
语音克隆技术虽令人惊叹,但以往模型往往对硬件要求苛刻------动辄需要4GB以上显存,生成速度缓慢,且输出音频常被限制在24kHz,细节丢失严重。如今,一款名为LuxTTS的开源模型彻底打破了这一局面。
LuxTTS基于ZipVoice 架构设计,是一个专为高品质语音克隆与真实感生成 打造的轻量级文本到语音(TTS)模型。它的核心亮点令人难以置信:推理速度可达实时速度的150倍 (生成150秒音频仅需1秒)、显存占用不超过1GB (普通低端显卡甚至核显均可运行)、直接输出48kHz采样率 的高清语音,并且支持零样本语音克隆------仅需几秒钟的参考音频即可完美复刻目标人声。实测效果相当出色。
▲ 语音克隆视频软件功能演示
【⚠️ 重要伦理与合规声明】
语音克隆技术具有双重用途潜力。本工具介绍仅限于个人学习、技术研究、合法内容创作(如有声书自制、虚拟偶像辅助) 等场景。
**严禁将本工具用于任何未经同意的声音模仿、电信诈骗、虚假信息传播、侵犯他人肖像权/名誉权等非法及不道德行为。**使用者应对其生成内容的合法性、正当性承担全部法律责任。请务必遵守所在国家/地区的法律法规及平台规则。
LuxTTS核心优势与技术突破
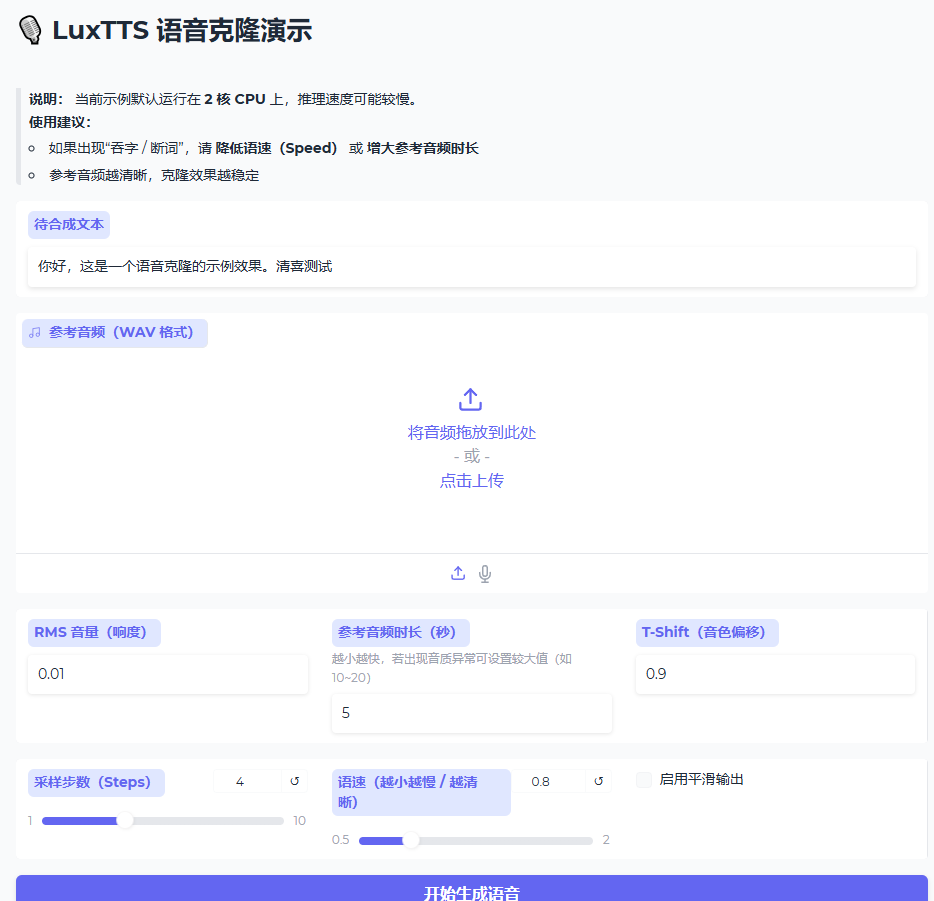
相较于现有主流语音克隆模型,LuxTTS在效率、音质与资源消耗上实现了跨越式提升。
1. 极速推理,硬件门槛极低
- 150倍实时速度: 在单个消费级GPU上,生成150秒音频仅需1秒。即使在无独立显卡的CPU上,生成速度也快于实时播放速度。
- **显存占用<1GB:**这意味着它可以在几乎所有支持CUDA的GPU上运行(包括GTX 1050 Ti、MX系列等低显存显卡),甚至部分集成显卡也可通过优化尝试运行。
2. 48kHz高清音频,远超主流标准
绝大多数TTS模型受限于24kHz采样率,高频信息丢失严重,听感"发闷"。LuxTTS直接输出48kHz采样率的音频,保留更多声音细节与泛音,接近CD级音质,尤其适合对音质要求较高的专业应用(如音乐制作、播客、影视配音)。
3. 零样本语音克隆,效果媲美大模型
- **短音频参考:**仅需提供目标说话人3~10秒的干净语音样本,无需额外训练或微调。
- **SOTA级克隆效果:**尽管模型体积比主流模型小近10倍,但语音克隆的相似度、自然度仍达到当前一流水平。
4. 本地离线,完全免费开源
LuxTTS采用MIT等宽松开源协议,用户可免费下载、使用,并完全离线运行,无需担心数据隐私泄露或API调用费用。
技术规格与运行环境
- **模型架构:**基于ZipVoice的轻量化设计
- **输入:**文本 + 参考音频(.wav, 3-10秒)
- **输出:**48kHz, 16bit, 单声道/立体声 WAV
- 推理速度:≥150×实时(GPU),>1×实时(CPU)
- **显存要求:**最低约800MB,推荐1GB以上
- **系统支持:**Windows / Linux / macOS(需Python环境或整合包)
典型应用场景(请确保合法授权)
- **个人有声书制作:**用自己的声音克隆后录制长篇书籍,或为已故亲人声音保留"数字记忆"。
- **虚拟主播/偶像辅助:**为3D模型快速生成多语气语音内容。
- **游戏/影视草稿配音:**在正式配音前快速验证剧本节奏。
- **语言学习材料:**生成任意目标人声的标准发音范例。
快速开始:下载与基础使用
由于LuxTTS为开源项目,目前可通过以下渠道获取整合包或源码:
- 网盘下载(整合包): 点击下载LuxTTS本地一键整合包 (含模型权重及简单GUI)
极简使用步骤(以整合包为例):
- 下载并解压整合包,双击运行 `start.bat` 或 `LuxTTS.exe`。
- 在界面中上传一段参考音频(.wav格式,建议3-10秒,背景干净)。
- 输入需要合成的文字内容(支持中英文)。
- 点击"合成",等待数秒即可在输出文件夹获得48kHz高清语音文件。