文章目录
- [1. 引言:malloc 的黑盒与真相](#1. 引言:malloc 的黑盒与真相)
- [2. malloc 的混合分配策略:为何需要两种机制?](#2. malloc 的混合分配策略:为何需要两种机制?)
-
- [2.1 阈值的可配置性](#2.1 阈值的可配置性)
- [2.2 为何不统一使用一种机制?](#2.2 为何不统一使用一种机制?)
- [3. brk/sbrk:堆的连续扩展机制](#3. brk/sbrk:堆的连续扩展机制)
-
- [3.1 堆的起源与增长](#3.1 堆的起源与增长)
- [3.2 malloc 的堆管理](#3.2 malloc 的堆管理)
- [4. mmap:匿名映射与独立内存区域](#4. mmap:匿名映射与独立内存区域)
-
- [4.1 匿名映射的创建](#4.1 匿名映射的创建)
- [4.2 释放行为的本质差异](#4.2 释放行为的本质差异)
- [5. 进程虚拟地址空间布局](#5. 进程虚拟地址空间布局)
-
- [5.1 关键设计意图](#5.1 关键设计意图)
- [6. /proc/pid/maps:内存布局的实时快照](#6. /proc/[pid]/maps:内存布局的实时快照)
-
- [6.1 字段详解](#6.1 字段详解)
- [6.2 典型区域识别](#6.2 典型区域识别)
- [6.3 高级分析:结合 smaps 定位内存热点](#6.3 高级分析:结合 smaps 定位内存热点)
- [7. /proc/pid/mem:进程内存的原始接口](#7. /proc/[pid]/mem:进程内存的原始接口)
-
- [7.1 访问约束](#7.1 访问约束)
- [7.2 正确使用方式](#7.2 正确使用方式)
- [7.3 安全边界](#7.3 安全边界)
- [7.4 现代替代方案](#7.4 现代替代方案)
- [8. 实验验证:观察 malloc 的实际行为](#8. 实验验证:观察 malloc 的实际行为)
-
- [8.1 跟踪系统调用](#8.1 跟踪系统调用)
- [8.2 观察地址空间变化](#8.2 观察地址空间变化)
- [9. 分配器对比:ptmalloc2 之外的选择](#9. 分配器对比:ptmalloc2 之外的选择)
- [10. 内存碎片:理论与现实](#10. 内存碎片:理论与现实)
-
- [10.1 外部碎片(External Fragmentation)](#10.1 外部碎片(External Fragmentation))
- [10.2 内部碎片(Internal Fragmentation)](#10.2 内部碎片(Internal Fragmentation))
- [11. 安全视角:ASLR 与内存布局随机化](#11. 安全视角:ASLR 与内存布局随机化)
- [12. 总结:关键认知与实践建议](#12. 总结:关键认知与实践建议)
1. 引言:malloc 的黑盒与真相
malloc 作为 C 标准库中最基础的内存分配接口,每日被数以亿计的程序调用。然而其内部机制常被视为"黑盒":开发者知道它能分配内存,却未必清楚内核如何配合、内存究竟落在地址空间的何处、何时会产生碎片。本文将穿透这层黑盒,系统解析 malloc 的底层实现机制,重点阐明 brk 与 mmap 的分工策略,并结合 /proc 虚拟文件系统揭示进程内存布局的完整图景。
2. malloc 的混合分配策略:为何需要两种机制?
现代 libc(如 glibc)采用 ptmalloc2 作为默认分配器,其核心设计是 根据请求大小动态选择底层系统调用:

2.1 阈值的可配置性
该阈值并非硬编码,可通过 mallopt() 动态调整:
c
#include <malloc.h>
mallopt(M_MMAP_THRESHOLD, 256 * 1024); // 将阈值设为 256KBglibc 还会根据历史分配模式动态调整阈值:若频繁分配大块内存后立即释放,可能自动降低阈值以减少碎片。
2.2 为何不统一使用一种机制?
brk 的优势与缺陷
优势:堆连续,分配/释放开销极低(仅移动 program break 指针);适合高频小对象。
缺陷:释放中间内存会产生"孔洞",导致堆无法收缩,长期运行后虚拟内存浪费严重。
mmap 的优势与缺陷
优势:独立映射,释放即回收,无碎片累积;适合生命周期明确的大对象。
缺陷:每次分配需系统调用,建立新 VMA(Virtual Memory Area),开销较大;过多映射会增加页表管理负担。
设计哲学:小对象追求速度与复用,大对象追求隔离与回收。混合策略在性能与内存效率间取得平衡。
3. brk/sbrk:堆的连续扩展机制
3.1 堆的起源与增长
进程启动时,内核在数据段(.bss)之后预留一小段连续内存作为初始堆。brk 系统调用通过移动 program break 指针扩展堆顶:
c
// 简化版 brk 工作流程
void *current_brk = sbrk(0); // 获取当前堆顶
void *new_brk = sbrk(4096); // 向上扩展 4KB
// 内核将 [current_brk, new_brk) 映射为可读写匿名页3.2 malloc 的堆管理
ptmalloc2 在 brk 提供的连续空间上构建空闲链表(free list):
将大块堆内存切分为不同大小的"bins"(如 fastbins、smallbins)
分配时从合适 bin 中取出 chunk;释放时将 chunk 归还至 bin
仅当堆顶存在连续空闲区域且超过阈值时,才调用 brk 向下收缩堆
关键点:free() 通常不立即归还内存给内核,而是保留在分配器的空闲池中。这是用户态内存管理与内核内存管理的分界。
4. mmap:匿名映射与独立内存区域
4.1 匿名映射的创建
c
void *ptr = mmap(NULL, size,
PROT_READ | PROT_WRITE,
MAP_PRIVATE | MAP_ANONYMOUS,
-1, 0);MAP_ANONYMOUS:不关联文件,内容初始化为零
MAP_PRIVATE:写时复制(COW),修改不影响其他进程
返回的地址独立于堆,形成新的 VMA
4.2 释放行为的本质差异
c
free(ptr); // 若为 mmap 分配,内部直接调用 munmap()munmap() 会:
从进程页表中移除该 VMA 的映射
释放对应的物理页(若为私有匿名页)
地址空间立即回收,无残留
这与 brk 分配的内存形成鲜明对比:后者释放后仍占据虚拟地址空间,仅标记为空闲。
5. 进程虚拟地址空间布局
理解内存分配位置,需先掌握 Linux 进程的标准地址空间模型(以 x86_64 为例):
c
高位地址 (0x7fffffffffff)
+------------------------+
| 栈 (Stack) | ← 向下增长,主线程栈约 8MB
| [vvar] | 内核变量只读映射
| [vdso] | 虚拟动态共享对象
+------------------------+
| 内存映射区 (mmap) | ← 新映射通常从此向下分配
| • 匿名 mmap |
| • 共享库 (.so) |
| • 线程栈 |
+------------------------+
| (空洞) | 隔离堆与映射区,缓解碎片
+------------------------+
| 堆 (Heap) | ← 向上增长,由 brk 管理
+------------------------+
| BSS / Data 段 |
| 代码段 (.text) |
+------------------------+
低位地址 (0x0000000000400000)5.1 关键设计意图
堆与映射区分离:避免大对象释放后在堆中留下无法跨越的"孔洞",阻碍堆收缩。
映射区向下增长:与堆的向上增长形成"背向扩展",最大化利用中间空洞。
64 位优势:地址空间极大(48 位有效),堆与映射区可相距数 TB,几乎无冲突风险;32 位系统则需谨慎管理空洞。
6. /proc/pid/maps:内存布局的实时快照
该文件以文本形式暴露进程的完整 VMA 列表,是分析内存行为的基石。
6.1 字段详解
c
address perms offset dev inode pathname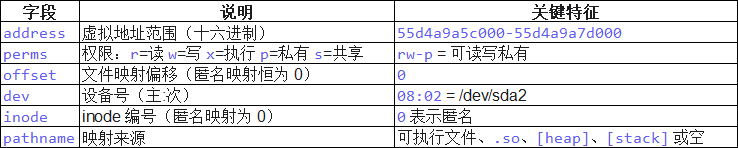
6.2 典型区域识别
c
$ cat /proc/self/maps | grep -E "\[heap\]|\[stack\]|\.so|^\S+\s+rw-p\s+00000000\s+00:00\s+0\s*$"
55d4a9a5c000-55d4a9a7d000 rw-p 00000000 00:00 0 [heap]
7f3a8c000000-7f3a8c021000 rw-p 00000000 00:00 0 ← mmap 匿名(大内存分配)
7f3a8f800000-7f3a8f9a7000 r-xp 00000000 08:02 2345678 /lib/x86_64-linux-gnu/libc.so.6
7ffcd0b5e000-7ffcd0b7f000 rw-p 00000000 00:00 0 [stack]heap:唯一标记的堆区域,由 brk 管理
无标记的 rw-p + inode=0:匿名 mmap,可能是大内存分配或线程栈
.so 路径:共享库,通常含多段(代码 r-xp、数据 rw-p)
6.3 高级分析:结合 smaps 定位内存热点
/proc/pid/smaps 在 maps 基础上增加物理内存统计:
c
awk '/^7f3a8c000000-7f3a8c021000/,/^$/' /proc/1234/smaps输出关键字段:
Size:虚拟内存大小(KB)
Rss:实际驻留物理内存
Anonymous:匿名页大小(堆/mmap)
Swap:被换出的大小
适用于定位"虚拟内存占用高但物理内存低"的稀疏分配问题。
7. /proc/pid/mem:进程内存的原始接口
该文件允许按虚拟地址直接读写目标进程的内存,是调试器与内存工具的底层基石。
7.1 访问约束
直接读写受内核严格限制:
必须可 ptrace:目标进程未设置 PR_SET_DUMPABLE=0,且系统未启用严格 Yama 策略(/proc/sys/kernel/yama/ptrace_scope)
调用者权限:需为 root、目标进程父进程且已 PTRACE_ATTACH,或具有 CAP_SYS_PTRACE
7.2 正确使用方式
c
#include <sys/ptrace.h>
#include <sys/wait.h>
#include <fcntl.h>
#include <unistd.h>
void read_process_memory(pid_t pid, unsigned long addr, void *buf, size_t len) {
// 1. 附加进程
ptrace(PTRACE_ATTACH, pid, NULL, NULL);
waitpid(pid, NULL, 0);
// 2. 打开 mem 文件
char path[64];
snprintf(path, sizeof(path), "/proc/%d/mem", pid);
int fd = open(path, O_RDONLY);
// 3. 按虚拟地址读取(必须用 pread)
pread(fd, buf, len, addr);
// 4. 清理
close(fd);
ptrace(PTRACE_DETACH, pid, NULL, NULL);
}关键细节:必须使用 pread()/pwrite() 指定偏移量(即虚拟地址),lseek()+read() 在此文件上行为未定义。
7.3 安全边界
内核在 pread 时校验:地址是否在合法 VMA 内、进程是否可访问该页
尝试写入只读页(如 .text 段)将失败,调试器需通过 ptrace(PTRACE_POKETEXT) 临时修改页权限
容器环境中,跨命名空间访问 /proc/pid/mem 通常被 cgroup/ns 机制阻止
7.4 现代替代方案
Linux 3.2+ 提供更安全的 process_vm_readv()/process_vm_writev():
c
struct iovec local = {.iov_base = buf, .iov_len = len};
struct iovec remote = {.iov_base = (void *)addr, .iov_len = len};
process_vm_readv(pid, &local, 1, &remote, 1, 0);优势:无需 ptrace 附加,语义清晰,推荐新项目优先采用。
8. 实验验证:观察 malloc 的实际行为
8.1 跟踪系统调用
c
# 小内存分配(应触发 brk)
strace -e brk,mmap,munmap ./a.out 2>&1 | grep -E "brk|mmap"
# 大内存分配(应触发 mmap)
strace -e brk,mmap,munmap ./b.out 2>&1 | grep -E "brk|mmap"测试程序 a.c:
c
#include <stdlib.h>
int main() {
void *p = malloc(1024); // < 128KB
free(p);
return 0;
}测试程序 b.c:
c
#include <stdlib.h>
int main() {
void *p = malloc(200*1024); // > 128KB
free(p);
return 0;
}8.2 观察地址空间变化
c
# 启动长期运行进程
cat > test.c <<EOF
#include <stdlib.h>
#include <unistd.h>
int main() {
void *small = malloc(1024);
void *large = malloc(200*1024);
sleep(60); // 保持进程存活
free(small); free(large);
return 0;
}
EOF
gcc test.c -o test && ./test &
PID=$!
# 等待进程启动后抓取 maps
sleep 2
grep -E "\[heap\]|rw-p.*00:00.*0$" /proc/$PID/maps预期输出:
c
55d4a9a5c000-55d4a9a7d000 rw-p 00000000 00:00 0 [heap] ← small 分配
7f3a8c000000-7f3a8c032000 rw-p 00000000 00:00 0 ← large 分配(mmap)9. 分配器对比:ptmalloc2 之外的选择

实践建议:
通用应用:默认 ptmalloc2 足够
高并发服务:考虑 jemalloc/tcmalloc(通过 LD_PRELOAD 替换)
嵌入式:musl 的轻量级优势明显
10. 内存碎片:理论与现实
10.1 外部碎片(External Fragmentation)
现象:堆中存在大量小空洞,无法满足大块连续分配请求
成因:频繁分配/释放不同大小对象,尤其 brk 管理的堆区域
缓解:
大对象用 mmap 隔离
对象池(Object Pool)复用固定大小内存
定期重启长生命周期进程
10.2 内部碎片(Internal Fragmentation)
现象:分配器为对齐将 1025 字节请求向上取整至 2048 字节
成因:内存对齐要求(如 16 字节对齐)
权衡:内部碎片换取分配速度与对齐安全,通常可接受
关键认知:碎片是内存管理的固有代价,目标是控制而非消除。合理设计数据结构(如避免频繁变长对象)比更换分配器更有效。
11. 安全视角:ASLR 与内存布局随机化
现代 Linux 启用 ASLR(Address Space Layout Randomization)后:
每次运行时,堆、栈、mmap 区的基地址随机偏移
/proc/pid/maps 内容每次不同,增加漏洞利用难度
mmap 分配的地址在 64 位系统上具有 28 位熵(约 2.6 亿种可能)
c
# 禁用 ASLR(仅用于调试)
echo 0 | sudo tee /proc/sys/kernel/randomize_va_space
# 启用(默认)
echo 2 | sudo tee /proc/sys/kernel/randomize_va_space安全提示:生产环境切勿禁用 ASLR。调试时临时关闭,结束后立即恢复。
12. 总结:关键认知与实践建议
malloc 非单一机制:小内存走 brk(堆),大内存走 mmap(独立映射),阈值可调。
释放 ≠ 归还内核:brk 分配的内存 free 后仍驻留进程地址空间;mmap 分配则立即回收。
地址空间布局有规律:堆向上、栈向下、mmap 区居中向下,三者隔离设计缓解碎片。
/proc/pid/maps 是内存地图:结合 smaps 可精准定位内存热点与泄漏。
/proc/pid/mem 需谨慎使用:必须 ptrace 附加,现代场景优先用 process_vm_readv。
碎片不可避免:通过对象池、避免频繁变长分配、定期重启控制其影响。
分配器选择需场景化:通用场景用 ptmalloc2,高并发服务考虑 jemalloc/tcmalloc。
理解这些机制,不仅有助于编写高效内存代码,更能深入掌握操作系统与用户态库的协作本质------这正是系统编程的核心魅力所在。