1 概述
构建基于 AI 大模型的智能爬虫。
AI 智能爬虫的主要优势在于自主获取数据和抗干扰性强。
传统的爬虫依赖固定的 CSS 选择器或 XPath 等,一旦网页改版,代码就会失效。而基于 AI 的爬虫则是让模型去"读"网页,像人一样找到目标数据在哪里,而不是依赖固定的数据获取和解析代码。
2 实战案例
2.1 需求
百度热搜 AI 爬虫:使用 python ,基于 AI 大模型实现一个爬虫,爬虫内容为:获取百度首页(即 https://www.baidu.com/)中"百度热搜"里的标题列表
2.2 核心思路
- 获取网页内容 (Fetch): 使用 requests 库获取 HTML(需伪装 User-Agent)。
- 预处理 (Pre-process): 网页 HTML 极其庞大,直接扔给大模型会消耗大量 Token 且容易超长。我们需要用 BeautifulSoup 进行粗略清洗,只保留文本或大致的容器。
- AI 提取 (AI Parse): 将清洗后的内容投喂给大模型(这里以 OpenAI 格式的 API 为例,你可以换成 DeepSeek、阿里通义等兼容 OpenAI 协议的模型),让它输出 JSON 格式的标题列表。
2.3 依赖
requests
beautifulsoup4
openai
2.4 代码实现
(1)代码实现如下所示
python
import json
import os
import requests
from bs4 import BeautifulSoup
from openai import OpenAI
# --- 配置区域 ---
# 这里以 OpenAI 官方 API 为例,你也可以换成 DeepSeek / 通义千问 / kimi 的 API Key 和 Base URL
# API_KEY = "your-api-key-here"
# BASE_URL = "https://api.openai.com/v1" # 如果用别的模型,修改这里
# MODEL_NAME = "gpt-4o-mini" # 或者是 deepseek-chat, qwen-turbo 等
# 读取环境变量中配置的模型信息
BASE_URL = os.getenv("BASE_URL")
API_KEY = os.getenv("API_KEY")
MODEL_NAME = os.getenv("MODEL_NAME")
def fetch_baidu_html():
"""
步骤 1: 获取百度首页的 HTML
"""
url = "https://www.baidu.com/"
# 必须添加 Header 伪装成浏览器,否则百度会拦截
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8"
}
try:
response = requests.get(url, headers=headers, timeout=10)
response.encoding = 'utf-8' # 确保中文不乱码
if response.status_code == 200:
return response.text
else:
print(f"请求失败,状态码: {response.status_code}")
return None
except Exception as e:
print(f"发生错误: {e}")
return None
def preprocess_html(html_content):
"""
步骤 2: 清洗 HTML (为了节省 Token)
"""
if not html_content:
return None
soup = BeautifulSoup(html_content, 'html.parser')
# 为了减少模型的token消耗,可以只获取热搜模块的信息
# 获取 id=s-hotsearch-wrapper 的 div内容
hot_search_div = soup.find('div', {'id': 's-hotsearch-wrapper'})
return hot_search_div
def extract_titles_with_ai(clean_text):
"""
步骤 3: 调用 AI 大模型提取数据
"""
client = OpenAI(api_key=API_KEY, base_url=BASE_URL)
# 构造 Prompt
prompt = f"""
你是一个智能爬虫助手。
请从下面的网页文本中,提取出百度热搜内容的标题。
要求:
1. 结果为 JSON 格式,包含 title。
2. 如果找不到热搜内容,返回空json。
网页文本内容如下:
{clean_text}
"""
try:
response = client.chat.completions.create(
model=MODEL_NAME,
messages=[
{"role": "system", "content": "You are a helpful data extraction assistant."},
{"role": "user", "content": prompt}
],
temperature=0.1, # 低温度保证输出稳定
)
content = response.choices[0].message.content
# 清理可能存在的 markdown 格式
content = content.replace("```json", "").replace("```", "").strip()
return json.loads(content)
except Exception as e:
print(f"AI 提取失败: {e}")
return []
def main():
print("正在访问百度首页...")
html = fetch_baidu_html()
if html:
print("网页获取成功,正在预处理数据...")
# 注意:百度首页是动态加载的,有时 requests 拿到的静态 HTML 可能不包含完整热搜
# 如果 requests 拿不到,通常需要用 Selenium
clean_text = preprocess_html(html)
print("正在调用 AI 模型进行分析...")
hot_titles = extract_titles_with_ai(clean_text)
print("-" * 30)
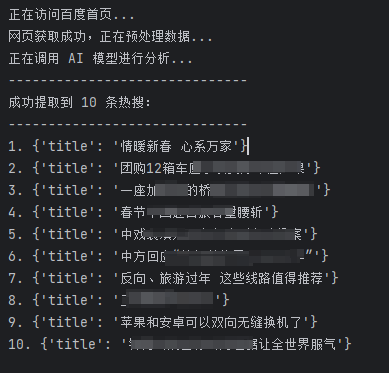
print(f"成功提取到 {len(hot_titles)} 条热搜:")
print("-" * 30)
for idx, title in enumerate(hot_titles, 1):
print(f"{idx}. {title}")
else:
print("流程终止。")
#
if __name__ == "__main__":
main()(2)结果打印