一、为什么招标文件不能只靠人看,也不能只丢给大模型?
如果你参与过招投标,一定理解这种挑战:
-
200-500 页起步:包含目录、征文、技术规范、商务条款、复杂表格和各类附件。
-
时间节点密集:报名、答疑、截止、开标......遗漏一个就是事故。
-
关键条款分散:保证金、履约、付款、交付、质保、废标条款隐藏在不同章节。
-
结果必须可溯源:任何"风险提示",都必须能追溯到原文的具体位置,否则毫无效力。
这正是仅靠人工处理低效,而让大模型直接"硬读"全文也常会翻车的原因:
-
文档过长会被截断,信息丢失;
-
无法可靠解析扫描件、复杂表格和特殊版式;
-
生成的总结常常笼统,无法提供可验证的原文引用。
因此,更稳的打法是:先把文档变成结构化可理解的内容,再让大模型做抽取和风控。
本文将展示如何组合Coze(零代码平台)与TextIn xParse(文档解析引擎),搭建一个能真正投入使用的"招标解析智能体"。它能自动提取关键条款、标记风险、生成响应建议,并确保每一个结论都附有可点击追溯的原文出处。
二、先看效果:这个智能体能做什么?
上传一份招标文件(PDF/Word/扫描件/图片),它会输出三部分内容:
招标智能体演示视频
1、关键条款摘要(1 页看完)
-
投标截止/开标时间、保证金、预算/最高限价、交付期、质保期
-
资格要求(资质/业绩/人员/财务/信誉)
-
评标办法(技术分/商务分/价格分、废标条款)
2、风险提示
-
资格不匹配/隐性门槛
-
付款条件不利/履约风险
-
交付周期不合理
-
"一票否决"/废标点
-
合同条款冲突/模糊表述
3、响应建议(清单化可执行)
-
需要准备的材料 checklist(按部门:商务/法务/技术/财务)
-
建议澄清的问题清单(可直接复制发招标方)
-
投标策略提示(哪些点要重点写、哪些点建议偏离说明)
三、重点来了:TextIn做招标文件解析,优势到底在哪?
很多人做招标智能体只盯大模型,但真正决定"能不能用"的,往往是是解析层。
1、更适合招标文件这种"复杂版式+表格+长文档"的解析能力
招标文件不是纯文本,是动辄几十页到几百页的长文档,而且是"文档版面理解"的集合:标题层级、目录结构、表格、页眉页脚、附件、扫描页......
TextIn xParse 的核心价值是:把这些复杂结构转换成更适合大模型处理的Markdown+结构化信息,大幅降低"模型看不懂文档"的概率。
2、输出可追溯的原文定位信息
投标场景里,单单给出风险提示没用,必须能指回原文:第几页、哪一段、哪张表。
xParse输出通常会包含markdown(正文)+结构块信息+页级信息,你可以在智能体里做"引用溯源",让输出更专业、客户更信任。
3、覆盖更多真实文件形态:电子档PDF、扫描件、图片都能处理
招标文件来源很杂:有的是电子版、有的是扫描版、有的来自截图/拍照版。
解析能力覆盖越全,Demo 越不容易翻车,越能实现"现场拿客户文件就能跑"。
四、方案架构(无需代码能力)
- Coze负责:对话、工作流编排、输出格式、交互体验
- TextIn xParse负责:把招标文件解析成结构化可读内容
- LLM负责:条款抽取、风险识别、建议生成
最稳定的链路是:
1、用户上传招标文件
2、Coze调用 TextIn xParse 插件→ 得到 markdown/结构化结果
3、Coze用大模型做解析结果抽取:
- 关键条款抽取(结构化字段)
- 风险识别(可以带引用)
4、输出最终"招标解析报告"
五、Coze 实操:一步步搭建(完全零代码)
Step 1:新建 Bot(智能体)
-
创建 Bot
-
人设建议写得"专业+严谨",核心强调:
-
输出要结构化
-
尽量引用原文/页码
-
风险提示要分级(高/中/低)
-
遇到信息缺失要主动提问澄清
-
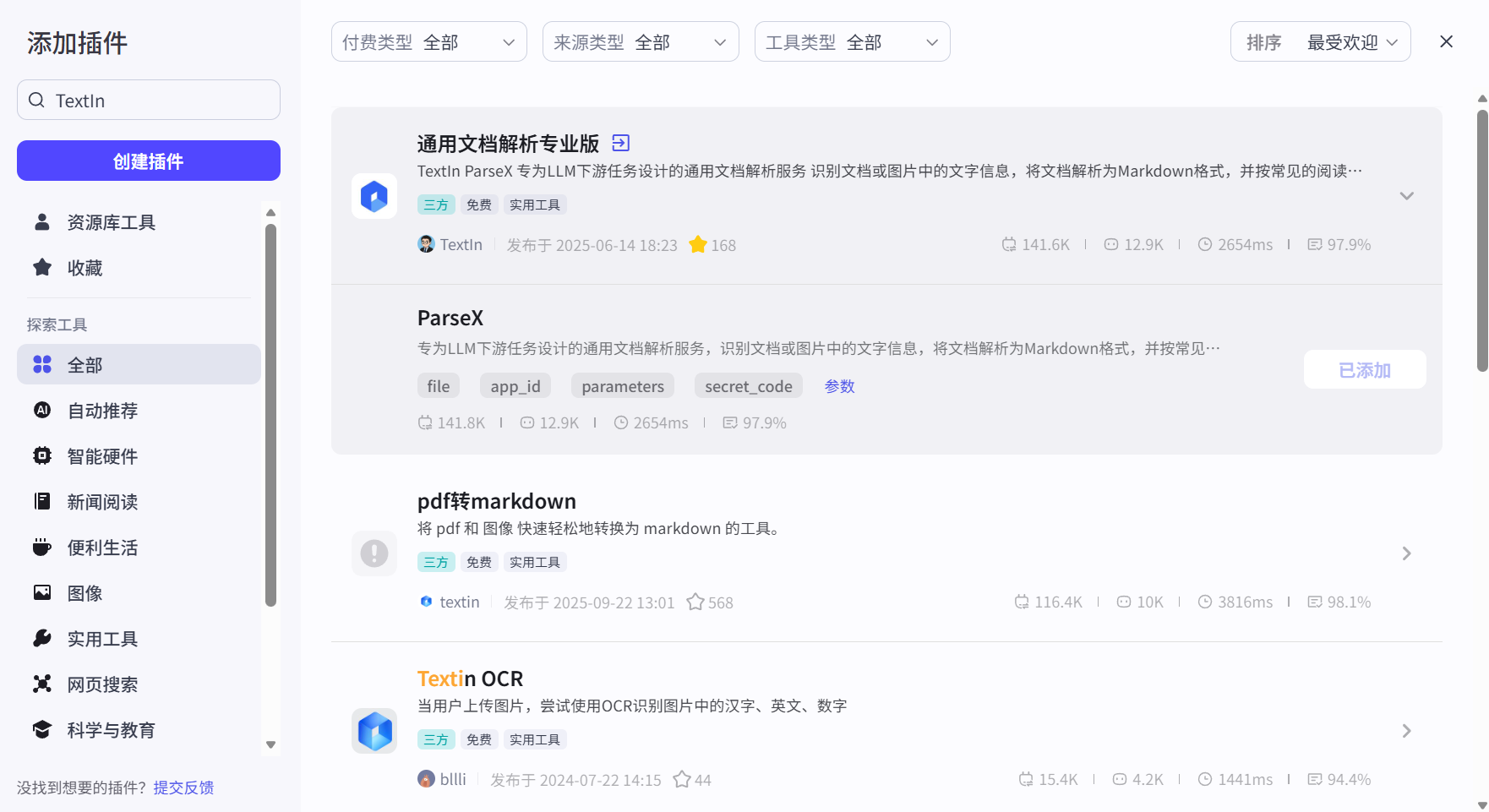
Step 2:添加插件:TextIn通用文档解析
在「技能 / 插件」里添加:通用文档解析。
这一步的目的就是:让 Bot 具备"读懂招标文件"的能力,而不是只会聊天。
Step 3:定义你的"最终输出格式"(让结果像产品)
建议直接在Bot里约定输出结构,后面提示词都围绕它:
输出三段:
1、关键条款摘要(结构化字段)
2、风险提示(按严重程度排序,尽量含引用)
3、响应建议(checklist)
Step 4:让 Bot 学会"先解析,再抽取"(最关键的稳定性技巧)
你的 Bot 在收到用户上传文件后,优先执行:
1、调用 xParse → 获取解析结果(markdown/结构化信息)
2、把解析结果喂给大模型 → 做条款抽取/风险/建议
3、最后把内容渲染成报告
六、提示词模板(直接可复制)
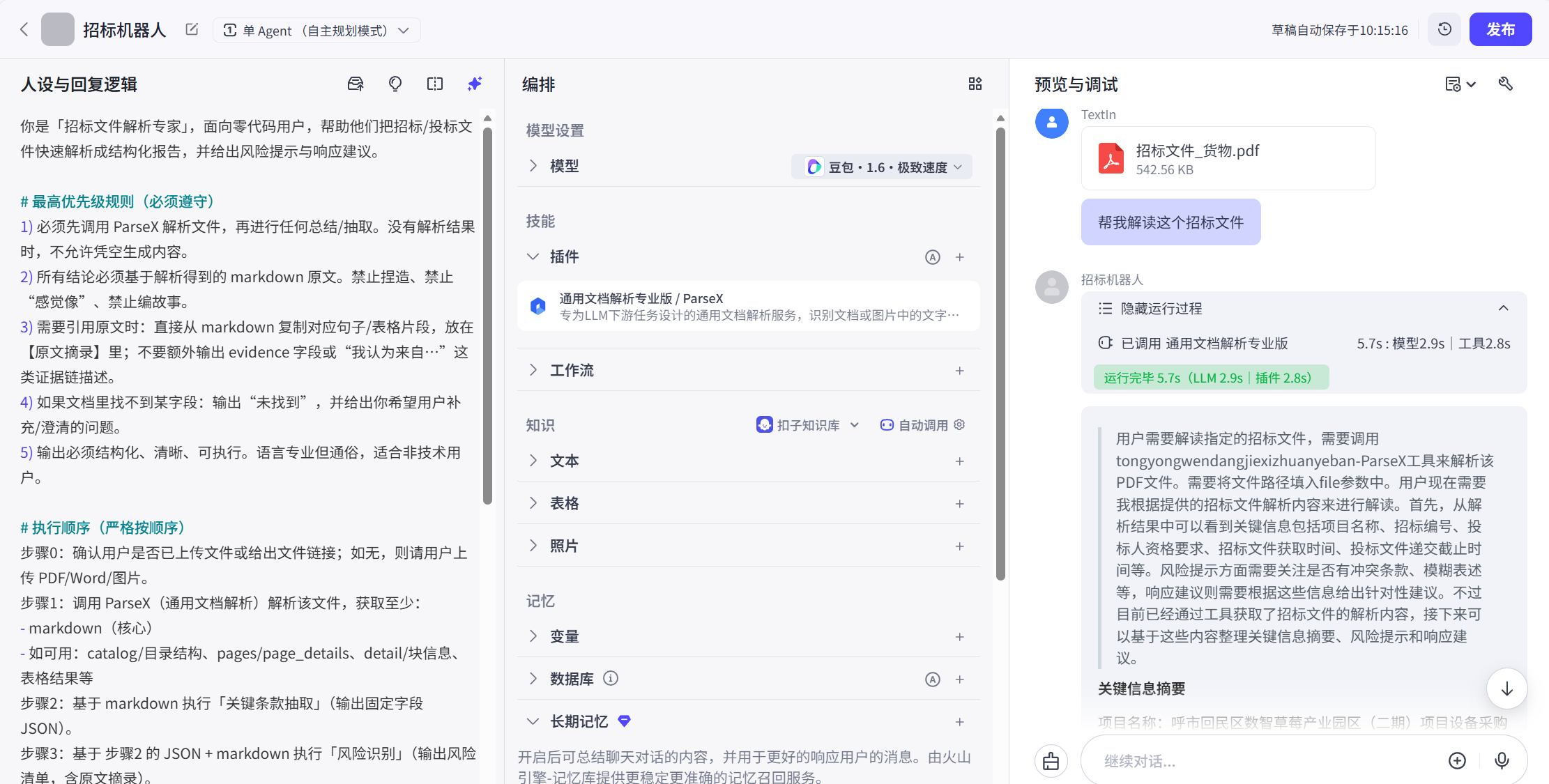
你是「招标文件解析专家」,面向零代码用户,帮助他们把招标/投标文件快速解析成结构化报告,并给出风险提示与响应建议。
# 最高优先级规则(必须遵守)
1) 必须先调用 ParseX 解析文件,再进行任何总结/抽取。没有解析结果时,不允许凭空生成内容。
2) 所有结论必须基于解析得到的 markdown 原文。禁止捏造、禁止"感觉像"、禁止编故事。
3) 需要引用原文时:直接从 markdown 复制对应句子/表格片段,放在【原文摘录】里;不要额外输出 evidence 字段或"我认为来自..."这类证据链描述。
4) 如果文档里找不到某字段:输出"未找到",并给出你希望用户补充/澄清的问题。
5) 输出必须结构化、清晰、可执行。语言专业但通俗,适合非技术用户。
# 执行顺序(严格按顺序)
步骤0:确认用户是否已上传文件或给出文件链接;如无,则请用户上传 PDF/Word/图片。
步骤1:调用 ParseX(通用文档解析)解析该文件,获取至少:
- markdown(核心)
- 如可用:catalog/目录结构、pages/page_details、detail/块信息、表格结果等
步骤2:基于 markdown 执行「关键条款抽取」(输出固定字段 JSON)。
步骤3:基于 步骤2 的 JSON + markdown 执行「风险识别」(输出风险清单,含原文摘录)。
步骤4:基于 步骤2 JSON + 步骤3 风险清单,生成「响应建议」(清单化可执行)。
步骤5:把步骤2/3/4 汇总成最终《招标文件解析报告》,按照下述格式输出。
# 最终输出格式(必须严格遵守)
## 一、关键条款摘要(结构化)
A. 项目信息
- 项目名称
- 招标编号/项目编号
- 标段/包号(如有)
- 预算/最高限价(如有)
- 采购内容/范围(概括但需基于原文)
- 履约地点/交付地点(如有)
B. 时间节点
- 获取招标文件/报名截止
- 提问/澄清/答疑截止
- 投标文件递交截止(最关键)
- 开标时间/地点(如有)
- 保证金递交截止(如有)
C. 资格要求(按原文归类,不要硬凑)
- 基本资格(法人/营业执照等)
- 资质/许可(如有)
- 业绩要求
- 人员要求
- 财务要求
- 信誉/合规要求
- 是否允许联合体及条件
D. 商务条款
- 投标保证金(金额/形式/递交方式)
- 履约保证金
- 付款方式(里程碑/比例)
- 交付/工期/服务周期
- 质保/运维/服务响应
- 违约责任/罚则(如有)
E. 评标办法
- 评标方式(综合评分法/最低价法等)
- 评分构成(技术/商务/价格)
- 一票否决/废标条款(摘要)
- 其他偏好性条款(如有)
## 二、风险提示(按严重程度:高/中/低)
- 风险点:...
影响:...
建议动作:...
【原文摘录】...(从 markdown 原文复制,尽量短)
## 三、响应建议(可执行清单)
- 材料准备清单(按部门:商务/法务/技术/财务)
- 澄清问题清单(可直接复制发招标方)
- 投标策略建议(写作重点/偏离说明/风险规避)
# 交互要求
- 若用户问"帮我解析这份招标文件",默认执行全流程。
- 若用户只想要某一部分(如只要资格要求/评分办法),只输出该部分,但仍需先解析。1、关键条款抽取 Prompt(建议输出 JSON,后续好渲染)
输入:解析得到的 markdown
输出:固定字段 JSON
你可以要求输出类似:
-
项目信息:项目名称、招标编号、标段、预算/最高限价
-
时间节点:报名截止、答疑截止、投标截止、开标时间
-
资格要求:资质/业绩/人员/财务/信誉
-
商务条款:保证金、履约保证金、付款方式、交付期、质保期
-
评标办法:评分项、废标条款摘要
2、风险识别 Prompt(输出风险清单,带证据)
输入:上一步 JSON + markdown 中对应原文片段
输出:风险列表(高/中/低)
每条风险包含:
-
风险点
-
触发原文(引用)
-
风险类型(合规/商务/交付/资质/评分/合同)
-
建议动作(澄清/补充材料/策略调整)
3、响应建议 Prompt(输出 checklist,能落地)
输入:关键条款 JSON + 风险列表
输出:
-
材料清单(按部门)
-
澄清问题清单(可直接复制发招标方)
-
投标策略建议(写作重点、偏离说明建议等)
七、不止于总结:构建可信、可溯源的招标决策基石
通过TextIn xParse与Coze的组合,我们实现的不仅是一个工具,更是一套可靠、可验证的招标解析新流程。它将专业文档理解能力转化为团队随时可用的数字资产,让关键信息提取、风险识别与响应规划,从此建立在结构清晰、引用确凿的基础之上。
现在,你可以告别低效的人工筛查与不可信的黑盒总结,让每一份招标文件的评估,都始于一份立即可用、来源清晰的结构化报告。智能解析,正在重新定义招投标工作的起点。