
一、langchain.messages 模块
在 LangChain 中,消息相关的模块主要用于与聊天模型(Chat Models)进行交互。随着 LangChain 的版本迭代,这些核心类目前主要存放在 langchain_core.messages 模块下。
但如果你已经安装了 langchain 的话,langchain.messages 里也可以直接取到这些类。
1.1. 核心消息类 (Core Message Types)
所有的消息类都继承自基础类 BaseMessage。它们分别对应了聊天对话中的不同角色:
-
SystemMessage (系统消息):用于设定 AI 的行为、背景、规则或人物设定。通常作为对话的第一条消息传入。
-
HumanMessage (人类消息):代表来自用户(人类)的输入或提问。
-
AIMessage (AI 消息):代表来自大语言模型(AI 助手)的回复。
-
ChatMessage (自定义角色消息):当标准角色(System, Human, AI)不够用时,可以使用这个类,并手动指定 role 参数(例如角色设定为 "moderator" 或 "user_2")。
-
ToolMessage (工具消息):代表工具(Tool)执行完毕后返回的结果。在现代的 Agent 和工具调用(Tool Calling)流程中非常常用,通常包含 tool_call_id。
使用这些类,不仅可以避免像在之前直接 OpenAI的 API 时那些写 { "role": "system" },更重要的是语义化上的方便与类型判断。
例如:
python
if isinstance(last_message, AIMessage)可以用来判断 last_message 是否是 AI 回复的消息。
同时,当我们构建人类输入时,我们拿到用户的输入字符串后,可以这样构建输入消息的结构:
python
input_message = {"messages": [HumanMessage(content=user_input)]}对比直接写JSON,语义上的进步是比较大的。
1.2. 流式传输消息类 (Streaming Message Chunks)
当使用流式输出(Streaming)时,模型会逐块(chunk)返回数据。这些类专门用于处理流式响应,它们都继承自 BaseMessageChunk:
-
AIMessageChunk:AI 回复的流式片段。
-
HumanMessageChunk:人类消息的流式片段。
-
SystemMessageChunk:系统消息的流式片段。
-
ChatMessageChunk:自定义角色消息的流式片段。
-
ToolMessageChunk:工具消息的片段。
注:这些 Chunk 类支持使用 + 运算符进行拼接(例如两个 AIMessageChunk 相加会合并成一个完整的 Chunk)。
如果用不上流式传输,可以暂时忽视这部分。
二、 检查点/持久化
如果没有 Checkpointer(检查点/持久化),你的 Agent 就会变得和你们公司的领导一样,转头就会忘记刚画好的饼子。
每次程序运行结束或者一旦程序崩溃,状态(State)就被彻底擦除。下一次用户再说话时,它又得从零开始。
2.1 核心概念:快照
上一节讲到,新版本的LangChain的一个核心概念就是状态机思维,各个节点可以通过共同读写同一组状态,从而进行节点的流转。
那么 Checkpointer 的作用,其实就是选在关键的节点给状态来一张快照,把状态当前的状态存入内存或者进行持久化(存入数据库)。
- 快照触发时机:只要图里的一条 Edge 流转结束,或者一个 Node 刚刚更新完全局状态,就会触发快照。
- Thread ID:直接理解为区分会话的唯一标识即可,不同 Thread ID 的状态持久化完全隔离。
2.2 Checkponter 解决了什么问题?
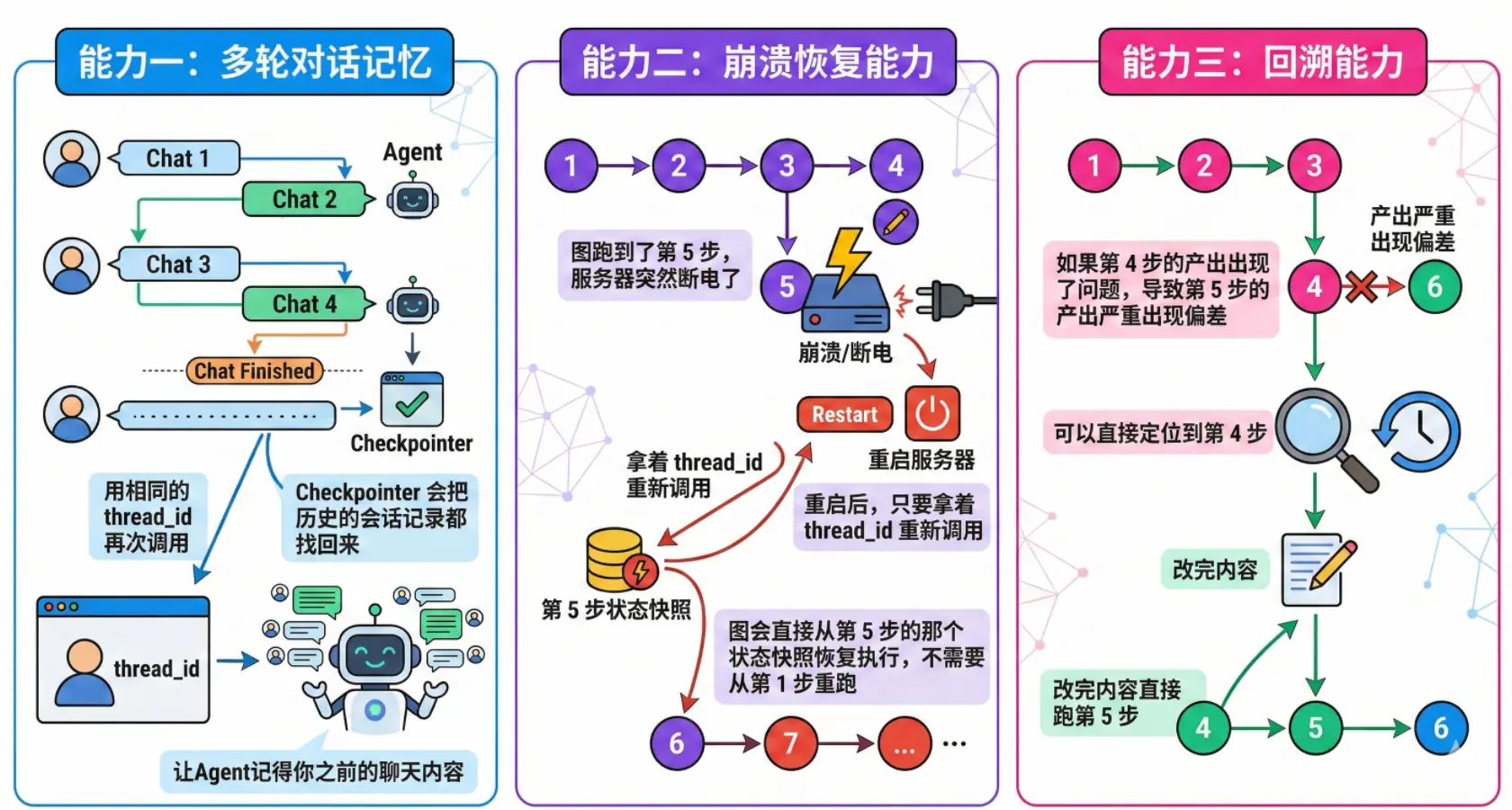
引入 Checkpointer 后,你的 Agent 能得到三种主要的能力:
-
能力一:多轮对话记忆。哪怕图跑完了,只需要
thread_id一致,Checkpointer 也会把历史的会话记录都找回来,让Agent记得你之前的聊天内容。 -
能力二:崩溃恢复能力。图跑到了第 5 步,服务器突然断电了。没关系!重启后,只要拿着 thread_id 重新调用,图会直接从第 5 步的那个状态快照恢复执行,不需要从第 1 步重跑。
-
能力三:回溯能力。如果第4步的产出出现了问题,导致第5步的产出严重出现偏差。没关系,可以直接定位到第4步,改完内容直接跑第5步。
2.3 如何使用内存存储
内存存储的用法最为简单,甚至不需要引入任何第三方插件,langchain官方直接内置了。
python
# 1. 引入 MemorySaver
from langgraph.checkpoint.memory import MemorySaver
# 2. 实例化这个存储器
checkpointer = MemorySaver()
# 3. 重点在这里!编译图的时候,把存储器指派给图
graph = graph_builder.compile(checkpointer=checkpointer)这样,只要程序稳定运行,内存里就可以记住你刚才说的内容。
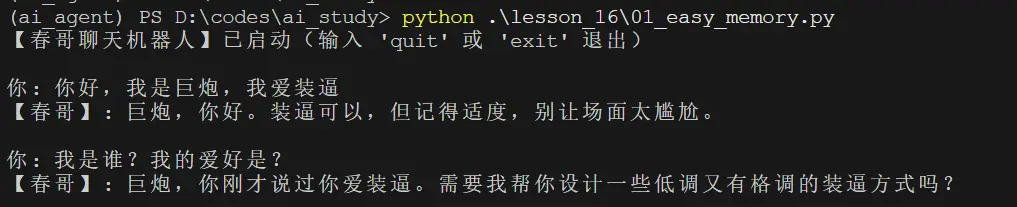
但生产一般不用这个方案,这个只适合demo和本地调试。
因为一旦崩溃,或者服务重启,内存清空,Agent就会失忆。
2.4 轻量级的Sqlite存储
众所周知,sqlite是客户端的数据库宠儿,随时随地,创建一个 xxx.db 文件,就能进行数据存储。
不需要起端口,不用部署,贼方便。
不过 langchain 的官方并没有内置,而是需要安装插件:
bash
pip install langgraph-checkpoint-sqlite使用起来的写法要比 MemorySaver 稍微麻烦一点点,需要用到 with 关键词。
python
from langgraph.checkpoint.sqlite import SqliteSaver
with SqliteSaver.from_conn_string("checkpoints.db") as checkpointer:
graph = graph_builder.compile(checkpointer=checkpointer)在这个语法的加持下,python程序能更安全地建立和本地文件的数据流开关,除此之外没啥差异。
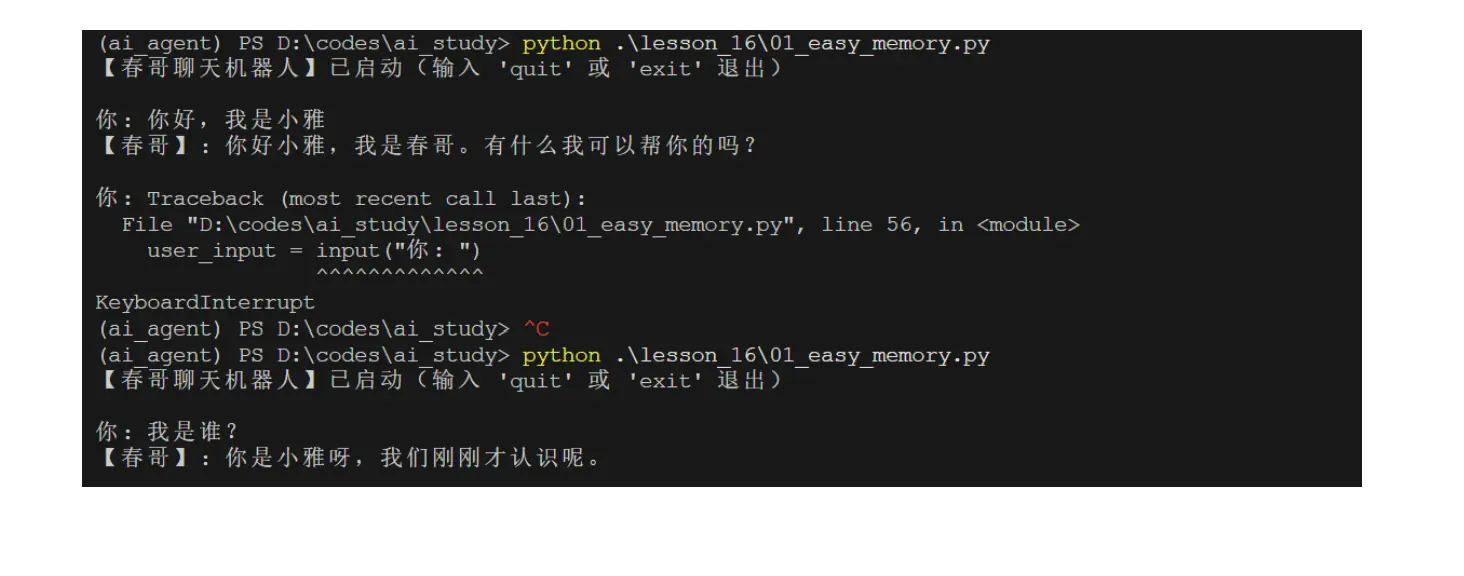
在 sqlite 的本地化存储的加持下,哪怕我用ctrl + C终止了进程,再次执行时,历史记录依然能被保留。
AI拥有了跨会话的记忆!
当然,在生产使用时,还会有mysql的插件,postgresSql的插件,这就根据需要选择了。
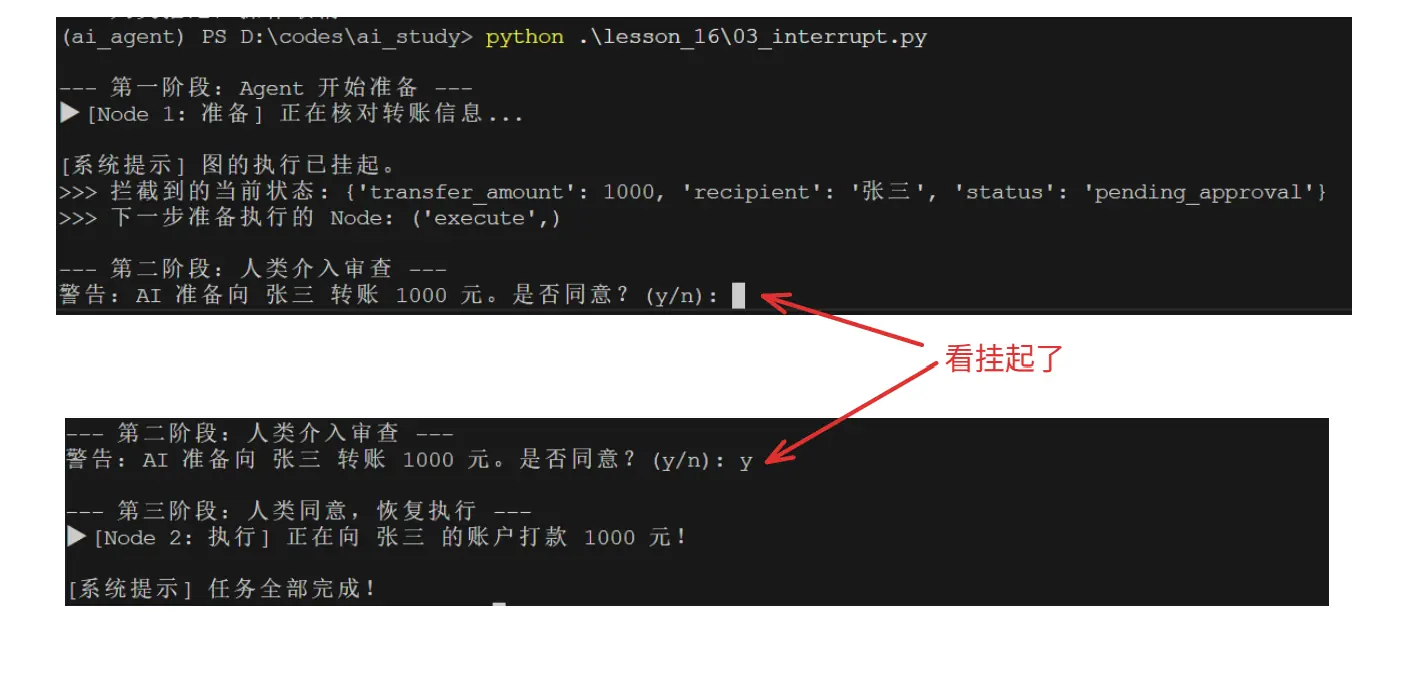
三、Human In Loop: 人类干预
在没有 Human-in-the-loop(HITL,循环内人类干预)之前,AI Agent 就像一辆没有刹车的自动驾驶汽车。
如果它只是用来总结文章,那还没关系;但如果它的最后一步是"发送一封群发邮件"、"删除数据库表"或"调用 API 扣款",你绝对会惊出冷汗。
哈哈,有没有想到前几天的新闻:Meta的安全专家被openClaw狂删邮件那事儿?要不然claw的安全口碑是个大问题呢。
有了 Checkpointer的加持,我们就可以给Agent装上 "中断器(Interrupt)" 了。
3.1 核心思想:在关键节点前"挂起"
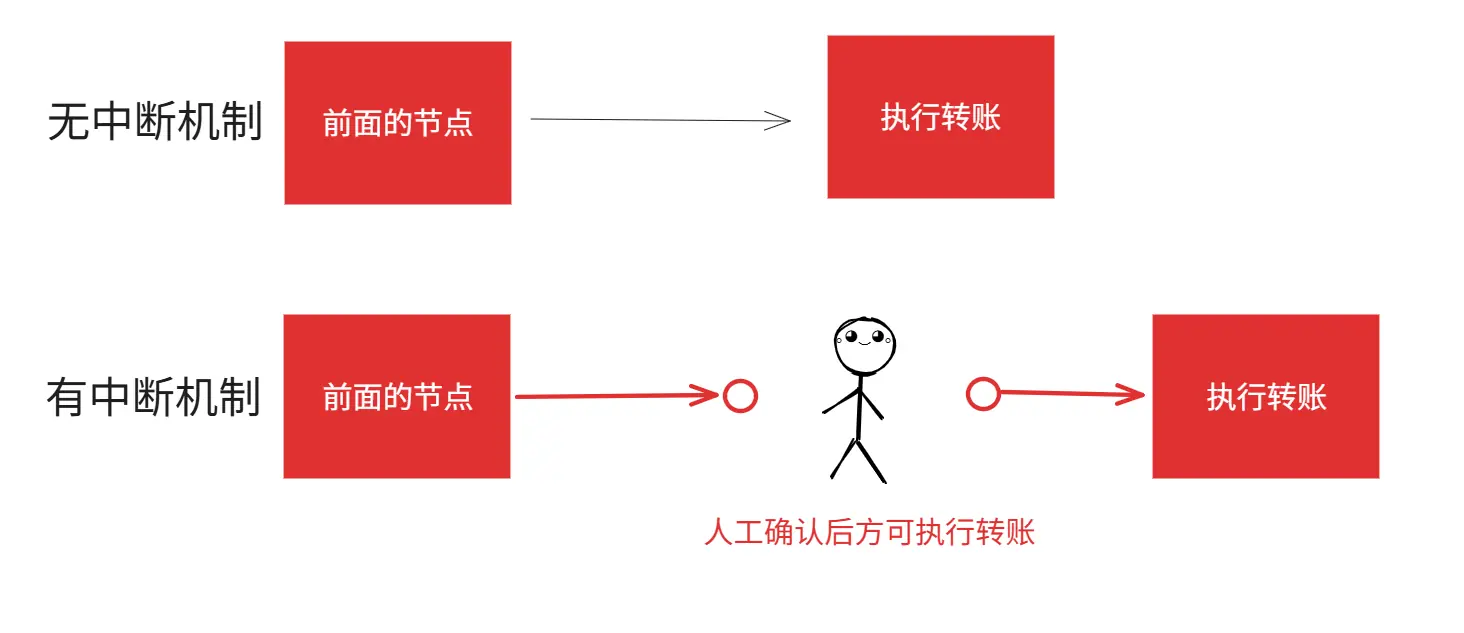
中断器的核心机制如下:
- 它会利用Checkpointer的机制,在关键节点前主动结束任务,完成持久化,并且留下一个标记。
- 只有当用户再次启动,利用Checkpointer恢复状态,并且主动确认之前留下的标记后,才能进入关键节点。
3.2 代码实现
其核心执行代码分两个部分。
核心1:定义阻断点
python
app = workflow.compile(
checkpointer=memory,
interrupt_before=["execute"] # 遇到 execute 节点,立刻阻断
)核心2:恢复图
python
if human_input.lower() == 'y':
app.invoke(None, config=config)这里在 app.invoke(None,) 时传入的None代表确认了之前的阻断,允许接着往下执行。
四、小结
至此,LangChain较为核心的概念我们就都接触了一遍了,后续就需要上实战就行验证了。
敬请期待!
