这篇写给"真要替"的人:你手上有一套 MongoDB 业务,准备收敛到金仓数据库(KingbaseES),但又不想把风险全押在一句"兼容"上。我更习惯用工程的方式把事情说透:先把适用场景划清楚,再把能在 Windows + ksql 上跑通的实操摆出来,最后再用一套验收口径把闭环做完整。

@toc
1. 所谓"MongoDB兼容",到底兼容到哪
在项目里聊"MongoDB 兼容性",我一般会先把它拆成三层,不然讨论很容易跑偏:
- 数据模型层:文档(JSON)能不能自然存、能不能自然查、能不能自然更新;
- 查询能力层:常用的过滤、投影、排序、分页、聚合,能不能用一套可维护的方式落地;
- 工程与运维层 :迁移能不能跑通、回滚怎么做、性能瓶颈怎么定位、上线窗口怎么控住。

2. 适用场景:哪些 MongoDB 业务我更愿意往金仓上收敛
如果你的 MongoDB 主要在做下面这些事,往金仓上收敛通常会更顺手:
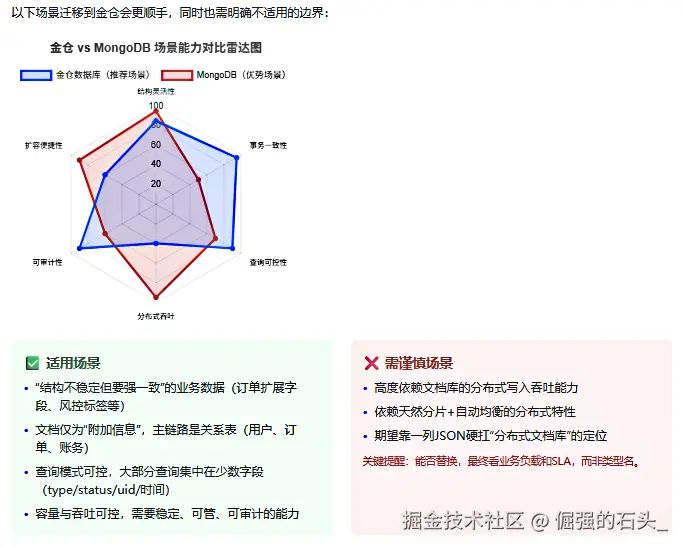
- "结构不稳定但要强一致"的业务数据:比如订单扩展字段、风控标签、业务规则快照;一边是 JSON 形态灵活,另一边又需要事务一致性、审计、对账。
- 文档只是"附加信息":主链路是关系表(用户、订单、账务),文档更多是扩展属性或请求/响应留痕。
- 查询模式可控 :大部分查询集中在几个字段上(比如
type/status/uid/时间),而不是任意字段随便查。 - 容量与吞吐在可控范围:你不依赖"自动分片+横向扩容"这种文档库的分布式特性,更多需要的是稳定、可管、可审计。
反过来,如果你特别依赖文档库的分布式写入吞吐、天然分片/自动均衡能力,那评估阶段就得把这点写进风险清单:别指望靠一列 JSON 就去硬扛"分布式文档库"的定位。到底能不能替,最后看的是业务负载和 SLA,而不是看一个类型名。
3. 兼容性拆解:从 MongoDB 文档到金仓 JSONB 的映射思路

4. Windows + ksql 实操:用一张表把"存、查、改、索引"跑通
我的环境是 Windows 且在 ksql 上操作,下面所有演示默认满足:
- Windows 已安装 KingbaseES,并创建了 Oracle 模式实例
- 你能在 PowerShell / Windows Terminal 中执行
ksql
如果你在这一步就卡住了(端口不通、服务没起来、ksql 连不上),我之前整理过一篇从安装到连通性验证的笔记,按步骤走基本不会翻车:
Windows 安装 KingbaseES V9R1C10 与 Oracle 兼容特性实战
概念解释我就不在这里铺开了,先把环境确认下来更重要:只要你能在 ksql 里把关键语法跑起来,后面这些实操才算"落地"。
下面所有命令都按 Windows 环境、ksql 客户端来写(复制 SQL 本体即可)。
4.1 连接数据库
bash
ksql -h 127.0.0.1 -p 54321 -U system -d test端口这块按你的实例来,我这边 Oracle 兼容版用的是 54322,所以截图里会看到 54322。 
4.2 建表:一列 JSONB + 一列主键 + 一列高频冗余字段
sql
DROP TABLE IF EXISTS t_user_doc;
CREATE TABLE t_user_doc(
user_id VARCHAR(64) PRIMARY KEY,
doc_type VARCHAR(32) NOT NULL,
doc JSONB NOT NULL,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP NOT NULL
);我这里把 doc_type 单独冗余出来,是因为它通常就是最高频的过滤条件之一。把它做成普通列再建索引,比每次都从 JSONB 里解析要稳得多。
4.3 插入文档:用 JSONB 直接落库
sql
INSERT INTO t_user_doc(user_id, doc_type, doc)
VALUES
('u001', 'profile', '{"name":"张三","age":28,"tags":["vip","beta"],"city":"南京"}'::jsonb),
('u002', 'profile', '{"name":"李四","age":35,"tags":["vip"],"city":"上海"}'::jsonb),
('u003', 'event', '{"event":"login","ip":"10.2.3.4","device":{"os":"windows","ver":"11"}}'::jsonb);
COMMIT;4.4 查询:按键/键值对过滤(更接近文档库的使用方式)
在金仓的 JSONB 操作符里,@> 表示"左边的 JSONB 在顶层是否包含右边的路径/值项",? 表示"某个键是否存在"。用这两类条件写查询,会更贴近文档库里那种"按字段过滤"的习惯[
sql
-- 查 profile 且 city=上海 的用户
SELECT user_id
FROM t_user_doc
WHERE doc_type = 'profile'
AND doc @> '{"city":"上海"}'::jsonb
ORDER BY user_id;
-- 查 doc 顶层是否存在 tags 键
SELECT user_id
FROM t_user_doc
WHERE doc ? 'tags'
ORDER BY user_id;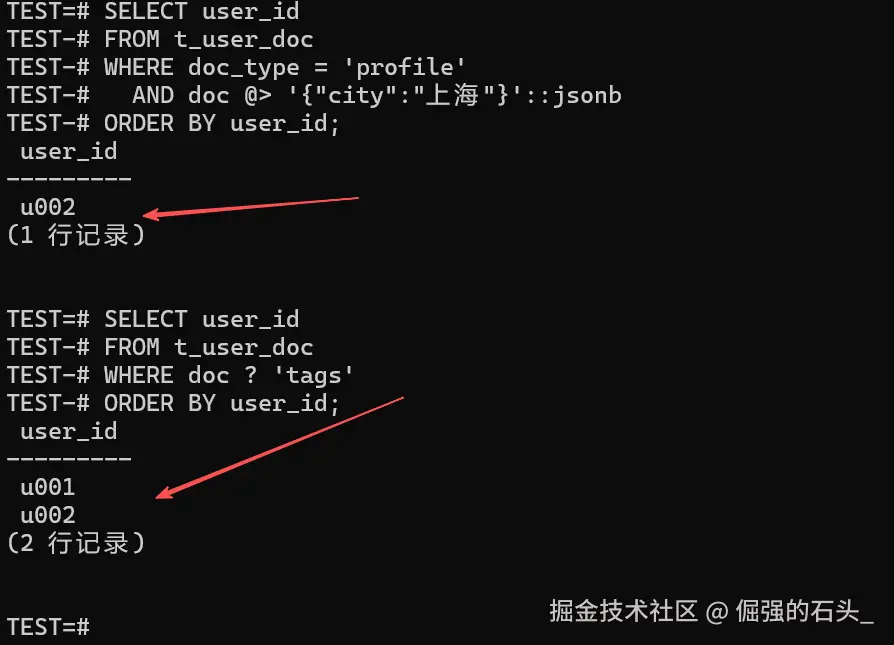
如果你要把某个字段"抽出来当文本/数字"做排序或聚合,我建议写法上把类型转换摆在明面上,别把隐式转换的坑留到线上才踩:
sql
-- 按 age 排序(示例:把 doc 里的 age 转成整数)
SELECT user_id, doc
FROM t_user_doc
WHERE doc_type = 'profile'
ORDER BY (doc->>'age')::int DESC;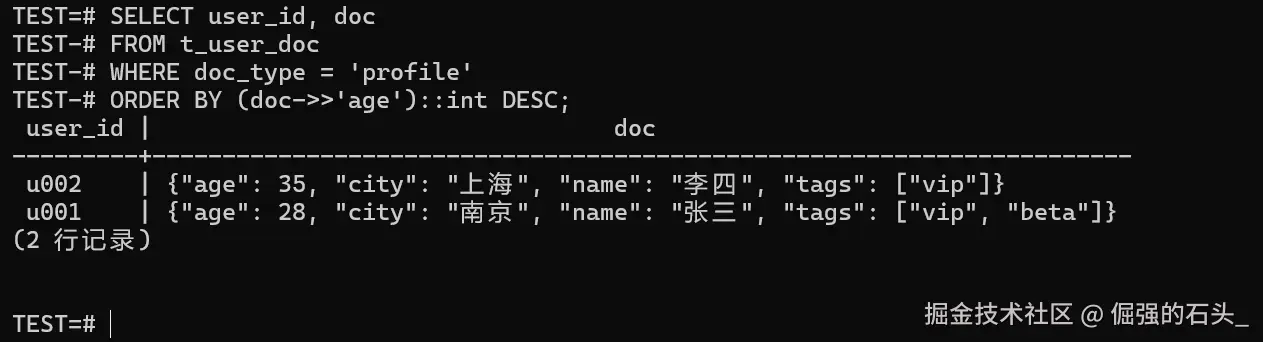
4.5 索引:给 JSONB 上 GIN,让"按键/键值对查"不再纯靠全表扫
手册里明确提到:GIN 索引可用于在大量 JSONB 文档中高效搜索键或键值对,并且也提到了不同操作符类在性能/灵活性上的取舍\^kb-json-datatypes。这里先用默认做一版最稳:
sql
CREATE INDEX idx_t_user_doc_doc_gin ON t_user_doc USING GIN (doc);索引建完以后,建议用执行计划确认一下是否真的走了索引(别凭感觉):
sql
EXPLAIN ANALYZE
SELECT user_id
FROM t_user_doc
WHERE doc @> '{"city":"上海"}'::jsonb;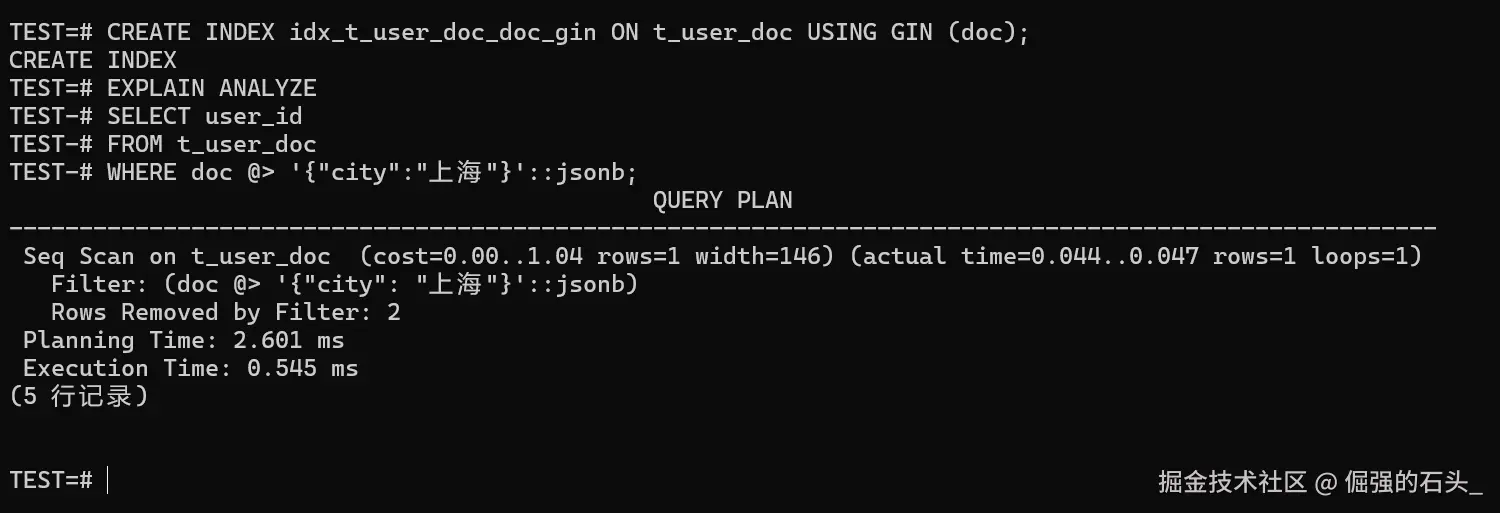
4.6 更新:只改文档里的某一块(把"局部更新"写成可维护的 SQL)
文档库里大家都喜欢"改一个字段就完事"。在金仓里也能做到类似效果:用 JSONB 的拼接/删除等操作符,把更新范围写清楚,后面维护也省心\^kb-json-operators。
sql
-- 给 u001 的文档追加一个字段(示例:last_login)
UPDATE t_user_doc
SET doc = doc || '{"last_login":"2026-02-04 10:00:00"}'::jsonb,
updated_at = CURRENT_TIMESTAMP
WHERE user_id = 'u001';
COMMIT;
5. 迁移步骤:从 MongoDB 导出到金仓落库(可回放、可重跑)
迁移这块我更推荐拆成"可重复执行"的三段:导出、落地、验证。别一次性脚本跑到底,出了问题你会发现最难受的不是修,而是没法回放、没法重跑。
5.1 导出:建议用 JSON Lines(每行一个文档),方便分片与回放
导出方式你们团队怎么习惯都行,我只盯两点:
- 一行一个文档,方便按文件/按批次回放
- 保留原始
_id,迁移后方便做抽样对照
5.2 落库:先落 staging(文本),再显式 cast 成 JSONB
先建两张表:一张 staging 用来接文件,一张目标表用来承载 JSONB:
sql
DROP TABLE IF EXISTS stg_mongo_doc;
CREATE TABLE stg_mongo_doc(
user_id VARCHAR(64),
doc_type VARCHAR(32),
doc_raw TEXT
);用 ksql 的 \copy 把文件导入 staging(示例:tab 分隔,Windows 路径记得用双反斜杠或直接用单引号包裹):
sql
\copy stg_mongo_doc(user_id, doc_type, doc_raw) FROM 'D:\\mig\\user_doc.tsv' WITH (FORMAT csv, DELIMITER E'\t', HEADER true)再把 staging 的 doc_raw 显式转成 JSONB 写入目标表:
sql
INSERT INTO t_user_doc(user_id, doc_type, doc)
SELECT user_id, doc_type, doc_raw::jsonb
FROM stg_mongo_doc;
COMMIT;这种"两段式"落地的好处是:一旦遇到脏数据(JSON 语法不合法),你能很快定位到具体哪一行、哪个文件、哪个批次;而不是整套迁移脚本跑到一半炸掉,剩下的只能靠猜。
6. 应用案例:我见过最"值回票价"的三类替换
6.1 订单扩展字段:交易表稳住,文档当扩展
做电商/交易系统时,订单核心字段(金额、状态、时间)天然适合关系型;但扩展字段(渠道参数、风控标签、营销命中规则)经常变。
做法就是:订单主表走关系字段,扩展字段用 JSONB 挂在同一个库里,避免跨库一致性问题。
6.2 用户画像/配置中心:结构常变但查询很固定
画像的字段多、变更频繁,但业务查询往往只盯几个条件:tag/city/level/更新时间。
这种"字段多但用得少"的模型,用 JSONB + 冗余列 + 索引 很容易跑得又稳又省事。
6.3 审计留痕:可追溯比"写得快"更重要
很多系统要保留请求/响应、变更前后快照。你不一定需要在文档库里做复杂查询,更多是"存得下、查得到、可审计"。
把审计数据落在同一个数据库里,反而更好管控权限、备份与验收口径。
7. 兼容性坑点清单:不提前说清楚,后面一定会还债
文档库中,"没有这个字段"和"字段存在但值为 null"常常被当作同一件事对待,但在转为 SQL 查询的时候,务必在条件里予以区分。
数值精度:JSONB 对数字类型的范围和精度存在限制,手册清楚表明,超出数据库 numeric 范围的数字将会被拒收,JSON 文本类型则不然,迁移之前需专门考量大数/高精度字段。
索引策略:并非要对每个字段均实施索引设置,首先要分析查询模式,然后决定多余列及JSONB索引的设置情况。
不要指望仅靠 JSON 来完成全部解析工作,在线上环境当中,最常遇到的问题就是"把所有的过滤条件都记录在 JSONB 中",这样最终只能不断增加机器数量,对于那些高频出现的字段来说,应当执行冗余设计。
结语:替不替,先用一套可跑通的闭环说话
我不太相信一句"兼容"能自动解决项目问题。我更相信两件事:
-
你能在本地,把"建表、写入、查询、索引、更新、导入、验证"完整跑一遍;
-
你能把"哪些场景适合替、哪些场景不适合替"写进验收口径里,避免上线后用业务来做实验。
把这两件事做好,MongoDB的替换就不是凭空想象,而是变成一项可以执行,检查,还能回滚的工程项目交付。