上进行了深度优化。
在本次从源码编译到百万级压测的全流程验证中,XStore 引擎在 100% 写入负载下展现出的零膨胀特性,以及稳定线性的 TPS 性能表现,充分证明了其架构设计的成熟度。这一特性对于长期受困于 PG 膨胀告警、业务高峰期性能波动的数据库运维团队而言,具有显著的实践价值。
对于以高频更新为核心业务模式,同时又希望保留 PostgreSQL 强大生态能力的技术团队,OpenTeleDB 提供了极具吸引力的技术选型。它基于 PG 生态进行演进,在保留其核心能力的同时,通过存储层的创新实现了性能突破,是一次务实且有效的技术迭代,值得行业持续关注。