文章目录
- [WHERE 条件优化](#WHERE 条件优化)
- 外连接优化
- [ORDER BY 优化](#ORDER BY 优化)
-
- [使用索引进行 order by](#使用索引进行 order by)
- [GROUP BY 优化](#GROUP BY 优化)
- 函数调用优化
- 总结
WHERE 条件优化
- 删除不必要的括号
- 常量合并
- 去除常量条件
- 删除超出范围的值
优先常量比较过滤一个小范围(调整 and 顺序)
范围优化
单部索引范围访问
其实就是使用一个表的一个索引列范围查找
- 判断恒为真或者恒为假的条件,去除不必要的范围条件
多部索引范围访问
使用复合索引完成范围查找
比如:
- **前导索引列:**使用第一个索引筛选
- **HASH 索引:**就是复合索引的每一列使用= is NULL is not NULL 完成比较
- **BTREE 索引:**使用所有判断相关的运算符来确定范围,这要注意的是 等值一路通,范围断所有,使用范围查找后, and 后面的条件都只能作为过滤,不能使用索引了
等值一路通,范围断所有:多部索引范围访问的第一个=后,后面第一个!= < > 仍然可以使用索引,但是第二个!= < >就不能使用索引查找了。
等值一路通,范围断所有(断后续,不断自身) :
- 复合索引的有序性是层级的:只有前一列是 "等值匹配" 时,后一列才保持有序,范围条件才能利用索引;
- 范围条件是索引中断点:第一个范围条件(!=/</> 等)会打破后续列的有序性,导致后续列无法通过索引查找,只能过滤;
- 最左匹配的核心:索引能用到的列,截止到 "第一个范围条件" 为止,后续列仅能作为过滤条件,而非索引查找条件。
在第一列 = 确定之后,索引只对紧邻的第二列保持"有序"。一旦对第二列使用了范围查询(!=, >, <),索引的连续性就会被打破,后续的列就失去了"有序"的基础,无法再进行高效的索引查找。
想象一个复合索引 (col1, col2, col3),假设有以下数据按索引排序:
| 行号 | col1 | col2 | col3 |
|---|---|---|---|
| 1 | A | 1 | 10 |
| 2 | A | 2 | 20 |
| 3 | A | 5 | 5 |
| 4 | A | 8 | 30 |
| 5 | B | 1 | 15 |
| 6 | B | 3 | 25 |
| 7 | C | 2 | 12 |
索引合并优化
允许优化器在处理单个表的查询时同时利用多个索引,并将多个索引的扫描结果合并为一个最终结果集。
在传统的查询优化中,数据库优化器通常为单个表的查询只选择一个最优索引,剩下的条件只能对结果筛选。而索引合并优化打破了这一限制,允许:
- 多次索引扫描:对同一表的不同列分别使用不同的索引
- 结果集合并:将多个索引的检索结果进行合并(交集/并集操作)
什么时候走合并优化,什么时候走BTREE索引。可以各走一半么?
优先使用BTREE索引:
- 当查询条件中的列有高选择性(即过滤后数据量小)。
- 当需要范围查询或排序时。
- BTree索引的场景,适合单个索引上用= . >, < 这些条件查询
优先使用合并优化:
- 查询条件包含多个不同索引的列,而且用or,and链接的时候
在实际的查询优化中,优化器会自动评估代价,并选择最优的执行计划。也就是说,优化器会根据统计信息(如表大小、索引选择性、数据分布等)来决定是使用单个BTREE索引、Index Merge还是Merge Join。
- BTREE索引是基础,大多数查询都会首先考虑使用BTREE索引。
- 合并优化是补充,当单个索引无法满足需求时,优化器会考虑使用合并优化。
优化器在选择执行计划时,会综合考虑以下因素:
- I/O代价:读取数据页的次数。
- CPU代价:计算和比较的开销。
- 内存使用:排序和合并所需的内存。
能不能各走一半,是有优化器进行预估以后决定的
BTREE索引是基础,合并优化是补充,为什么这么说?
io cpu 内存来考量,如下
sql
┌─────────────────────────────────────────────────────────────┐
│ 磁盘IO效率对比 │
├─────────────────────────────────────────────────────────────┤
│ │
│ 顺序IO(BTREE索引扫描): │
│ ┌───┬───┬───┬───┬───┬───┬───┬───┬───┬───┐ │
│ │ 1 │ 2 │ 3 │ 4 │ 5 │ 6 │ 7 │ 8 │ 9 │ 10│ ... → 连续读取 │
│ └───┴───┴───┴───┴───┴───┴───┴───┴───┴───┘ │
│ 磁盘转动一次,读取多个连续扇区 │
│ 耗时:1ms(读取10页) │
│ │
├─────────────────────────────────────────────────────────────┤
│ │
│ 随机IO(合并优化/多索引扫描): │
│ ┌───┬───┬───┬───┬───┬───┬───┬───┬───┬───┐ │
│ │ 1 │ │ │ 2 │ │ │ 3 │ │ │ 4 │ ... → 跳跃读取 │
│ └───┴───┴───┴───┴───┴───┴───┴───┴───┴───┘ │
│ 磁盘臂需要来回移动 │
│ 耗时:100ms(读取4页) │
│ │
└─────────────────────────────────────────────────────────────┘cpu:BTREE查找:O(log n) 合并排序:O(n log n)
内存:
- BTREE索引:索引缓存+查询缓冲区共 101MB
- 合并优化:归并缓存、临时结果集、排序缓冲区(排序后的数据才能进行归并) 共 296MB
索引合并优化会比优化前提升filtered么?
会的,这个filtered的分母是扫描的行数,这个索引合并优化就让回表查询扫描的行数少了
三个概念
**交叉访问算法:**用 and 连接,const 筛选。是索引合并优化的一种情况
**联合访问算法:**用 or 连接,const 筛选。是索引合并优化的一种情况
**排序联合算法:**支持索引的范围查找。是索引合并优化的一种情况
索引下推 (ICP) 优化
使用范围查找(%开始的模糊查询除外),如果没有索引下推需要根据主键回表后判断其他 where 条件,使用复合索引且其他条件可以用复合索引中的列判断时,在存储引擎层就进行过滤,不用回表查询后过滤,最终会减少回表的次数,提升效率。
ps:mysql 四层架构由上到底层:连接层(连接、权限、连接池)、服务层(处理 sql、优化和解析)、存储引擎层、文件系统层
辨析 IPC 和索引合并和 BTREE 索引
| 优化方法 | 场景 | 效果 |
|---|---|---|
| IPC | 复合索引+范围查找 | 在存储引擎层直接优化 |
| BTREE 索引 | 复合索引 | 索引完,交给 IPC 完成接下来操作,然后操作文件 |
| 索引合并 | 筛选的列都是索引,彼此间没有关系。条件是 and 也可以是 or。可以是范围查找也可以是常数查找 | 先查索引,然后结果进行归并排序,计算并集或者交集,然后回表 |
外连接优化
先读取依赖的表再读取当前表
外连接条件用于决定如何从当前表检索数据行
右连接分发到存储引擎执行时也是以左连接方式执行的,调换顺序
ORDER BY 优化
使用索引进行 order by
索引是有序的,使用索引可以避免额外的排序。
比如:在表建立复合索引(key1, key2,key3)
使用 sql: select * from t1 where key1 = 1 order by key2
但是,如果直接select * from t1 order by key2是不行的,因为你没有戳二级索引整体排序,同理,对 key1 进行范围筛选也是不行的,使用 key1 筛选,key3 排序也是不行的。这一系列不行可以归结一个原因:不满足最左原则.
使对索引列进行函数 / 运算 也不行
GROUP BY 优化
使用 GROUP BY 分组查询时:
- 把复合 WHERE 结果的数据放入临时表
- 临时表每行都连续
- 分离每个组,如果有聚合函数就使用
因为索引本身就是连续的,所以可以使用索引来避免建立临时表。
可以这么理解:创建临时表的目的有两个,全表扫描读取所需数据,排序分组保证筛选出的数据连续方便分组。这个排序是主要原因。
使用索引就可以直接解决排序问题,而且用索引还可以快速筛选需要的数据。以此避免建立临时表和排序和降低回表的性能损耗
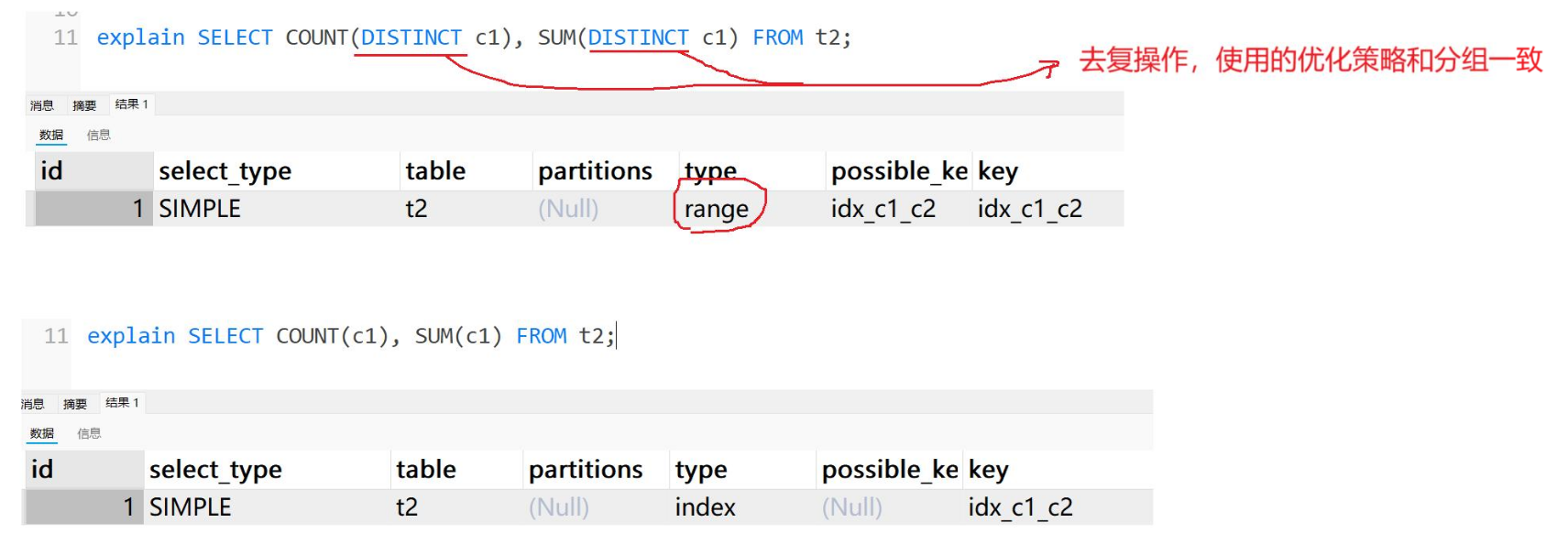
为什么聚合函数中使用索引列更高效
max(class_id) class_id是索引列,比max(age)快的原因。如果class_id作为复合索引的非第一位,可以更快么还
叶子节点(Leaf Node)都存储了完整的键值,并且是 按键值从小到大排序链接 的。如果非第一位就不行了,原因是第二位索引是根据第一位的排列结果前提下排序的。
函数调用优化
函数 RAND UUID 是非确定函数,使用非确定函数无法使用索引,但如果把非确定函数放入变量在使用索引就行了。
总结
避免索引使用不当
- 复合索引满足最左原则
- WHERE 条件有 OR,且有条件列没有索引,导致需要全表扫描
- 使用以%开始的模糊查询
- 对于模糊查询,可能会让 mysql 判断不出来是否使用索引,可以再 from table1 后使用 use index(idx_name)建议使用,或 force index(idx_name)。
- 索引使用类型转换导致 mysql 识别不出来
- 索引列进行表达式运算
- 索引列进行函数运算
- 查询范围太大,mysql 决定全表,因为全表比走索引还快
加索引
- 起码的主键
- distinct order by group by join where 条件都加索引
- 频繁操作的 table 不要加索引,维护要成本!
- 索引覆盖
- 避免在重复值过多的列上建立索引
- 多表 json 有确定条件时,比如 where class_id = 1,可以分成多个单表查询然后合并
- use force 强制或建议索引
- 创建索引可以指定索引排序方式
- 创建索引前确保当前数据库实例没有创建大事务,防止卡死
- 不常用索引清理