专题介绍
当我们对 AI4SQL/AI4DB/DB4AI 类产品进行研究时,我们发现 SQL 领域应用能力的提升很大程度上依赖于高质量的数据集。
还需要在此基础上进行数据合成,生成针对特定问题的训练集和评估集。为了帮助更多开发者快速获取资源,我们将近年来公开的 Text2SQL/NL2SQL 数据集进行了整理清单,持续分享给大家!
本期为系列文章的第六期,将介绍 大模型在地理空间查询 SQL 生成 和 提高 NL2SQL 精准度 方面的两款数据集:GeoSQL-Eval 与 DeKeyNLU。
GeoSQL-Eval / GeoSQL-Bench
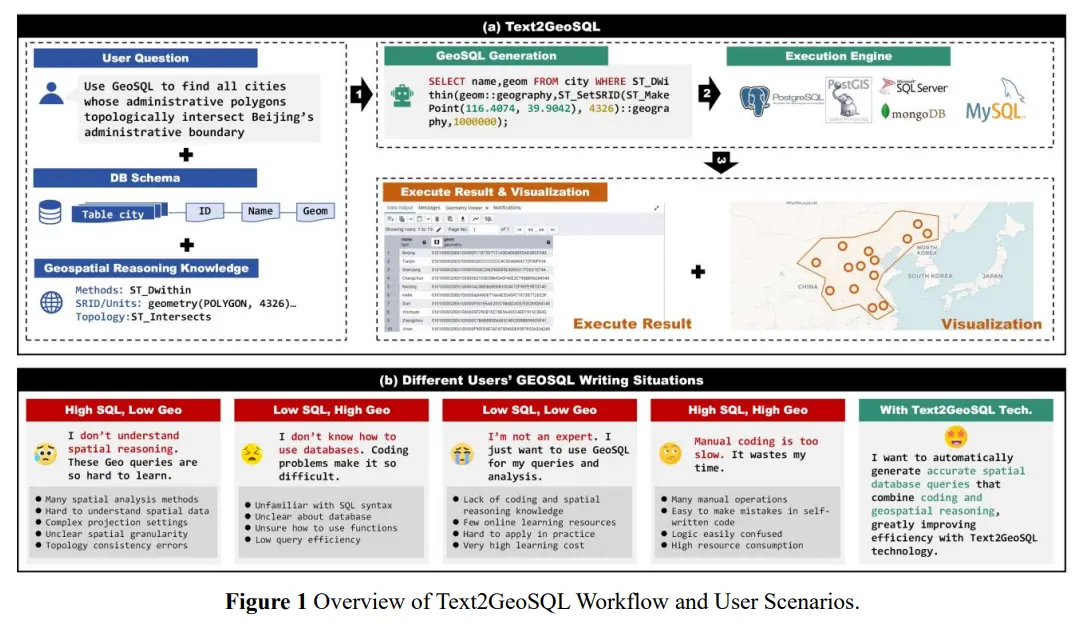
GeoSQL-Eval 是首个面向 PostGIS 环境的端到端自动化评估框架,旨在衡量大型语言模型在 地理空间 数据库查询生成(GeoSQL)方面的性能。
该研究还包括发布 GeoSQL-Bench 基准测试数据集,其中包含 14,178 个实例、340 个 PostGIS 函数和 82 个专题数据库。
论文意图
本文主要针对现有大型语言模型在生成 PostGIS 空间查询(GeoSQL)方面的性能评估难题,探讨如何系统地衡量这些模型的性能,因为目前 缺乏专门的评估基准和框架。传统的 NL2SQL 基准测试无法涵盖空间数据类型、函数和坐标系等复杂元素,导致在实际应用场景中出现函数错觉和参数误用等错误。
为了解决这一问题,论文提出了:
- GeoSQL-Bench 基准测试
- GeoSQL-Eval 评估框架
这些框架旨在为 NL2GeoSQL 任务建立一个标准化、多层次且可执行的评估系统,支持模型能力诊断和优化,并降低不同领域用户使用空间数据库的门槛。
数据集分析
GeoSQL-Bench 数据集 采用多源结构化方法构建,涵盖三种类型的任务:
- 多项选择题和判断题(2380 道),基于 PostGIS 3.5 官方手册,测试函数功能、参数顺序、返回类型以及是否符合规范;
- 语法级 SQL 生成题(3744 道),源自手册示例,包含显式提示和欠规范提示,验证模型生成可执行查询的能力;
- 表结构检索题(2155 道),基于使用联合国全球地理信息管理 (UN GGIM) 主题和 ISO 19115 分类构建的包含 82 个真实场景的空间数据库,要求模型使用表结构生成复杂查询。
所有任务均在 GPT-4o 的辅助下生成,并经过领域专家的三重审核,以确保准确性、多样性和真实性。
小结
本研究使用 GeoSQL-Eval 框架 系统地评估了六大类共 24 个主流模型。
实验表明,推理增强型模型(例如 GPT-5 和 o4-mini)在复杂的空间查询和多轮查询生成方面表现出色,尤其是在几何任务中展现出显著的准确率优势。通用非推理模型(例如 Claude3.7-Sonnet)在执行效率和语法正确性方面表现更佳。然而,函数调用和参数匹配错误仍然是核心瓶颈,约占 70%,而表结构检索任务由于多表连接逻辑的复杂性而面临最大挑战。
这项工作建立了首个针对 NL2GeoSQL 任务的标准化评估系统,为自然语言与空间数据库的交互提供了关键的基准和优化方向。
DeKeyNLU
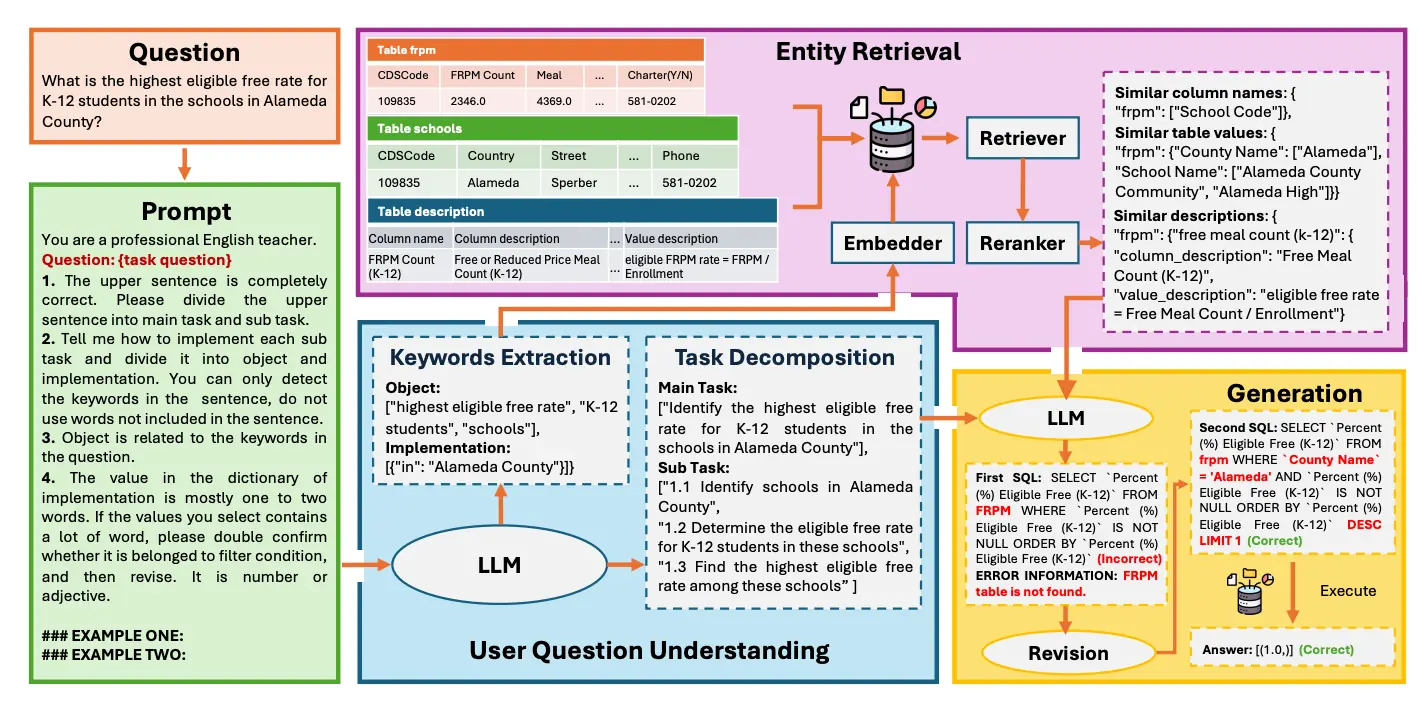
DeKeyNLU 通过三层人工交叉验证,实现了任务分解和关键词提取的联合细粒度标注。在此基础上,DeKeySQL 框架创新性地将一个专门的理解模块深度集成到 RAG(结果生成)过程中,建立了一种 "优先考虑精确语义解析 " 的新范式,显著提高了复杂查询 SQL 生成的准确性和领域适应性。
论文意图
本文旨在解决当前 RAG(检索增强生成)和 CoT(思维链)技术在 NL2SQL(自然语言 SQL 生成)任务中遇到的主要瓶颈:
通用大模型在任务分解和关键词提取方面的准确性不足。
现有的数据集在任务分解方面往往过于碎片化,且缺乏特定领域的关键词标注。为了解决这些问题,作者提出了 DeKeyNLU 数据集 和 DeKeySQL 流程(包含三个模块:用户问题理解、实体检索和生成)。通过对模型进行微调以优化问题理解阶段,最终生成的 SQL 语句的准确性得到了提升。
数据集分析
DeKeyNLU 数据集 包含 1500 个高质量标注的问答对,数据来源于 BIRD 基准数据集,涵盖金融、教育等多个领域的真实数据库场景,数据集按 7:2:1 的比例划分为训练集、验证集和测试集。
数据合成采用 "LLM 预标注 + 人工润色" 的混合工作流程:
- 第一步:使用 GPT-4o 自动生成每个问题的初步任务分解(主任务/子任务)和关键词提取(对象/实现);
- 第二步:三位专家标注员进行三轮交叉验证和修订确保标注质量。
小结
论文通过引入 DeKeyNLU 数据集 和 DeKeySQL 框架 ,证明了 针对性的任务分解和关键词提取训练能够有效提升 NL2SQL 的性能。
实验结果表明,利用 DeKeyNLU 对 "用户问题理解" 模块进行微调后,模型在 BIRD 开发集上的准确率从 62.31% 提升至 69.10%,在 Spider 开发集上的准确率从 84.2% 提升至 88.7%。
在 NL2SQL 流程中,实体检索被认为是影响整体准确率的最关键环节,其次是用户问题理解和修正机制。这些发现凸显了以数据集为中心的方法和精心设计的流程对于提升 NL2SQL 系统能力的重要价值,并为用户实现直观、准确的数据交互铺平了道路。