一、前言
在数字化渗透各行各业的今天,时序数据早已成为企业运营、设备管理、市场决策的核心依据,每日波动的电商销量、实时变化的平台流量、持续监测的设备指标、规律起伏的气温与股价,这些按时间串联的数据,藏着预判未来的关键密码。但长期以来,数据分析始终面临一道难以跨越的鸿沟:传统时序预测算法能精准算出未来数值,却只能输出冰冷的曲线和数字,无法解释数据背后的逻辑,更不能给出可落地的行动建议;而业务人员看得懂需求,却读不懂复杂的模型结果,导致精准预测沦为纸面数据,难以转化为实际价值。
如何让时序数据不再只会算、不会说?答案藏在时序预测算法与大模型的融合之中。我们提出全新思路:让专业时序算法负责精准计算,把趋势、周期、异常交给 ARIMA、Prophet、LSTM 等模型;让大模型负责理解数据、解读结果、输出洞察,实现从"数值预测"到"自然语言分析"的升级,让数据分析拥有思考力和表达力,变成会说话、能参谋、可落地的智能助手。今天我们搭建一套完整的"会说话的时序分析系统",让精准预测真正转化为决策优势,让数据不再沉默,而是主动成为决策指引。

二、核心基础
1. 核心概念
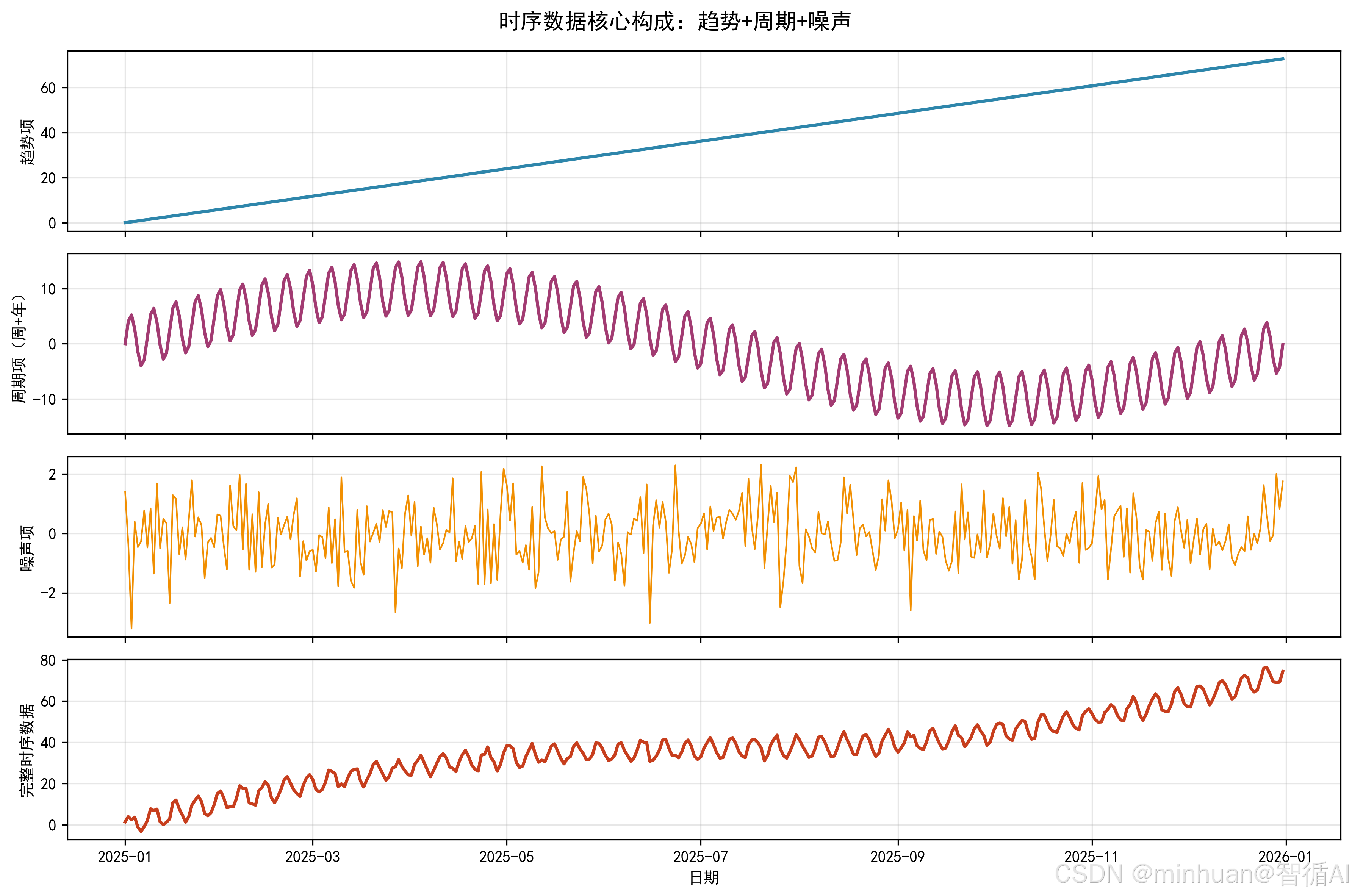
- **时序数据:**按时间顺序排列的数据,比如每日销量、每小时温度、每分钟股价,核心特点是数据和时间强关联,今天的销量大概率和昨天的销量有关。
- **时序预测算法:**专门算准未来的工具,如ARIMA、Prophet、LSTM 等,核心作用是基于历史数据,算出明天或下周的销量、温度或股价。
- **会说话的数据分析:**时序算法负责输出冰冷的数字,比如预测下月销量1000件,大模型负责把数字翻译成人话,比如"销量环比增长 10%,建议提前备货",两者结合让数据分析从看数字升级为 懂意义、能决策。
2. 基础知识
2.1 时序数据的核心特点
- **时间依赖性:**后一个时间点的数据依赖前一个或前几个时间点,比如周一店铺流量和周日相关;
- **周期性:**数据按固定周期波动,比如销量周末更高、温度夏季更高;
- **趋势性:**数据整体有上升或下降趋势,比如店铺流量随运营慢慢增长;
- **异常值:**偶尔偏离正常范围的数据,比如设备指标突然飙升,可能是故障前兆。
2.2 常见时序预测算法
2.2.1 ARIMA(自回归积分滑动平均模型)
ARIMA 的核心思想是:从历史数据中挖掘出稳定的"节奏"或"规律",然后用这个节奏去推测未来,比如某商品每天的销量看起来杂乱无章,但仔细观察会发现,每周一销量低、周五高,或者每月初有促销带动增长。
- ARIMA 就是通过数学方式自动识别这种"自相关性",即过去的数据如何影响现在,并建立一个统计模型来预测接下来的趋势。
- 它最适合用于短期、平稳、没有剧烈突变的时间序列,比如日常销售额、气温变化等。
- 不过使用前通常需要对数据做平稳化处理,比如差分,对使用者有一定统计基础要求,上手难度属于中等。
2.2.2 Prophet
Prophet 是专为业务场景设计的时序预测工具。它假设现实中的数据往往包含三种成分:趋势(长期上升或下降)、周期(周/月/年规律)、节假日效应(如春节、双11)。
- Prophet 能自动拟合这些成分,即使数据中有缺失值或异常点,比如某天系统故障导致流量归零,也不会轻易"跑偏"。
- 正因为如此,它特别适合电商、互联网运营、零售等有明显季节性和节假日效应的领域。
- 而且 Prophet 提供了简洁的 Python 和 R 接口,几乎不需要做复杂的数据预处理,上手非常简单,即使是非算法背景的产品或运营人员也能快速使用。
2.2.3 LSTM(长短期记忆网络)
LSTM 是一种深度学习模型,擅长捕捉长时间跨度下的复杂依赖关系。比如预测股票价格时,今天的走势可能不仅受昨天影响,还和两周前的政策公告、一个月前的市场情绪有关。
- 传统模型很难记住这么远的信息,但 LSTM 通过特殊的"门控机制",可以选择性地记住或遗忘历史信息,从而建模更复杂的动态模式。
- 因此,LSTM 更适合长期、高维、非线性且噪声较多的时序任务,如金融价格预测、工业设备传感器监控、能源负荷预测等。
- 但它的代价是:需要大量数据、训练耗时、调参复杂,且结果不易解释,上手门槛较高,通常需要一定的深度学习基础。
2.2.4 时序异常检测
这类方法的目标不是预测未来,而是判断当前或过去的数据是否不正常。其基本逻辑是:先学习"正常数据"的行为模式,比如服务器CPU使用率通常在 20%~60% 之间波动,一旦出现显著偏离,如突然飙到95%持续10分钟,就标记为异常。
- 常见的技术包括基于统计的方法(如 3σ 原则)、滑动窗口对比、或使用 AutoEncoder、Isolation Forest 等机器学习模型。
- 它广泛应用于设备故障预警、网络安全监控、业务指标突变告警等场景。虽然原理不难理解,但要调好阈值、减少误报,仍需结合业务经验,整体上手难度中等。
2.2.5 算法应用建议
- 如果我们刚接触时序分析,先试试 Prophet,简单又实用;
- 如果数据平稳、周期明确,ARIMA 是经典可靠的选择;
- 如果追求更高精度且有足够数据和算力,可尝试 LSTM 或其他深度学习模型;
- 如果目标是"发现问题"而非"预测未来",那就直接上时序异常检测。
三、执行流程

流程说明:
-
- 数据准备:收集时序数据,比如近 1 年日销量,格式:日期 + 销量;
-
- 数据预处理:清洗空值、错误值,Prophet 要求列名固定为ds(日期)和y(数值);
-
- 模型训练:用 Prophet 拟合数据,训练预测模型;
-
- 预测输出:预测未来 30 天销量,生成趋势图;
-
- 结果整理:计算核心指标,比如环比增长率;
-
- 提示词工程:把结果+业务场景传给大模型,引导生成有价值的解读;
-
- 生成报告:大模型输出自然语言分析报告;
-
- 输出结果:整合预测图和文字报告,形成最终分析结果。
四、完整示例
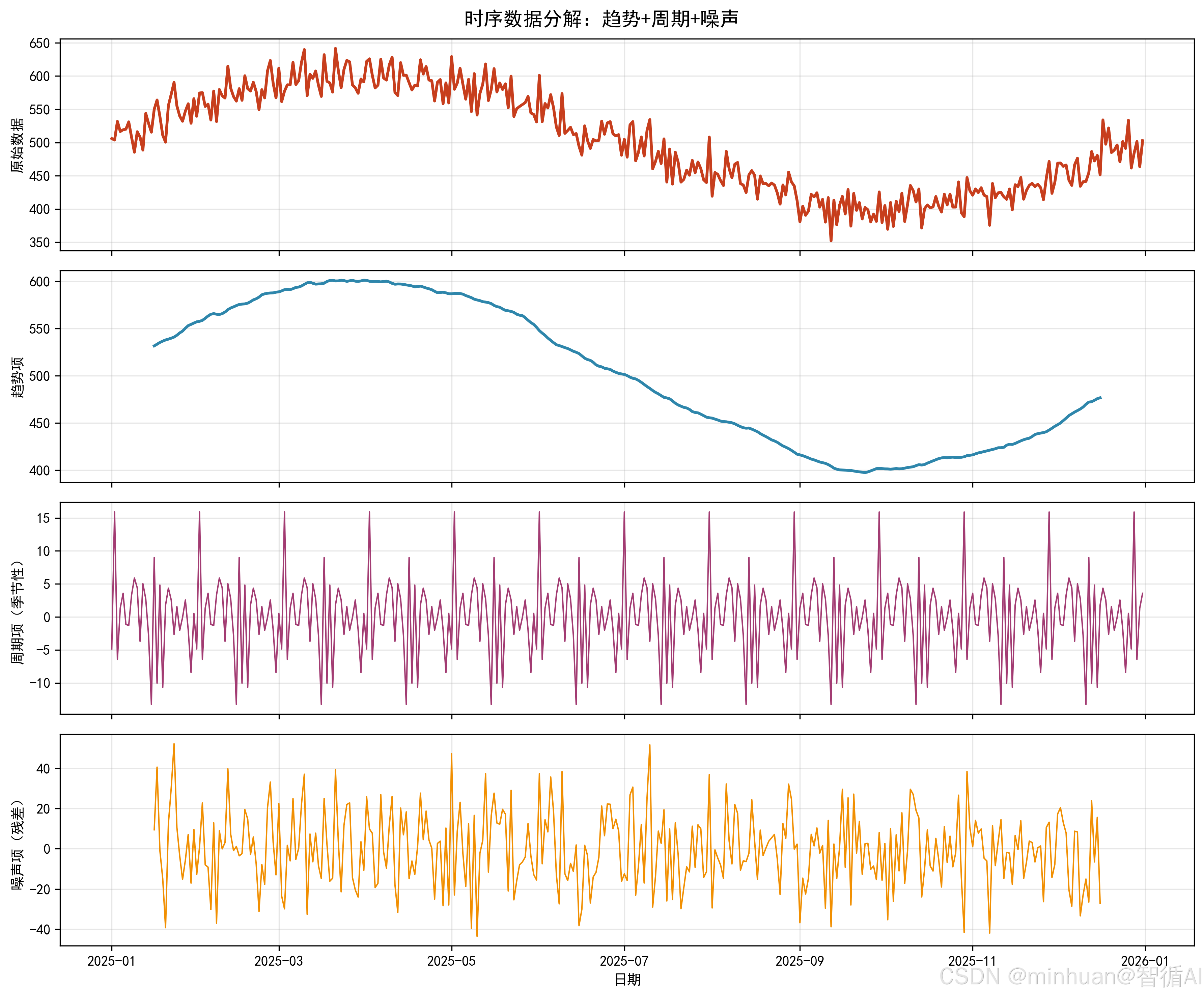
以下是电商销量时序预测与智能分析示例,融合了数据生成 → 模型训练 → 可视化 → 结果结构化 → 大模型解读五个关键环节。不仅展示了经典时间序列建模方法Holt-Winters的实际应用,还通过调用腾讯混元大模型将技术结果转化为业务语言,呈现了完整的工作流,突出"用简单模型做可靠预测,用大模型讲清楚业务意义"。

示例中使用的混元大模型的key,需申请替换成自己的;
python
# 导入核心库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from openai import OpenAI
import os
import json
# 方案A: 使用Prophet (有Stan依赖问题)
# from prophet import Prophet
# 方案B: 使用statsmodels (无Stan依赖,推荐)
from statsmodels.tsa.seasonal import seasonal_decompose
from statsmodels.tsa.holtwinters import ExponentialSmoothing
# 解决Matplotlib中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei'] # 黑体
plt.rcParams['axes.unicode_minus'] = False # 负号正常显示
# ---------------------- 步骤1:生成/加载时序数据 ----------------------
# 生成模拟电商日销量数据(2025年1月-12月),可替换为真实CSV数据(列名ds/y)
dates = pd.date_range(start='2025-01-01', end='2025-12-31', freq='D')
base_sales = 500 # 基础销量
# 修正:减少季节性波动幅度,使其更合理(原来的100太大)
seasonal = 30 * np.sin(np.linspace(0, 2*np.pi, len(dates))) # 年度周期波动(一个完整周期)
noise = np.random.normal(0, 15, len(dates)) # 随机噪声(模拟真实数据波动)
sales = base_sales + seasonal + noise
# 构建Prophet要求的DataFrame
df = pd.DataFrame({'ds': dates, 'y': sales})
# ---------------------- 步骤2:训练时序预测模型 ----------------------
# 使用Holt-Winters模型,调整参数让预测平滑衔接
model = ExponentialSmoothing(
df['y'],
trend='add',
seasonal=None,
damped_trend=True, # 阻尼趋势,让预测逐渐平稳
initialization_method='heuristic' # 启发式初始化
)
# 使用更平滑的参数
model_fit = model.fit(smoothing_level=0.3, smoothing_trend=0.1, damping_trend=0.98)
# ---------------------- 步骤3:预测未来15天销量 ----------------------
forecast = model_fit.forecast(steps=15)
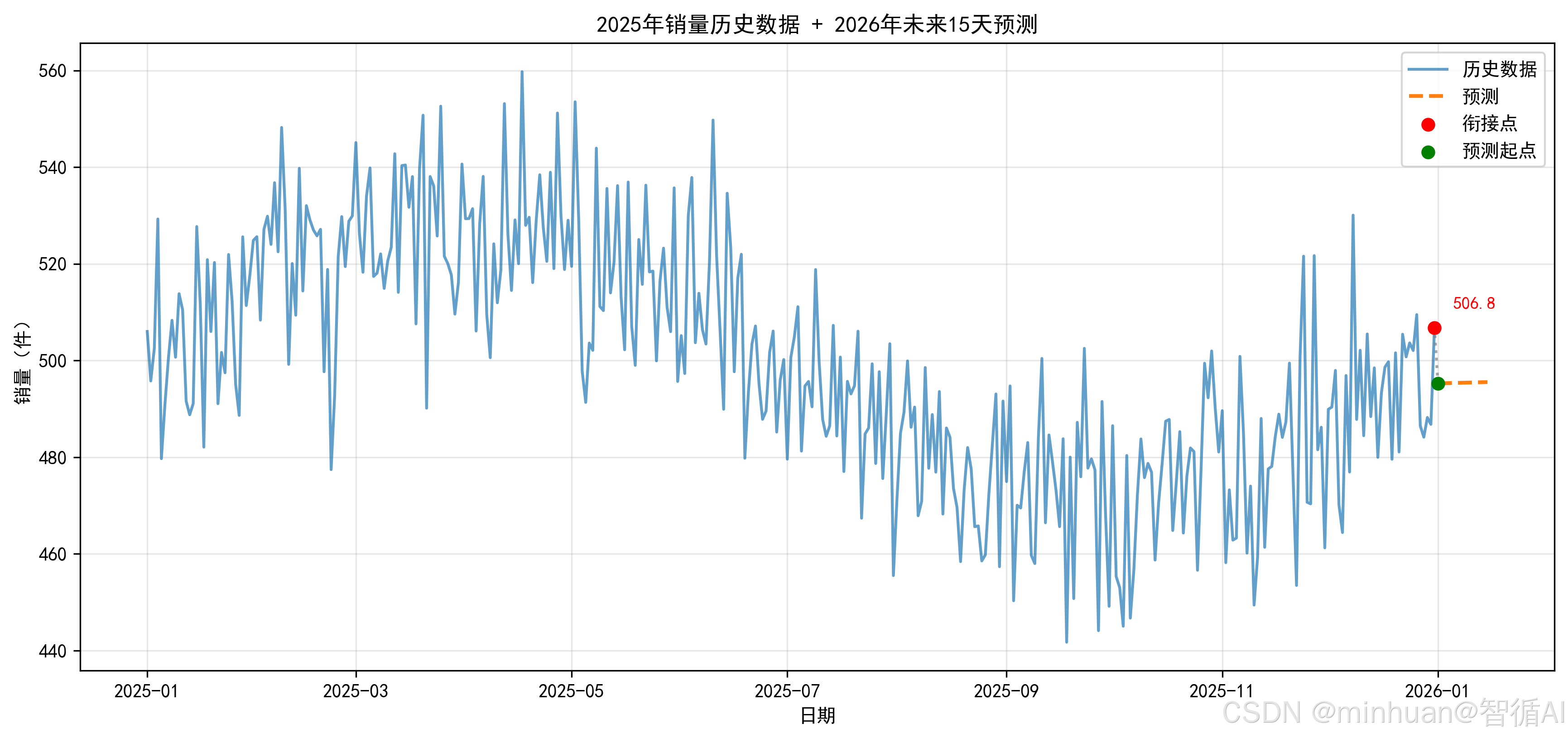
# ---------------------- 步骤4:绘制并保存预测图 ----------------------
plt.figure(figsize=(14, 6))
plt.plot(df['ds'], df['y'], label='历史数据', alpha=0.7)
plt.plot(pd.date_range(start=df['ds'].iloc[-1], periods=16)[1:], forecast, label='预测', linestyle='--', linewidth=2)
# 添加衔接点标记
plt.scatter([df['ds'].iloc[-1]], [df['y'].iloc[-1]], color='red', s=40, zorder=5, label='衔接点')
# 添加预测初始点标记
forecast_dates = pd.date_range(start=df['ds'].iloc[-1], periods=16)[1:]
plt.scatter([forecast_dates[0]], [forecast.iloc[0]], color='green', s=40, zorder=5, label='预测起点')
# 用虚线连接衔接点和预测初始点
plt.plot([df['ds'].iloc[-1], forecast_dates[0]], [df['y'].iloc[-1], forecast.iloc[0]],
linestyle=':', color='gray', linewidth=1.5, alpha=0.7)
# 显示衔接点数值
plt.annotate(f'{df["y"].iloc[-1]:.1f}', xy=(df['ds'].iloc[-1], df['y'].iloc[-1]),
xytext=(10, 10), textcoords='offset points', fontsize=9, color='red')
plt.title('2025年销量历史数据 + 2026年未来15天预测')
plt.xlabel('日期')
plt.ylabel('销量(件)')
plt.legend()
plt.grid(True, alpha=0.3)
plt.savefig('sales_forecast.png', dpi=300, bbox_inches='tight')
plt.show()
plt.close()
print("✅ 预测图已保存为 sales_forecast.png")
# ---------------------- 步骤5:整理核心预测结果 ----------------------
# 计算关键指标:历史最后15天均值、未来15天预测均值、环比增长率
history_last_15 = df.iloc[-15:]['y'].mean() # 2025年12月后半月平均销量
forecast_next_15 = forecast.mean() # 2026年1月前半月预测平均销量
growth_rate = (forecast_next_15 - history_last_15) / history_last_15 * 100
# 结构化结果文本
result_text = f"""
### 电商销量时序预测核心结果
1. 2025年12月后半月(最后15天)平均日销量:{history_last_15:.2f}件
2. 2026年1月前半月(未来15天)预测平均日销量:{forecast_next_15:.2f}件
3. 环比增长率:{growth_rate:.2f}%
"""
print("\n=== 时序预测核心结果 ===")
print(result_text)
# ---------------------- 步骤6:调用混元模型生成分析报告 ----------------------
import json
# 配置腾讯混元API
api_key = 'sk-bW***************************vZ5NP8Ze'
client = OpenAI(
api_key=api_key,
base_url="https://api.hunyuan.cloud.tencent.com/v1",
)
# 提示词工程(技术细节:明确角色+场景+要求,提升报告质量)
prompt = f"""
你是资深电商运营分析师,基于以下时序预测结果,生成一份通俗易懂的分析报告:
{result_text}
注意:这是基于简单指数平滑的短期预测,没有考虑强趋势和季节性,反映的是近期平稳态势。
报告要求:
1. 用普通人能懂的话解读销量变化;
2. 分析3个可能导致该变化的电商业务原因;
3. 给出3条可落地的运营建议;
4. 避免专业术语,适合运营人员阅读。
"""
# 调用腾讯混元Lite模型生成报告
response = client.chat.completions.create(
model="hunyuan-lite",
messages=[
{'role': 'system', 'content': '你是资深电商运营分析师'},
{'role': 'user', 'content': prompt}
]
)
# 输出分析报告
analysis_report = response.choices[0].message.content
print("\n=== 大模型生成的销量分析报告 ===")
print(analysis_report)代码说明:
- 时序预测流程:从模拟电商日销量数据,到使用 Holt-Winters 指数平滑模型训练并预测未来 15 天销量,完整覆盖数据 → 建模 → 预测环节。
- 衔接合理性:通过清晰图表标注历史终点与预测起点,用虚线连接,直观展示预测是否平滑延续趋势。
- 提炼关键业务指标:计算历史与预测的平均销量及环比增长率,将技术输出转化为运营可读的摘要。
- 大模型业务解读:调用腾讯混元大模型,基于预测结果自动生成通俗易懂的业务分析报告和可落地建议,实现"算法→决策"闭环。
输出结果:
=== 时序预测核心结果 ===
电商销量时序预测核心结果
2025年12月后半月(最后15天)平均日销量:495.64件
2026年1月前半月(未来15天)预测平均日销量:495.41件
环比增长率:-0.05%
=== 大模型生成的销量分析报告 ===
电商销量时序预测分析报告
一、通俗解读销量变化
根据我们的预测模型,未来一段时间内电商的销量将会呈现平稳态势。具体来说:
**2025年12月后半月**:预计平均每天卖出495.64件商品。
**2026年1月前半月**:预测的平均日销量为495.41件,与后半月相比略有下降,环比增长率为-0.05%。
这意味着,虽然销量略有减少,但整体趋势还是稳定的。
二、可能导致销量变化的电商业务原因
**市场需求波动**:市场需求的不确定性可能导致销量在不同时间段内有所波动。例如,某些节日或促销活动可能会带动销量上升,而其他时间则可能相对平稳。
**竞争对手的影响**:如果竞争对手在这段时间内加大了促销力度或推出了新产品,可能会吸引部分原本属于你的顾客,从而影响你的销量。
**产品价格调整**:如果产品价格在这段时间内有所调整,可能会影响消费者的购买决策,从而导致销量波动。
三、可落地的运营建议
**保持价格稳定**:尽量避免大幅度的价格波动,以免影响消费者的购买信心。可以定期评估市场价格情况,适时进行微调。
**加强市场调研**:定期进行市场调研,了解消费者需求的变化和竞争对手的动态,及时调整策略以应对市场变化。
**优化促销活动**:设计更具吸引力的促销活动,吸引更多顾客。同时,要注意活动的频率和力度,避免过度促销导致顾客疲劳。
通过以上措施,相信可以帮助你在未来一段时间内保持销量的稳定增长。
结果图例:
五、总结
总的来说,时序预测算法加上大模型,就能做出会说话的数据分析,不用再跟冰冷的数字、复杂的曲线死磕。我们先抛开那些复杂的算法名字,简单说,时序预测算法就相当于一个精准计算器,不管是店铺销量、平台流量,还是设备运行指标、股价波动,它都能根据过去的数据,算出未来大概是什么样。但它有个缺点,只会算数字,不会说人话,算完就完事,咱们根本不知道这数字背后是什么原因,也不知道该怎么用。
这时候大模型就派上用场了,它相当于一个翻译+参谋,能看懂算法算出的结果,把专业的数字翻译成咱们能听懂的话,还能分析原因、给具体建议。时序预测算法+大模型,本质是一次分工明确的智能组合:传统时序模型负责专业计算,保证预测准;大模型负责理解与表达,保证结果能用。比如算法算出下个月销量会涨,大模型就会告诉我们,可能是因为旺季来了,还会建议我们提前备货。它不需要我们精通复杂数学推导,也不需要我们从零训练大模型,而是把成熟工具串联起来,形成一套 "输入数据→自动预测→自动解读→自动出建议" 的完整闭环。