目录
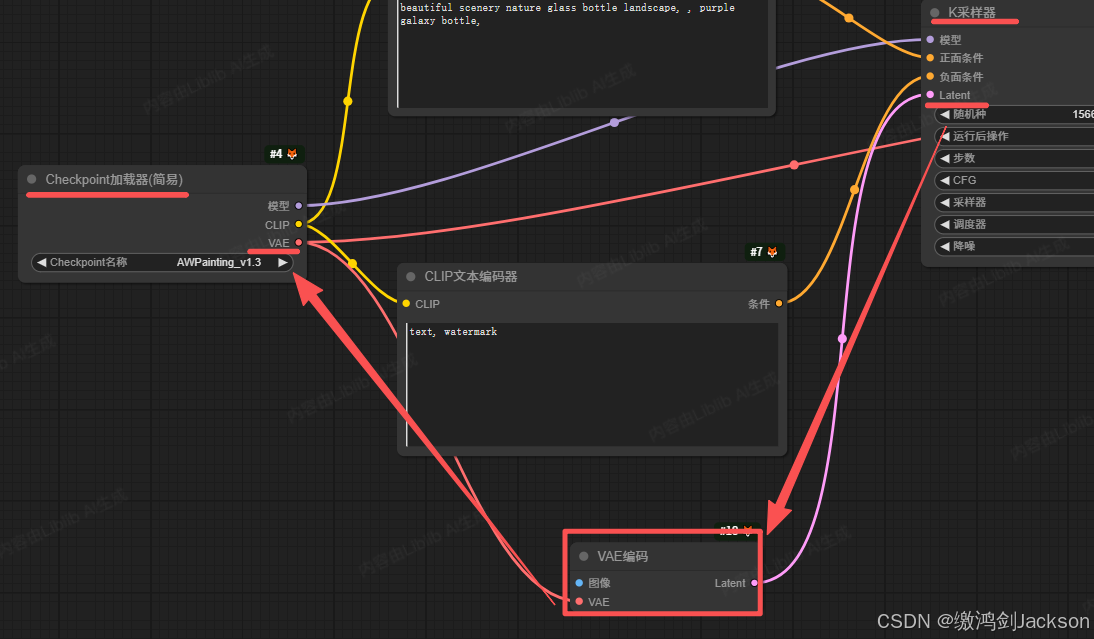
2.从K采样器的Latent接线头,拉出一个新的"VAE编码"节点,并将新VAE编码节点的VAE接线头和Checkpoint相连
一.搭建工作流的步骤
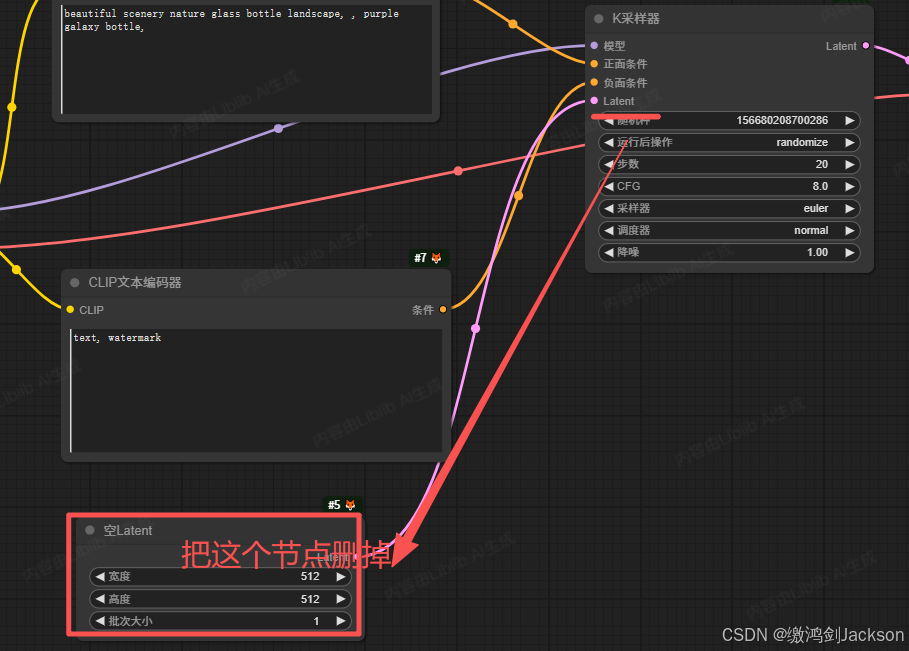
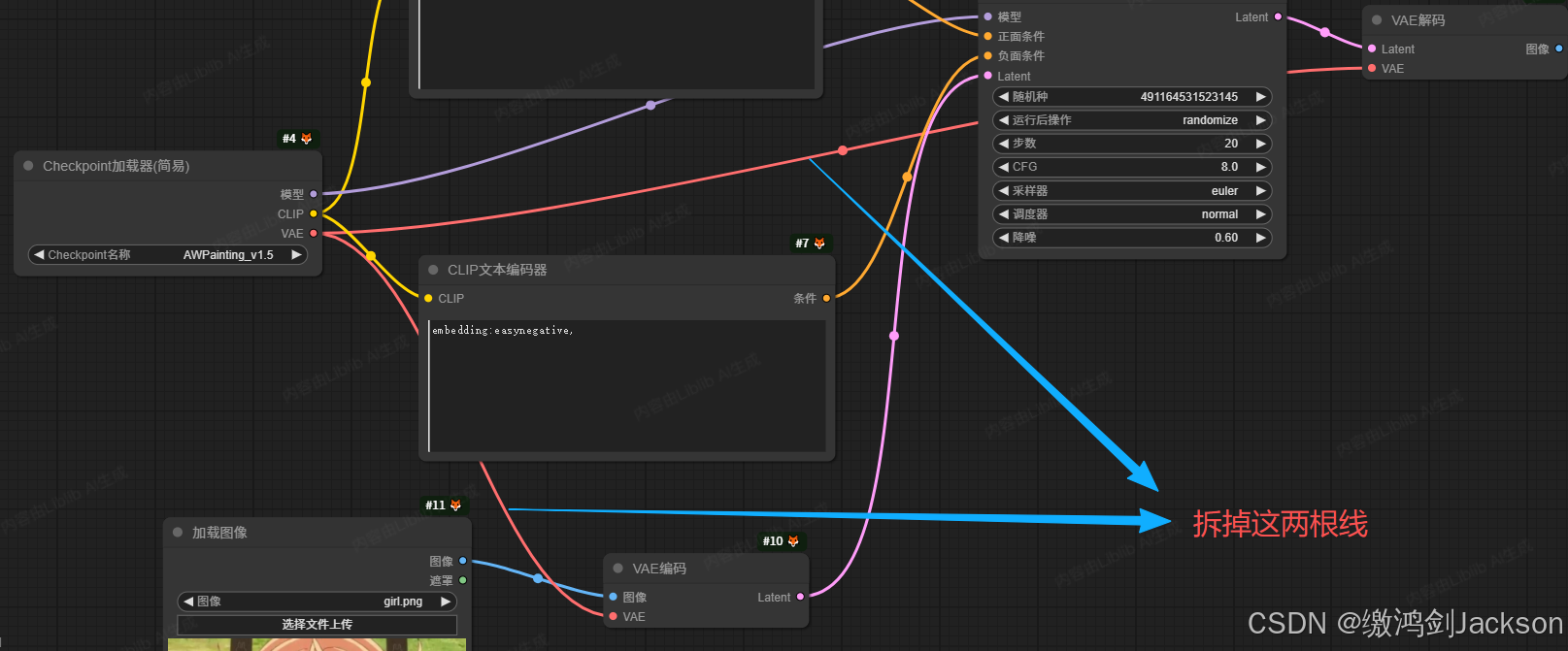
1.删掉K采样器的Latent节点
2.从K采样器的Latent接线头,拉出一个新的"VAE编码"节点,并将新VAE编码节点的VAE接线头和Checkpoint相连
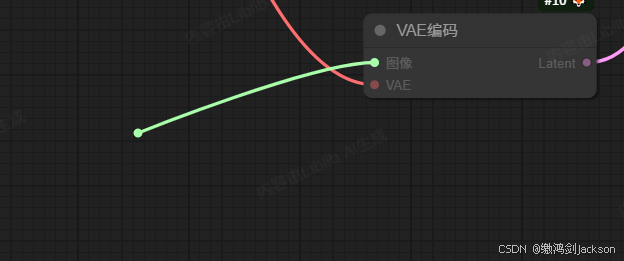
3.拖拽VAE编码节点的图像接线头,添加一个图像节点
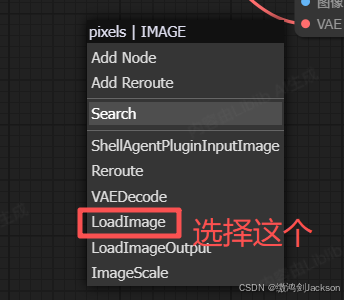
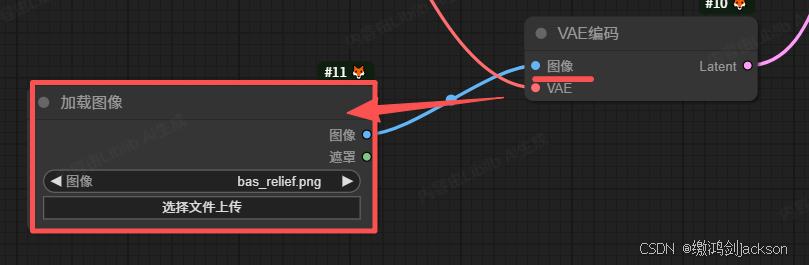
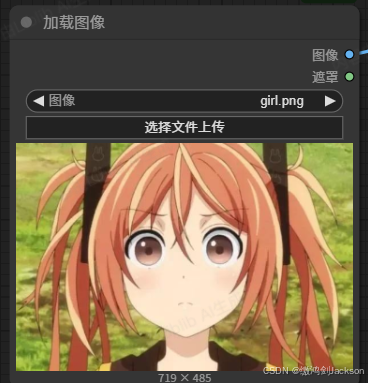
4.在图像节点,上传一张图片
5.在CLIP文本编码器,输入质量词

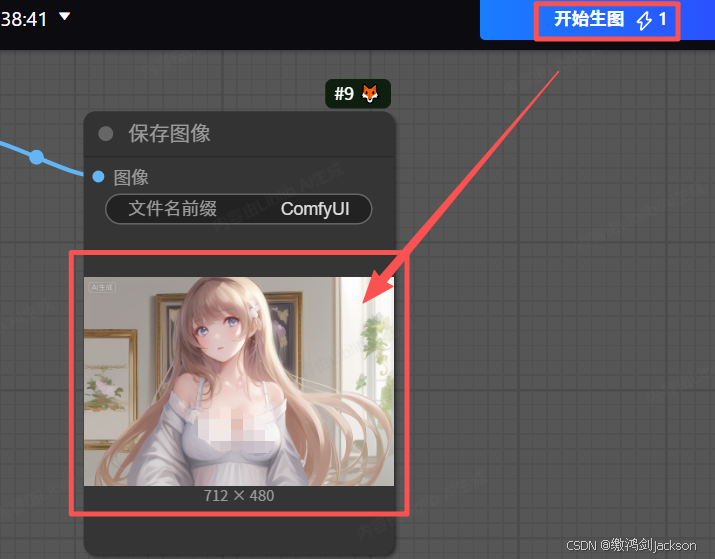
6.点击生图,查看效果
二.降噪值的作用
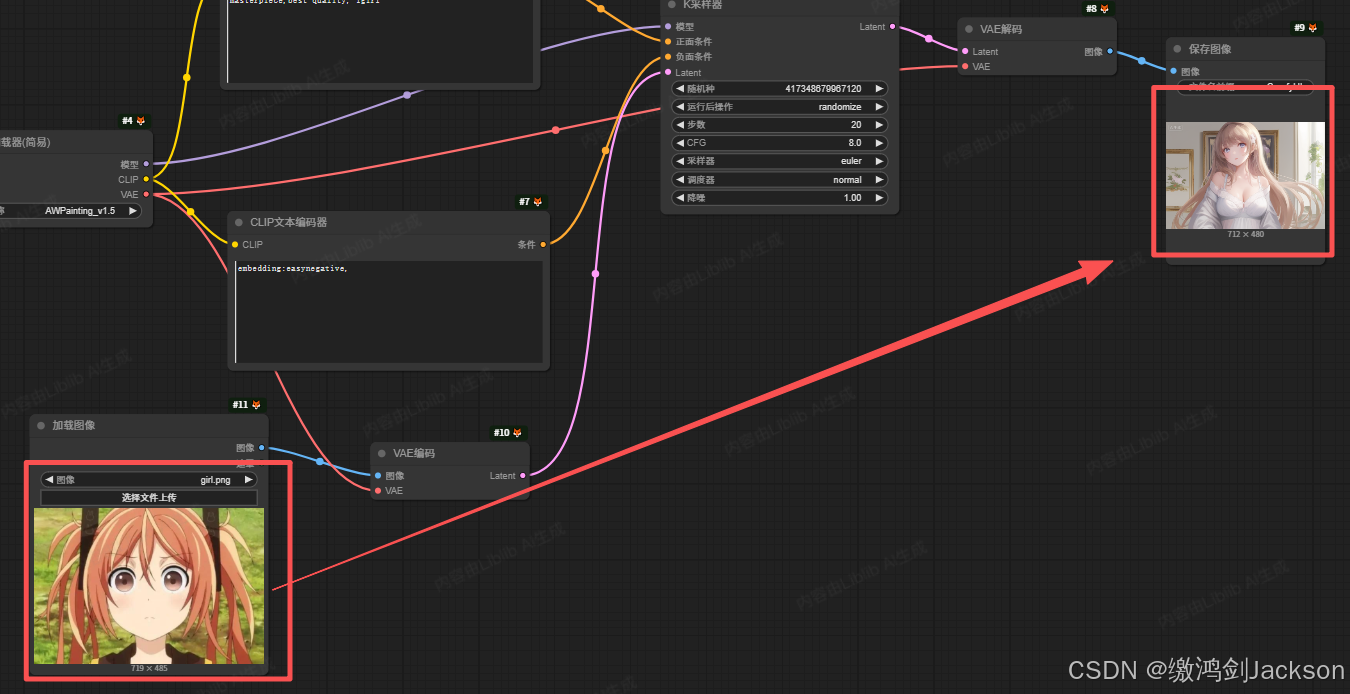
1.先看一个现象
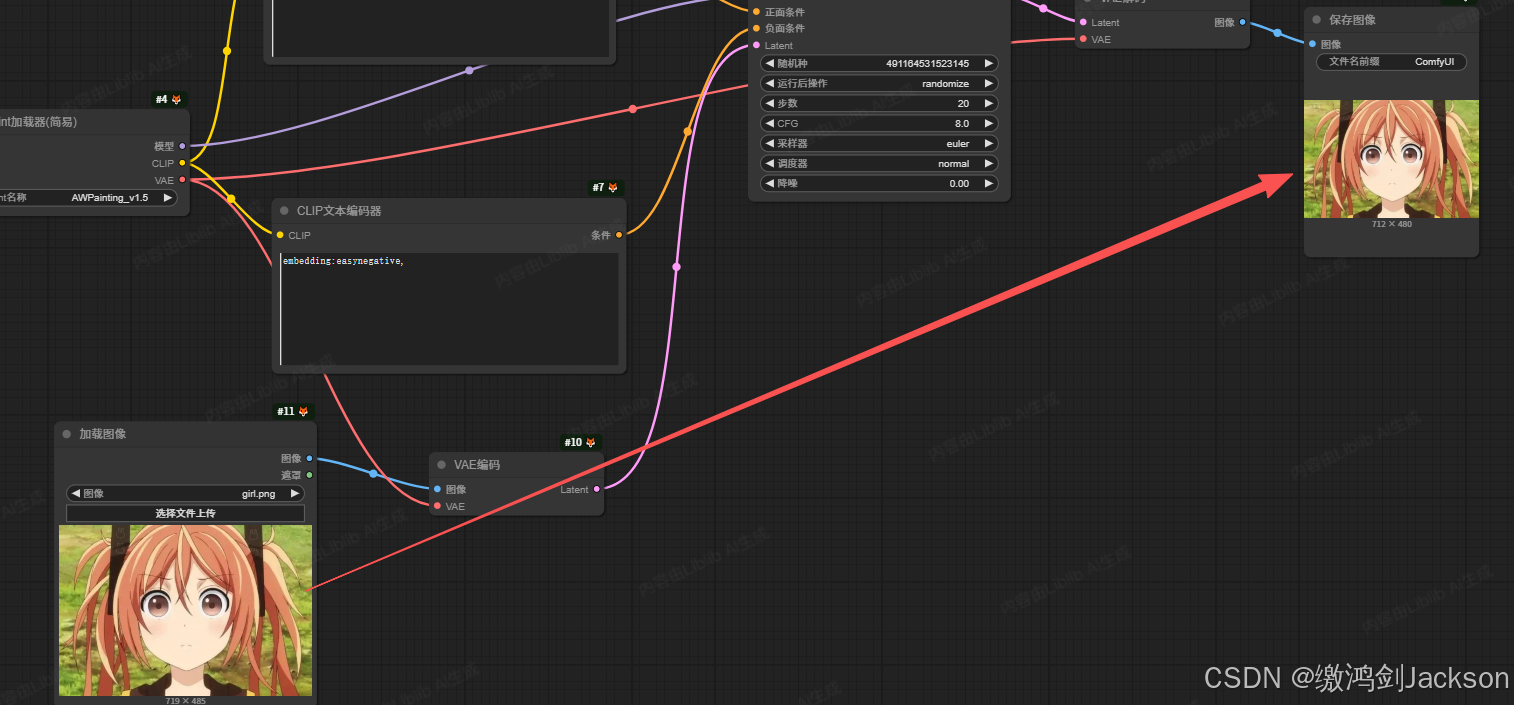
如下图所示,我们上传的图,和最终生成的图,只能说一点关系都没有啊,这是因为什么?
2.分析原因
答案:因为K采样器的降噪值开的太高了。
- 降噪值越大,原图的噪点就越多,AI就越有发挥想象的空间
- 降噪值越小,原图的噪点就越小,AI就没有发挥想象的空间
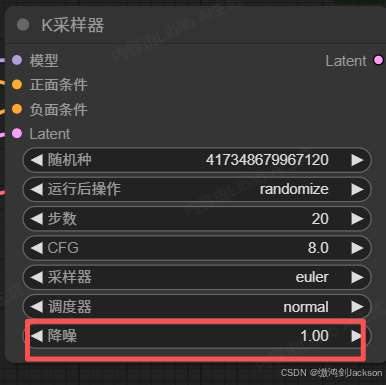
根据这个规律,那我们把K采样器的降噪值设置成0,是不是图片就不会产生变化?可以试一下
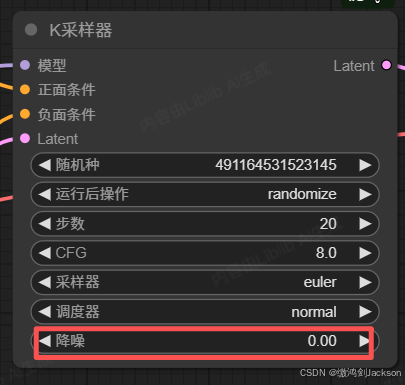
可见,当我们把K采样器的降噪值设置成0以后,就不会给原图添加任何噪点,此时AI就没有发挥想象的空间,因此最终生成的图片只能是原图。
3.做法
因此,为了让AI生成的图,和原图有一点相似,但是别完全相似/完全没关系,此时建议降噪值设置成0.3~0.6
三.VAE的作用
1.先看一个现象
如下图所示,我们的原图明显色彩更浓郁,而生成的图片却感觉色彩淡淡的,这是为什么?
2.分析原因
答案:因为采用的大模型自带的VAE。自己设置一个VAE就行了。
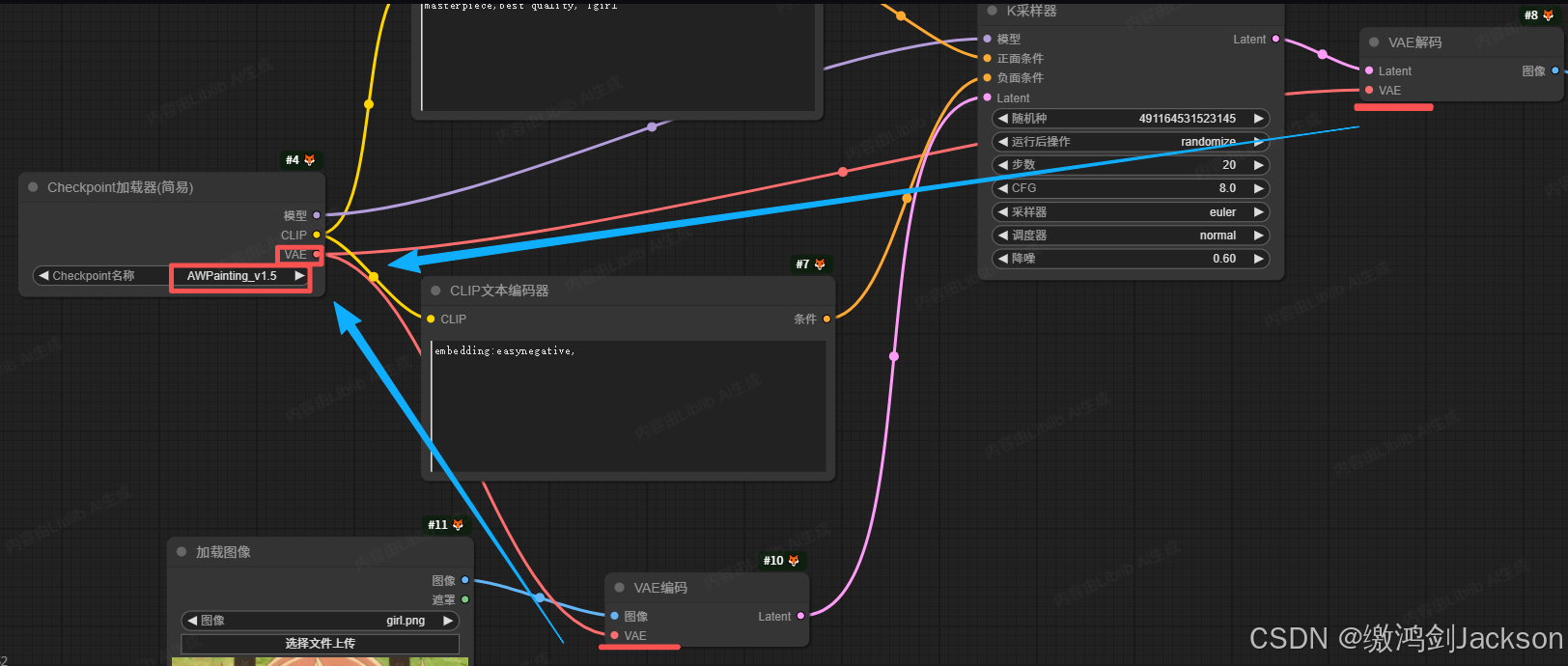
如下图所示,VAE编码、VAE解码,这两个节点,都连着Checkpoint加载器的VAE节点呢,此时用的就是大模型自带的VAE
3.具体做法
①先断开VAE编码、VAE解码和Checkpoint的VAE接线头的连线。
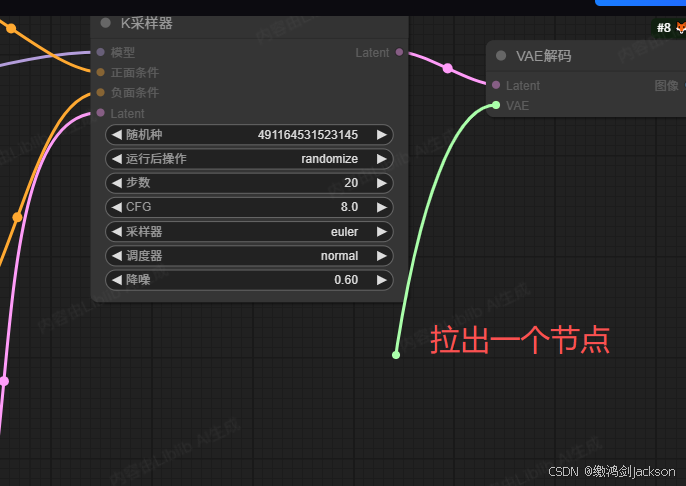
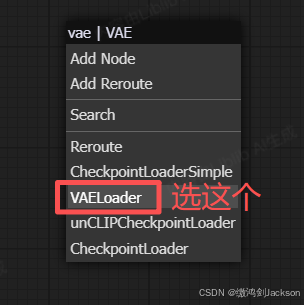
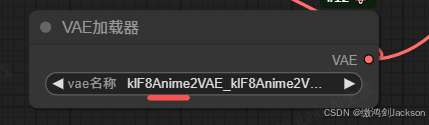
②从VAE编码(或者VAE解码)的VAE接线头,拉出一个VAE加载器
③确保VAE加载器分别和VAE编码、VAE解码这两个节点相连
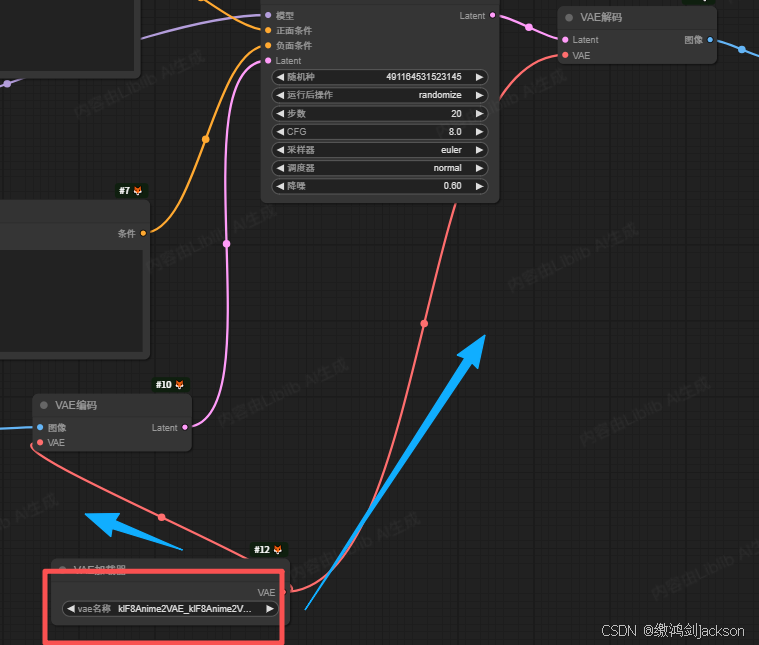
④给VAE加载器选择一个大模型(此时选择下图的带anime的大模型,表示动漫风格,这个色彩比较鲜艳)
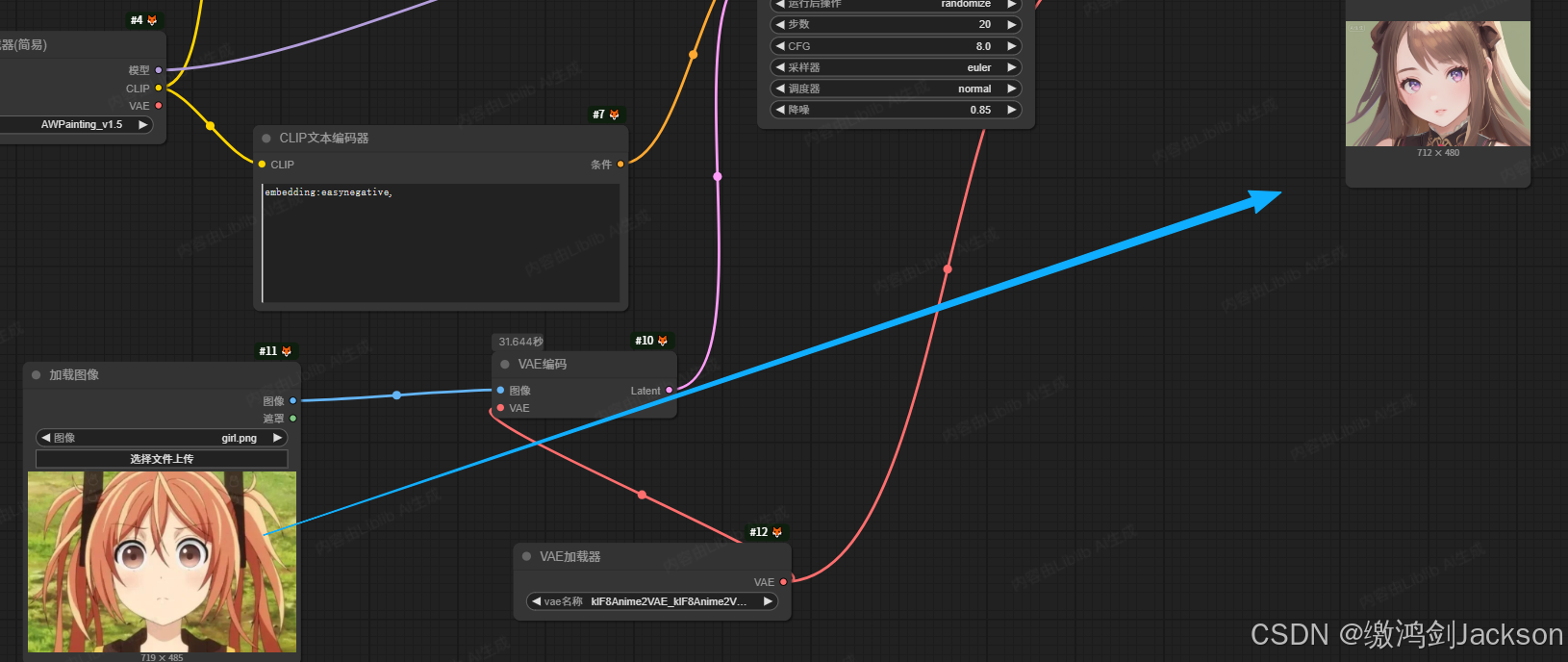
⑤再次点击生图,测试效果
如下图,可见此时稍微好点了。
四.图生图原理
1.先思考一个问题
K采样器的降噪值,是如何做到让生成图片与原图相似,或者不相似呢?
2.原理讲解
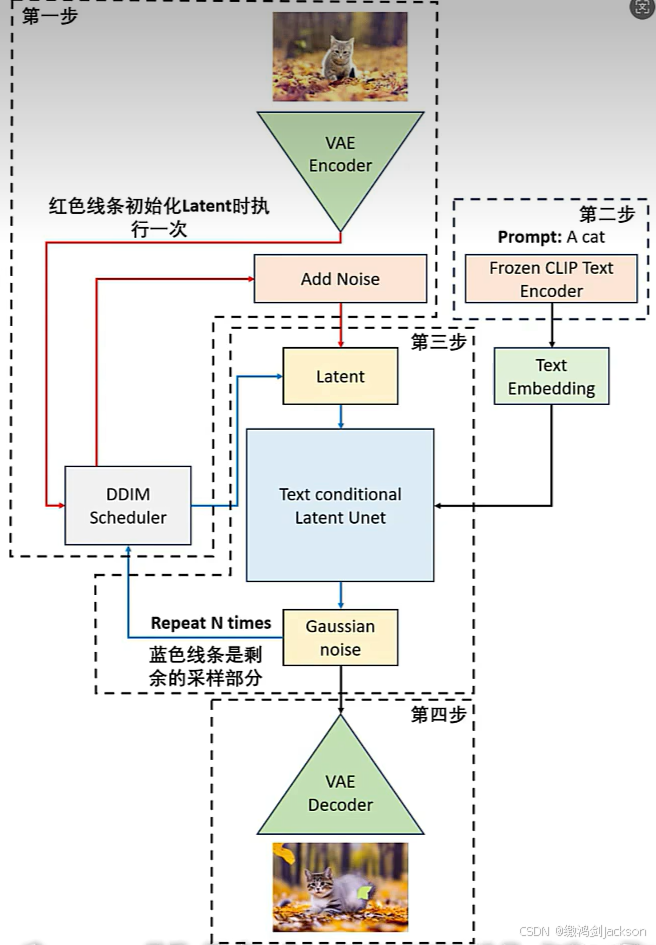
上面的流程图看不懂?没关系,我直接讲大白话(大致流程):
①我们上传的原图,会被VAE编码节点(最上面的绿色三角),由像素空间图像转换成浅空间图像,然后发送到K采样器,被K采样器添加上噪声(噪点的多少,由K采样器的降噪值决定),最终,这张被添加了噪点的浅空间图像,被发送到Unet模型
②用户输入的质量词,被转换成特征向量,也发送到Unet模型
③上述的①(图片输入)和②(文本输入),在Unet模型中,共同作用,最终生成一张浅空间图像,然后被VAE解码节点,转换成像素空间图像,也就是我们最终肉眼可见的图像。
五.实战:风格转换
1.要求
上传一张动漫风格的图片,然后你自己想办法设置一下工作流的各个节点,给它转换成写实风格的图片(说白了就是把动漫角色,变成真人)。
2.具体做法
①选择一个写实风格的大模型(这一步最关键)

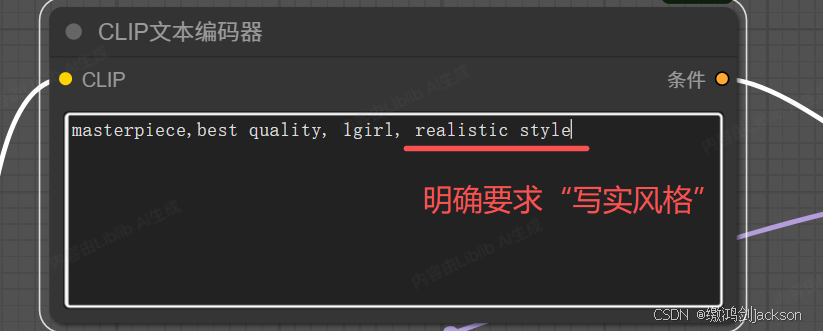
②在质量词中,添加"写实风格"字样的要求
③VAE加载器,选择sdxl
④点击生图,查看效果
可自行测试