02计算机组成原理-32位立即数与寻址
1.立即数
MIPS架构中指令设计的时候为了保证所有的指令长度一致并且相对较小从而去简化硬件的实现提高执行效率降低指令编码的复杂性,因此我们在许多含有立即数字段的指令格式中我们只预留了16位空间来存储这个立即数,例如上一节课中的I型指令,那我们如果要往这里面放个常数,那就是说这个里面的常数的大小不能超过216,那此时需要一个更大的数该怎么办,比如说需要填一个32位的立即数,很显然此时就不能用这个16位表示,那该怎么办呢?
由于指令长度的限制,我们不可能直接把32位长度的立即数直接放到指令格式里面。这时就需要采用特殊的编码方式来加载或存储32位的常数值以及使用完整的32位地址,需要采用两条指令来实现:
- lui(Load Upper Immediate):将最高16位的立即数载入到目标寄存器的高16位,同时低16位清零。
- ori(OR Immediate)或addi(Add Immediate):将剩余的低16位立即数与前一步得到的结果进行逻辑或( ori )操作,或者加法( addi ,如果目标寄存器之前已包含有效数据且希望累加的话),从而合成出完整的32位立即数。
其实就是把这个32位的立即数放进寄存器里,用的时候去寄存器里面取,而我们存放这个立即数也是一条指令,上节课说过不管是I R J型它们都有几位用于存放操作码,所以我们不可能一次性就存入这个32位的立即数,而是应该分几条指令来完成把这个立即数放进寄存器里面的操作。
例如,假设我们要将32位立即数0x12345678加载到寄存器t0中,我们需要这样操作:
第一步:lui 指令处理高 16 位lui 的作用是把 32 位立即数的高 16 位
(0x1234) 放到目标寄存器的高 16 位,同时把低 16 位强制清零。指令示例:lui t0, 0x1234
执行后,t0 的值是 0x12340000(高 16 位是 0x1234,低 16 位全 0)。
第二步:ori/addi 处理低 16 位
用 ori:逻辑或操作,因为 "任何数 | 0 = 本身",所以只会把低 16 位补上,不影响高 16 位。
指令示例:ori t0, t0, 0x5678
执行后,t0 = 0x12340000 | 0x00005678 = 0x12345678(完整的 32 位立即数)。
用 addi:加法操作,原理和 ori 一样(0x12340000 + 0x5678 = 0x12345678),适合寄存器已有有效数据、需要累加的场景;如果是从零拼接,ori 和 addi 效果完全一样。
2.地址
现在我们发现,想要用一个32位的立即数的时候用不了会放到寄存器里,后面想用的时候我就们需要去某个地址里面去找这个数据。这就牵涉到了寻址的问题。
不管什么指令结构,一个指令总的来说就是操作码+地址码。操作码给出指令做什么操作,地址码给出我要操作的数据在哪或者是谁。
地址我们分成两个部分:
形式地址(A):通过A加以转化得到EA
有效地址(EA):真实的地址
为什么要有两个地址呢,不能直接用EA吗?来看下面这个案例:
32位机的内存地址是32位的二进制数表示的
64位机的内存地址是64位的二进制数表示的
现在都按字节编址,问理论上上述两台机的内存地址是多大?
32位机的内存地址理论上是232B=4G,64位机的内存地址理论上是264B=16*230G(以上只是让大家知道怎么算内存地址的,下面来看案例)
以32位机举例,内存地址32位,MIPS的指令也是32位。也就是说我们的操作码+地址码总共才是32位了,不可能放得下一个32位的内存地址。既然放不进去那就说明我们指令里给出的地址码不一定是真实的内存地址。但是我们也应该根据它给出的地址来计算出真实的地址,所以我们需要形式地址。
地址:操作数存放的地方。注意:这个地址不一定非得是内存当中的,也可能是寄存器编号,I/O端口等。
3.寻址
寻址方式:是寻址指令或者操作数的有效地址的方式
寻址分两类,一类是指令寻址:去寻找下一条指令的地址,一类是数据寻址:去寻找本条指令的操作数的地址。
3.1顺序寻址
计算机怎么知道现在执行的指令是从哪里取出来的呢?或者说是谁给出了当前指令的地址?-->
PC:程序计数器,存放当前欲执行指令的地址,并且具有自动+1功能。
比如:一开始PC=1,那最开始就去1这个地方取出这条指令,取出后就会立马自动+1成2,这个2就是下一条指令要执行的地址,以此循环。这种寻址方式我们称为顺序寻址:直接通过PC+1(一条指令的长度对应的字节数).自动形成下一条指令的地址
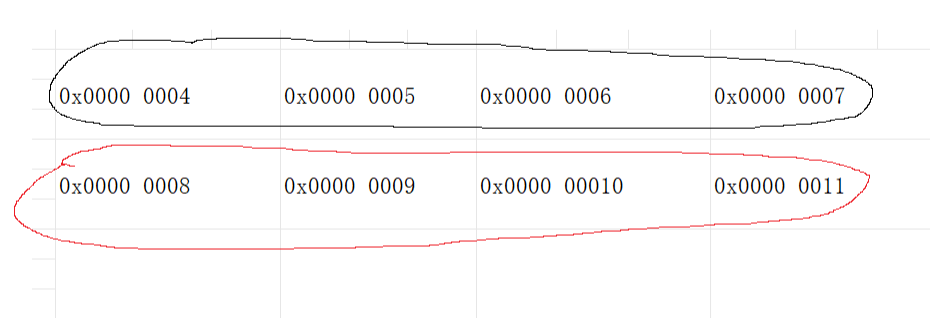
来做一个小题:MIPS架构下,按字节编址,指令长度位32位。
最初PC=0x0000 0004,问执行完这条指令后PC里面存的地址是?
PC=0x0000 0005?有的同学可能直接写成这样了,但事实上这个+1是加的一条指令的长度,而这里一条指令长度为32位,按字节编址,也就是说8位一个地址,那就说明跨过了4个地址,所以真正的下一条指令的地址是0x0000 0008。
如图:因为是按字节编址,即一个字节代表一个地址,而我们知道字节是8位,所以32位的指令长度,就会分为4个字节,即4个地址,所以PC初始位0x0000 0004,说明第一条指令的起始地址是0x0000 0004,再加上1,跳到下一条指令就到了0x0000 0008。
接下来先补充一点小知识吧,主要是我也才知道这个东西,我也是小白,哈哈:
我们平时会存 32 位整数(4 字节)、64 位浮点数(8 字节)这类多字节数据,它们会占用连续的字节地址,比如一个 32 位整数存在地址0x100开始的位置,那它会占用0x100、0x101、0x102、0x103四个连续的字节地址。
但是32位的话不就是4个字节吗,那一个字节不就是8个二进制数,那就是2给十六进制数啊,你为什么这里每个都有3个十六进制数?
0x100、0x101 这些是内存地址的十六进制表示(3 位十六进制数),而 1 个字节能存 2 位十六进制数,这是两个完全不同的概念 ------ 地址的十六进制位数是 "编号长度",字节的十六进制位数是 "存储容量",两者没有必须一致的要求。相当于是地址是门牌号,而里面的字节才是存储的内容。我们只有要求字节的格式是2个十六位进制的数,而地址和字节两者没有必须一致的要求。
3.2跳跃寻址
跳跃指令:转移类指令实现的。也就是说不让PC+1去得到下一个指令的地址了,而是在本条指令中直接告诉你下一条指令在哪,它会给出你下一条指令的形式地址,直接根据形式地址算出有效地址,跳到有效地址那个地方就可以了。
3.2.1无条件跳转(J型指令)
J型指令格式的跳转指令:

J型指令是一种专门用于无条件跳转(Jump)的指令格式。在MIPS指令集中,J型指令的具体格式如下:
6位操作码:用于指示这是一个J型跳转指令。
26位地址字段:会给出一个形式地址然后根据J型跳转指令的寻址方式根据形式地址去得到一个有效地址。
而J型指令的寻址方式主要是变通的直接寻址(伪直接寻址):跳转地址(有效地址)由指 26 位字段(形式地址的字段)和 PC 高4位相连而成,最低两位补0。
例:假设当前PC=0x0000 1000(执行跳转指令前的PC值),J型指令的26位形式地址字段值为0xF(注意:不是有效地址)。首先CPU从PC=0x0000 1000地址取出这条J型指令,取出后PC自动加4(MIPS指令4字节对齐,"+1"是指令数的增量,对应字节数+4),此时PC更新为0x0000 1004。
接下来执行这条跳转指令,按J型指令的伪直接寻址规则计算有效地址:
- 提取PC+4(0x0000 1004)的高4位:二进制为0000 0000 0000 0000 0001 0000 0000 0100,高4位是0000(十六进制0x0);
- 将26位形式地址0xF左移2位(补最低两位0,适配4字节对齐):0xF << 2 = 0x3C;
- 拼接高4位和左移后的形式地址:将高4位(0x0)左移28位得到0x0000 0000,再与0x3C做或运算,最终有效地址=0x0000 0000 | 0x0000 003C = 0x0000 003C。最后把0x0000 003C赋给PC
注意,小补充:
0xF是十六进制的简写形式,它代表的是 "数值 15",而不是 "只有 4 位二进制"------ 当把0xF放入 J 型指令的 26 位形式地址字段时,会自动在高位(左侧)补 0,填充成完整的 26 位二进制数,本质是 "小数值适配长字段" 的通用规则。
比如如果 J 型指令的形式地址是0x123(十六进制,对应二进制 100100011,9 位):填充到 26 位:0000 0000 0000 0001 0010 0011;
0xF<<2:
步骤 1:十六进制 0xF 转二进制
十六进制的每 1 位对应二进制的 4 位,这是固定换算关系:
0xF(十六进制) = 1111(二进制)
步骤 2:二进制左移 2 位,右侧补 0
左移 2 位就是把 1111 整体向左挪 2 位,右边空出的 2 位补 0:
原始二进制:1111
左移 1 位:11110(补 1 个 0)
左移 2 位:111100(补 2 个 0)
此时得到移位后的二进制数:111100。
步骤 3:二进制 111100 转回十六进制
先把二进制数按 "每 4 位分组"(不足 4 位的左侧补 0),再逐组换算:
二进制 111100 → 补 0 分组:0011 1100
第一组 0011 = 十进制 3 = 十六进制 0x3
第二组 1100 = 十进制 12 = 十六进制 0xC
拼接结果:0x3C
可能有人会疑惑不是26位吗最后计算出来怎么变32位了呢?
一、核心结论先明确
26 位只是形式地址的字段长度(指令里存储的原始数据),而 MIPS 的内存地址是 32 位(CPU 能访问的地址空间是 32 位),所以整个寻址过程的最终目标,就是把 "26 位形式地址" 和 "PC+4 的高 4 位" 组合成完整的 32 位有效地址------26 位是 "原料",32 位是 "成品"。
二、逐步骤拆解 "26 位→32 位" 的逻辑(对应你的 3 个步骤)
-
步骤 1:提取 PC+4 的高 4 位(32 位地址的 "高位原料")
PC+4 本身就是 32 位(0x00001004),我们只取它的最高 4 位(0000),这 4 位是用来补全 32 位地址的 "高位部分"。
-
步骤 2:26 位形式地址左移 2 位(变成 28 位 "低位原料")
原始形式地址:26 位(0xF 填充后是000000000000000000001111);
左移 2 位:在低位补 0,变成 28 位(00000000000000000000111100,对应 0x3C);
👉 关键:左移 2 位的目的有两个:
适配 MIPS 指令 4 字节对齐(地址最低 2 位必须是 0);
把 26 位扩展成 28 位,为后续和 4 位高地址拼接成 32 位做准备。
-
步骤 3:拼接成 32 位有效地址(4 位 + 28 位 = 32 位)
这是核心步骤!我们有两个 "原料":
高位原料:4 位(PC+4 的高 4 位,左移 28 位后变成 32 位,占最高 4 位);
低位原料:28 位(形式地址左移 2 位后的结果,占低 28 位);
补充:为什么不直接用 26 位?
MIPS 是 32 位架构,CPU 只能识别 32 位的内存地址 ------26 位形式地址的范围太小(只能覆盖 2^26=64MB 地址空间),通过拼接 PC+4 的高 4 位,能把寻址范围扩展到 2^32=4GB(完整的 32 位地址空间),这也是 "伪直接寻址" 的设计目的。
3.2.2有条件跳转(I型地址)
I 型指令格式的条件分支指令:
与无条件跳转指令不同,条件分支指令在跳转到目标地址之前会先比较两个操作数的值。如果满足比较条件,则执行跳转;否则,继续顺序执行下一条指令。具体来说:
1.两个操作数:这些操作数通常是从寄存器中获取的值,例如 rs (源寄存器1)和 rt (源寄存器2),用于比较它们之间的关系。
2.条件判断:不同的条件分支指令对应着不同的条件判断,如beq检查两者是否相等,bne检查两者是否不相等,blt则检查第一个操作数是否小于第二个操作数。
3.分支地址:如果满足特定条件,则程序计数器PC会被更新为指令中指定的目标地址,从而实现有条件地转移到新的指令序列继续执行。

条件分支指令的寻址方式是:PC相对寻址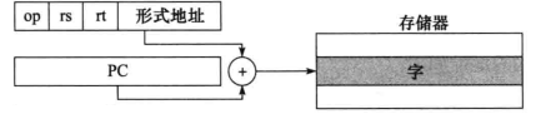
PC相对寻址(PC-Relative Addressing)是一种指令寻址方式,它使用当前程序计数器(ProgramCounter, PC)的值加上一个相对于当前指令地址的偏移量来确定下一条要执行的指令或数据的位置。
具体来说,在PC相对寻址中,指令包含了一个表示偏移量的字段。当CPU执行到含有PC相对寻址的跳转指令时,它会将当前PC值与该偏移量相加,得到的目标地址就是跳转的目的地。这种方式使得程序员可以编写出与加载地址无关的代码,增强了程序的可移植性,并且简化了硬件设计,因为不需要复杂的计算逻辑去生成绝对地址。
优点:简洁性和可预测性。
缺点:限制了分支目标的范围,因为偏移量的大小是有限的。不利于代码的重定位和共享。
寻址附近的指令也是加速大概率事件的另外一个例子 。
以上都是指令寻址,后一节博客会写数据寻址的内容。大概先写这些吧,今天的博客就先写到这,谢谢您的观看。