【FireRedASR-AED】目前性能最好的开源中文ASR模型(非大模型版)
- FireRedASR
- FireRedASR-AED模型结构
-
- [FireRedASR-AED Encoder](#FireRedASR-AED Encoder)
-
- 下采样模块(subsampling)
- [Conformer Block](#Conformer Block)
-
- [Conformer Macaron-style Feed-Forward Network modules](#Conformer Macaron-style Feed-Forward Network modules)
- [Multi-Head Self-Attention Module Incorporating Relative Positional Encoding](#Multi-Head Self-Attention Module Incorporating Relative Positional Encoding)
- [Convolution Module](#Convolution Module)
- [FireRedASR-AED Decoder](#FireRedASR-AED Decoder)
-
- [Transformer Block](#Transformer Block)
-
- [Multi-Head Attention](#Multi-Head Attention)
- [Feed-Forward Network](#Feed-Forward Network)
FireRedASR
Paper Model Blog Demo modelscope
FireRedASR是一个开源的工业级自动语音识别(ASR)模型家族,支持普通话、中国方言和英语,在公共普通话ASR基准测试上达到了新的最先进水平(SOTA),同时还提供了出色的歌词识别能力。
FireRedASR-AED:旨在平衡高性能和计算效率,并在基于大语言模型的语音模型中作为有效的语音表示模块。它利用基于注意力的编码器-解码器(AED)架构。
FireRedASR-AED模型结构
FireRedASR-AED采用端到端架构(end-to-end),结合了Conformer编码器(Encoder)和Transfomer解码器(Decoder)。这种设计选择利用了Conformer对语音特征中的局部和全局依赖性建模的能力以及Transformer在序列转导中的有效性。
FireRedASR-AED的整体架构如图所示:
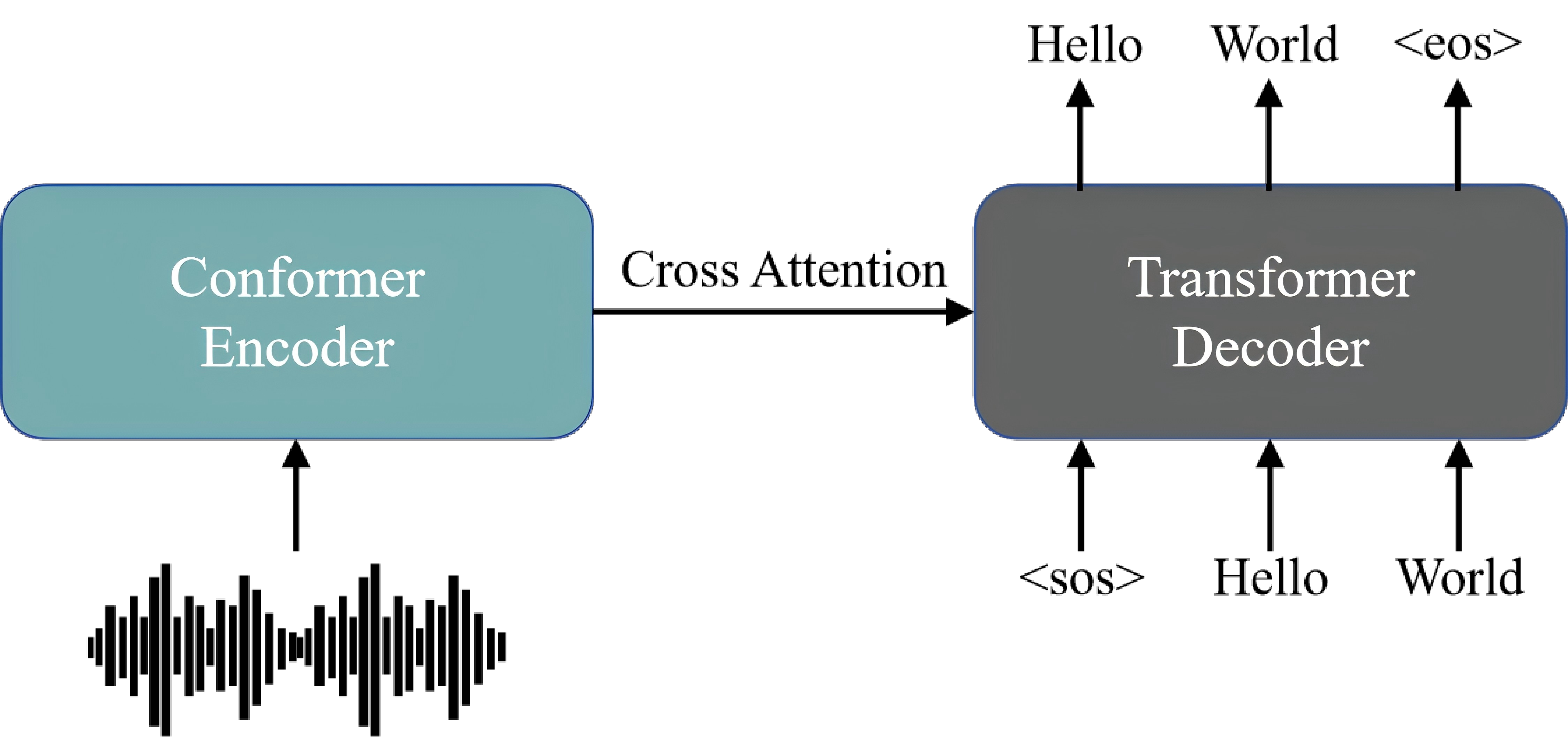
FireRedASR-AED Encoder
编码器(Encoder)由两个核心组件构成:一个下采样模块(subsampling)和16个Conformer块(blocks)。
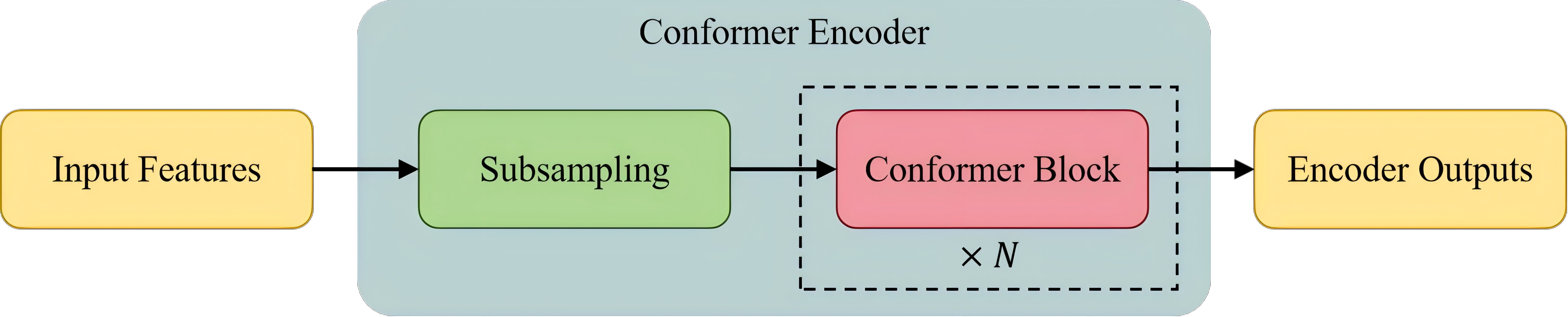
下采样模块(subsampling)
下采样模块采用两个串联的卷积层(每层步幅为 2、核大小为 3),后续紧跟 ReLU 激活函数。该配置将时间分辨率从每帧 10ms 降至 40ms,在保留关键声学信息的同时有效控制了计算复杂度。

Conformer Block
下采样模块处理后的特征随后送入一组 Conformer Block 进行处理,每个 Conformer Block 包含四个主要组件:位于块首尾的两个 Conformer Macaron-style Feed-Forward Network 模块、一个 multi-head self-attention module incorporating relative positional encoding 和 一个 convolution module equipped with gated linear unit (GLU) and layer normalization。最后经过一个LayerNorm(层正则化)输出

Conformer Macaron-style Feed-Forward Network modules
Conformer Macaron-style Feed-Forward Network(前馈神经网络) modules由一个残差网络网络组成。网络内部由层正则化(LayerNorm)、线性层(Linear)、激活函数(Swish)和线性层(Linear)顺序组成。

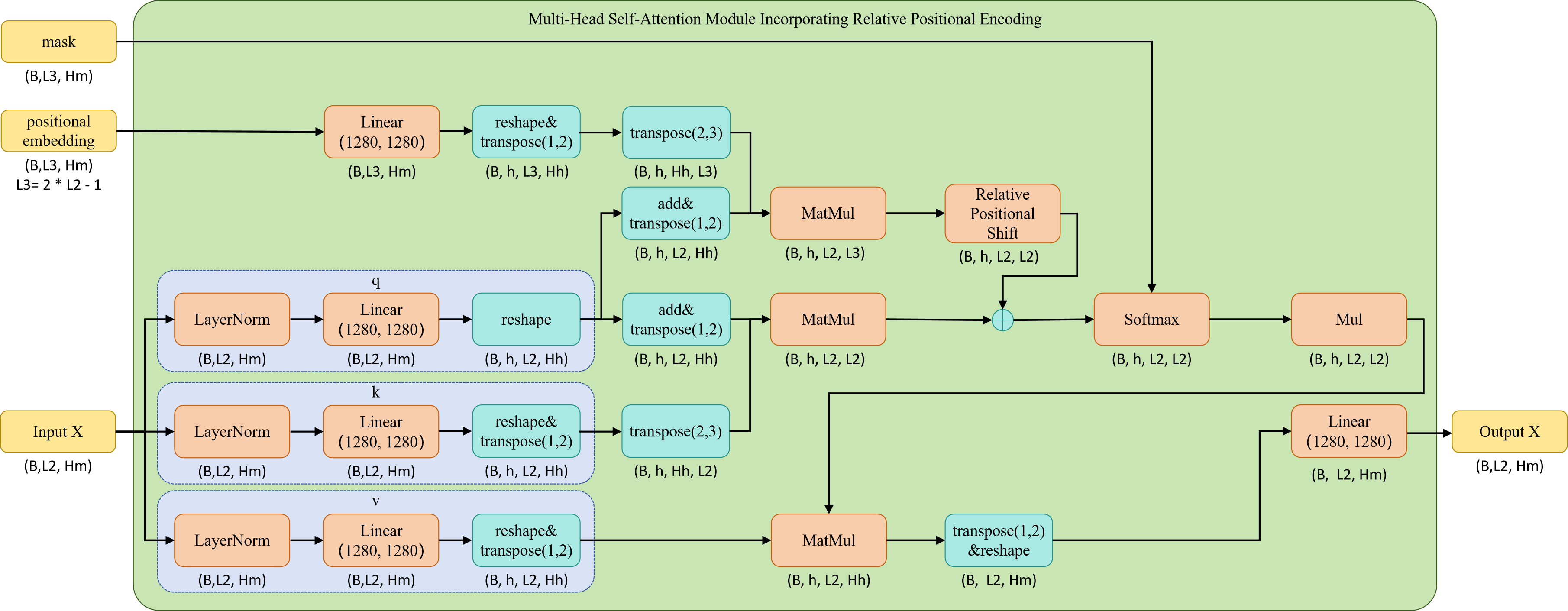
Multi-Head Self-Attention Module Incorporating Relative Positional Encoding
Multi-Head Self-Attention(多头自注意力) Module Incorporating Relative Positional Encoding在标准自注意力的基础知识增加了Relative Positional Encoding(相对位置编码)。标准自注意力由q、k、v组成即 s e l f - a t t e n t i o n = s c a l e ∗ s o f t m a x ( q ∗ k ) ∗ v self\text{-}attention=scale * softmax(q * k) * v self-attention=scale∗softmax(q∗k)∗v 。这里对q和k进行了修改,其中q和k都增加了一个科学系的偏移量。q则额外还与相对位置编码进行了额外的运算。
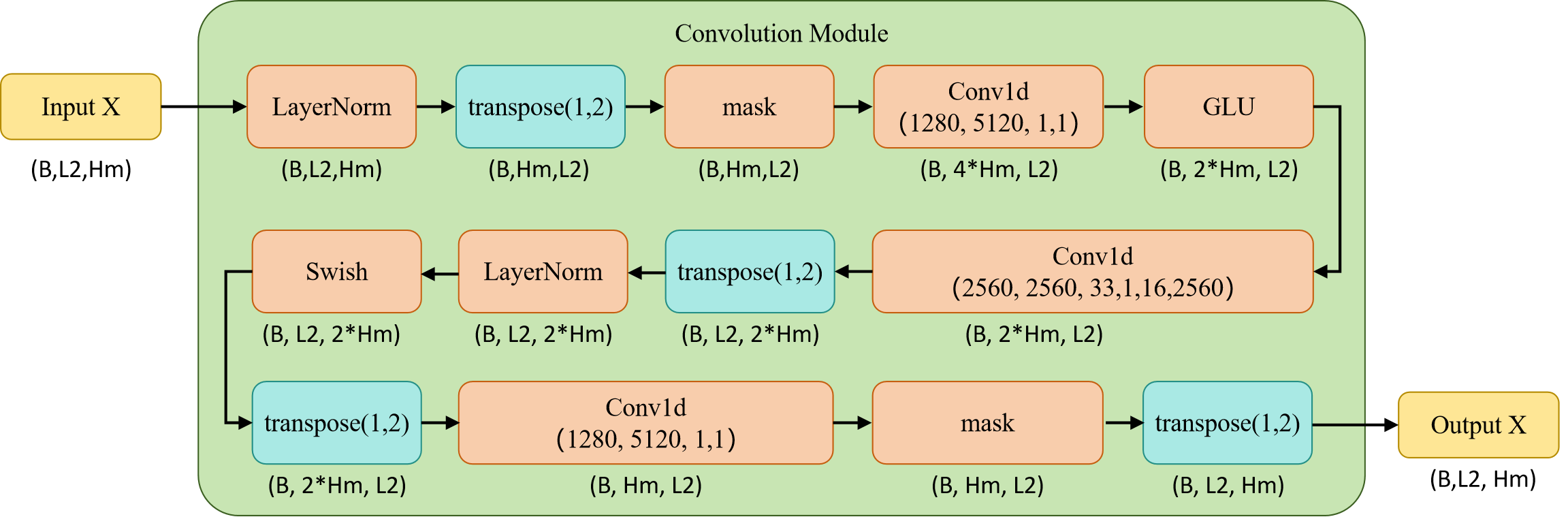
Convolution Module
a convolution(卷积) module 配置了gated linear unit (GLU) and layer normalization(层正则化)。此外含有三个卷积层和一个Swish函数。
FireRedASR-AED Decoder
解码器(Decoder)使用的是标准Transformer结构
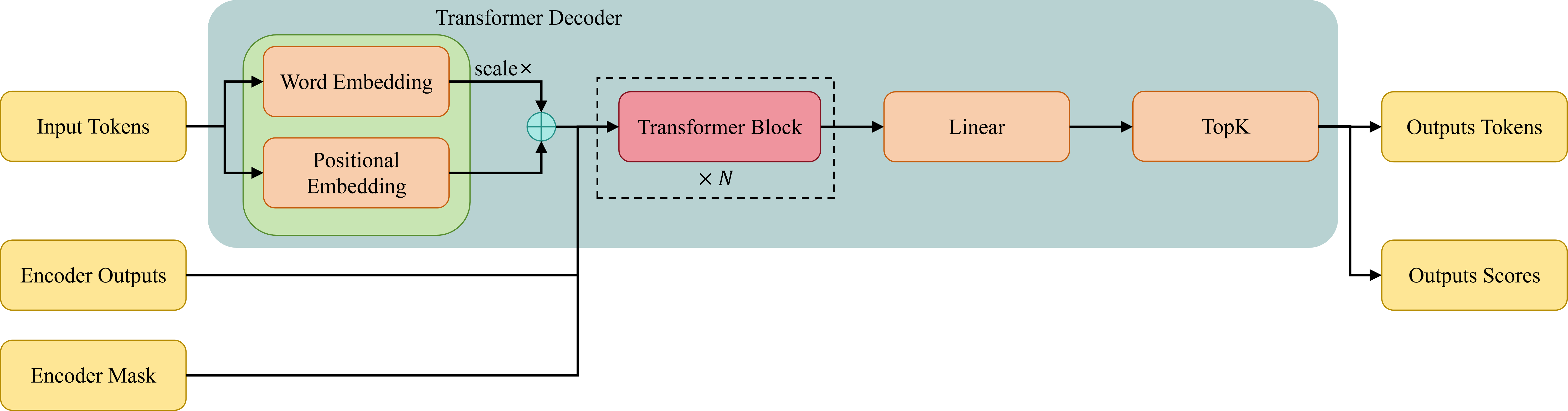
Transformer Block
每个Transformer Block包含三个子层,分别是多头自注意力层(multi-head self-attention),Encoder-Decoder多头注意力层(multi-head cross-attention)和前馈神经网络层(feed-forward network),所有模块使用前作残差连接(pre-norm residual units)。

Multi-Head Attention
- 对于多头自注意力层(self-attention),输入的Q、K、V都来自前一个子层的输入。
- 对于Encoder-Decoder多头注意力层(cross-attention),输入的Q来自Decoder前一个子层的输出,K和V来自Encoder的输出
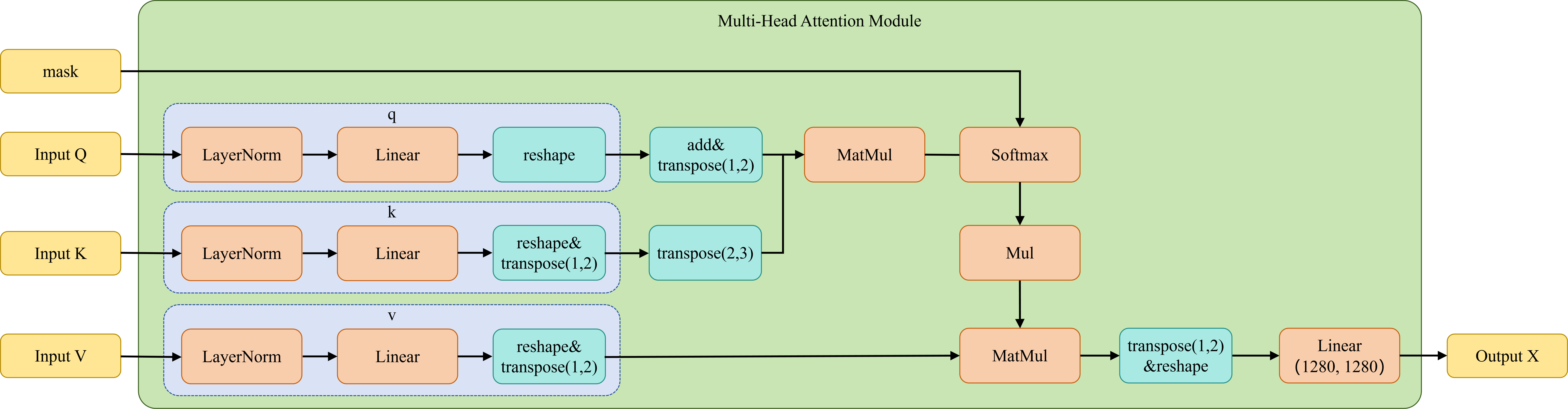
Feed-Forward Network
前馈神经网络层(feed-forward network)比较简单,有两个线性层组成,中间的激活函数使用的是GELU
