一、共识原理
1、文件 = 内容 + 属性
2、文件分为打开的文件和没打开的文件
3、打开的文件:是进程打开的;文件被打开,必须先加载到内存;进程:打开的文件 = 1:n;
操作系统内部一定存在大量的被打开的文件,操作系统要管理这些被打开的文件---先描述,再组织
4、没打开的文件:在磁盘上
二、C文件接口
C程序默认在启动的时候,会打开三个标准输入输出流(文件):
stdin:键盘文件
stdout:显示器文件
stderr:显示器文件
但是这不是C语言的特性,这是操作系统的特性,进程默认会打开stdin, stdout, stderr。
1、fopen:打开或创建文件
FILE *fopen(const char *path, const char *mode);参数:
path:文件路径
mode:打开模式("r"--读,"w"--写,"a"--追加等)
注意:
1)w在写入之前,会对文件进行清空处理。
2)创建的文件默认在当前路径(进程的当前路径cwd),如果通过chdir命令更改了当前进程的cwd,就可以把文件新建到其他目录。
FILE *fp = fopen("test.txt", "a");
if(fp == NULL)
{
perror("fopen failed");
}2、fclose:关闭文件流
int fclose(FILE *stream);参数:stream为fopen返回的文件流指针
fclose(fp);3、fwrite:写入数据到文件
size_t fwrite(const void *ptr, size_t size, size_t nmemb, FILE *stream);参数:
ptr:内存数据的地址
size:单个元素的字节数
nmemb:元素个数
stream:文件流指针
const char *message = "abcd";
fwrite(message, strlen(message), 1, fp);4、fread:从文件读取数据到内存
size_t fread(void *ptr, size_t size, size_t nmemb, FILE *stream);参数:
ptr:存储数据的内存缓冲区地址
size:单个元素的字节数
nmemb:元素个数
stream:文件流指针
char buf[100];
fread(buf, sizeof(char), 5, fp);5、fseek:定位文件流的读写位置
int fseek(FILE *stream, long offset, int whence);参数:
offset:偏移字节数
whence:偏移基准(SEEK_SET--文件开头,SEEK_CUR--当前位置,SEEK_END--文件末尾)
fseek(fp, 0, SEEK_SET);6、fprintf:按指定格式将数据写入文件流
int fprintf(FILE *stream, const char *format, ...);参数:
stream:目标文件流指针
format:格式化字符串(和printf完全一致)
fprintf(stdout, "%d\n", n);三、文件系统调用
文件其实是在磁盘上的,磁盘是外部设备,访问磁盘文件其实是访问硬件。
几乎所有的库只要是访问硬件设备,必定要封装系统调用。
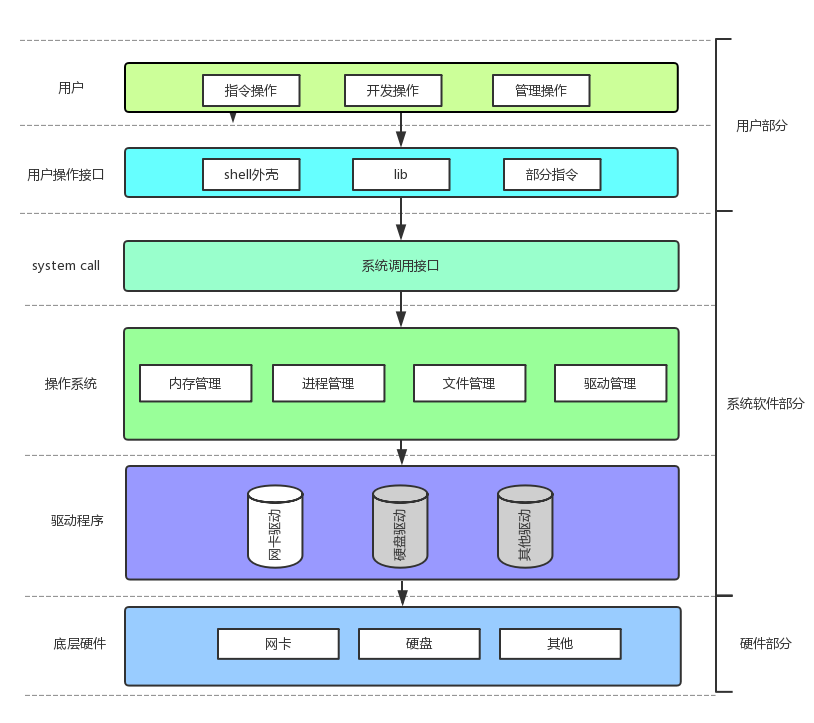
**对文件描述符的理解:**在进程中每打开一个文件,都会创建有相应的文件描述信息struct file,这个描述信息被添加在pcb的struct files_struct中,以数组的形式进行管理,随即向用户返回数组的下标作为文件描述符,用于操作文件。
默认的文件描述符:标准输入stdin-----0, 标准输出stdout-----1, 标准错误stderr-----2
1、open:打开或创建文件,返回文件描述符(本质是数组的下标)
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int open(const char *pathname, int flags);
int open(const char *pathname, int flags, mode_t mode);参数:
pathname:文件路径
flags:打开标志(O_RDONLY--只读,O_WRONLY--只写,O_RDWR--读写,O_CREAT--不存在就创建,O_TRUNC--每次打开文件要清空内容,O_APPEND--追加内容)
mode:创建文件时的权限(eg:0666)
int fd = open("log.txt", O_WRONLY|O_CREAT|O_TRUNC, 0666);
if(fd < 0)
{
printf("open file error\n");
}2、close:关闭文件描述符,释放资源
#include <unistd.h>
int close(int fd);参数:fd为open返回的文件描述符
close(fd);3、write:向文件写入数据
#include <unistd.h>
ssize_t write(int fd, const void *buf, size_t count);参数:
fd:文件描述符
buf:待写入数据的缓冲区
count:期望写入的字节数
const char *message = "xxx";
write(fd, message, strlen(message));
//C语言中字符串末尾有'\0',但是与文件无关,不用strlen(message) + 14、read:从文件读取数据,成功返回实际读取的字节数
#include <unistd.h>
ssize_t read(int fd, void *buf, size_t count);参数:
fd:文件描述符
buf:存储读取数据的缓冲区
count:期望读取的最大字节数
char buffer[1024];
ssize_t s = read(0, buffer, sizeof(buffer));
if(s < 0) return 1;
buffer[s] = '\0';
printf("echo : %s\n", buffer);5、lseek:移动文件读写指针
#include <sys/types.h>
#include <unistd.h>
off_t lseek(int fd, off_t offset, int whence);参数:
fd:文件描述符
offset:偏移量(可正可负)
whence:偏移基准(SEEK_SET--从文件开头,SEEK_CUR--从当前位置,SEEK_END--从文件末尾)
lseek(fd, 0, SEEK_SET);可以认为,f#系列的函数,都是对系统调用的封装,方便二次开发。
关于文件系统调用接口的详细内容请通过man手册查看。
四、访问文件的本质
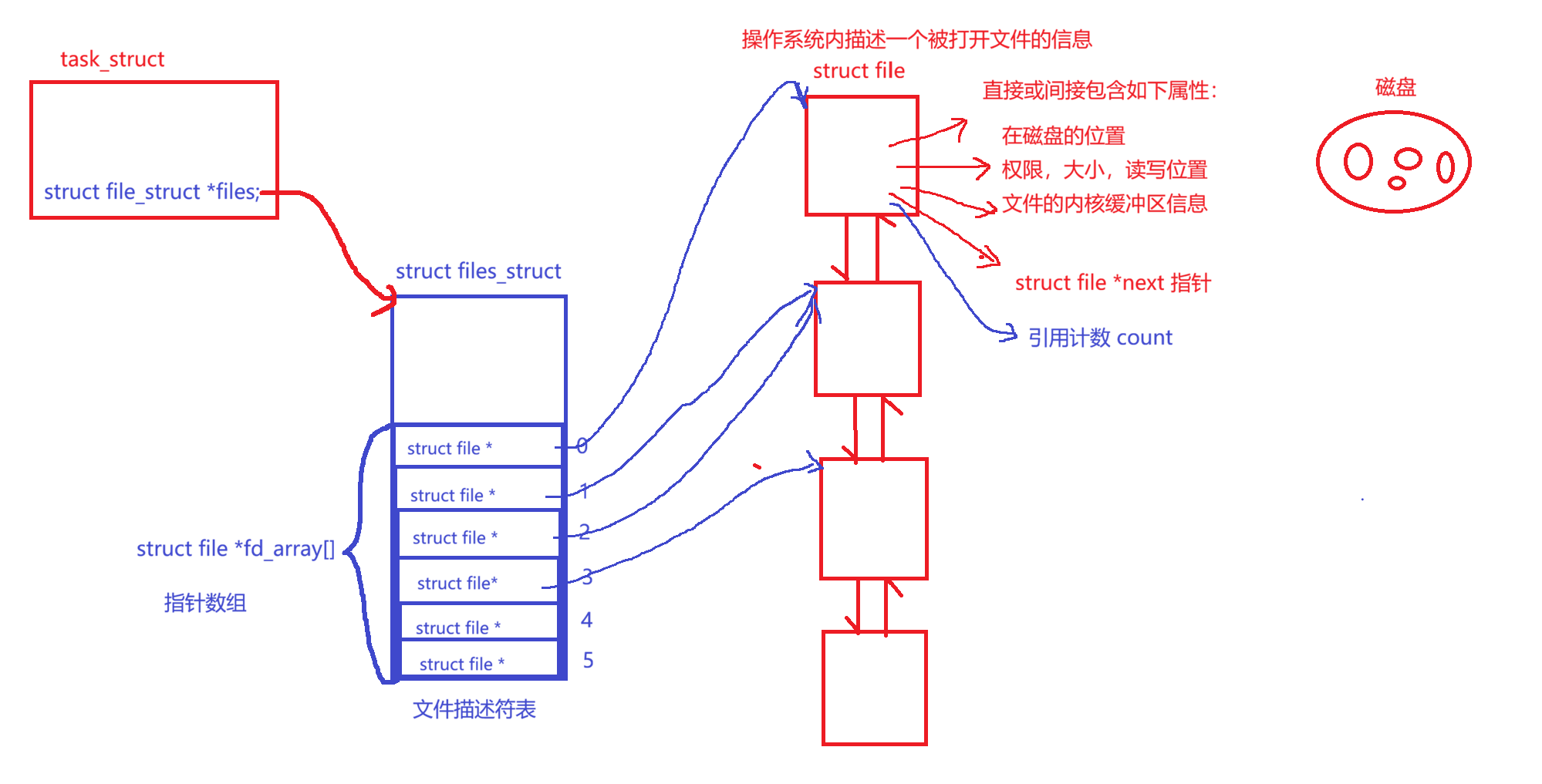
文件描述符对应的分配规则:
从0下标开始,寻找最小的没有被使用的数组位置,它的下标就是新文件的文件描述符。
五、重定向
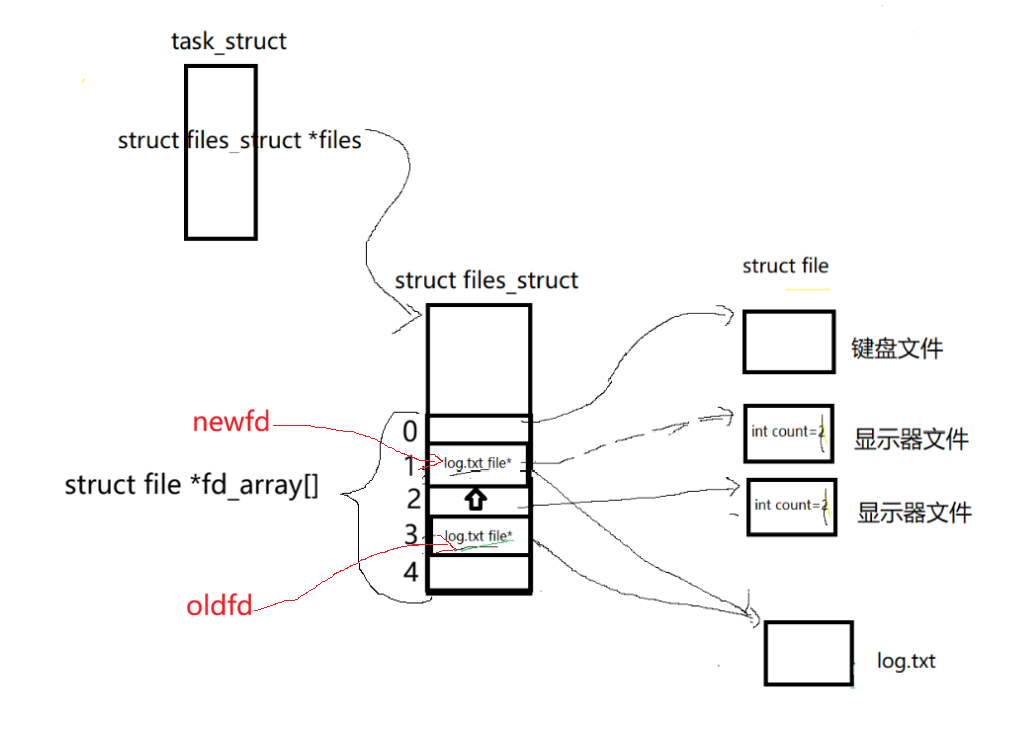
重定向的原理:
每个文件描述符都是一个内核中文件描述信息数组的下标,对应有一个文件的描述信息用于操作文件,而重定向就是在不改变所操作的文件描述符的情况下,通过改变描述符对应的文件描述信息进而实现改变所操作的文件。
#include<unistd.h>
int dup2(int oldfd, int newfd);这个系统调用接口可以让newfd重定向为oldfd的副本,让两个文件描述符指向同一个文件,若newfd已打开,会先自动关闭再重定向。
六、用户缓冲区
当我们调用C接口(printf/fprintf/fwrite...)时,C语言会给我们提供一个缓冲区(用户级缓冲区)。
用户刷新的本质:就是将数据通过文件描述符1 + write写入到内核中。
目前我们认为,只要将数据刷新到了内核,数据就可以到硬件了(不考虑系统级缓冲区)。
1、缓冲区刷新方案
1)无缓冲-----直接刷新
2)行缓冲-----不刷新,直到碰到\n,会将以往数据全部刷新出来(显示器文件采用行缓冲)
3)全缓冲-----缓冲区满了,才刷新(普通文件采用全缓冲)
注意:进程退出的时候,也会刷新。
代码示例:
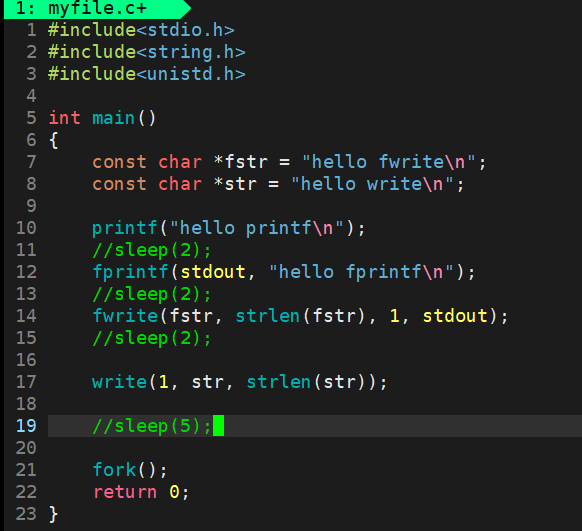
运行结果:
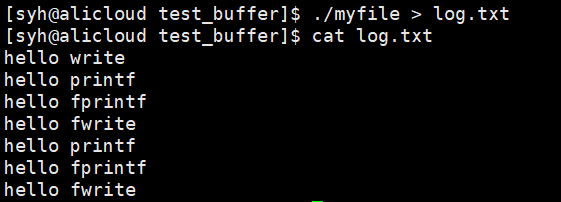
向log.txt普通文件中写入时,由行缓冲变成了全缓冲,遇到\n不刷新,系统调用接口write率先刷新,调用fork创建子进程,在进程退出之前,发生了写时拷贝,父子进程各自私有一份缓冲区中的内容,进程退出时,父子进程的缓冲区内容都会被写入到文件中。
2、为什么要有这个缓冲区?
1)解决用户的效率问题(就像我们要把快递寄给远方的人,我们不用亲自去送,而是放到楼下的菜鸟驿站,等到合适的时间,驿站会帮我们统一派送)
2)配合格式化(当我们输入123时,其实是一个一个的字符,通过%d等格式化控制转换成整数123)
3、这个缓冲区在哪里?
用户缓冲区其实在FILE结构体中定义。
4、简单模拟实现一下用户级缓冲区的刷新
1)main.c
#include "Mystdio.h"
#include <unistd.h>
#define myfile "test.txt"
int main()
{
_FILE *fp = _fopen(myfile, "a");
if(fp == NULL) return 1;
const char *msg = "hello world\n";
int cnt = 10;
while(cnt){
_fwrite(fp, msg, strlen(msg));
// fflush(fp);
sleep(1);
cnt--;
}
_fclose(fp);
return 0;
}2)Mystdio.h
#ifndef __MYSTDIO_H__
#define __MYSTDIO_H__
#include <string.h>
#define SIZE 1024
#define FLUSH_NOW 1 // 无缓冲
#define FLUSH_LINE 2 // 行缓冲
#define FLUSH_ALL 4 // 全缓冲
typedef struct IO_FILE
{
int fileno;
int flag;
//char inbuffer[SIZE];
//int in_pos;
char outbuffer[SIZE]; // 只实现一下输出缓冲区
int out_pos;
}_FILE;
_FILE * _fopen(const char*filename, const char *flag);
int _fwrite(_FILE *fp, const char *s, int len);
void _fclose(_FILE *fp);
#endif3)Mystdio.c
#include "Mystdio.h"
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <stdlib.h>
#include <unistd.h>
#include <assert.h>
#define FILE_MODE 0666
// "w", "a", "r"
_FILE * _fopen(const char*filename, const char *flag)
{
assert(filename);
assert(flag);
int f = 0;
int fd = -1;
if(strcmp(flag, "w") == 0) {
f = (O_CREAT|O_WRONLY|O_TRUNC);
fd = open(filename, f, FILE_MODE);
}
else if(strcmp(flag, "a") == 0) {
f = (O_CREAT|O_WRONLY|O_APPEND);
fd = open(filename, f, FILE_MODE);
}
else if(strcmp(flag, "r") == 0) {
f = O_RDONLY;
fd = open(filename, f);
}
else
return NULL;
if(fd == -1) return NULL;
_FILE *fp = (_FILE*)malloc(sizeof(_FILE));
if(fp == NULL) return NULL;
fp->fileno = fd;
//fp->flag = FLUSH_LINE;
fp->flag = FLUSH_ALL;
fp->out_pos = 0;
return fp;
}
int _fwrite(_FILE *fp, const char *s, int len)
{
// "abcd\n"
memcpy(&fp->outbuffer[fp->out_pos], s, len); // 没有做异常处理, 也不考虑局部问题
fp->out_pos += len;
if(fp->flag&FLUSH_NOW)
{
write(fp->fileno, fp->outbuffer, fp->out_pos);
fp->out_pos = 0;
}
else if(fp->flag&FLUSH_LINE)
{
if(fp->outbuffer[fp->out_pos-1] == '\n'){ // 不考虑其他情况
write(fp->fileno, fp->outbuffer, fp->out_pos);
fp->out_pos = 0;
}
}
else if(fp->flag & FLUSH_ALL)
{
if(fp->out_pos == SIZE){
write(fp->fileno, fp->outbuffer, fp->out_pos);
fp->out_pos = 0;
}
}
return len;
}
void _fflush(_FILE *fp)
{
if(fp->out_pos > 0){
write(fp->fileno, fp->outbuffer, fp->out_pos);
fp->out_pos = 0;
}
}
void _fclose(_FILE *fp)
{
if(fp == NULL) return;
_fflush(fp);
close(fp->fileno);
free(fp);
}FILE中的缓冲区的意义是什么?
1)减少系统调用次数,提升性能(将数据攒够一定量再进行刷新)
2)适配不同的刷新策略(无缓冲,行缓冲,全缓冲)
3)统一用户态I/O接口(无论底层是linux,还是windows, 虽然系统调用接口不一样,但用户都可以通过fwrite,fputs等标准接口进行操作)
七、inode和软硬链接
1、认识磁盘(硬件)
磁盘是以前笔记本电脑和现在台式机中唯一的一个机械设备,也是一个外设。

每片有两面,都是光滑的,磁头是一面一个,磁头和盘面不接触。
磁盘工作时,盘面会高速旋转(定位扇区),磁头会左右摆动(定位磁道和柱面)。
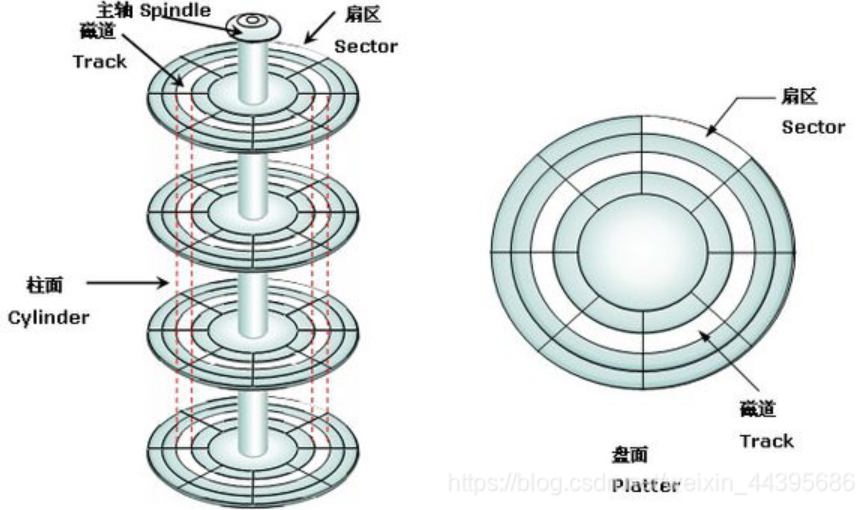
磁盘被访问的最基本单元是扇区(每个扇区的大小为512B或4KB)。
我们可以把磁盘看作由无数个扇区构成的存储介质。
要把数据存到磁盘,首要任务就是定位扇区:哪一面(定位用哪个磁头),哪个磁道,哪个扇区。
Cylinder-----磁道,Header-----磁头,Sector-----扇区 =====>CHS寻址方式(物理地址)
我们将磁盘延展开,可以认为磁盘的逻辑结构是线性的,由无数个扇区组成,任意一个扇区都有下标,即磁盘是一个基于扇区的大数组。

逻辑扇区地址(LBA地址)可以与物理地址进行转换。
eg:每个盘面有20000个扇区,每个盘面有50个磁道,每个磁道有400个扇区,扇区编号为28888。
28888 / 20000 = 1 ----- 第2面
28888 / 20000 = 8888
8888 / 400 = 22 ----- 第22个磁道
8888 % 400 = 88 ----- 第88个扇区
不仅仅CPU有寄存器,磁盘也有。
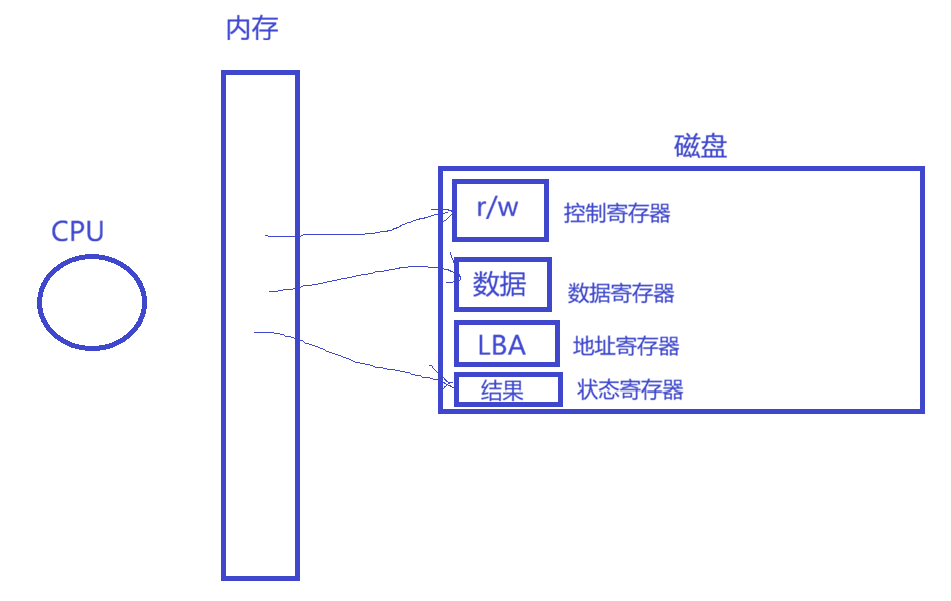
2、文件系统
Linux的文件在磁盘中存储,是将属性和内容分开存储的。
假设磁盘的存储空间大小为800GB。
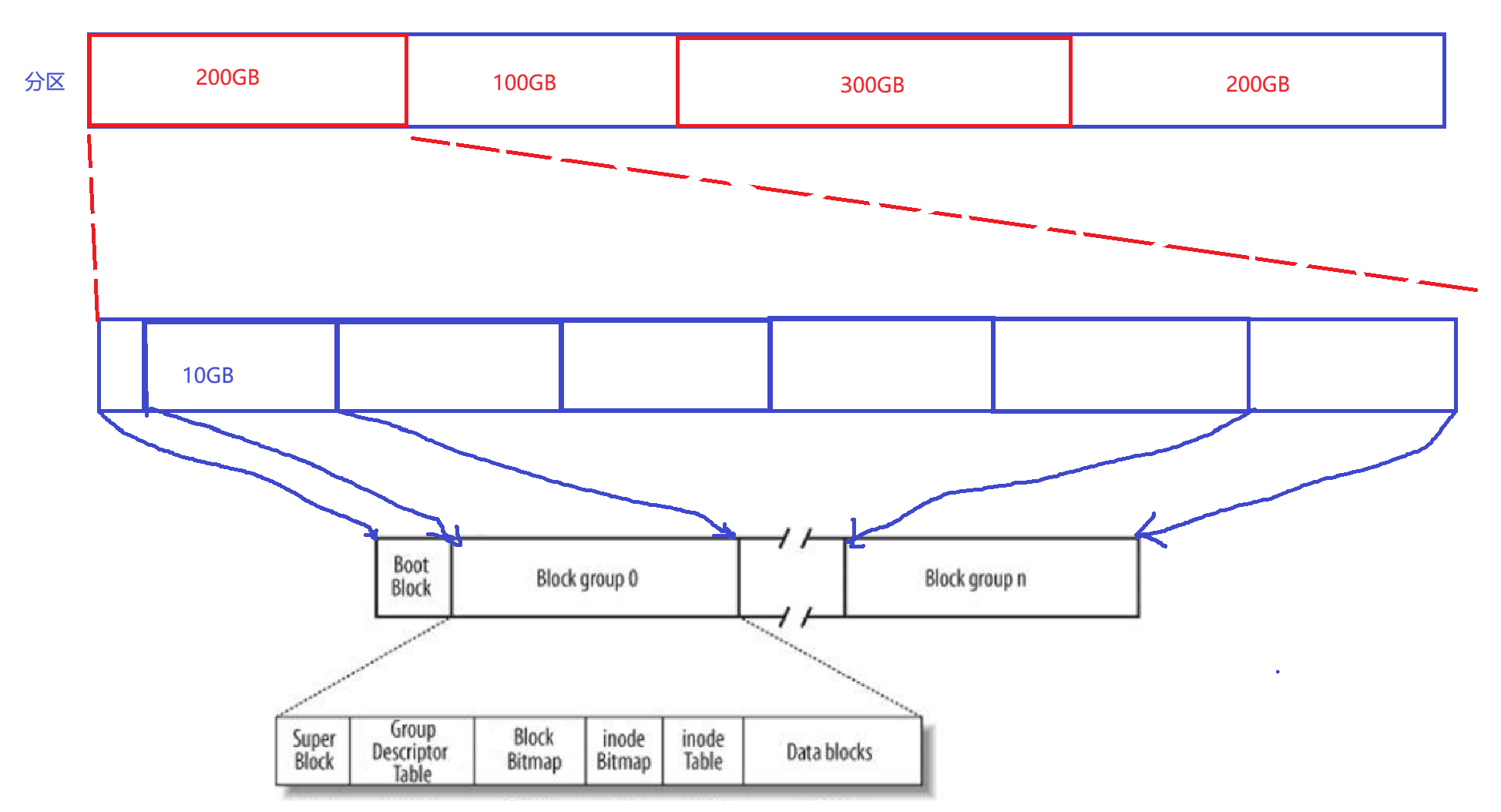
Super Block:
存储文件系统的基本信息,里面包含的是整个分区的基本使用情况(一共有多少组,每个组的大小,每个组的inode数量,每个组的block数量,每个组的起始inode,文件系统的类型等)。
注意:Super Block不会在每个组都存在,为了节省资源,只会在某几个块中存在,为了防止文件系统发生崩溃。
Group Descriptor Table:
描述每个块组的属性(该块的块位图,inode位图,inode表的位置)。
Block Bitmap:
比特位的位置和块号映射起来,比特位的内容表示该块有没有被使用。
注意:删一个文件的时候,只需将对应的比特位由1变成0即可(删除=允许被覆盖)。
inode Bitmap:
比特位的位置和inode的编号映射起来,比特位的内容表示inode是否有效。
inode Table:
单个文件的所有的属性(占128B)(inode编号,文件类型,权限,引用计数,拥有者,所属组,ACM时间,存储块的数组),一般一个文件一个inode,inode有唯一的编号(inode的设置是以分区为单位的,不能跨分区)。
注意:在Linux中,文件的属性不包含文件名,标识文件用的是inode编号。
Data blocks:
存文件内容的区域,以块的形式呈现,常见的是一个块为4KB。
格式化:
每一个分区在被使用之前,都必须提前先将部分文件系统的属性信息提前设置进对应的分区中,方便我们后续使用这个分区或分组。
如何理解目录?
目录也是文件,也有自己的inode,也有数据块,数据块里面存放的是该目录下,文件的文件名和对应文件的inode的映射关系。
3、软硬链接
如何理解软链接?
软链接是一个独立的文件,有独立的inode,也有独立的数据块,数据块里面保存的是指向的文件路径。
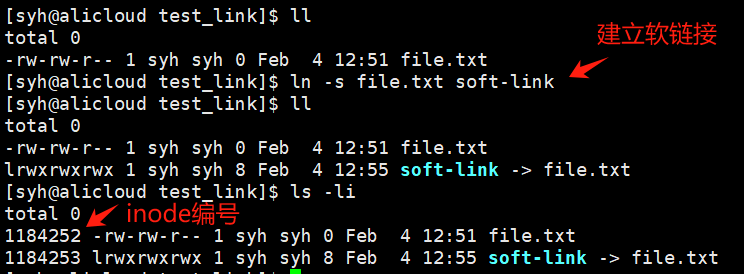
软链接的应用场景:
相当于windows快捷方式。
如何理解硬链接?
硬链接不是一个独立的文件,它没有独立的inode,所谓的建立硬链接,本质其实就是在特定目录的数据块中新增文件名和指向的文件的inode编号的映射关系。
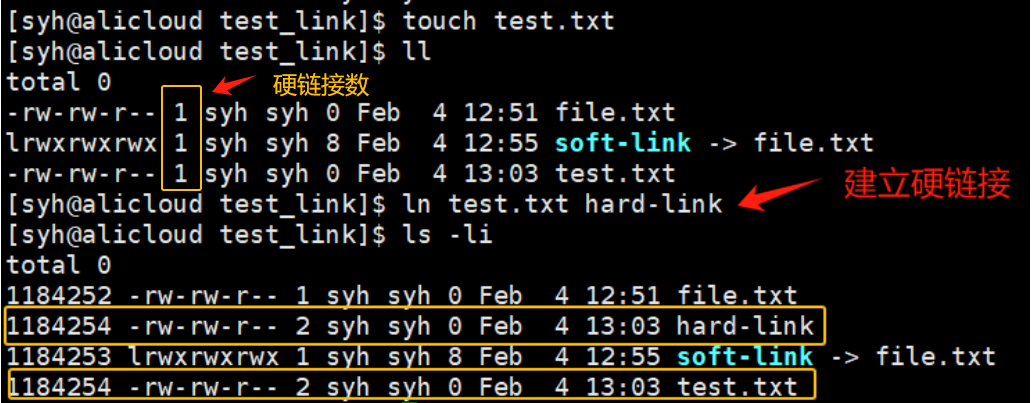
建立硬链接后,硬链接数由1变成了2,说明有两个文件同时指向一个inode。
每一个inode内部,都有一个叫做引用计数的计数器(有多少个文件名指向inode),当引用计数减减至0时,才会真正把文件删除。
eg:
文件名1:inode 1234
文件名2:inode 1234
文件名3:inode 1234
文件名4:inode 1234
Linux系统不允许我们对目录建立硬链接(会形成无限循环的闭环),但是操作系统可以建立硬链接(目录内部的 ./..就是硬链接,./..不会形成环,因为系统不会对它们进行搜索)。

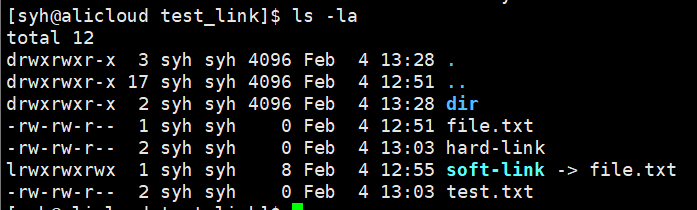
硬链接的应用场景:
通常用来进行路径定位,采用硬链接可以进行目录间切换。
八、动静态库
1、静态库
libXXX.a ----- 静态链接
要想把我们提供的方法给别人用:1)直接给源代码 2)把源代码想办法打包成库(库+.h)
把以.c为后缀的文件编译成以.o为后缀的文件,打包成库libXXX.a。
制作一个静态库:
makefile:
static-lib=libmymath.a
$(static-lib):mymath.o
ar -rc $@ $^ // 生成静态库(-r:替换文件,-c:创建库)
mymath.o:mymath.c
gcc -c $^
.PHONY:clean
clean:
rm -rf *.o *.a mylib
.PHONY:output
output:
mkdir -p mylib/include
mkdir -p mylib/lib
cp *.h mylib/include
cp *.a mylib/libmymath.h:
#pragma once
#include <stdio.h>
extern int myerrno;
int add(int x, int y);
int sub(int x, int y);
int mul(int x, int y);
int div(int x, int y);mymath.c:
#include "mymath.h"
int myerrno = 0;
int add(int x, int y)
{
return x + y;
}
int sub(int x, int y)
{
return x - y;
}
int mul(int x, int y)
{
return x * y;
}
int div(int x, int y)
{
if(y == 0){
myerrno = 1;
return -1;
}
return x / y;
}
注意:
1)除编程语言和操作系统自带的标准库以外的是第三方库,使用gcc编译链接时,必定要使用gcc -lXXX(库名,除前缀lib和后缀.a)。
2)errno的本质是一个全局变量,用于在系统调用或标准库函数执行失败时,保存具体的错误码。
3)如果系统中只提供静态链接,gcc则只能对该库进行静态链接。
4)如果系统中需要链接多个库,则gcc可以链接多个库。
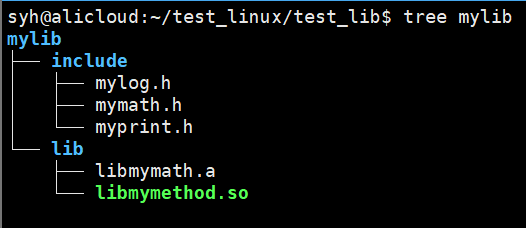
2、动态库
libYYY.so ----- 动态链接
制作一个动态库(这里同时形成静态库和动态库):
makefile:
dy-lib=libmymethod.so
static-lib=libmymath.a
.PHONY:all
all:$(dy-lib) $(static-lib)
$(static-lib):mymath.o
ar -rc $@ $^
mymath.o:mymath.c
gcc -c $^
$(dy-lib):mylog.o myprint.o
gcc -shared -o $@ $^ // 形成动态库
mylog.o:mylog.c
gcc -fPIC -c $^
myprint.o:myprint.c
gcc -fPIC -c $^
.PHONY:clean
clean:
rm -rf *.o *.a *.so mylib
.PHONY:output
output:
mkdir -p mylib/include
mkdir -p mylib/lib
cp *.h mylib/include
cp *.a mylib/lib
cp *.so mylib/libmylog.h:
#pragma once
#include <stdio.h>
void Log(const char*);mylog.c:
#include "mylog.h"
void Log(const char* info)
{
printf("warning: %s\n", info);
}myprint.h:
#pragma once
#include <stdio.h>
void Print();myprint.c:
#include "myprint.h"
void Print()
{
printf("hello new world!\n");
printf("hello new world!\n");
printf("hello new world!\n");
printf("hello new world!\n");
}main.c:
#include "mylog.h"
#include "myprint.h"
int main()
{
Print();
Log("hello log function");
return 0;
}
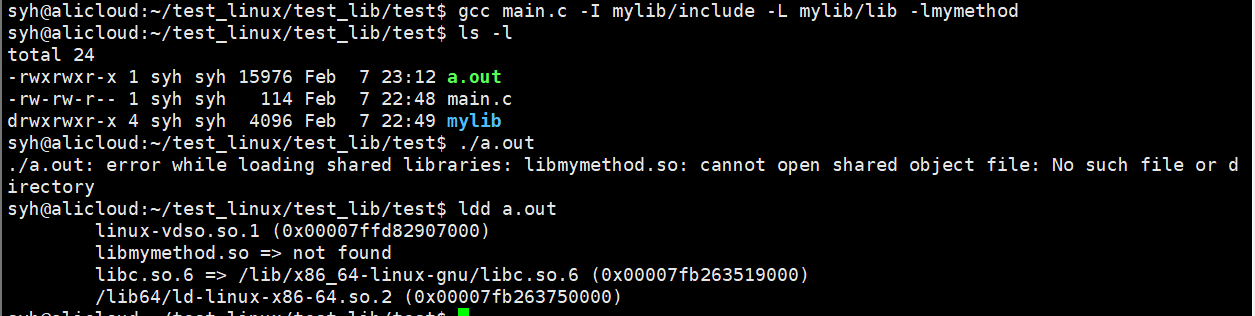
我们只是告诉编译器头文件和库的位置了,但是系统(加载器)并不知道动态库在哪里。
解决加载找不到动态库的方法:
1)拷贝到系统默认的库路径

2)在系统默认的库路径下建立软链接
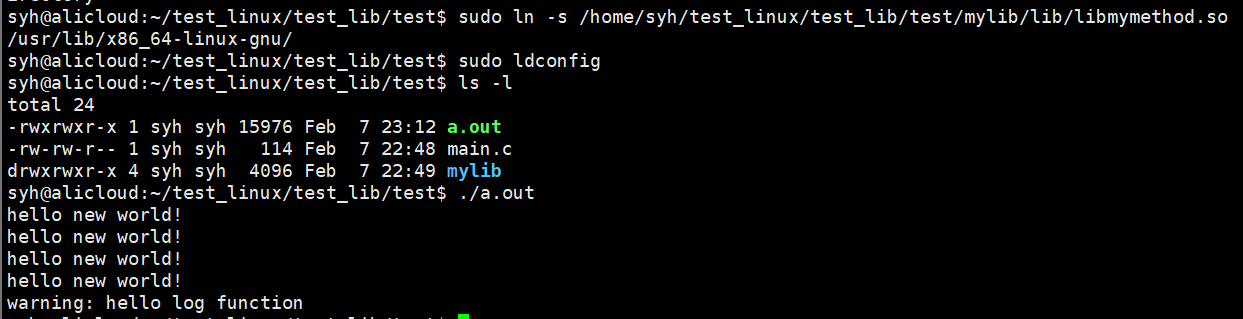

3)将自己的库所在的路径,添加到系统的环境变量LD_LIBRARY_PATH中(临时的)

4)/etc/ld.so.conf.d 建立自己的动态库路径的配置文件,然后重新ldconfig即可
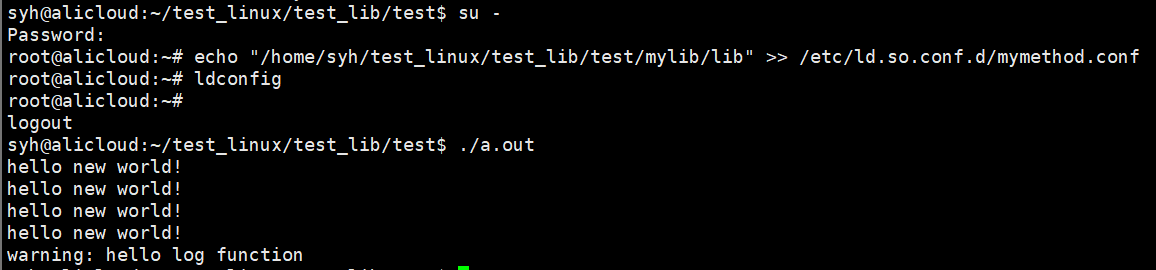
实际情况中,我们用的库都是别人成熟的库,都采用直接安装到系统的方式。
常见的动态库被所有的可执行程序使用(共享),所以动态库也叫共享库。
动态库在进程运行的时候,是要被加载的(静态库没有)。
动态库是如何被加载的?
动态库从磁盘加载到物理内存时,就会被所有需要它的进程共享,通过页表,让多个进程的虚拟地址空间都映射到同一份物理内存上,当进程要修改动态库中的内容时(eg:errno),会发生写时拷贝。系统中,所有库的加载情况,OS非常清楚。
动态库的地址:
动态库可以在虚拟内存的任意位置加载,这要求库代码必须是位置无关码(fPIC),即代码中直接使用偏移量对库中函数进行编址,而不采用绝对编址。动态库加载到物理内存时,自动填充页表中物理地址和虚拟地址的映射,通过动态库在虚拟内存的起始地址加内部函数的偏移量,就可以找到所有函数的虚拟地址。
静态库为什么不用加载产生位置无关码?
静态库在编译时就被打包进可执行程序,不具备位置无关性。