文章:DVLA-RL: DUAL-LEVEL VISION-LANGUAGE ALIGNMENT WITH REINFORCEMENT LEARNING GATING FOR FEW-SHOT LEARNING
代码:暂无
单位:山东大学、深圳环湾研究院、山东财经大学计算机与人工智能学院
一、问题背景
深度学习在大规模标注数据的支撑下取得了显著成就,但现实场景中获取大量标注数据往往成本高昂,甚至不切实际。少样本学习(FSL)应运而生,它旨在通过少量标注样本,将从基础数据集学到的知识推广到新类别任务中,在罕见病诊断、工业异常检测等领域具有广泛应用前景。
现有少样本学习方法中,部分方案尝试融合大语言模型(LLMs)的语义信息来丰富视觉表征,但存在明显局限:要么仅依赖单一层级的语义(低层级属性或高层级描述),要么采用静态融合模块,忽视了视觉与语言从低层级到高层级语义的渐进式、自适应对齐需求,导致语义增益有限,难以充分挖掘有限样本中的判别性信息。
二、方法创新
针对上述问题,研究团队提出了双级视觉-语言对齐与强化学习门控(DVLA-RL)框架,核心包含两大创新模块:
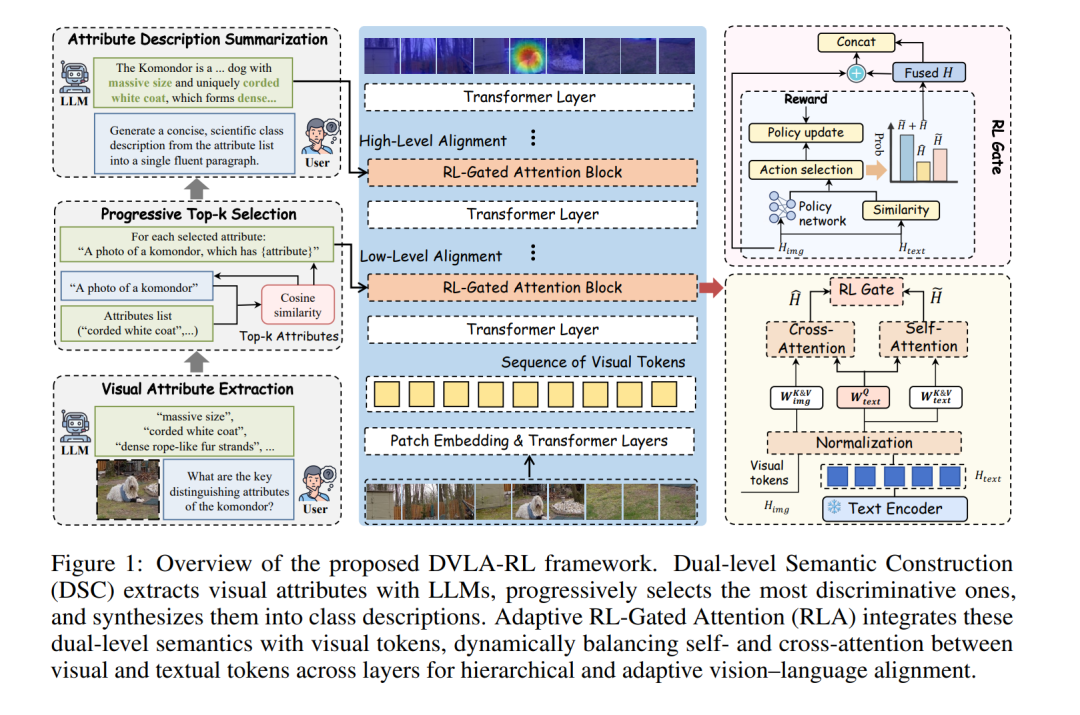
1. 双级语义构建(DSC)模块
以类别名称和支持样本为双重条件,通过LLM生成具有区分性的候选属性;再通过渐进式Top-k选择策略,基于余弦相似度迭代筛选出最相关的属性,抑制语义幻觉和冗余信息;最后将筛选后的属性合成为连贯的类别描述,同时提供细粒度的低层级属性和整体性的高层级描述,兼顾精准定位与全局理解。
2. 强化学习门控注意力(RLA)模块
将跨模态融合转化为序列决策过程,通过基于情节强化学习训练的轻量级策略,自适应平衡自注意力与交叉注意力的贡献。该机制让浅层网络聚焦局部属性细节,深层网络强调全局语义,实现视觉与语言在不同网络层级的精准对齐,动态整合双级语义与视觉特征。
三、实验结果
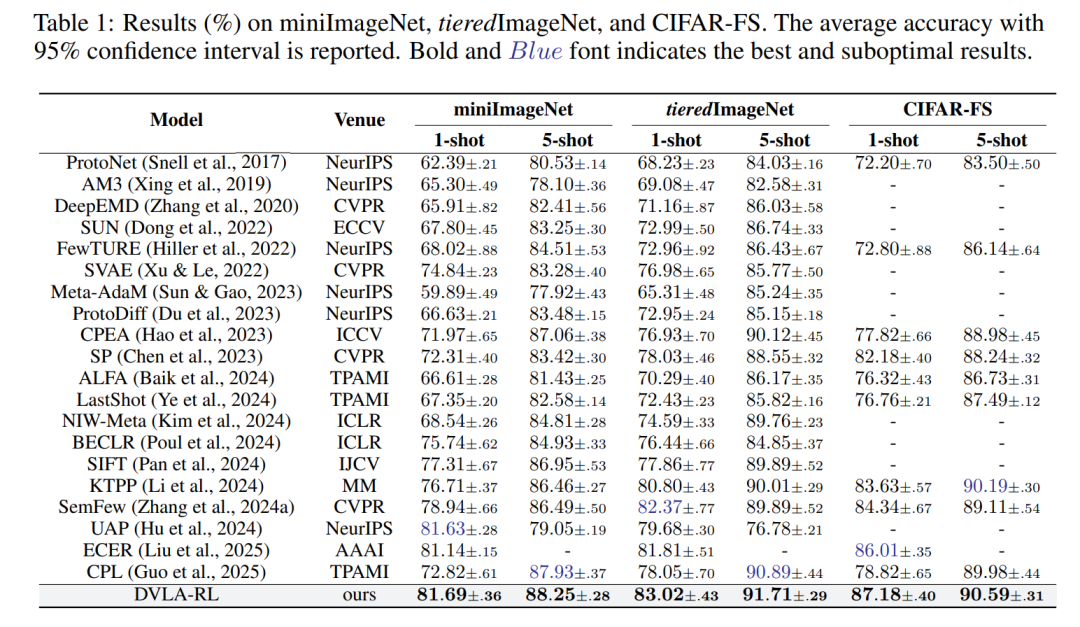
DVLA-RL在三类少样本学习场景的9个基准数据集上进行了全面验证,表现亮眼:
-
通用少样本分类:在miniImageNet、tieredImageNet、CIFAR-FS数据集上,1-shot和5-shot设置下均取得最优或次优性能,其中miniImageNet的1-shot准确率达81.69%、5-shot达88.25%,CIFAR-FS的1-shot准确率达87.18%、5-shot达90.59%,超越强基线SemFew 0.6%-2.8%。
-
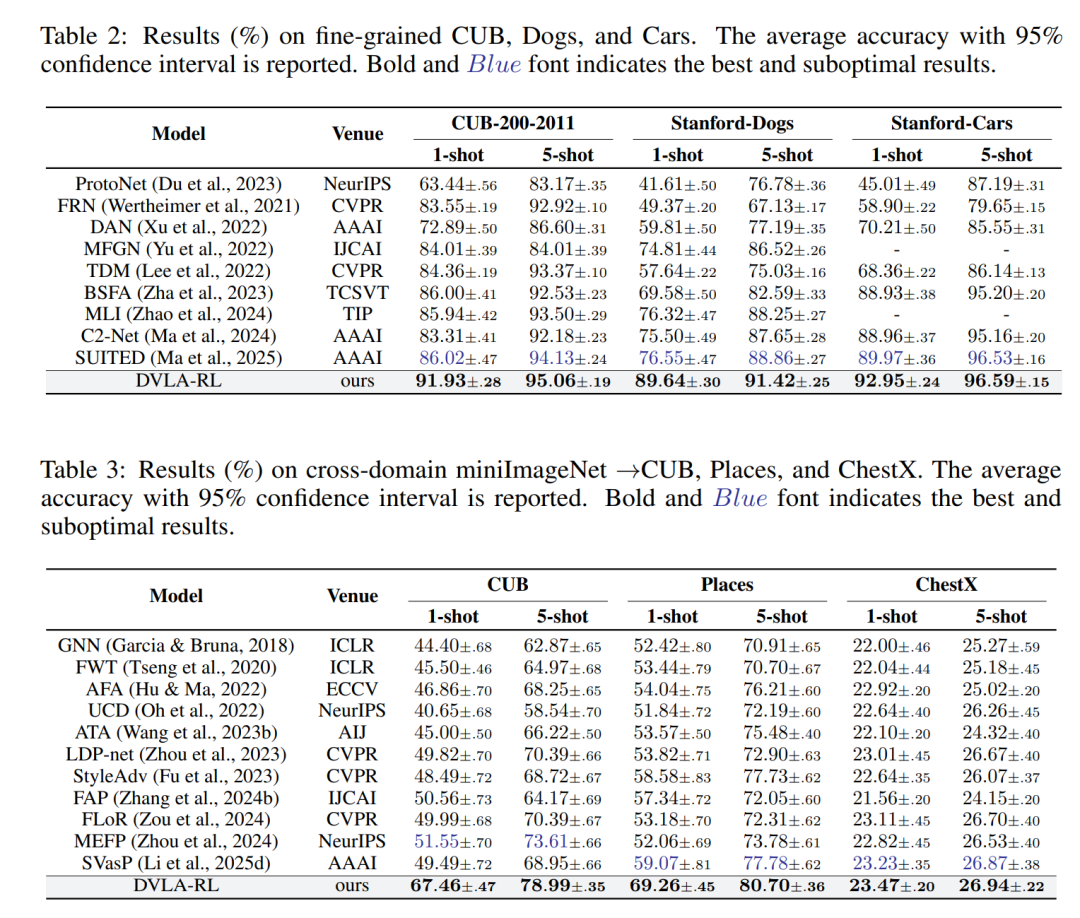
细粒度少样本分类:在CUB-200-2011、Stanford Dogs、Stanford Cars数据集上表现突出,1-shot设置下显著超越第二名SUITED 5.4%-15.3%,CUB数据集的1-shot准确率达91.93%、5-shot达95.06%,精准捕捉类别间细微差异。
-
跨域少样本分类:在miniImageNet作为训练集、CUB、Places、ChestX作为测试集的跨域场景中,1-shot和5-shot任务均优于所有基线,其中Places数据集的1-shot准确率达69.26%、5-shot达80.70%,在医学影像数据集ChestX上也实现了有效突破。
此外,消融实验证实,DSC的双级语义和Top-k选择、RLA的自适应融合均对性能有显著提升,各组件协同作用达到最优效果。
四、优势与局限
优势
-
层级化对齐:首次实现视觉-语言从低层级到高层级的渐进式对齐,兼顾细粒度属性与全局描述的互补价值。
-
动态自适应:通过强化学习门控机制,动态平衡不同网络层级的注意力分配,适配视觉特征的层级化特性。
-
高效低耗:采用轻量化设计,文本语义离线生成,训练时间(22分钟)、推理延迟(80ms)和GPU内存消耗均低于现有LLM-based方法,计算效率优势明显。
-
鲁棒性强:对不同LLM(Qwen2.5-VL-32B、GPT-4 turbo、GPT-4o)均有良好适配,且能有效抑制语义幻觉。
局限
-
跨域极端场景性能受限:在ChestX等医学影像数据集上,虽取得SOTA,但受限于影像本身低纹理、类别表现重叠等特性,性能提升幅度小于自然图像数据集。
-
依赖LLM语义质量:尽管通过Top-k选择和自适应融合降低了影响,但LLM生成语义的准确性仍会对最终性能产生间接影响。
-
超参数敏感度过低:虽鲁棒性强,但Beta浓度和RL权重等超参数仍需根据不同数据集微调以达到最优效果。
五、一句话总结
DVLA-RL通过双级语义构建与强化学习门控注意力的创新组合,实现了少样本学习中视觉-语言的层级化、动态化对齐,在三类典型场景的9个基准数据集上刷新SOTA,同时兼顾高效性与鲁棒性,为少样本学习的跨模态融合提供了新范式。