大模型桌游体验官来了!不仅能快速给出评价与建议,还能模拟不同类型玩家的体验差异。
近期,来自盛大东京研究院、上海创智学院、南开大学、上海人工智能实验室的研究团队联合提出了 MeepleLM,这是首个能模拟真实玩家视角,并基于动态游戏体验给出建设性批评的虚拟试玩模型。
为了减轻 AI 评价的 "悬浮感",研究团队构建了包含 1,727 本结构化桌游规则手册与 15 万条玩家真实评论的专属数据集,建立了从"客观规则" 到"主观体验"的映射关系。
在此基础上,团队引入经典的 MDA_(机制 - 动态 - 美学)_游戏设计理论构建推理核心,使模型能够跨越静态文字、推演游戏运行时的动态交互,并进一步从评价数据中提炼出五种典型玩家画像,让 AI 内化特定偏好以模拟 "千人千面" 的真实感受。
实验表明,MeepleLM 在还原玩家口碑与评分分布的精准度上,显著优于 GPT-5.1 和 Gemini3-Pro 等通用模型。
桌游设计的 "盲盒" 困境
桌游产业正在经历快速增长,但其设计过程仍面临巨大挑战。与电子游戏不同,桌游的体验高度依赖于玩家之间的社交互动和规则的涌现效应*(EmergentGameplay)*。
传统的设计流程极其依赖人工试玩_(Playtesting),这不仅耗时耗力,而且很难覆盖所有类型的玩家偏好。现有的通用大模型(LLM)_虽然能理解文本,但往往缺乏对 "游戏机制如何转化为情感体验" 的深度理解,生成的建议通常是模棱两可的"场面话",或者仅仅是复述规则,无法提供基于不同玩家视角的深刻洞察。
为了打破这一僵局,研究团队提出了 MeepleLM,一个不仅能读懂规则,还能 "模拟人心" 的虚拟试玩者。
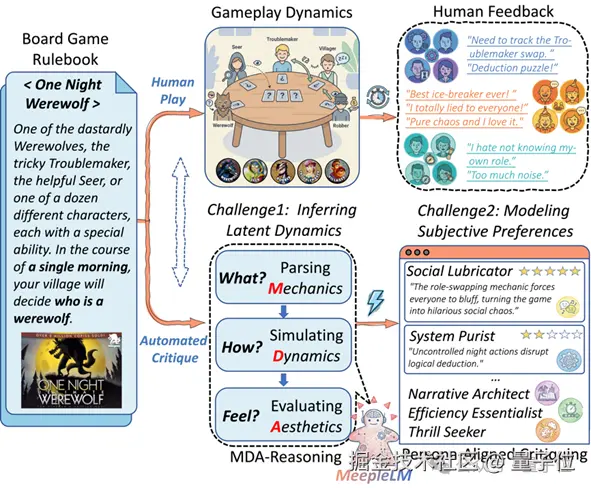
△ 图 1:MeepleLM 概览。从静态规则书出发,通过 MDA 推理,模拟不同玩家画像的动态游戏体验并生成反馈。
教 AI 像设计师一样思考
MeepleLM 的核心突破在于它并未将评价视为简单的文本生成任务,而是构建了一条从客观规则到主观体验的认知链路。
1. 高质量的专业数据集
团队首先通过分层采样策略选取了 1,727 款覆盖不同复杂度与年份的代表性游戏,将非结构化的 PDF 规则书转化为结构化的文档。构建了一个包含 1,727 本结构化规则书和 15 万条高质量评论的数据集。
同时,针对 180 万条海量评论,团队设计了一套包含硬过滤、MDA 评分与语义维度识别的自动化处理流程,最终筛选出约 8% 能够深度关联 "游戏机制" 与"动态体验"的高质量语料,确保模型学到的是真正的 "体验洞察"。
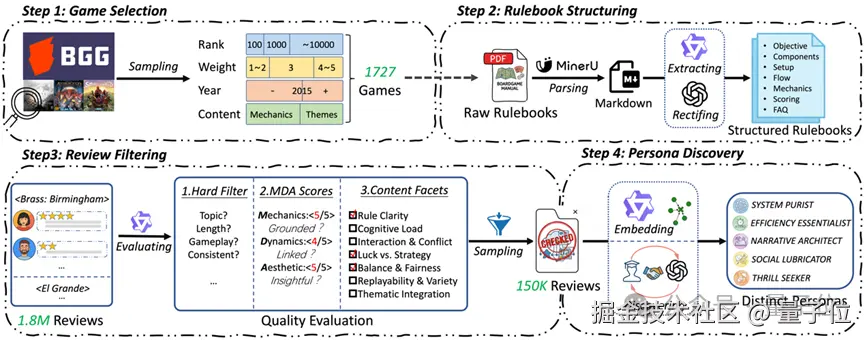
△ 图 2:数据构建流程。涵盖游戏筛选、规则书结构化、评论过滤及用户画像挖掘。
2. MDA 认知链(Chain-of-Thought)
为了让模型理解 "好玩" 的成因,MeepleLM 引入了游戏设计经典的 MDA 框架_(Mechanics-Dynamics-Aesthetics)_作为思维链:
Mechanics *(机制):游戏里有什么规则?(TheWhat)*
Dynamics *(动态):规则运行时发生了什么交互?(TheHow)*
Aesthetics *(美学):这种交互带给玩家什么情感体验?(TheFeel)*
通过这种显式的推理路径,模型不再是瞎猜,而是逻辑严密地推导出体验结果。
3. 五大玩家画像(Personas)
"彼之蜜糖,吾之砒霜"。不同玩家对同一机制的反应截然不同。研究团队通过聚类分析,提炼出了五种典型的数据驱动型玩家画像:
**The System Purist:**追求极致的平衡与逻辑,痛恨随机性。
**The Efficiency Essentialist:**追求流畅的节奏,厌恶繁琐的操作。
**The Narrative Architect:**沉浸故事与代入感,机制服务于主题。
**The Social Lubricator:**玩游戏是为了社交,喜欢嘴炮和互动。
**The Thrill Seeker:**追求高风险高回报的快感,享受骰子。
MeepleLM 能够 "角色扮演" 这些特定画像,从而给出带有特定偏好但多样的反馈。

△ 图 3:不同玩家画像的偏好分析。
更懂玩家的虚拟评测员
为了验证效果,研究团队在 207 款游戏_(包含 2024-2025 年发布的新作)_上进行了广泛测试。
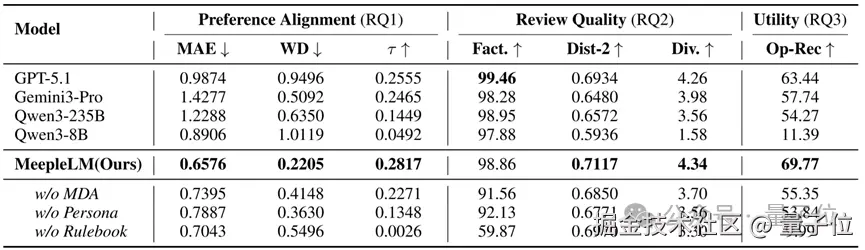
△ 图 4:整体表现。MeepleLM 在社区对齐度、生成质量和实用价值方面均展现出卓越的性能
1. 宏观评分对齐:
通用大模型_(如 GPT-5.1)_往往像一个圆滑的 "老好人" ,倾向于打出 7~10 分的安全分。而 MeepleLM 克服了这种 "正向偏差",这意味着它不仅能识别优点,更能敏锐捕捉到那些导致玩家"退坑" 的致命缺陷,精准还原出真实社区中口碑两极分化的评价形态。
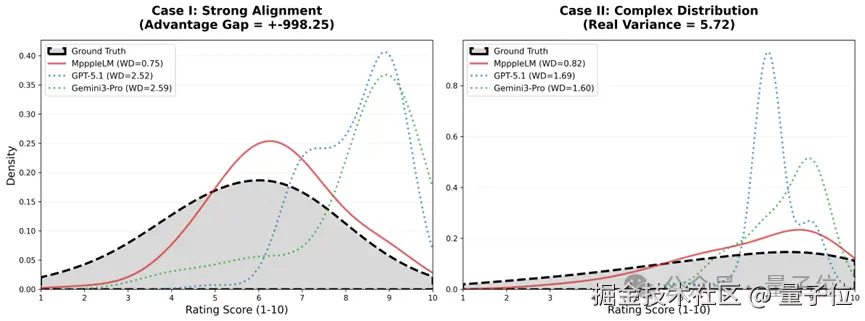
△ 图 5:评分密度分布示例。MeepleLM 展现出卓越的评分分布保真度。
2. 微观评价质量:
在评论内容的生成上,MeepleLM 兼顾了事实准确性_(Factuality)和观点多样性 (Diversity)。如图 6 所示的关于《一夜终极狼人》的评价,Qwen3-8B 采用一种通用的夸张煽情语气 ("悲情剧场"),GPT-5.1 听起来像一位冷漠的记者("社交万能润滑剂")_,但 MeepleLM 却能真实捕捉到每个角色的独特声音。
模型能在社交语境中自如切换到社区俚语_(例如 "阿尔法玩家"),在面对纯粹主义者时又能转为技术评论(例如 "变体规则")_,这证明它并非只是在检索知识,而是真正在模拟玩家的视角。
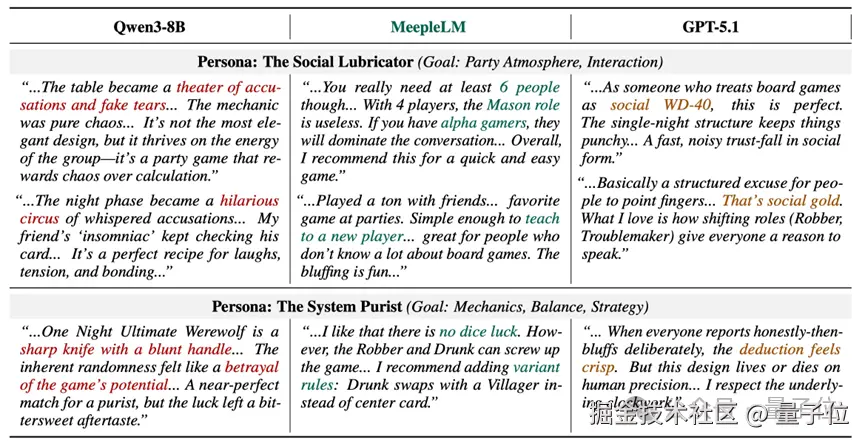
△ 图 6:案例研究。MeepleLM 生成的评论基于事实,且与特定角色的情感倾向相符。通过捕捉技术细节和社区特定俚语,模型展现出了语义的丰富性和观点的多样性。
3. 实用价值:
从历史评论提取真实观点,再与模型生成的模拟评论进行语义匹配,结果显示 MeepleLM 的 Op-Rec 最高,证明其在预测市场反馈和呈现多样玩家意见方面具有实用价值。
在包含 10 位不同类型玩家的 A/B 盲测中,MeepleLM 在真实性_(Authenticity)和决策辅助(DecisionConfidence)_等维度上均大幅领先 GPT-5.1。70% 以上的用户倾向于使用 MeepleLM 作为购买决策的参考,用户称其 "不太像营销话术",并且在识别潜在设计缺陷方面更有效。
交互系统评估新范式
通过连接静态规则与动态体验,MeepleLM 为通用交互系统的自动化虚拟测试建立了一种新范式:
既能基于预期的市场反馈加速设计迭代,也能帮助玩家进行个性化选择。这为 "体验感知型" 的人机协作铺平了道路,使模型从单纯的功能工具逐渐演变为能够体察主观受众感受的共情型伙伴。
论文标题:
MeepleLM:A Virtual Playtester Simulating Diverse Subjective Experiences
论文链接:
arxiv.org/abs/2601.07...
项目链接:
github.com/leroy9472/M...
第一作者:
Zizhen Li(Shanda AI Research Tokyo / 南开大学)
通讯作者:
Kaipeng Zhang(Shanda AI Research Tokyo)
欢迎在评论区留下你的想法!
--- 完 ---